 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
Global Error Bounds and Linear Convergence for Gradient-Based Algorithms for Trend Filtering and $\ell_{1}$-Convex Clustering
Apr 16, 2019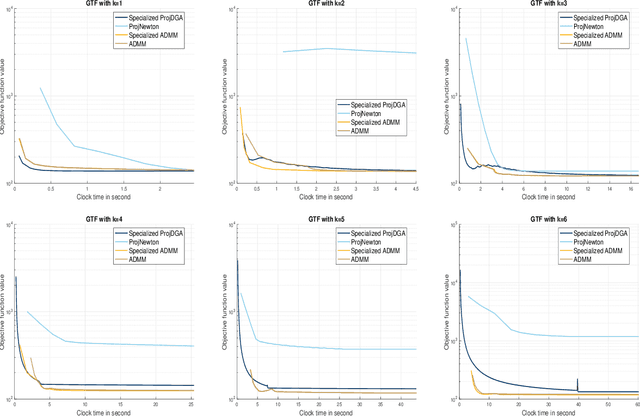
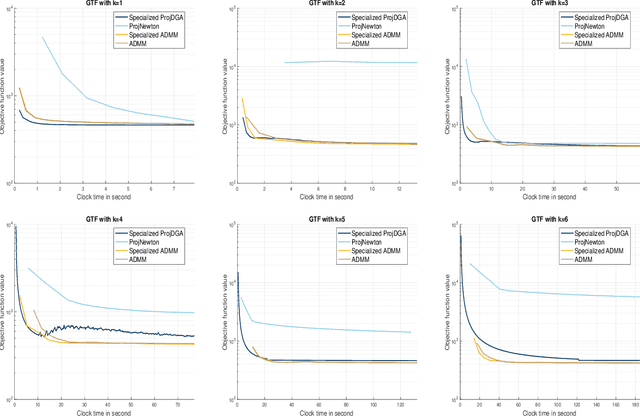
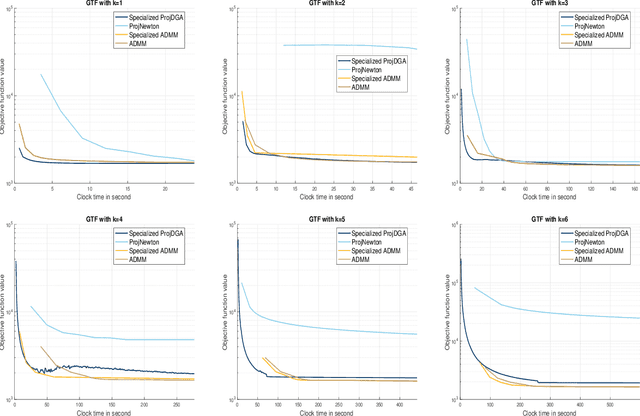
We propose a class of first-order gradient-type optimization algorithms to solve structured \textit{filtering-clustering problems}, a class of problems which include trend filtering and $\ell_1$-convex clustering as special cases. Our first main result establishes the linear convergence of deterministic gradient-type algorithms despite the extreme ill-conditioning of the difference operator matrices in these problems. This convergence result is based on a convex-concave saddle point formulation of filtering-clustering problems and the fact that the dual form of the problem admits a global error bound, a result which is based on the celebrated Hoffman bound for the distance between a point and its projection onto an optimal set. The linear convergence rate also holds for stochastic variance reduction gradient-type algorithms. Finally, we present empirical results to show that the algorithms that we analyze perform comparable to state-of-the-art algorithms for trend filtering, while presenting advantages for scalability.
Bridging Theory and Algorithm for Domain Adaptation
Apr 11, 2019



This paper addresses the problem of unsupervised domain adaption from theoretical and algorithmic perspectives. Existing domain adaptation theories naturally imply minimax optimization algorithms, which connect well with the adversarial-learning based domain adaptation methods. However, several disconnections still form the gap between theory and algorithm. We extend previous theories (Ben-David et al., 2010; Mansour et al., 2009c) to multiclass classification in domain adaptation, where classifiers based on scoring functions and margin loss are standard algorithmic choices. We introduce a novel measurement, margin disparity discrepancy, that is tailored both to distribution comparison with asymmetric margin loss, and to minimax optimization for easier training. Using this discrepancy, we derive new generalization bounds in terms of Rademacher complexity. Our theory can be seamlessly transformed into an adversarial learning algorithm for domain adaptation, successfully bridging the gap between theory and algorithm. A series of empirical studies show that our algorithm achieves the state-of-the-art accuracies on challenging domain adaptation tasks.
