 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIris: A Conversational Agent for Complex Tasks
Jul 17, 2017
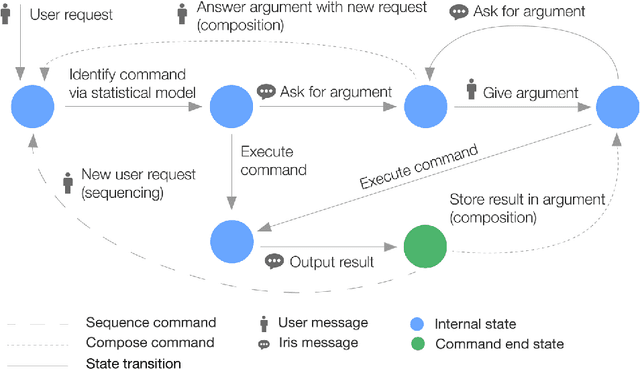

Today's conversational agents are restricted to simple standalone commands. In this paper, we present Iris, an agent that draws on human conversational strategies to combine commands, allowing it to perform more complex tasks that it has not been explicitly designed to support: for example, composing one command to "plot a histogram" with another to first "log-transform the data". To enable this complexity, we introduce a domain specific language that transforms commands into automata that Iris can compose, sequence, and execute dynamically by interacting with a user through natural language, as well as a conversational type system that manages what kinds of commands can be combined. We have designed Iris to help users with data science tasks, a domain that requires support for command combination. In evaluation, we find that data scientists complete a predictive modeling task significantly faster (2.6 times speedup) with Iris than a modern non-conversational programming environment. Iris supports the same kinds of commands as today's agents, but empowers users to weave together these commands to accomplish complex goals.
Long-Term Trends in the Public Perception of Artificial Intelligence
Dec 02, 2016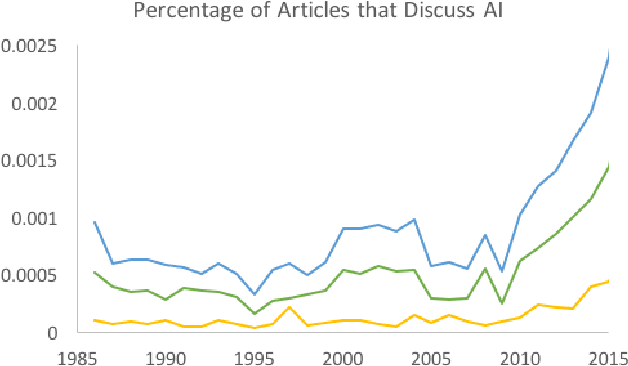
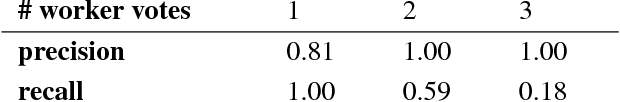

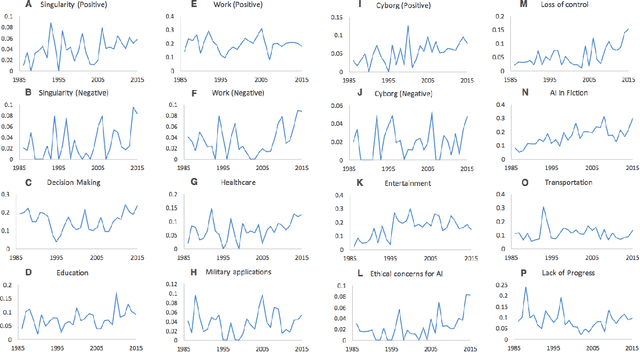
Analyses of text corpora over time can reveal trends in beliefs, interest, and sentiment about a topic. We focus on views expressed about artificial intelligence (AI) in the New York Times over a 30-year period. General interest, awareness, and discussion about AI has waxed and waned since the field was founded in 1956. We present a set of measures that captures levels of engagement, measures of pessimism and optimism, the prevalence of specific hopes and concerns, and topics that are linked to discussions about AI over decades. We find that discussion of AI has increased sharply since 2009, and that these discussions have been consistently more optimistic than pessimistic. However, when we examine specific concerns, we find that worries of loss of control of AI, ethical concerns for AI, and the negative impact of AI on work have grown in recent years. We also find that hopes for AI in healthcare and education have increased over time.
