 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2HF: Multi-level Multi-modal Hybrid Fusion for Text-Video Retrieval
Aug 16, 2022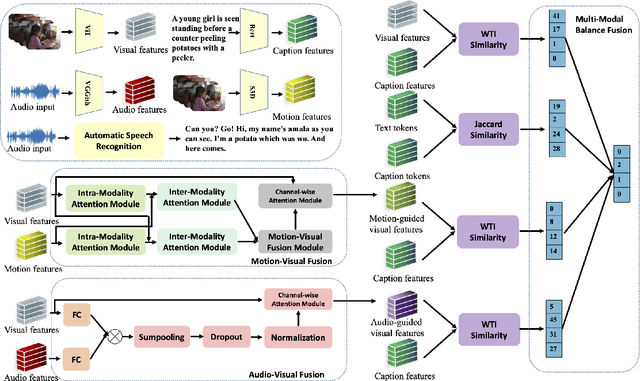
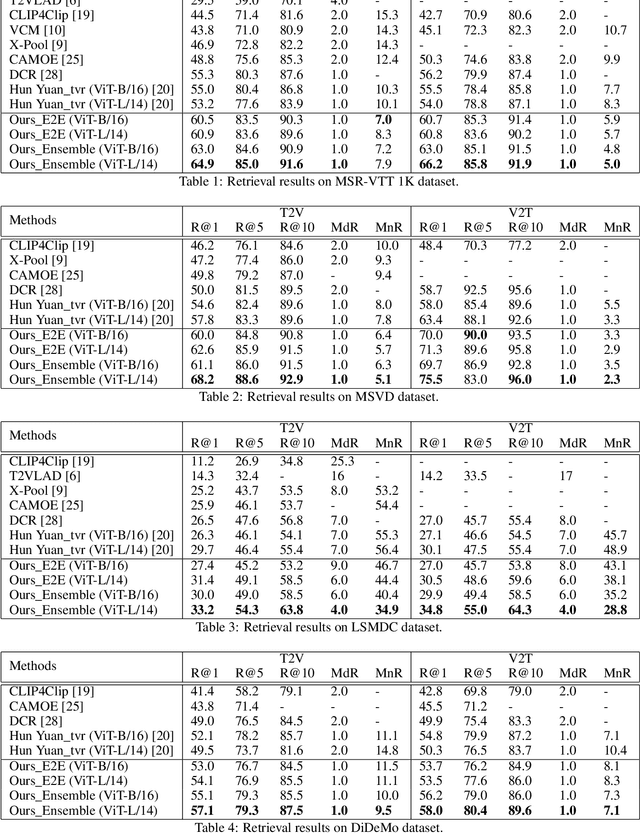


Videos contain multi-modal content, and exploring multi-level cross-modal interactions with natural language queries can provide great prominence to text-video retrieval task (TVR). However, new trending methods applying large-scale pre-trained model CLIP for TVR do not focus on multi-modal cues in videos. Furthermore, the traditional methods simply concatenating multi-modal features do not exploit fine-grained cross-modal information in videos. In this paper, we propose a multi-level multi-modal hybrid fusion (M2HF) network to explore comprehensive interactions between text queries and each modality content in videos. Specifically, M2HF first utilizes visual features extracted by CLIP to early fuse with audio and motion features extracted from videos, obtaining audio-visual fusion features and motion-visual fusion features respectively. Multi-modal alignment problem is also considered in this process. Then, visual features, audio-visual fusion features, motion-visual fusion features, and texts extracted from videos establish cross-modal relationships with caption queries in a multi-level way. Finally, the retrieval outputs from all levels are late fused to obtain final text-video retrieval results. Our framework provides two kinds of training strategies, including an ensemble manner and an end-to-end manner. Moreover, a novel multi-modal balance loss function is proposed to balance the contributions of each modality for efficient end-to-end training. M2HF allows us to obtain state-of-the-art results on various benchmarks, eg, Rank@1 of 64.9\%, 68.2\%, 33.2\%, 57.1\%, 57.8\% on MSR-VTT, MSVD, LSMDC, DiDeMo, and ActivityNet, respectively.
