 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPTNESS: Incorporating Appraisal Theory and Emotion Support Strategies for Empathetic Response Generation
Jul 23, 2024



Empathetic response generation is designed to comprehend the emotions of others and select the most appropriate strategies to assist them in resolving emotional challenges. Empathy can be categorized into cognitive empathy and affective empathy. The former pertains to the ability to understand and discern the emotional issues and situations of others, while the latter involves the capacity to provide comfort. To enhance one's empathetic abilities, it is essential to develop both these aspects. Therefore, we develop an innovative framework that combines retrieval augmentation and emotional support strategy integration. Our framework starts with the introduction of a comprehensive emotional palette for empathy. We then apply appraisal theory to decompose this palette and create a database of empathetic responses. This database serves as an external resource and enhances the LLM's empathy by integrating semantic retrieval mechanisms. Moreover, our framework places a strong emphasis on the proper articulation of response strategies. By incorporating emotional support strategies, we aim to enrich the model's capabilities in both cognitive and affective empathy, leading to a more nuanced and comprehensive empathetic response. Finally, we extract datasets ED and ET from the empathetic dialogue dataset \textsc{EmpatheticDialogues} and ExTES based on dialogue length. Experiments demonstrate that our framework can enhance the empathy ability of LLMs from both cognitive and affective empathy perspectives. Our code is released at https://github.com/CAS-SIAT-XinHai/APTNESS.
Hierarchical Context Pruning: Optimizing Real-World Code Completion with Repository-Level Pretrained Code LLMs
Jun 27, 2024
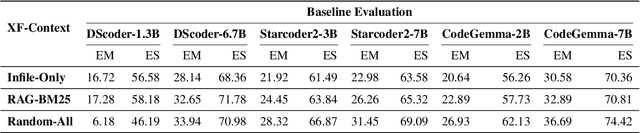
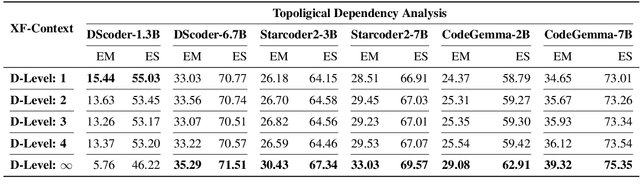
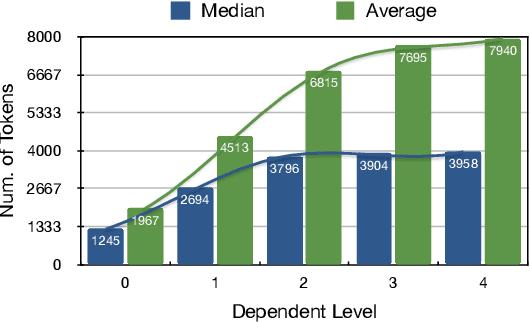
Some recently developed code large language models (Code LLMs) have been pre-trained on repository-level code data (Repo-Code LLMs), enabling these models to recognize repository structures and utilize cross-file information for code completion. However, in real-world development scenarios, simply concatenating the entire code repository often exceeds the context window limits of these Repo-Code LLMs, leading to significant performance degradation. In this study, we conducted extensive preliminary experiments and analyses on six Repo-Code LLMs. The results indicate that maintaining the topological dependencies of files and increasing the code file content in the completion prompts can improve completion accuracy; pruning the specific implementations of functions in all dependent files does not significantly reduce the accuracy of completions. Based on these findings, we proposed a strategy named Hierarchical Context Pruning (HCP) to construct completion prompts with high informational code content. The HCP models the code repository at the function level, maintaining the topological dependencies between code files while removing a large amount of irrelevant code content, significantly reduces the input length for repository-level code completion. We applied the HCP strategy in experiments with six Repo-Code LLMs, and the results demonstrate that our proposed method can significantly enhance completion accuracy while substantially reducing the length of input. Our code and data are available at https://github.com/Hambaobao/HCP-Coder.
Leave No Document Behind: Benchmarking Long-Context LLMs with Extended Multi-Doc QA
Jun 25, 2024