Boundary Attack++: Query-Efficient Decision-Based Adversarial Attack
Apr 03, 2019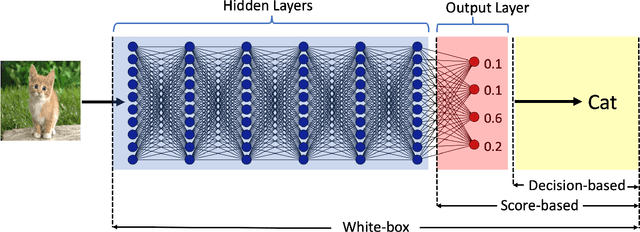
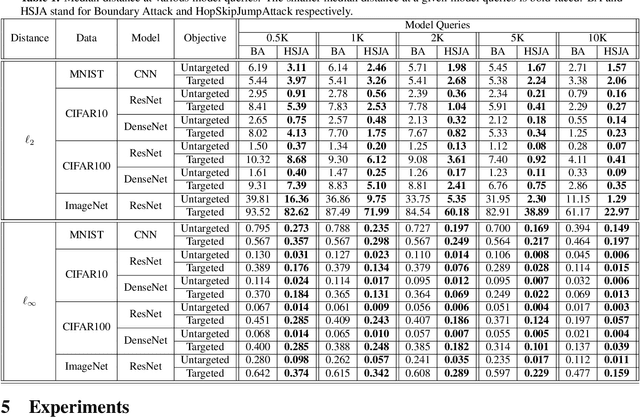
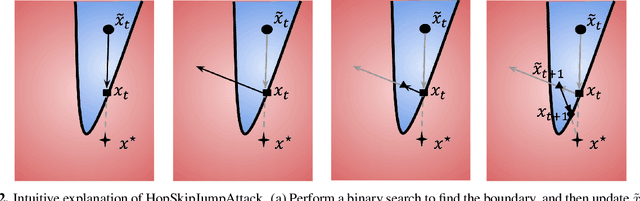
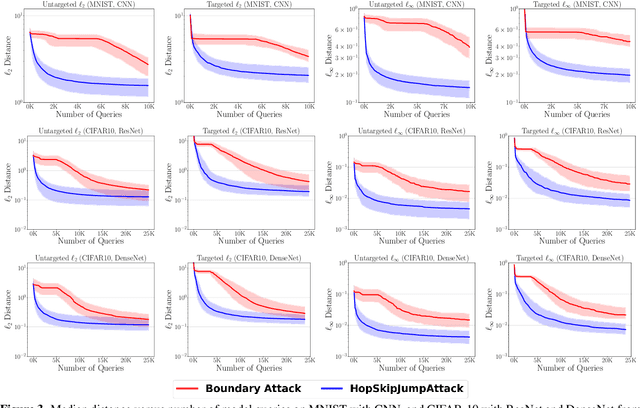
Decision-based adversarial attack studies the generation of adversarial examples that solely rely on output labels of a target model. In this paper, decision-based adversarial attack was formulated as an optimization problem. Motivated by zeroth-order optimization, we develop Boundary Attack++, a family of algorithms based on a novel estimate of gradient direction using binary information at the decision boundary. By switching between two types of projection operators, our algorithms are capable of optimizing $L_2$ and $L_\infty$ distances respectively. Experiments show Boundary Attack++ requires significantly fewer model queries than Boundary Attack. We also show our algorithm achieves superior performance compared to state-of-the-art white-box algorithms in attacking adversarially trained models on MNIST.