Improving Task Generalization via Unified Schema Prompt
Aug 05, 2022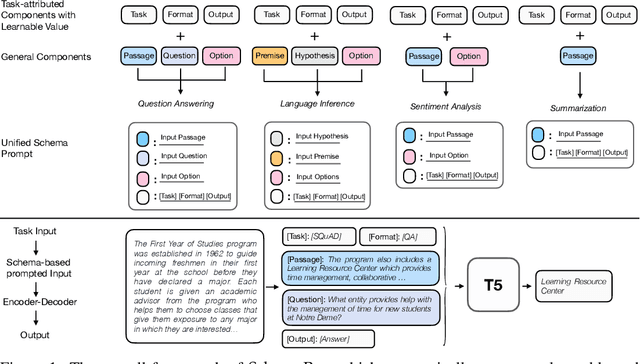
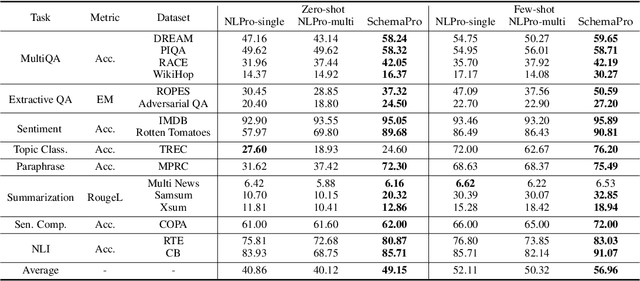

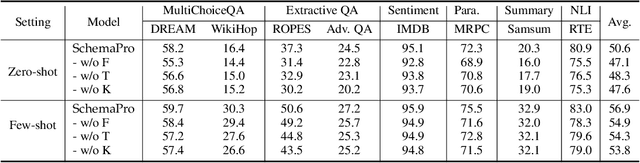
Task generalization has been a long standing challenge in Natural Language Processing (NLP). Recent research attempts to improve the task generalization ability of pre-trained language models by mapping NLP tasks into human-readable prompted forms. However, these approaches require laborious and inflexible manual collection of prompts, and different prompts on the same downstream task may receive unstable performance. We propose Unified Schema Prompt, a flexible and extensible prompting method, which automatically customizes the learnable prompts for each task according to the task input schema. It models the shared knowledge between tasks, while keeping the characteristics of different task schema, and thus enhances task generalization ability. The schema prompt takes the explicit data structure of each task to formulate prompts so that little human effort is involved. To test the task generalization ability of schema prompt at scale, we conduct schema prompt-based multitask pre-training on a wide variety of general NLP tasks. The framework achieves strong zero-shot and few-shot generalization performance on 16 unseen downstream tasks from 8 task types (e.g., QA, NLI, etc). Furthermore, comprehensive analyses demonstrate the effectiveness of each component in the schema prompt, its flexibility in task compositionality, and its ability to improve performance under a full-data fine-tuning setting.
ProQA: Structural Prompt-based Pre-training for Unified Question Answering
May 09, 2022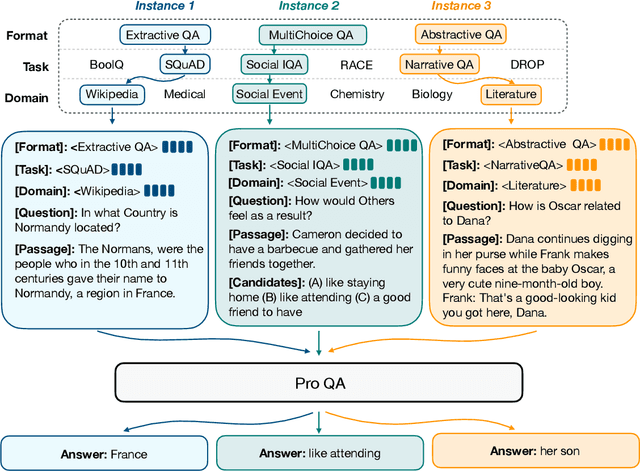
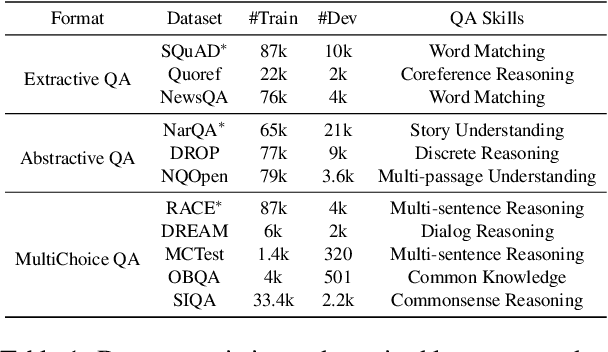

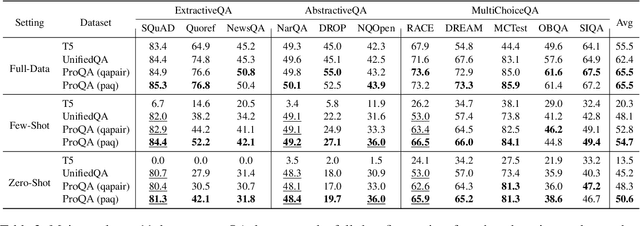
Question Answering (QA) is a longstanding challenge in natural language processing. Existing QA works mostly focus on specific question types, knowledge domains, or reasoning skills. The specialty in QA research hinders systems from modeling commonalities between tasks and generalization for wider applications. To address this issue, we present ProQA, a unified QA