Identifying Dogmatism in Social Media: Signals and Models
Sep 01, 2016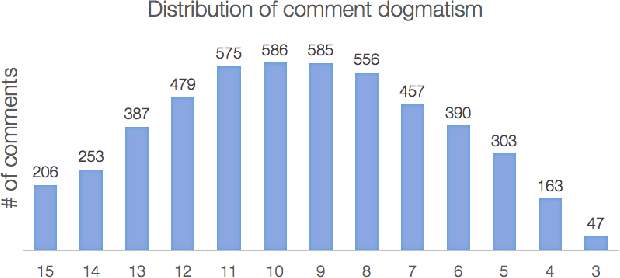
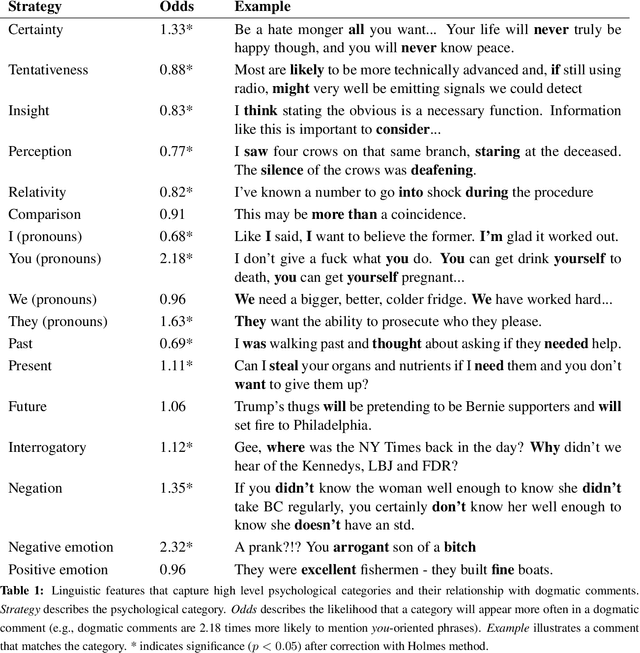
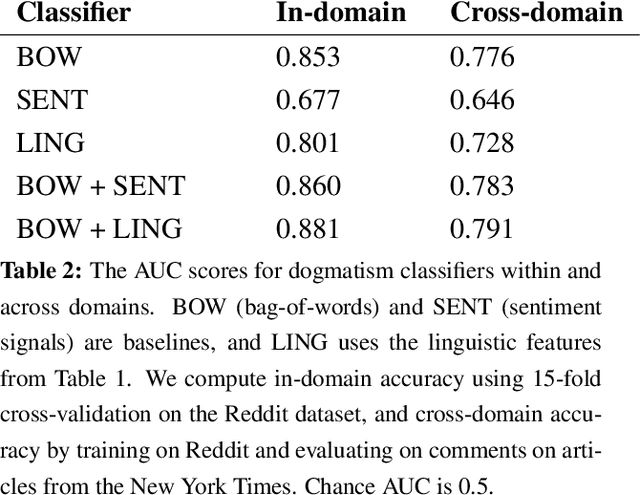
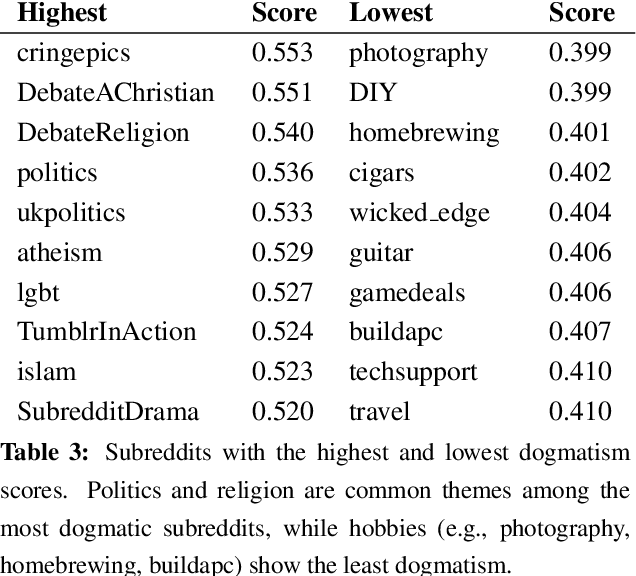
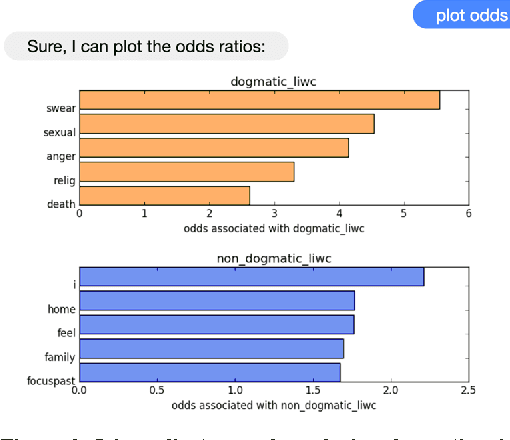
We explore linguistic and behavioral features of dogmatism in social media and construct statistical models that can identify dogmatic comments. Our model is based on a corpus of Reddit posts, collected across a diverse set of conversational topics and annotated via paid crowdsourcing. We operationalize key aspects of dogmatism described by existing psychology theories (such as over-confidence), finding they have predictive power. We also find evidence for new signals of dogmatism, such as the tendency of dogmatic posts to refrain from signaling cognitive processes. When we use our predictive model to analyze millions of other Reddit posts, we find evidence that suggests dogmatism is a deeper personality trait, present for dogmatic users across many different domains, and that users who engage on dogmatic comments tend to show increases in dogmatic posts themselves.