Long-context modeling capabilities have garnered widespread attention, leading to the emergence of Large Language Models (LLMs) with ultra-context windows. Meanwhile, benchmarks for evaluating long-context LLMs are gradually catching up. However, existing benchmarks employ irrelevant noise texts to artificially extend the length of test cases, diverging from the real-world scenarios of long-context applications. To bridge this gap, we propose a novel long-context benchmark, Loong, aligning with realistic scenarios through extended multi-document question answering (QA). Unlike typical document QA, in Loong's test cases, each document is relevant to the final answer, ignoring any document will lead to the failure of the answer. Furthermore, Loong introduces four types of tasks with a range of context lengths: Spotlight Locating, Comparison, Clustering, and Chain of Reasoning, to facilitate a more realistic and comprehensive evaluation of long-context understanding. Extensive experiments indicate that existing long-context language models still exhibit considerable potential for enhancement. Retrieval augmented generation (RAG) achieves poor performance, demonstrating that Loong can reliably assess the model's long-context modeling capabilities.
Beyond Near-Field: Far-Field Location Division Multiple Access in Downlink MIMO Systems
Jun 18, 2024



Exploring channel dimensions has been the driving force behind breakthroughs in successive generations of mobile communication systems. In 5G, space division multiple access (SDMA) leveraging massive MIMO has been crucial in enhancing system capacity through spatial differentiation of users. However, SDMA can only finely distinguish users at adjacent angles in ultra-dense networks by extremely large-scale antenna arrays. For a long time, most research has focused on the angle domain of the space, overlooking the potential of the distance domain. Near-field location division multiple access (LDMA) was proposed based on the beam-focusing effect yielded by near-field spherical propagation model, partitioning channel resources by both angle and distance. To achieve a similar idea in the far-field region, this paper introduces a far-field LDMA scheme for wideband systems based on orthogonal frequency division multiplexing (OFDM). Benefiting from frequency diverse arrays (FDA), it becomes possible to manipulate beams in the distance domain. Combined with OFDM, the inherent cyclic prefix ensures a complete OFDM symbol can be received without losing distance information, while the matched filter of OFDM helps eliminate the time-variance of FDA steering vectors. Theoretical and simulation results show that LDMA can fully exploit the additional degrees of freedom in the distance domain to significantly improve spectral efficiency, especially in narrow sector multiple access (MA) scenarios. Moreover, LDMA can maintain independence between array elements even in single-path channels, making it stand out in MA schemes at millimeter-wave and higher frequency bands.
CoEvol: Constructing Better Responses for Instruction Finetuning through Multi-Agent Cooperation
Jun 11, 2024



In recent years, instruction fine-tuning (IFT) on large language models (LLMs) has garnered considerable attention to enhance model performance on unseen tasks. Attempts have been made on automatic construction and effective selection for IFT data. However, we posit that previous methods have not fully harnessed the potential of LLMs for enhancing data quality. The responses within IFT data could be further enhanced by leveraging the capabilities of LLMs themselves. In this paper, we propose CoEvol, an LLM-based multi-agent cooperation framework for the improvement of responses to instructions. To effectively refine the responses, we develop an iterative framework following a debate-advise-edit-judge paradigm. A two-stage multi-agent debate strategy is further devised to ensure the diversity and reliability of editing suggestions within the framework. Empirically, models equipped with CoEvol outperform competitive baselines evaluated by MT-Bench and AlpacaEval, demonstrating its effectiveness in enhancing instruction-following capabilities for LLMs.
II-Bench: An Image Implication Understanding Benchmark for Multimodal Large Language Models
Jun 11, 2024



The rapid advancements in the development of multimodal large language models (MLLMs) have consistently led to new breakthroughs on various benchmarks. In response, numerous challenging and comprehensive benchmarks have been proposed to more accurately assess the capabilities of MLLMs. However, there is a dearth of exploration of the higher-order perceptual capabilities of MLLMs. To fill this gap, we propose the Image Implication understanding Benchmark, II-Bench, which aims to evaluate the model's higher-order perception of images. Through extensive experiments on II-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on II-Bench. The pinnacle accuracy of MLLMs attains 74.8%, whereas human accuracy averages 90%, peaking at an impressive 98%. Subsequently, MLLMs perform worse on abstract and complex images, suggesting limitations in their ability to understand high-level semantics and capture image details. Finally, it is observed that most models exhibit enhanced accuracy when image sentiment polarity hints are incorporated into the prompts. This observation underscores a notable deficiency in their inherent understanding of image sentiment. We believe that II-Bench will inspire the community to develop the next generation of MLLMs, advancing the journey towards expert artificial general intelligence (AGI). II-Bench is publicly available at https://huggingface.co/datasets/m-a-p/II-Bench.
Improving In-Context Learning with Prediction Feedback for Sentiment Analysis
Jun 05, 2024