Stochastic Gradient Descent Escapes Saddle Points Efficiently
Feb 13, 2019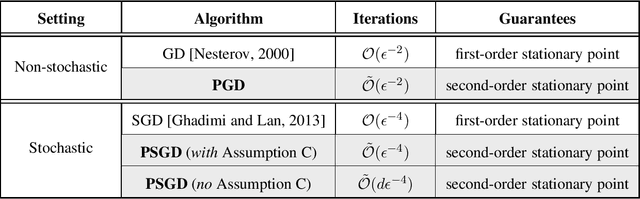
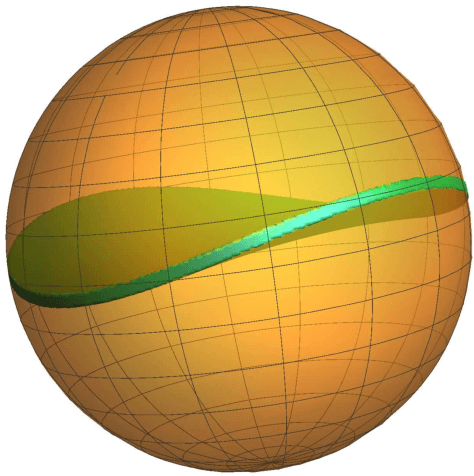
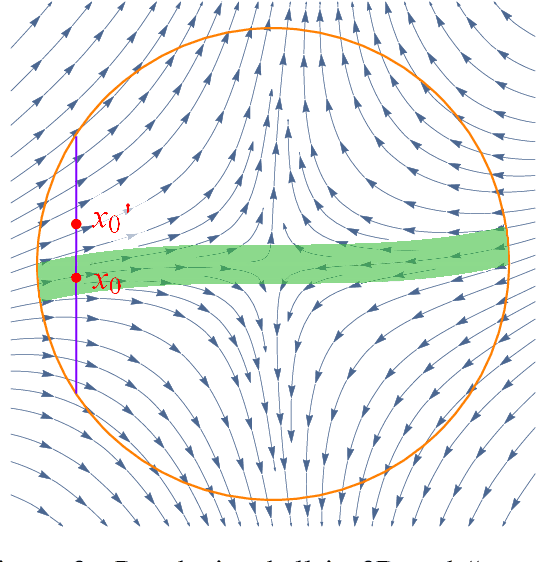
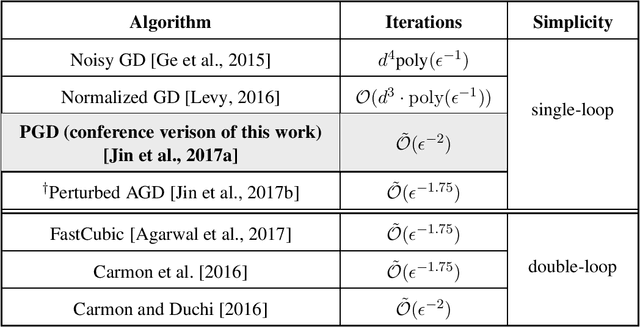
This paper considers the perturbed stochastic gradient descent algorithm and shows that it finds $\epsilon$-second order stationary points ($\left\|\nabla f(x)\right\|\leq \epsilon$ and $\nabla^2 f(x) \succeq -\sqrt{\epsilon} \mathbf{I}$) in $\tilde{O}(d/\epsilon^4)$ iterations, giving the first result that has linear dependence on dimension for this setting. For the special case, where stochastic gradients are Lipschitz, the dependence on dimension reduces to polylogarithmic. In addition to giving new results, this paper also presents a simplified proof strategy that gives a shorter and more elegant proof of previously known results (Jin et al. 2017) on perturbed gradient descent algorithm.
LS-Tree: Model Interpretation When the Data Are Linguistic
Feb 11, 2019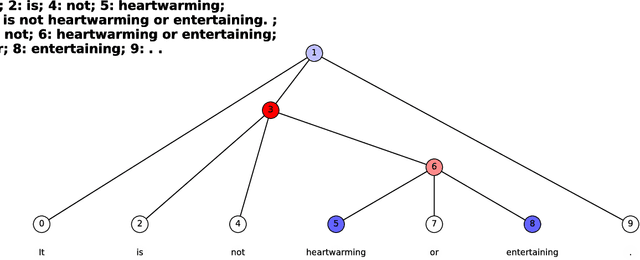
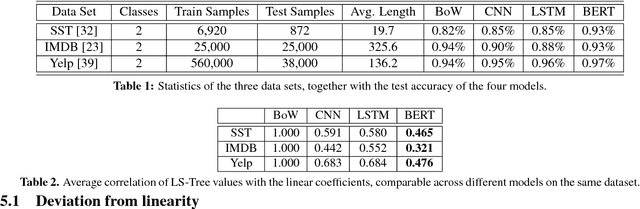
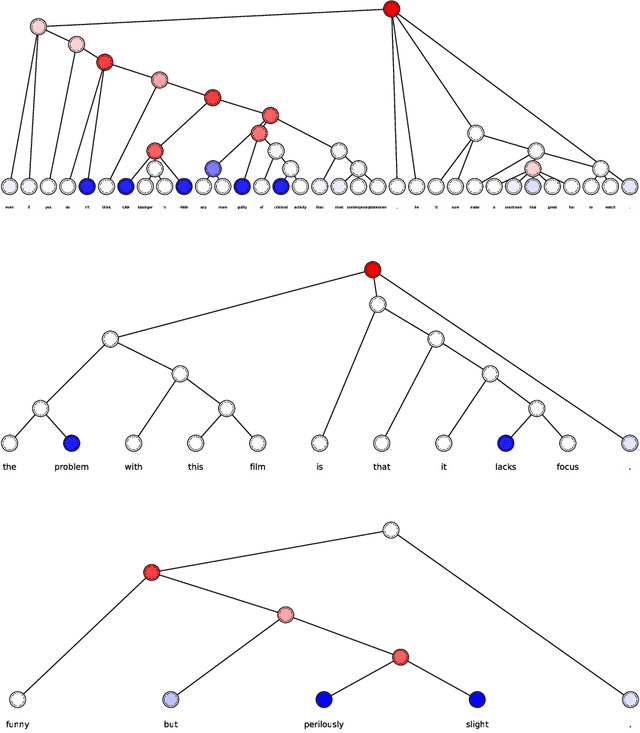
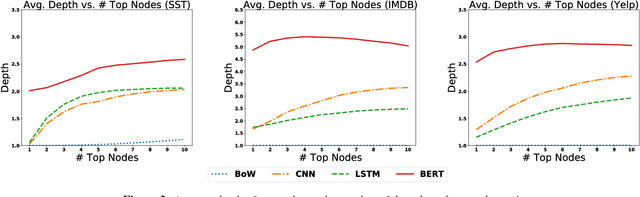
We study the problem of interpreting trained classification models in the setting of linguistic data sets. Leveraging a parse tree, we propose to assign least-squares based importance scores to each word of an instance by exploiting syntactic constituency structure. We establish an axiomatic characterization of these importance scores by relating them to the Banzhaf value in coalitional game theory. Based on these importance scores, we develop a principled method for detecting and quantifying interactions between words in a sentence. We demonstrate that the proposed method can aid in interpretability and diagnostics for several widely-used language models.
A Short Note on Concentration Inequalities for Random Vectors with SubGaussian Norm
Feb 11, 2019In this note, we derive concentration inequalities for random vectors with subGaussian norm (a generalization of both subGaussian random vectors and norm bounded random vectors), which are tight up to logarithmic factors.
Acceleration via Symplectic Discretization of High-Resolution Differential Equations
