 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised learning of video representations from a child's perspective
Feb 01, 2024



Children learn powerful internal models of the world around them from a few years of egocentric visual experience. Can such internal models be learned from a child's visual experience with highly generic learning algorithms or do they require strong inductive biases? Recent advances in collecting large-scale, longitudinal, developmentally realistic video datasets and generic self-supervised learning (SSL) algorithms are allowing us to begin to tackle this nature vs. nurture question. However, existing work typically focuses on image-based SSL algorithms and visual capabilities that can be learned from static images (e.g. object recognition), thus ignoring temporal aspects of the world. To close this gap, here we train self-supervised video models on longitudinal, egocentric headcam recordings collected from a child over a two year period in their early development (6-31 months). The resulting models are highly effective at facilitating the learning of action concepts from a small number of labeled examples; they have favorable data size scaling properties; and they display emergent video interpolation capabilities. Video models also learn more robust object representations than image-based models trained with the exact same data. These results suggest that important temporal aspects of a child's internal model of the world may be learnable from their visual experience using highly generic learning algorithms and without strong inductive biases.
Learning and Forgetting Unsafe Examples in Large Language Models
Dec 20, 2023



As the number of large language models (LLMs) released to the public grows, there is a pressing need to understand the safety implications associated with these models learning from third-party custom finetuning data. We explore the behavior of LLMs finetuned on noisy custom data containing unsafe content, represented by datasets that contain biases, toxicity, and harmfulness, finding that while aligned LLMs can readily learn this unsafe content, they also tend to forget it more significantly than other examples when subsequently finetuned on safer content. Drawing inspiration from the discrepancies in forgetting, we introduce the "ForgetFilter" algorithm, which filters unsafe data based on how strong the model's forgetting signal is for that data. We demonstrate that the ForgetFilter algorithm ensures safety in customized finetuning without compromising downstream task performance, unlike sequential safety finetuning. ForgetFilter outperforms alternative strategies like replay and moral self-correction in curbing LLMs' ability to assimilate unsafe content during custom finetuning, e.g. 75% lower than not applying any safety measures and 62% lower than using self-correction in toxicity score.
LifelongMemory: Leveraging LLMs for Answering Queries in Egocentric Videos
Dec 07, 2023



The egocentric video natural language query (NLQ) task involves localizing a temporal window in an egocentric video that provides an answer to a posed query, which has wide applications in building personalized AI assistants. Prior methods for this task have focused on improvements of network architecture and leveraging pre-training for enhanced image and video features, but have struggled with capturing long-range temporal dependencies in lengthy videos, and cumbersome end-to-end training. Motivated by recent advancements in Large Language Models (LLMs) and vision language models, we introduce LifelongMemory, a novel framework that utilizes multiple pre-trained models to answer queries from extensive egocentric video content. We address the unique challenge by employing a pre-trained captioning model to create detailed narratives of the videos. These narratives are then used to prompt a frozen LLM to generate coarse-grained temporal window predictions, which are subsequently refined using a pre-trained NLQ model. Empirical results demonstrate that our method achieves competitive performance against existing supervised end-to-end learning methods, underlining the potential of integrating multiple pre-trained multimodal large language models in complex vision-language tasks. We provide a comprehensive analysis of key design decisions and hyperparameters in our pipeline, offering insights and practical guidelines.
BIM: Block-Wise Self-Supervised Learning with Masked Image Modeling
Nov 28, 2023