paradigm that solves various tasks through a single model. ProQA takes a unified structural prompt as the bridge and improves the QA-centric ability by structural prompt-based pre-training. Through a structurally designed prompt-based input schema, ProQA concurrently models the knowledge generalization for all QA tasks while keeping the knowledge customization for every specific QA task. Furthermore, ProQA is pre-trained with structural prompt-formatted large-scale synthesized corpus, which empowers the model with the commonly-required QA ability. Experimental results on 11 QA benchmarks demonstrate that ProQA consistently boosts performance on both full data fine-tuning, few-shot learning, and zero-shot testing scenarios. Furthermore, ProQA exhibits strong ability in both continual learning and transfer learning by taking the advantages of the structural prompt.
Adversarial Fine-tune with Dynamically Regulated Adversary
Apr 28, 2022

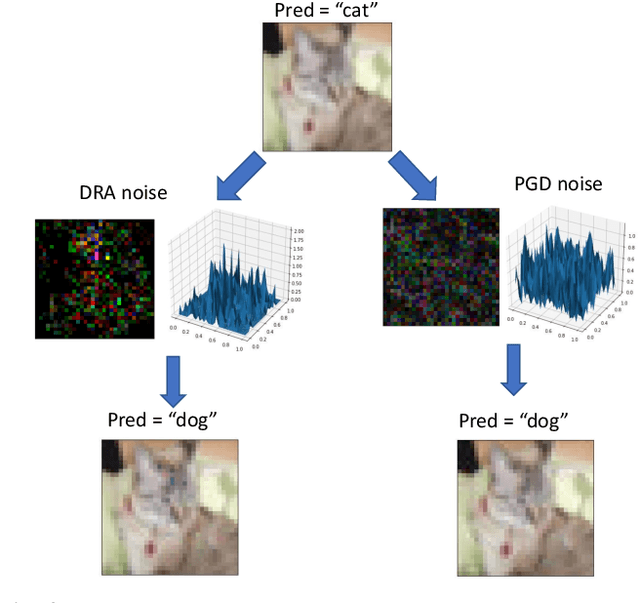
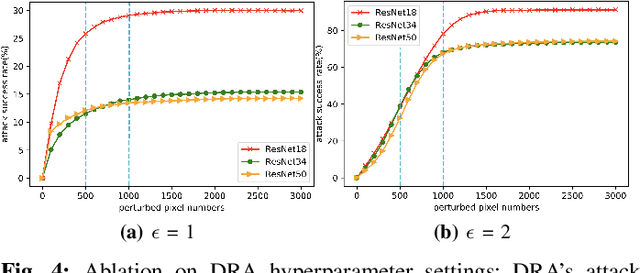
Adversarial training is an effective method to boost model robustness to malicious, adversarial attacks. However, such improvement in model robustness often leads to a significant sacrifice of standard performance on clean images. In many real-world applications such as health diagnosis and autonomous surgical robotics, the standard performance is more valued over model robustness against such extremely malicious attacks. This leads to the question: To what extent we can boost model robustness without sacrificing standard performance? This work tackles this problem and proposes a simple yet effective transfer learning-based adversarial training strategy that disentangles the negative effects of adversarial samples on model's standard performance. In addition, we introduce a training-friendly adversarial attack algorithm, which facilitates the boost of adversarial robustness without introducing significant training complexity. Extensive experimentation indicates that the proposed method outperforms previous adversarial training algorithms towards the target: to improve model robustness while preserving model's standard performance on clean data.