Shirtless and Dangerous: Quantifying Linguistic Signals of Gender Bias in an Online Fiction Writing Community
Mar 29, 2016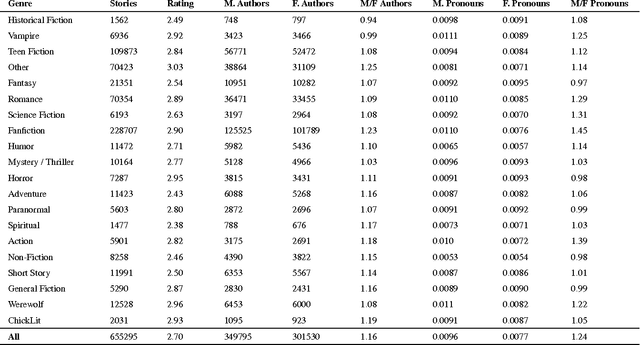
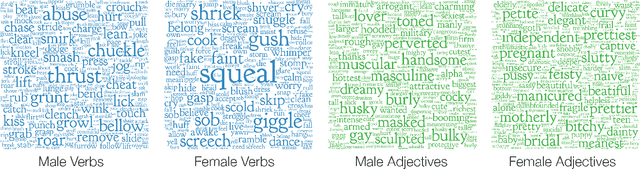
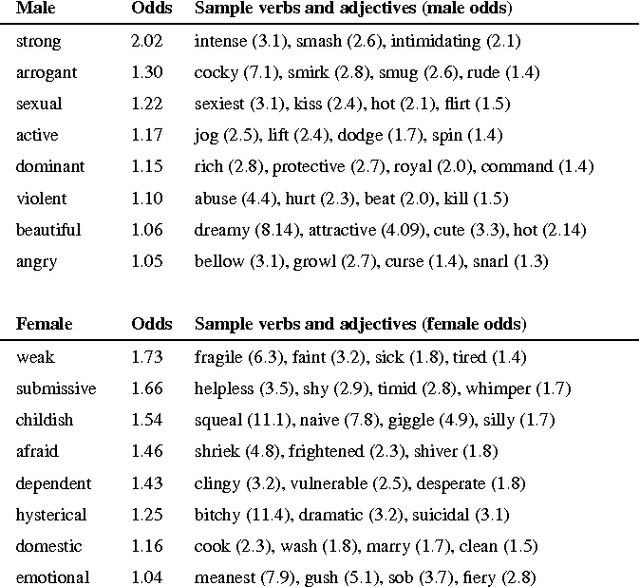
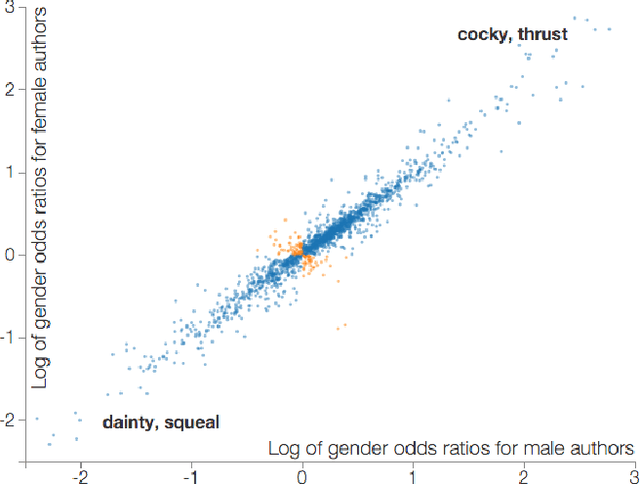
Imagine a princess asleep in a castle, waiting for her prince to slay the dragon and rescue her. Tales like the famous Sleeping Beauty clearly divide up gender roles. But what about more modern stories, borne of a generation increasingly aware of social constructs like sexism and racism? Do these stories tend to reinforce gender stereotypes, or counter them? In this paper, we present a technique that combines natural language processing with a crowdsourced lexicon of stereotypes to capture gender biases in fiction. We apply this technique across 1.8 billion words of fiction from the Wattpad online writing community, investigating gender representation in stories, how male and female characters behave and are described, and how authors' use of gender stereotypes is associated with the community's ratings. We find that male over-representation and traditional gender stereotypes (e.g., dominant men and submissive women) are common throughout nearly every genre in our corpus. However, only some of these stereotypes, like sexual or violent men, are associated with highly rated stories. Finally, despite women often being the target of negative stereotypes, female authors are equally likely to write such stereotypes as men.
