 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttuneBench: A Conversation-Based Benchmark for LLM Emotional Intelligence
May 20, 2026Emotional intelligence (EI), the ability to perceive, understand, and respond appropriately to others' emotional states, is central to human communication, and increasingly important to assess as LLMs assume conversational roles in everyday life. Existing EI benchmarks rely on synthetic prompts, single-turn cases, or third-party annotation. These approaches do not directly measure how models infer and respond to a participant's emotional state over the course of a real conversation. We introduce AttuneBench, a benchmark grounded in 200 genuine multi-turn human-model conversations in which participants conversed with anonymized LLMs and provided turn-by-turn annotations of their emotional state, the model's behavior, and their preferred responses. Across 11 evaluated models, we find that model rankings on emotion recognition, behavioral classification, preference prediction, and judged response quality are largely independent, indicating that emotionally intelligent behavior decomposes into separable capabilities. Preference alignment and response-quality judgments are substantially more model-discriminating than emotion-label accuracy. These results indicate that emotionally intelligent behavior requires predicting what kind of response a specific user wants in context, a distinction that aggregate scoring can obscure and that single-turn or synthetic formats cannot directly capture across turns. AttuneBench provides a framework for assessing each of these capabilities and for diagnosing model-specific strengths and failure modes in emotionally salient conversation.
Empirically evaluating commonsense intelligence in large language models with large-scale human judgments
May 15, 2025



Commonsense intelligence in machines is often assessed by static benchmarks that compare a model's output against human-prescribed correct labels. An important, albeit implicit, assumption of these labels is that they accurately capture what any human would think, effectively treating human common sense as homogeneous. However, recent empirical work has shown that humans vary enormously in what they consider commonsensical; thus what appears self-evident to one benchmark designer may not be so to another. Here, we propose a novel method for evaluating common sense in artificial intelligence (AI), specifically in large language models (LLMs), that incorporates empirically observed heterogeneity among humans by measuring the correspondence between a model's judgment and that of a human population. We first find that, when treated as independent survey respondents, most LLMs remain below the human median in their individual commonsense competence. Second, when used as simulators of a hypothetical population, LLMs correlate with real humans only modestly in the extent to which they agree on the same set of statements. In both cases, smaller, open-weight models are surprisingly more competitive than larger, proprietary frontier models. Our evaluation framework, which ties commonsense intelligence to its cultural basis, contributes to the growing call for adapting AI models to human collectivities that possess different, often incompatible, social stocks of knowledge.
My Team Will Go On: Differentiating High and Low Viability Teams through Team Interaction
Nov 03, 2020
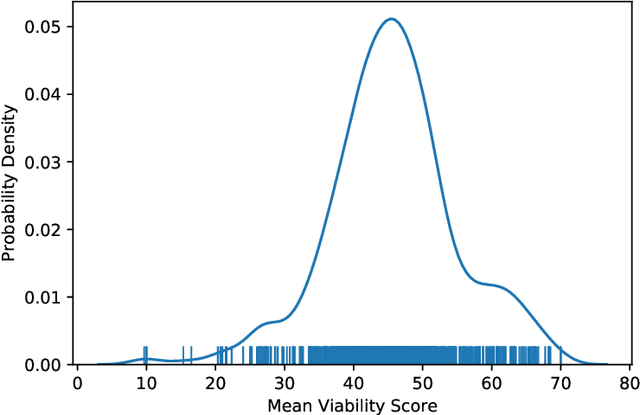
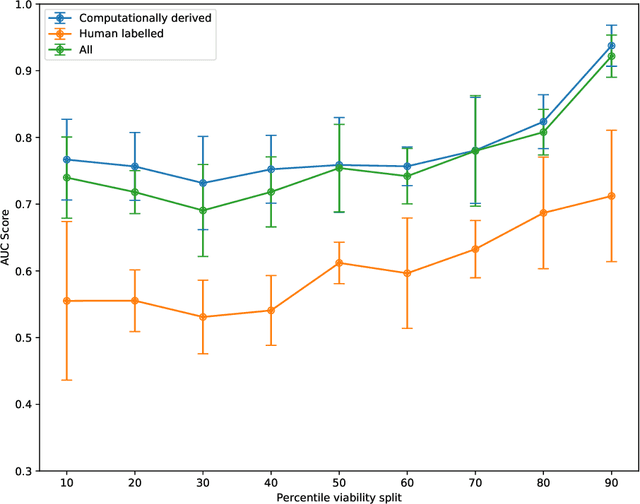
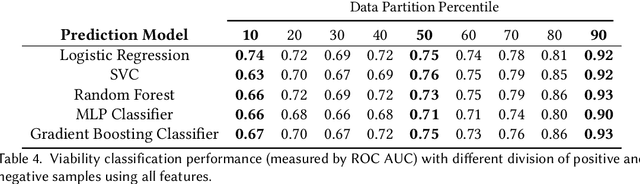
Understanding team viability -- a team's capacity for sustained and future success -- is essential for building effective teams. In this study, we aggregate features drawn from the organizational behavior literature to train a viability classification model over a dataset of 669 10-minute text conversations of online teams. We train classifiers to identify teams at the top decile (most viable teams), 50th percentile (above a median split), and bottom decile (least viable teams), then characterize the attributes of teams at each of these viability levels. We find that a lasso regression model achieves an accuracy of .74--.92 AUC ROC under different thresholds of classifying viability scores. From these models, we identify the use of exclusive language such as `but' and `except', and the use of second person pronouns, as the most predictive features for detecting the most viable teams, suggesting that active engagement with others' ideas is a crucial signal of a viable team. Only a small fraction of the 10-minute discussion, as little as 70 seconds, is required for predicting the viability of team interaction. This work suggests opportunities for teams to assess, track, and visualize their own viability in real time as they collaborate.
* CSCW 2020 Honorable Mention Award