 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThrough the Looking-Glass: AI-Mediated Video Communication Reduces Interpersonal Trust and Confidence in Judgments
Mar 19, 2026AI-based tools that mediate, enhance or generate parts of video communication may interfere with how people evaluate trustworthiness and credibility. In two preregistered online experiments (N = 2,000), we examined whether AI-mediated video retouching, background replacement and avatars affect interpersonal trust, people's ability to detect lies and confidence in their judgments. Participants watched short videos of speakers making truthful or deceptive statements across three conditions with varying levels of AI mediation. We observed that perceived trust and confidence in judgments declined in AI-mediated videos, particularly in settings in which some participants used avatars while others did not. However, participants' actual judgment accuracy remained unchanged, and they were no more inclined to suspect those using AI tools of lying. Our findings provide evidence against concerns that AI mediation undermines people's ability to distinguish truth from lies, and against cue-based accounts of lie detection more generally. They highlight the importance of trustworthy AI mediation tools in contexts where not only truth, but also trust and confidence matter.
Social Media Algorithms Can Shape Affective Polarization via Exposure to Antidemocratic Attitudes and Partisan Animosity
Nov 22, 2024



There is widespread concern about the negative impacts of social media feed ranking algorithms on political polarization. Leveraging advancements in large language models (LLMs), we develop an approach to re-rank feeds in real-time to test the effects of content that is likely to polarize: expressions of antidemocratic attitudes and partisan animosity (AAPA). In a preregistered 10-day field experiment on X/Twitter with 1,256 consented participants, we increase or decrease participants' exposure to AAPA in their algorithmically curated feeds. We observe more positive outparty feelings when AAPA exposure is decreased and more negative outparty feelings when AAPA exposure is increased. Exposure to AAPA content also results in an immediate increase in negative emotions, such as sadness and anger. The interventions do not significantly impact traditional engagement metrics such as re-post and favorite rates. These findings highlight a potential pathway for developing feed algorithms that mitigate affective polarization by addressing content that undermines the shared values required for a healthy democracy.
Jury Learning: Integrating Dissenting Voices into Machine Learning Models
Feb 07, 2022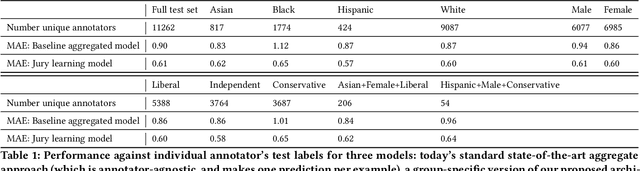

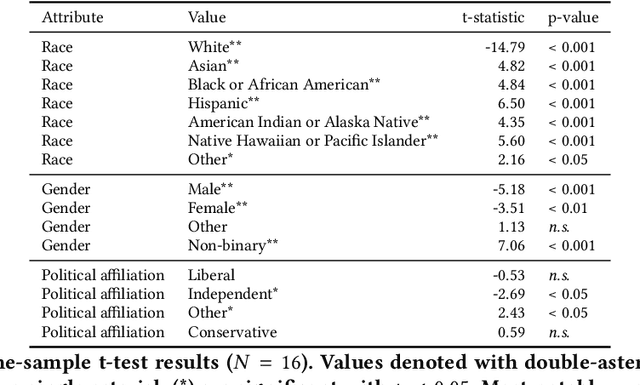

Whose labels should a machine learning (ML) algorithm learn to emulate? For ML tasks ranging from online comment toxicity to misinformation detection to medical diagnosis, different groups in society may have irreconcilable disagreements about ground truth labels. Supervised ML today resolves these label disagreements implicitly using majority vote, which overrides minority groups' labels. We introduce jury learning, a supervised ML approach that resolves these disagreements explicitly through the metaphor of a jury: defining which people or groups, in what proportion, determine the classifier's prediction. For example, a jury learning model for online toxicity might centrally feature women and Black jurors, who are commonly targets of online harassment. To enable jury learning, we contribute a deep learning architecture that models every annotator in a dataset, samples from annotators' models to populate the jury, then runs inference to classify. Our architecture enables juries that dynamically adapt their composition, explore counterfactuals, and visualize dissent.
Finding Deceptive Opinion Spam by Any Stretch of the Imagination
Jul 22, 2011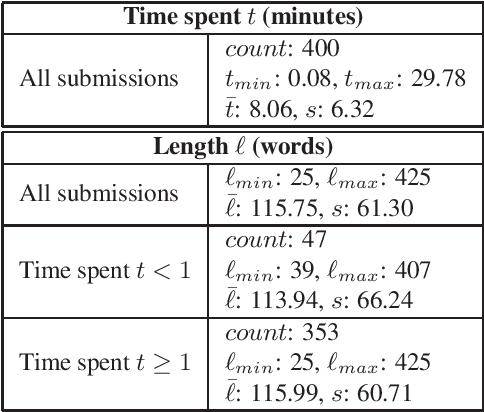
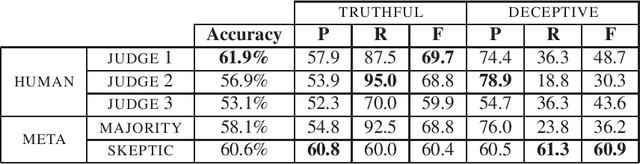
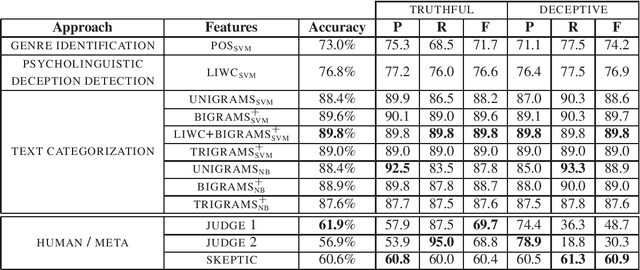
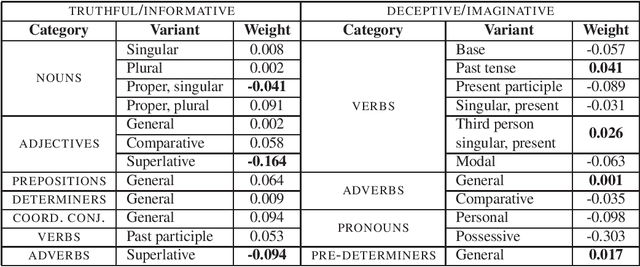
Consumers increasingly rate, review and research products online. Consequently, websites containing consumer reviews are becoming targets of opinion spam. While recent work has focused primarily on manually identifiable instances of opinion spam, in this work we study deceptive opinion spam---fictitious opinions that have been deliberately written to sound authentic. Integrating work from psychology and computational linguistics, we develop and compare three approaches to detecting deceptive opinion spam, and ultimately develop a classifier that is nearly 90% accurate on our gold-standard opinion spam dataset. Based on feature analysis of our learned models, we additionally make several theoretical contributions, including revealing a relationship between deceptive opinions and imaginative writing.
* 11 pages, 5 tables, data available at: http://www.cs.cornell.edu/~myleott