Large language models (LLMs) have achieved promising results in sentiment analysis through the in-context learning (ICL) paradigm. However, their ability to distinguish subtle sentiments still remains a challenge. Inspired by the human ability to adjust understanding via feedback, this paper enhances ICL by incorporating prior predictions and feedback, aiming to rectify sentiment misinterpretation of LLMs. Specifically, the proposed framework consists of three steps: (1) acquiring prior predictions of LLMs, (2) devising predictive feedback based on correctness, and (3) leveraging a feedback-driven prompt to refine sentiment understanding. Experimental results across nine sentiment analysis datasets demonstrate the superiority of our framework over conventional ICL methods, with an average F1 improvement of 5.95%.
NUMCoT: Numerals and Units of Measurement in Chain-of-Thought Reasoning using Large Language Models
Jun 05, 2024



Numeral systems and units of measurement are two conjoined topics in activities of human beings and have mutual effects with the languages expressing them. Currently, the evaluation of Large Language Models (LLMs) often involves mathematical reasoning, yet little attention is given to how minor changes in numbers or units can drastically alter the complexity of problems and the performance of LLMs. In this paper, we scrutinize existing LLMs on processing of numerals and units of measurement by constructing datasets with perturbations. We first anatomize the reasoning of math word problems to different sub-procedures like numeral conversions from language to numbers and measurement conversions based on units. Then we further annotate math word problems from ancient Chinese arithmetic works which are challenging in numerals and units of measurement. Experiments on perturbed datasets demonstrate that LLMs still encounter difficulties in handling numeral and measurement conversions.
Enhancing Noise Robustness of Retrieval-Augmented Language Models with Adaptive Adversarial Training
May 31, 2024



Large Language Models (LLMs) exhibit substantial capabilities yet encounter challenges, including hallucination, outdated knowledge, and untraceable reasoning processes. Retrieval-augmented generation (RAG) has emerged as a promising solution, integrating knowledge from external databases to mitigate these challenges. However, inappropriate retrieved passages can potentially hinder the LLMs' capacity to generate comprehensive and high-quality responses. Prior RAG studies on the robustness of retrieval noises often confine themselves to a limited set of noise types, deviating from real-world retrieval environments and limiting practical applicability. In this study, we initially investigate retrieval noises and categorize them into three distinct types, reflecting real-world environments. We analyze the impact of these various retrieval noises on the robustness of LLMs. Subsequently, we propose a novel RAG approach known as Retrieval-augmented Adaptive Adversarial Training (RAAT). RAAT leverages adaptive adversarial training to dynamically adjust the model's training process in response to retrieval noises. Concurrently, it employs multi-task learning to ensure the model's capacity to internally recognize noisy contexts. Extensive experiments demonstrate that the LLaMA-2 7B model trained using RAAT exhibits significant improvements in F1 and EM scores under diverse noise conditions. For reproducibility, we release our code and data at: https://github.com/calubkk/RAAT.
Long Context is Not Long at All: A Prospector of Long-Dependency Data for Large Language Models
May 28, 2024Long-context modeling capabilities are important for large language models (LLMs) in various applications. However, directly training LLMs with long context windows is insufficient to enhance this capability since some training samples do not exhibit strong semantic dependencies across long contexts. In this study, we propose a data mining framework \textbf{ProLong} that can assign each training sample with a long dependency score, which can be used to rank and filter samples that are more advantageous for enhancing long-context modeling abilities in LLM training. Specifically, we first use delta perplexity scores to measure the \textit{Dependency Strength} between text segments in a given document. Then we refine this metric based on the \textit{Dependency Distance} of these segments to incorporate spatial relationships across long-contexts. Final results are calibrated with a \textit{Dependency Specificity} metric to prevent trivial dependencies introduced by repetitive patterns. Moreover, a random sampling approach is proposed to optimize the computational efficiency of ProLong. Comprehensive experiments on multiple benchmarks indicate that ProLong effectively identifies documents that carry long dependencies and LLMs trained on these documents exhibit significantly enhanced long-context modeling capabilities.