Like masked language modeling (MLM) in natural language processing, masked image modeling (MIM) aims to extract valuable insights from image patches to enhance the feature extraction capabilities of the underlying deep neural network (DNN). Contrasted with other training paradigms like supervised learning and unsupervised contrastive learning, masked image modeling (MIM) pretraining typically demands significant computational resources in order to manage large training data batches (e.g., 4096). The significant memory and computation requirements pose a considerable challenge to its broad adoption. To mitigate this, we introduce a novel learning framework, termed~\textit{Block-Wise Masked Image Modeling} (BIM). This framework involves decomposing the MIM tasks into several sub-tasks with independent computation patterns, resulting in block-wise back-propagation operations instead of the traditional end-to-end approach. Our proposed BIM maintains superior performance compared to conventional MIM while greatly reducing peak memory consumption. Moreover, BIM naturally enables the concurrent training of numerous DNN backbones of varying depths. This leads to the creation of multiple trained DNN backbones, each tailored to different hardware platforms with distinct computing capabilities. This approach significantly reduces computational costs in comparison with training each DNN backbone individually. Our framework offers a promising solution for resource constrained training of MIM.
Towards Unsupervised Object Detection From LiDAR Point Clouds
Nov 03, 2023



In this paper, we study the problem of unsupervised object detection from 3D point clouds in self-driving scenes. We present a simple yet effective method that exploits (i) point clustering in near-range areas where the point clouds are dense, (ii) temporal consistency to filter out noisy unsupervised detections, (iii) translation equivariance of CNNs to extend the auto-labels to long range, and (iv) self-supervision for improving on its own. Our approach, OYSTER (Object Discovery via Spatio-Temporal Refinement), does not impose constraints on data collection (such as repeated traversals of the same location), is able to detect objects in a zero-shot manner without supervised finetuning (even in sparse, distant regions), and continues to self-improve given more rounds of iterative self-training. To better measure model performance in self-driving scenarios, we propose a new planning-centric perception metric based on distance-to-collision. We demonstrate that our unsupervised object detector significantly outperforms unsupervised baselines on PandaSet and Argoverse 2 Sensor dataset, showing promise that self-supervision combined with object priors can enable object discovery in the wild. For more information, visit the project website: https://waabi.ai/research/oyster
Rethinking Closed-loop Training for Autonomous Driving
Jun 27, 2023Recent advances in high-fidelity simulators have enabled closed-loop training of autonomous driving agents, potentially solving the distribution shift in training v.s. deployment and allowing training to be scaled both safely and cheaply. However, there is a lack of understanding of how to build effective training benchmarks for closed-loop training. In this work, we present the first empirical study which analyzes the effects of different training benchmark designs on the success of learning agents, such as how to design traffic scenarios and scale training environments. Furthermore, we show that many popular RL algorithms cannot achieve satisfactory performance in the context of autonomous driving, as they lack long-term planning and take an extremely long time to train. To address these issues, we propose trajectory value learning (TRAVL), an RL-based driving agent that performs planning with multistep look-ahead and exploits cheaply generated imagined data for efficient learning. Our experiments show that TRAVL can learn much faster and produce safer maneuvers compared to all the baselines. For more information, visit the project website: https://waabi.ai/research/travl
Gaussian-Bernoulli RBMs Without Tears
Oct 19, 2022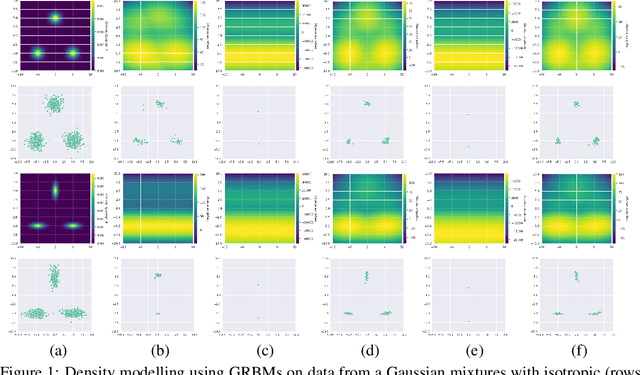