Feb 11, 2019We study first-order optimization methods obtained by discretizing ordinary differential equations (ODEs) corresponding to Nesterov's accelerated gradient methods (NAGs) and Polyak's heavy-ball method. We consider three discretization schemes: an explicit Euler scheme, an implicit Euler scheme, and a symplectic scheme. We show that the optimization algorithm generated by applying the symplectic scheme to a high-resolution ODE proposed by Shi et al. [2018] achieves an accelerated rate for minimizing smooth strongly convex functions. On the other hand, the resulting algorithm either fails to achieve acceleration or is impractical when the scheme is implicit, the ODE is low-resolution, or the scheme is explicit.
Cost-Effective Incentive Allocation via Structured Counterfactual Inference
Feb 07, 2019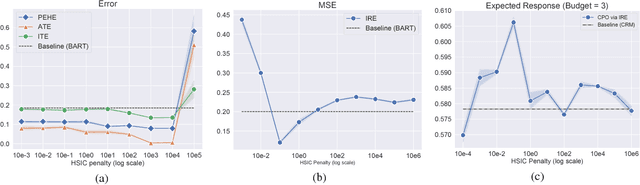
We address a practical problem ubiquitous in modern industry, in which a mediator tries to learn a policy for allocating strategic financial incentives for customers in a marketing campaign and observes only bandit feedback. In contrast to traditional policy optimization frameworks, we rely on a specific assumption for the reward structure and we incorporate budget constraints. We develop a new two-step method for solving this constrained counterfactual policy optimization problem. First, we cast the reward estimation problem as a domain adaptation problem with supplementary structure. Subsequently, the estimators are used for optimizing the policy with constraints. We establish theoretical error bounds for our estimation procedure and we empirically show that the approach leads to significant improvement on both synthetic and real datasets.
Is There an Analog of Nesterov Acceleration for MCMC?
Feb 04, 2019
We formulate gradient-based Markov chain Monte Carlo (MCMC) sampling as optimization on the space of probability measures, with Kullback-Leibler (KL) divergence as the objective function. We show that an underdamped form of the Langevin algorithm perform accelerated gradient descent in this metric. To characterize the convergence of the algorithm, we construct a Lyapunov functional and exploit hypocoercivity of the underdamped Langevin algorithm. As an application, we show that accelerated rates can be obtained for a class of nonconvex functions with the Langevin algorithm.