UniXcoder: Unified Cross-Modal Pre-training for Code Representation
Mar 08, 2022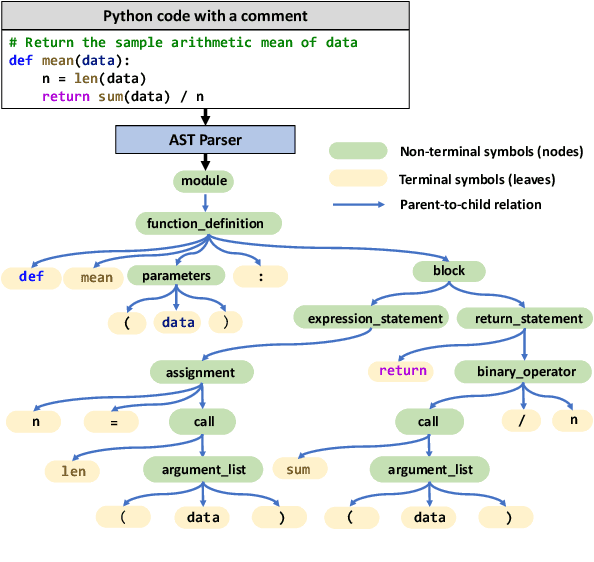
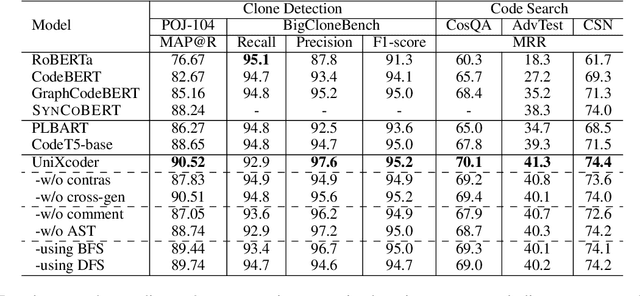
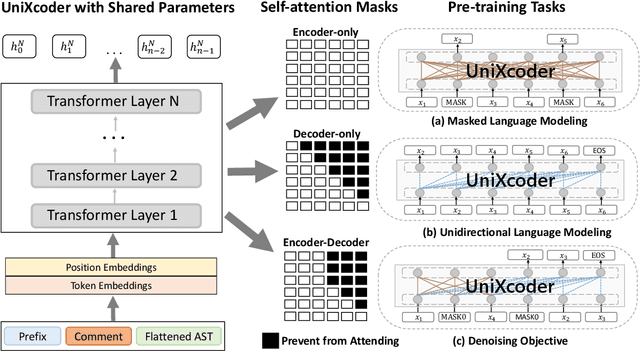
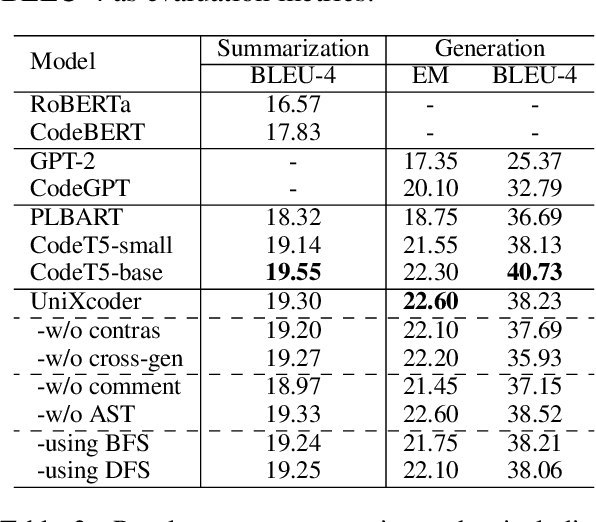
Pre-trained models for programming languages have recently demonstrated great success on code intelligence. To support both code-related understanding and generation tasks, recent works attempt to pre-train unified encoder-decoder models. However, such encoder-decoder framework is sub-optimal for auto-regressive tasks, especially code completion that requires a decoder-only manner for efficient inference. In this paper, we present UniXcoder, a unified cross-modal pre-trained model for programming language. The model utilizes mask attention matrices with prefix adapters to control the behavior of the model and leverages cross-modal contents like AST and code comment to enhance code representation. To encode AST that is represented as a tree in parallel, we propose a one-to-one mapping method to transform AST in a sequence structure that retains all structural information from the tree. Furthermore, we propose to utilize multi-modal contents to learn representation of code fragment with contrastive learning, and then align representations among programming languages using a cross-modal generation task. We evaluate UniXcoder on five code-related tasks over nine datasets. To further evaluate the performance of code fragment representation, we also construct a dataset for a new task, called zero-shot code-to-code search. Results show that our model achieves state-of-the-art performance on most tasks and analysis reveals that comment and AST can both enhance UniXcoder.