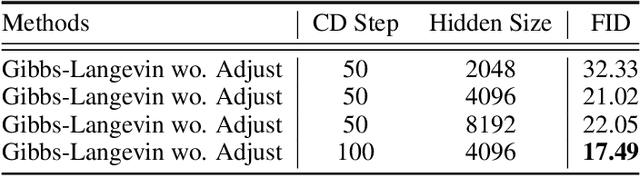
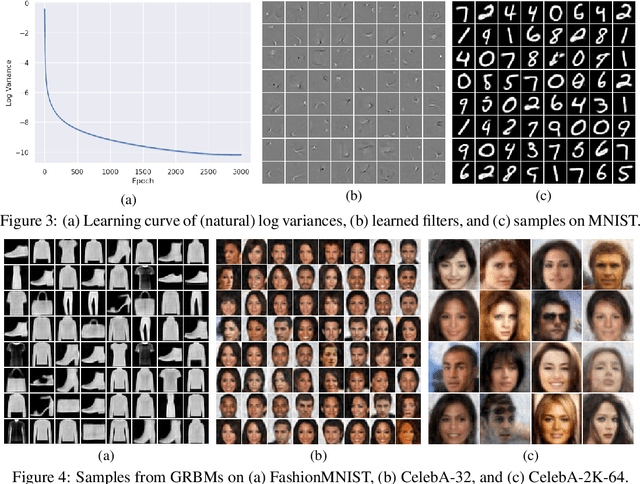
We revisit the challenging problem of training Gaussian-Bernoulli restricted Boltzmann machines (GRBMs), introducing two innovations. We propose a novel Gibbs-Langevin sampling algorithm that outperforms existing methods like Gibbs sampling. We propose a modified contrastive divergence (CD) algorithm so that one can generate images with GRBMs starting from noise. This enables direct comparison of GRBMs with deep generative models, improving evaluation protocols in the RBM literature. Moreover, we show that modified CD and gradient clipping are enough to robustly train GRBMs with large learning rates, thus removing the necessity of various tricks in the literature. Experiments on Gaussian Mixtures, MNIST, FashionMNIST, and CelebA show GRBMs can generate good samples, despite their single-hidden-layer architecture. Our code is released at: \url{https://github.com/lrjconan/GRBM}.
Scaling Forward Gradient With Local Losses
Oct 07, 2022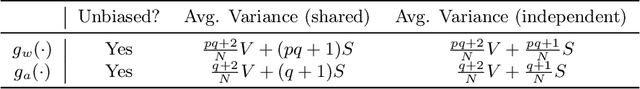

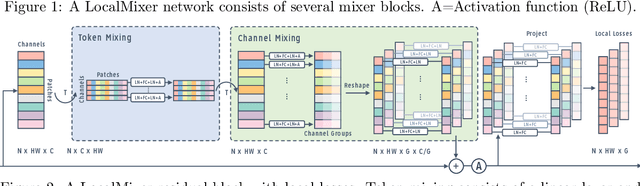
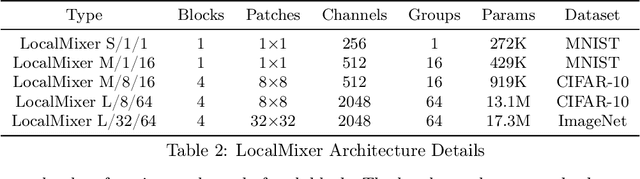
Forward gradient learning computes a noisy directional gradient and is a biologically plausible alternative to backprop for learning deep neural networks. However, the standard forward gradient algorithm, when applied naively, suffers from high variance when the number of parameters to be learned is large. In this paper, we propose a series of architectural and algorithmic modifications that together make forward gradient learning practical for standard deep learning benchmark tasks. We show that it is possible to substantially reduce the variance of the forward gradient estimator by applying perturbations to activations rather than weights. We further improve the scalability of forward gradient by introducing a large number of local greedy loss functions, each of which involves only a small number of learnable parameters, and a new MLPMixer-inspired architecture, LocalMixer, that is more suitable for local learning. Our approach matches backprop on MNIST and CIFAR-10 and significantly outperforms previously proposed backprop-free algorithms on ImageNet.
Learning to Reason With Relational Abstractions
Oct 06, 2022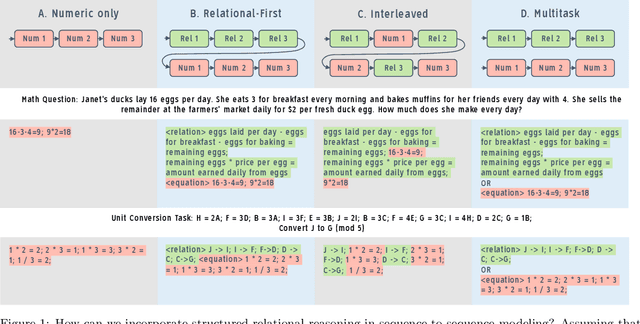

