 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJury Learning: Integrating Dissenting Voices into Machine Learning Models
Feb 07, 2022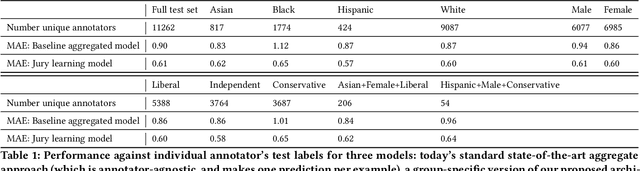


Whose labels should a machine learning (ML) algorithm learn to emulate? For ML tasks ranging from online comment toxicity to misinformation detection to medical diagnosis, different groups in society may have irreconcilable disagreements about ground truth labels. Supervised ML today resolves these label disagreements implicitly using majority vote, which overrides minority groups' labels. We introduce jury learning, a supervised ML approach that resolves these disagreements explicitly through the metaphor of a jury: defining which people or groups, in what proportion, determine the classifier's prediction. For example, a jury learning model for online toxicity might centrally feature women and Black jurors, who are commonly targets of online harassment. To enable jury learning, we contribute a deep learning architecture that models every annotator in a dataset, samples from annotators' models to populate the jury, then runs inference to classify. Our architecture enables juries that dynamically adapt their composition, explore counterfactuals, and visualize dissent.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
My Team Will Go On: Differentiating High and Low Viability Teams through Team Interaction
Nov 03, 2020
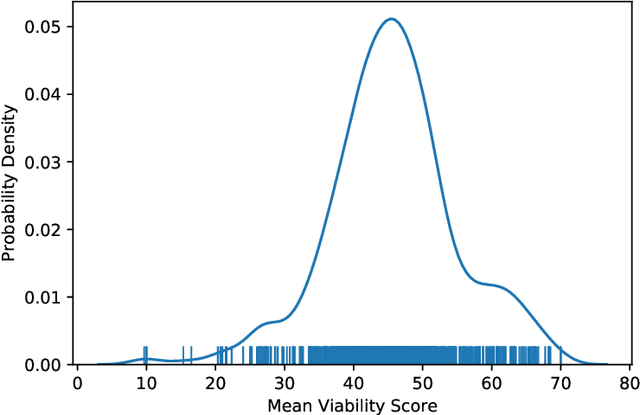
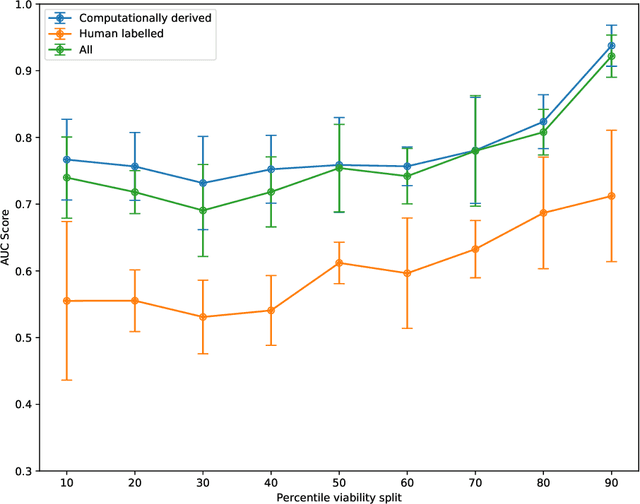
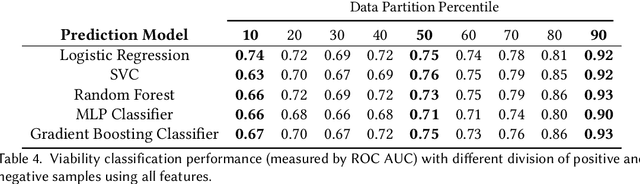
Understanding team viability -- a team's capacity for sustained and future success -- is essential for building effective teams. In this study, we aggregate features drawn from the organizational behavior literature to train a viability classification model over a dataset of 669 10-minute text conversations of online teams. We train classifiers to identify teams at the top decile (most viable teams), 50th percentile (above a median split), and bottom decile (least viable teams), then characterize the attributes of teams at each of these viability levels. We find that a lasso regression model achieves an accuracy of .74--.92 AUC ROC under different thresholds of classifying viability scores. From these models, we identify the use of exclusive language such as `but' and `except', and the use of second person pronouns, as the most predictive features for detecting the most viable teams, suggesting that active engagement with others' ideas is a crucial signal of a viable team. Only a small fraction of the 10-minute discussion, as little as 70 seconds, is required for predicting the viability of team interaction. This work suggests opportunities for teams to assess, track, and visualize their own viability in real time as they collaborate.
