 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Conceptual Multiverse
Apr 21, 2026When language models answer open-ended problems, they implicitly make hidden decisions that shape their outputs, leaving users with uncontextualized answers rather than a working map of the problem; drawing on multiverse analysis from statistics, we build and evaluate the conceptual multiverse, an interactive system that represents conceptual decisions such as how to frame a question or what to value as a space users can transparently inspect, intervenably change, and check against principled domain reasoning; for this structure to be worth navigating rather than misleading, it must be rigorous and checkable against domain reasoning norms, so we develop a general verification framework that enforces properties of good decision structures like unambiguity and completeness calibrated by expert-level reasoning; across three domains, the conceptual multiverse helped participants develop a working map of the problem, with philosophy students rewriting essays with sharper framings and reversed theses, alignment annotators moving from surface preferences to reasoning about user intent and harm, and poets identifying compositional patterns that clarified their taste.
Jury Learning: Integrating Dissenting Voices into Machine Learning Models
Feb 07, 2022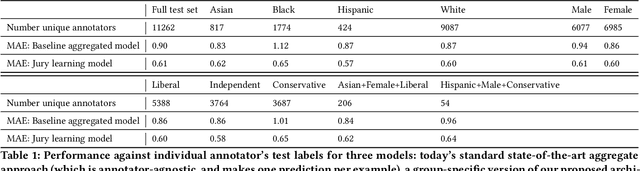

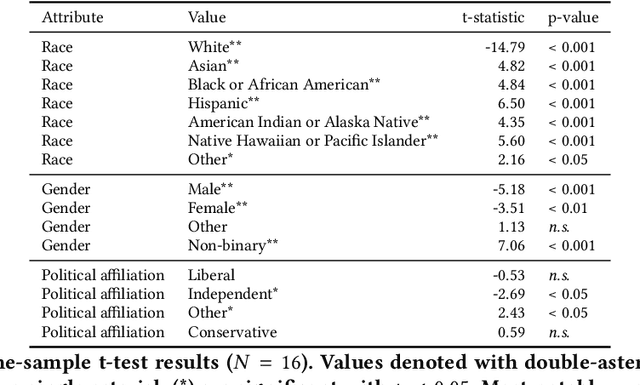

Whose labels should a machine learning (ML) algorithm learn to emulate? For ML tasks ranging from online comment toxicity to misinformation detection to medical diagnosis, different groups in society may have irreconcilable disagreements about ground truth labels. Supervised ML today resolves these label disagreements implicitly using majority vote, which overrides minority groups' labels. We introduce jury learning, a supervised ML approach that resolves these disagreements explicitly through the metaphor of a jury: defining which people or groups, in what proportion, determine the classifier's prediction. For example, a jury learning model for online toxicity might centrally feature women and Black jurors, who are commonly targets of online harassment. To enable jury learning, we contribute a deep learning architecture that models every annotator in a dataset, samples from annotators' models to populate the jury, then runs inference to classify. Our architecture enables juries that dynamically adapt their composition, explore counterfactuals, and visualize dissent.