 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Representation Learning from Flow Equivariance
Paper and Code
Jan 16, 2021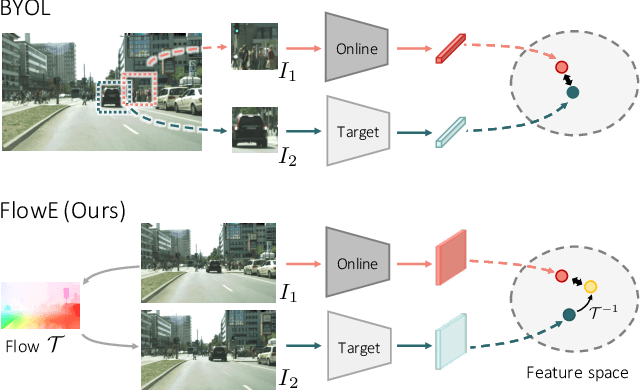
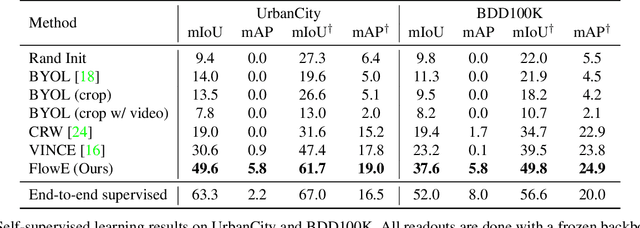
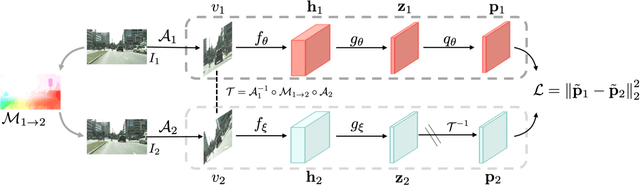
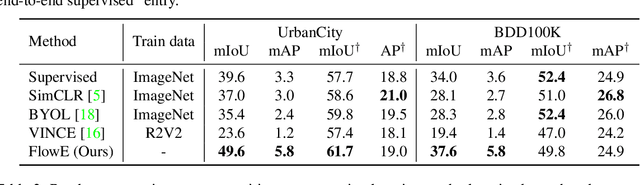
Self-supervised representation learning is able to learn semantically meaningful features; however, much of its recent success relies on multiple crops of an image with very few objects. Instead of learning view-invariant representation from simple images, humans learn representations in a complex world with changing scenes by observing object movement, deformation, pose variation, and ego motion. Motivated by this ability, we present a new self-supervised learning representation framework that can be directly deployed on a video stream of complex scenes with many moving objects. Our framework features a simple flow equivariance objective that encourages the network to predict the features of another frame by applying a flow transformation to the features of the current frame. Our representations, learned from high-resolution raw video, can be readily used for downstream tasks on static images. Readout experiments on challenging semantic segmentation, instance segmentation, and object detection benchmarks show that we are able to outperform representations obtained from previous state-of-the-art methods including SimCLR and BYOL.