* CSCW 2020 Honorable Mention Award
Establishing an Evaluation Metric to Quantify Climate Change Image Realism
Oct 22, 2019

With success on controlled tasks, generative models are being increasingly applied to humanitarian applications [1,2]. In this paper, we focus on the evaluation of a conditional generative model that illustrates the consequences of climate change-induced flooding to encourage public interest and awareness on the issue. Because metrics for comparing the realism of different modes in a conditional generative model do not exist, we propose several automated and human-based methods for evaluation. To do this, we adapt several existing metrics, and assess the automated metrics against gold standard human evaluation. We find that using Fr\'echet Inception Distance (FID) with embeddings from an intermediary Inception-V3 layer that precedes the auxiliary classifier produces results most correlated with human realism. While insufficient alone to establish a human-correlated automatic evaluation metric, we believe this work begins to bridge the gap between human and automated generative evaluation procedures.
HYPE: Human eYe Perceptual Evaluation of Generative Models
Apr 24, 2019


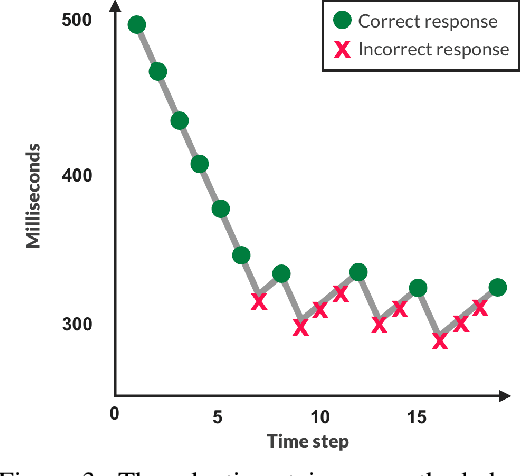
Generative models often use human evaluations to determine and justify progress. Unfortunately, existing human evaluation methods are ad-hoc: there is currently no standardized, validated evaluation that: (1) measures perceptual fidelity, (2) is reliable, (3) separates models into clear rank order, and (4) ensures high-quality measurement without intractable cost. In response, we construct Human-eYe Perceptual Evaluation (HYPE), a human metric that is (1) grounded in psychophysics research in perception, (2) reliable across different sets of randomly sampled outputs from a model, (3) results in separable model performances, and (4) efficient in cost and time. We introduce two methods. The first, HYPE-Time, measures visual perception under adaptive time constraints to determine the minimum length of time (e.g., 250ms) that model output such as a generated face needs to be visible for people to distinguish it as real or fake. The second, HYPE-Infinity, measures human error rate on fake and real images with no time constraints, maintaining stability and drastically reducing time and cost. We test HYPE across four state-of-the-art generative adversarial networks (GANs) on unconditional image generation using two datasets, the popular CelebA and the newer higher-resolution FFHQ, and two sampling techniques of model outputs. By simulating HYPE's evaluation multiple times, we demonstrate consistent ranking of different models, identifying StyleGAN with truncation trick sampling (27.6% HYPE-Infinity deception rate, with roughly one quarter of images being misclassified by humans) as superior to StyleGAN without truncation (19.0%) on FFHQ. See https://hype.stanford.edu for details.
A Glimpse Far into the Future: Understanding Long-term Crowd Worker Quality
Nov 01, 2016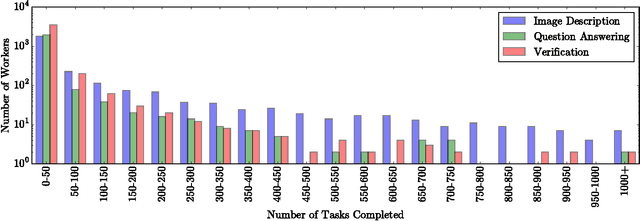

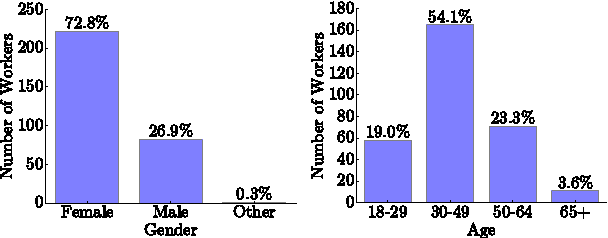
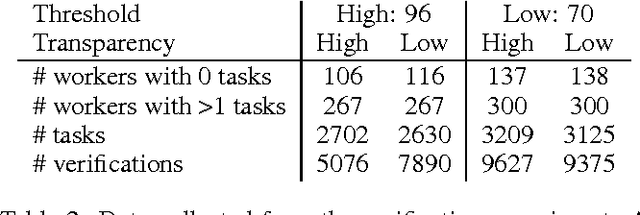
Microtask crowdsourcing is increasingly critical to the creation of extremely large datasets. As a result, crowd workers spend weeks or months repeating the exact same tasks, making it necessary to understand their behavior over these long periods of time. We utilize three large, longitudinal datasets of nine million annotations collected from Amazon Mechanical Turk to examine claims that workers fatigue or satisfice over these long periods, producing lower quality work. We find that, contrary to these claims, workers are extremely stable in their quality over the entire period. To understand whether workers set their quality based on the task's requirements for acceptance, we then perform an experiment where we vary the required quality for a large crowdsourcing task. Workers did not adjust their quality based on the acceptance threshold: workers who were above the threshold continued working at their usual quality level, and workers below the threshold self-selected themselves out of the task. Capitalizing on this consistency, we demonstrate that it is possible to predict workers' long-term quality using just a glimpse of their quality on the first five tasks.