Efficient Policy Space Response Oracles
Feb 17, 2022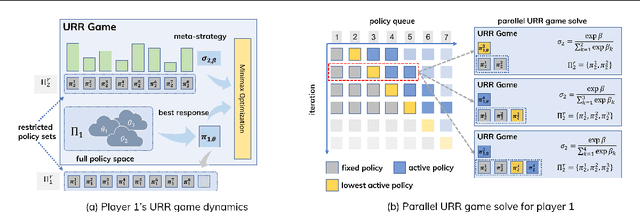
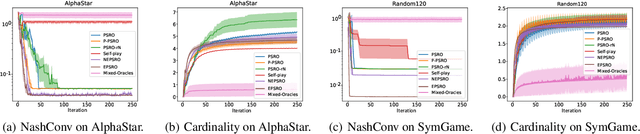
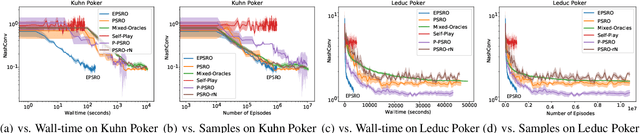
Policy Space Response Oracle method (PSRO) provides a general solution to Nash equilibrium in two-player zero-sum games but suffers from two problems: (1) the computation inefficiency due to consistently evaluating current populations by simulations; and (2) the exploration inefficiency due to learning best responses against a fixed meta-strategy at each iteration. In this work, we propose Efficient PSRO (EPSRO) that largely improves the efficiency of the above two steps. Central to our development is the newly-introduced subroutine of minimax optimization on unrestricted-restricted (URR) games. By solving URR at each step, one can evaluate the current game and compute the best response in one forward pass with no need for game simulations. Theoretically, we prove that the solution procedures of EPSRO offer a monotonic improvement on exploitability. Moreover, a desirable property of EPSRO is that it is parallelizable, this allows for efficient exploration in the policy space that induces behavioral diversity. We test EPSRO on three classes of games and report a 50x speedup in wall-time, 10x data efficiency, and similar exploitability as existing PSRO methods on Kuhn and Leduc Poker games.
Generative Adversarial Exploration for Reinforcement Learning
Jan 27, 2022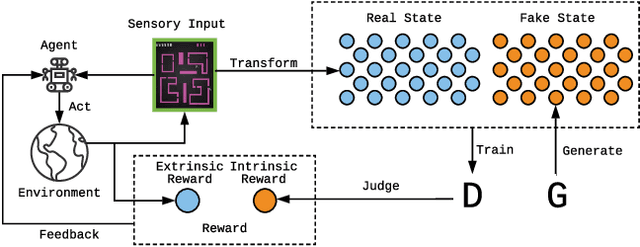
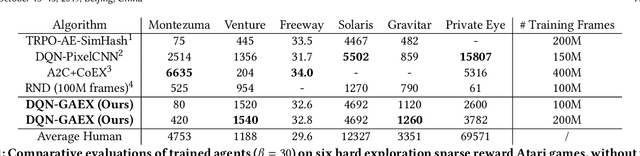
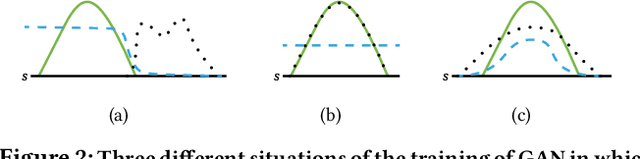
Exploration is crucial for training the optimal reinforcement learning (RL) policy, where the key is to discriminate whether a state visiting is novel. Most previous work focuses on designing heuristic rules or distance metrics to check whether a state is novel without considering such a discrimination process that can be learned. In this paper, we propose a novel method called generative adversarial exploration (GAEX) to encourage exploration in RL via introducing an intrinsic reward output from a generative adversarial network, where the generator provides fake samples of states that help discriminator identify those less frequently visited states. Thus the agent is encouraged to visit those states which the discriminator is less confident to judge as visited. GAEX is easy to implement and of high training efficiency. In our experiments, we apply GAEX into DQN and the DQN-GAEX algorithm achieves convincing performance on challenging exploration problems, including the game Venture, Montezuma's Revenge and Super Mario Bros, without further fine-tuning on complicate learning algorithms. To our knowledge, this is the first work to employ GAN in RL exploration problems.