Augur: Mining Human Behaviors from Fiction to Power Interactive Systems
Feb 25, 2016
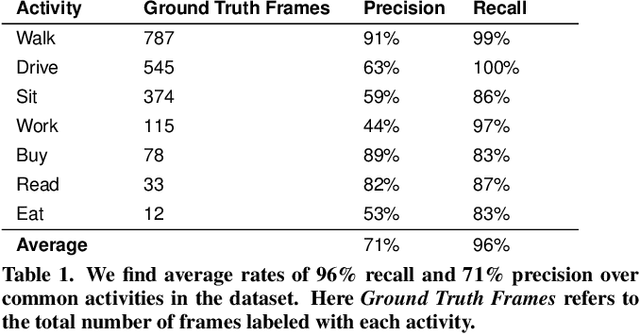


From smart homes that prepare coffee when we wake, to phones that know not to interrupt us during important conversations, our collective visions of HCI imagine a future in which computers understand a broad range of human behaviors. Today our systems fall short of these visions, however, because this range of behaviors is too large for designers or programmers to capture manually. In this paper, we instead demonstrate it is possible to mine a broad knowledge base of human behavior by analyzing more than one billion words of modern fiction. Our resulting knowledge base, Augur, trains vector models that can predict many thousands of user activities from surrounding objects in modern contexts: for example, whether a user may be eating food, meeting with a friend, or taking a selfie. Augur uses these predictions to identify actions that people commonly take on objects in the world and estimate a user's future activities given their current situation. We demonstrate Augur-powered, activity-based systems such as a phone that silences itself when the odds of you answering it are low, and a dynamic music player that adjusts to your present activity. A field deployment of an Augur-powered wearable camera resulted in 96% recall and 71% precision on its unsupervised predictions of common daily activities. A second evaluation where human judges rated the system's predictions over a broad set of input images found that 94% were rated sensible.
Empath: Understanding Topic Signals in Large-Scale Text
Feb 22, 2016

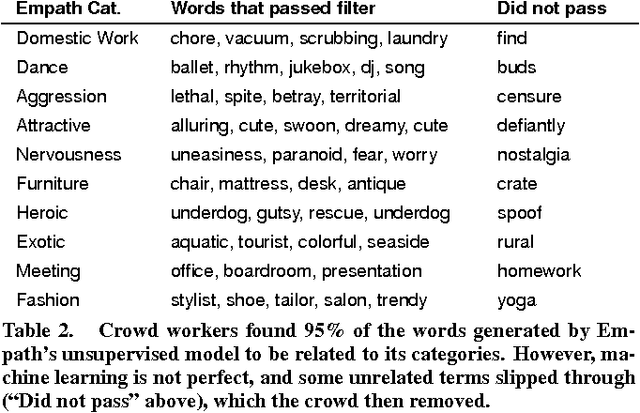

Human language is colored by a broad range of topics, but existing text analysis tools only focus on a small number of them. We present Empath, a tool that can generate and validate new lexical categories on demand from a small set of seed terms (like "bleed" and "punch" to generate the category violence). Empath draws connotations between words and phrases by deep learning a neural embedding across more than 1.8 billion words of modern fiction. Given a small set of seed words that characterize a category, Empath uses its neural embedding to discover new related terms, then validates the category with a crowd-powered filter. Empath also analyzes text across 200 built-in, pre-validated categories we have generated from common topics in our web dataset, like neglect, government, and social media. We show that Empath's data-driven, human validated categories are highly correlated (r=0.906) with similar categories in LIWC.