Shirtless and Dangerous: Quantifying Linguistic Signals of Gender Bias in an Online Fiction Writing Community
Mar 29, 2016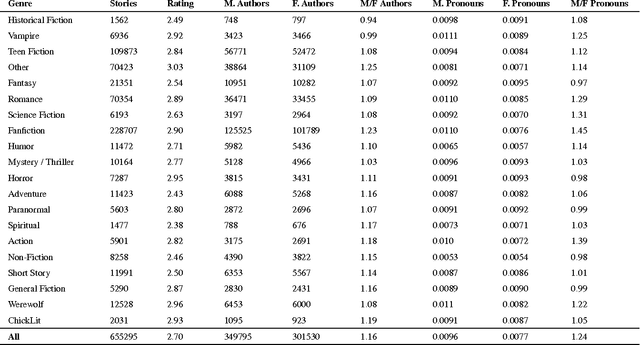
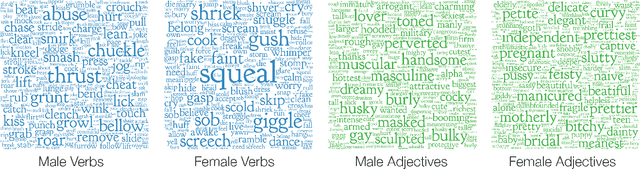
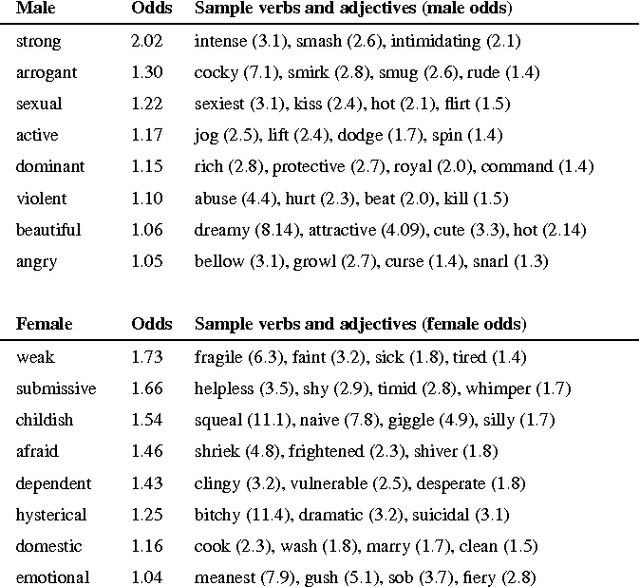
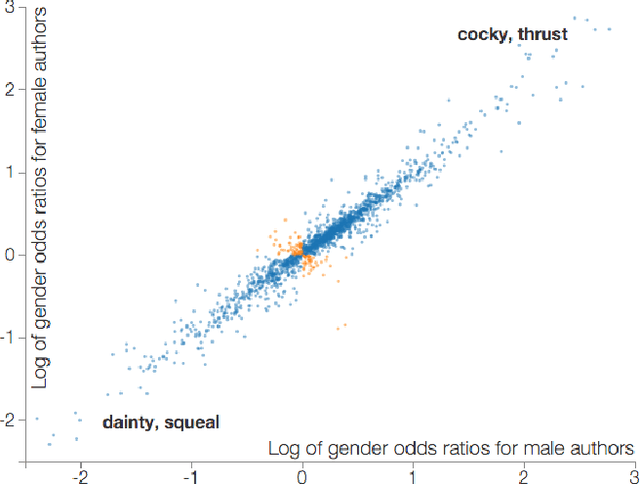
Imagine a princess asleep in a castle, waiting for her prince to slay the dragon and rescue her. Tales like the famous Sleeping Beauty clearly divide up gender roles. But what about more modern stories, borne of a generation increasingly aware of social constructs like sexism and racism? Do these stories tend to reinforce gender stereotypes, or counter them? In this paper, we present a technique that combines natural language processing with a crowdsourced lexicon of stereotypes to capture gender biases in fiction. We apply this technique across 1.8 billion words of fiction from the Wattpad online writing community, investigating gender representation in stories, how male and female characters behave and are described, and how authors' use of gender stereotypes is associated with the community's ratings. We find that male over-representation and traditional gender stereotypes (e.g., dominant men and submissive women) are common throughout nearly every genre in our corpus. However, only some of these stereotypes, like sexual or violent men, are associated with highly rated stories. Finally, despite women often being the target of negative stereotypes, female authors are equally likely to write such stereotypes as men.
Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations
Feb 23, 2016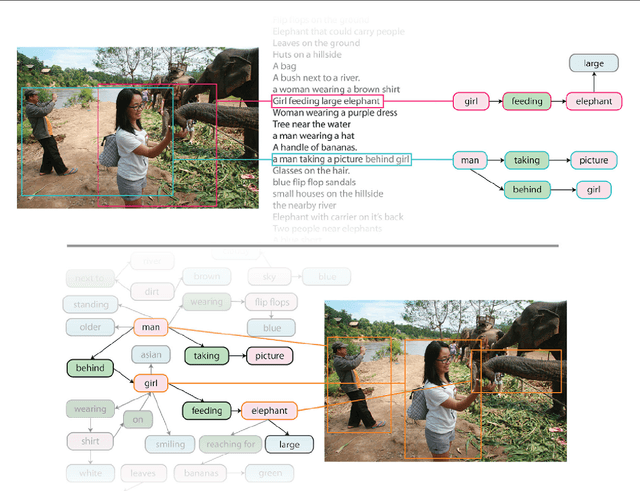
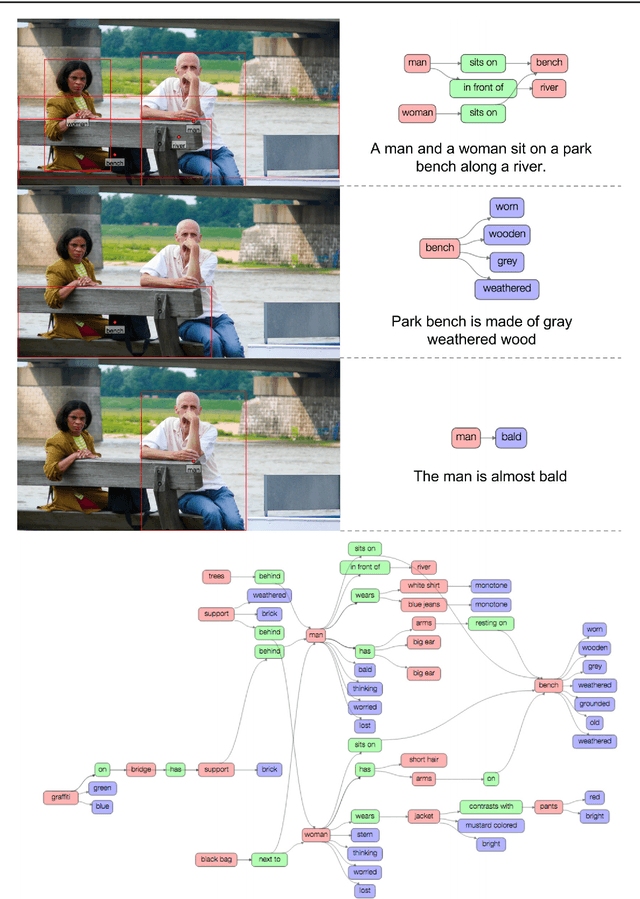

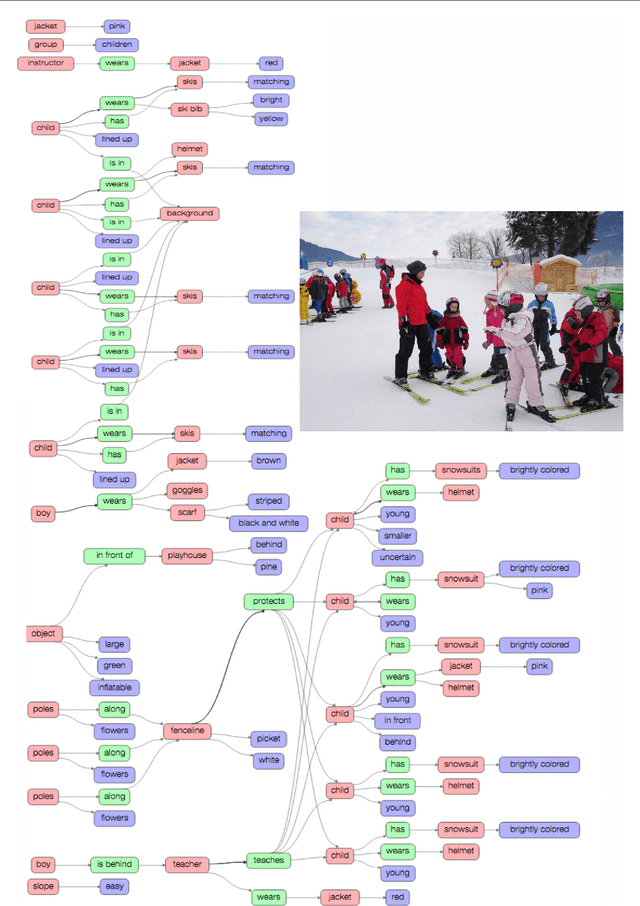
Despite progress in perceptual tasks such as image classification, computers still perform poorly on cognitive tasks such as image description and question answering. Cognition is core to tasks that involve not just recognizing, but reasoning about our visual world. However, models used to tackle the rich content in images for cognitive tasks are still being trained using the same datasets designed for perceptual tasks. To achieve success at cognitive tasks, models need to understand the interactions and relationships between objects in an image. When asked "What vehicle is the person riding?", computers will need to identify the objects in an image as well as the relationships riding(man, carriage) and pulling(horse, carriage) in order to answer correctly that "the person is riding a horse-drawn carriage". In this paper, we present the Visual Genome dataset to enable the modeling of such relationships. We collect dense annotations of objects, attributes, and relationships within each image to learn these models. Specifically, our dataset contains over 100K images where each image has an average of 21 objects, 18 attributes, and 18 pairwise relationships between objects. We canonicalize the