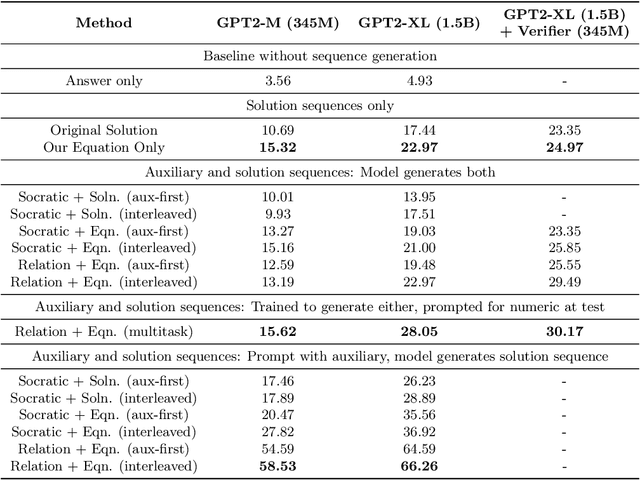

Large language models have recently shown promising progress in mathematical reasoning when fine-tuned with human-generated sequences walking through a sequence of solution steps. However, the solution sequences are not formally structured and the resulting model-generated sequences may not reflect the kind of systematic reasoning we might expect an expert human to produce. In this paper, we study how to build stronger reasoning capability in language models using the idea of relational abstractions. We introduce new types of sequences that more explicitly provide an abstract characterization of the transitions through intermediate solution steps to the goal state. We find that models that are supplied with such sequences as prompts can solve tasks with a significantly higher accuracy, and models that are trained to produce such sequences solve problems better than those that are trained with previously used human-generated sequences and other baselines. Our work thus takes several steps toward elucidating and improving how language models perform on tasks requiring multi-step mathematical reasoning.
Online Unsupervised Learning of Visual Representations and Categories
Sep 13, 2021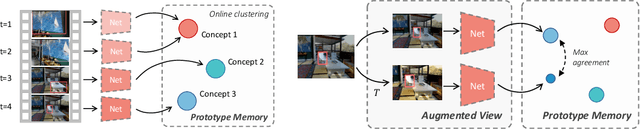
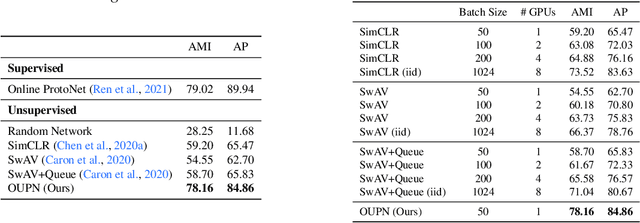


Real world learning scenarios involve a nonstationary distribution of classes with sequential dependencies among the samples, in contrast to the standard machine learning formulation of drawing samples independently from a fixed, typically uniform distribution. Furthermore, real world interactions demand learning on-the-fly from few or no class labels. In this work, we propose an unsupervised model that simultaneously performs online visual representation learning and few-shot learning of new categories without relying on any class labels. Our model is a prototype-based memory network with a control component that determines when to form a new class prototype. We formulate it as an online Gaussian mixture model, where components are created online with only a single new example, and assignments do not have to be balanced, which permits an approximation to natural imbalanced distributions from uncurated raw data. Learning includes a contrastive loss that encourages different views of the same image to be assigned to the same prototype. The result is a mechanism that forms categorical representations of objects in nonstationary environments. Experiments show that our method can learn from an online stream of visual input data and is significantly better at category recognition compared to state-of-the-art self-supervised learning methods.