Reasoning over Hybrid Chain for Table-and-Text Open Domain QA
Jan 15, 2022
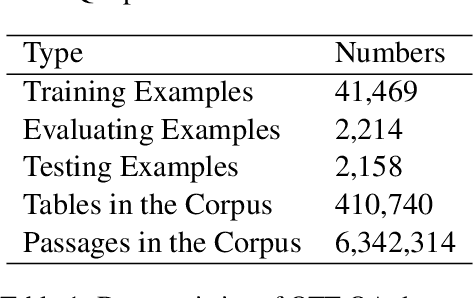
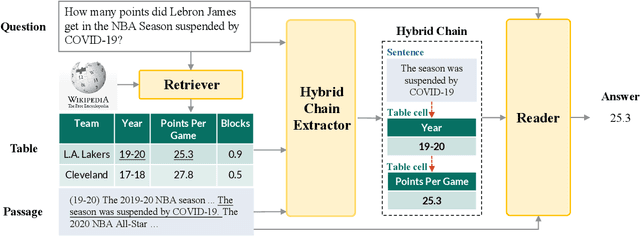
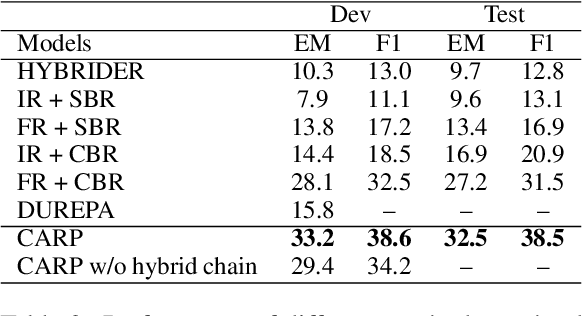
Tabular and textual question answering requires systems to perform reasoning over heterogeneous information, considering table structure, and the connections among table and text. In this paper, we propose a ChAin-centric Reasoning and Pre-training framework (CARP). CARP utilizes hybrid chain to model the explicit intermediate reasoning process across table and text for question answering. We also propose a novel chain-centric pre-training method, to enhance the pre-trained model in identifying the cross-modality reasoning process and alleviating the data sparsity problem. This method constructs the large-scale reasoning corpus by synthesizing pseudo heterogeneous reasoning paths from Wikipedia and generating corresponding questions. We evaluate our system on OTT-QA, a large-scale table-and-text open-domain question answering benchmark, and our system achieves the state-of-the-art performance. Further analyses illustrate that the explicit hybrid chain offers substantial performance improvement and interpretablity of the intermediate reasoning process, and the chain-centric pre-training boosts the performance on the chain extraction.