objects, attributes, relationships, and noun phrases in region descriptions and questions answer pairs to WordNet synsets. Together, these annotations represent the densest and largest dataset of image descriptions, objects, attributes, relationships, and question answers.
Embracing Error to Enable Rapid Crowdsourcing
Feb 14, 2016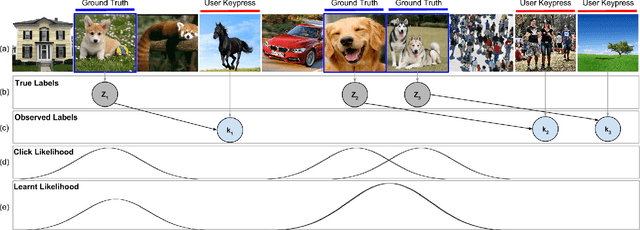
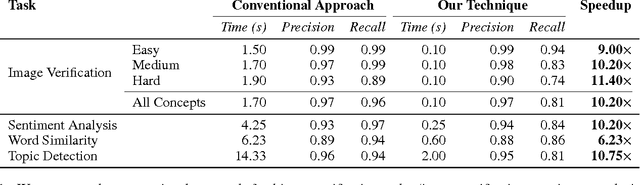
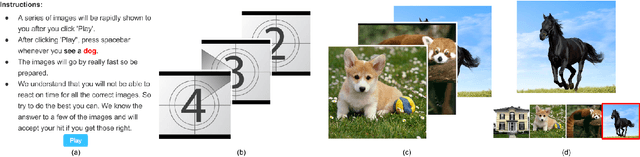

Microtask crowdsourcing has enabled dataset advances in social science and machine learning, but existing crowdsourcing schemes are too expensive to scale up with the expanding volume of data. To scale and widen the applicability of crowdsourcing, we present a technique that produces extremely rapid judgments for binary and categorical labels. Rather than punishing all errors, which causes workers to proceed slowly and deliberately, our technique speeds up workers' judgments to the point where errors are acceptable and even expected. We demonstrate that it is possible to rectify these errors by randomizing task order and modeling response latency. We evaluate our technique on a breadth of common labeling tasks such as image verification, word similarity, sentiment analysis and topic classification. Where prior work typically achieves a 0.25x to 1x speedup over fixed majority vote, our approach often achieves an order of magnitude (10x) speedup.