A Survey of Controllable Text Generation using Transformer-based Pre-trained Language Models
Jan 14, 2022
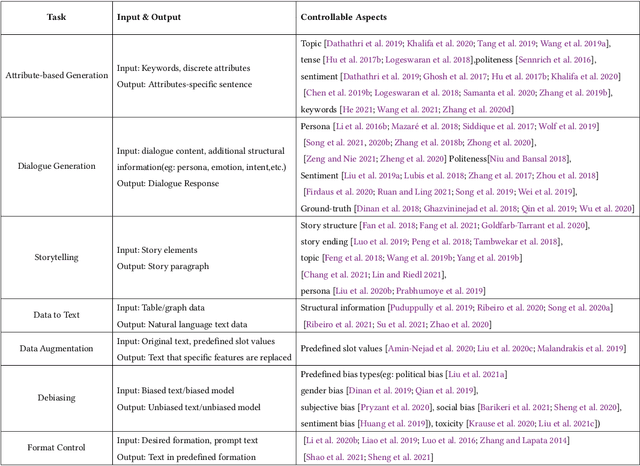
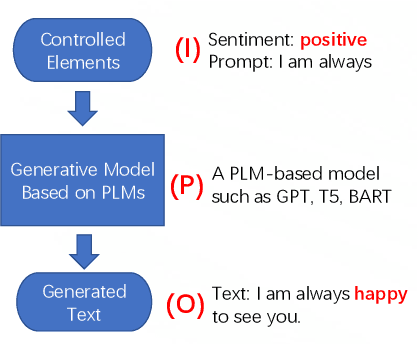
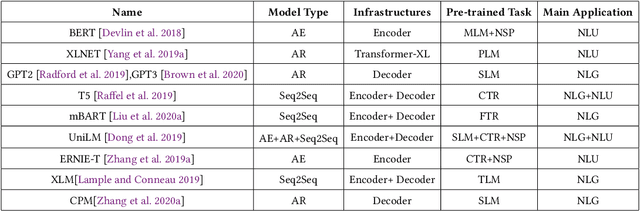
Controllable Text Generation (CTG) is emerging area in the field of natural language generation (NLG). It is regarded as crucial for the development of advanced text generation technologies that are more natural and better meet the specific constraints in practical applications. In recent years, methods using large-scale pre-trained language models (PLMs), in particular the widely used transformer-based PLMs, have become a new paradigm of NLG, allowing generation of more diverse and fluent text. However, due to the lower level of interpretability of deep neural networks, the controllability of these methods need to be guaranteed. To this end, controllable text generation using transformer-based PLMs has become a rapidly growing yet challenging new research hotspot. A diverse range of approaches have emerged in the recent 3-4 years, targeting different CTG tasks which may require different types of controlled constraints. In this paper, we present a systematic critical review on the common tasks, main approaches and evaluation methods in this area. Finally, we discuss the challenges that the field is facing, and put forward various promising future directions. To the best of our knowledge, this is the first survey paper to summarize CTG techniques from the perspective of PLMs. We hope it can help researchers in related fields to quickly track the academic frontier, providing them with a landscape of the area and a roadmap for future research.
Applications of Generative Adversarial Networks in Anomaly Detection: A Systematic Literature Review
Oct 22, 2021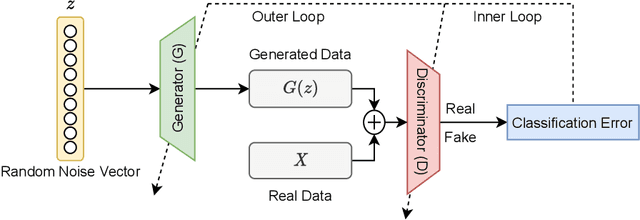

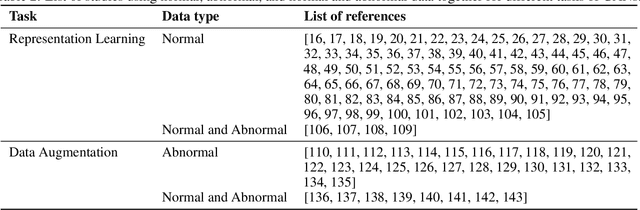
Anomaly detection has become an indispensable tool for modern society, applied in a wide range of applications, from detecting fraudulent transactions to malignant brain tumours. Over time, many anomaly detection techniques have been introduced. However, in general, they all suffer from the same problem: a lack of data that represents anomalous behaviour. As anomalous behaviour is usually costly (or dangerous) for a system, it is difficult to gather enough data that represents such behaviour. This, in turn, makes it difficult to develop and evaluate anomaly detection techniques. Recently, generative adversarial networks (GANs) have attracted a great deal of attention in anomaly detection research, due to their unique ability to generate new data. In this paper, we present a systematic literature review of the applications of GANs in anomaly detection, covering 128 papers on the subject. The goal of this review paper is to analyze and summarize: (1) which anomaly detection techniques can benefit from certain types of GANs, and how, (2) in which application domains GAN-assisted anomaly detection techniques have been applied, and (3) which datasets and performance metrics have been used to evaluate these techniques. Our study helps researchers and practitioners to find the most suitable GAN-assisted anomaly detection technique for their application. In addition, we present a research roadmap for future studies in this area.