 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill Not Only Data but Also Rewards: Can Smaller Language Models Surpass Larger Ones?
Feb 26, 2025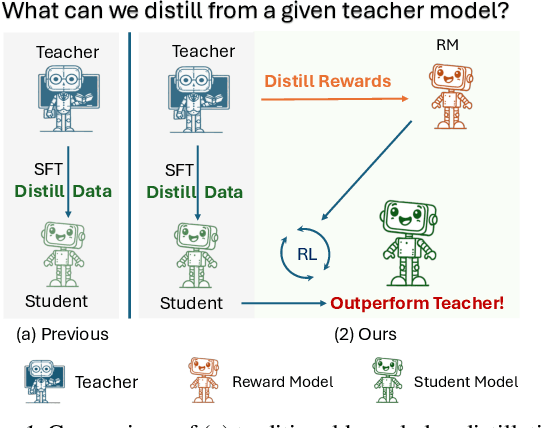

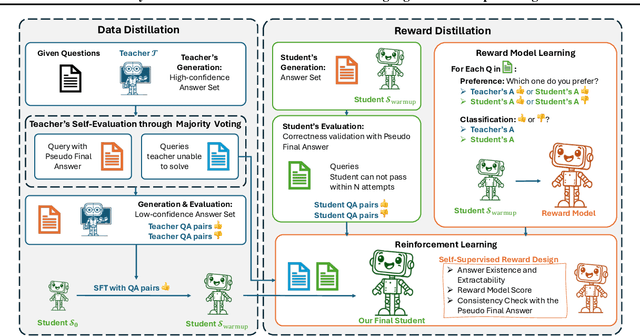
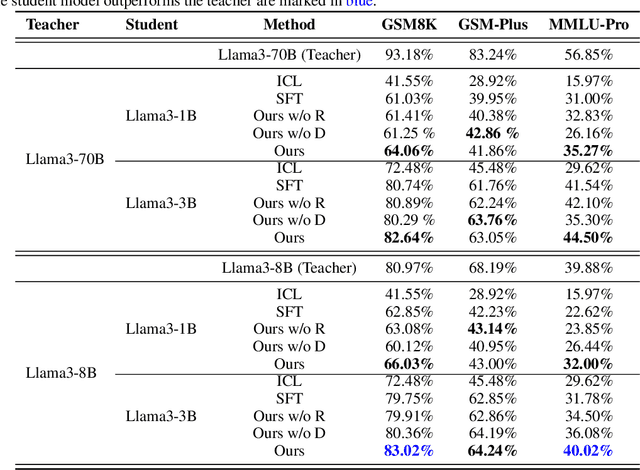
Distilling large language models (LLMs) typically involves transferring the teacher model's responses through supervised fine-tuning (SFT). However, this approach neglects the potential to distill both data (output content) and reward signals (quality evaluations). Extracting reliable reward signals directly from teacher models is challenging, as LLMs are optimized for generation rather than evaluation, often resulting in biased or inconsistent assessments. To address this limitation, we propose a novel distillation pipeline that transfers both responses and rewards. Our method generates pseudo-rewards through a self-supervised mechanism that leverages the inherent structure of both teacher and student responses, enabling reward learning without explicit external evaluation. The reward model subsequently guides reinforcement learning (RL), allowing iterative refinement of the student model after an SFT warm-up phase. Experiments on GSM8K and MMLU-PRO demonstrate that our method consistently outperforms traditional SFT-based approaches, enabling student models to surpass the performance of their teachers. This work highlights the potential for scalable, efficient distillation through structured self-supervised reward learning, reducing dependence on external reward supervision.
Geolocation with Real Human Gameplay Data: A Large-Scale Dataset and Human-Like Reasoning Framework
Feb 19, 2025



Geolocation, the task of identifying an image's location, requires complex reasoning and is crucial for navigation, monitoring, and cultural preservation. However, current methods often produce coarse, imprecise, and non-interpretable localization. A major challenge lies in the quality and scale of existing geolocation datasets. These datasets are typically small-scale and automatically constructed, leading to noisy data and inconsistent task difficulty, with images that either reveal answers too easily or lack sufficient clues for reliable inference. To address these challenges, we introduce a comprehensive geolocation framework with three key components: GeoComp, a large-scale dataset; GeoCoT, a novel reasoning method; and GeoEval, an evaluation metric, collectively designed to address critical challenges and drive advancements in geolocation research. At the core of this framework is GeoComp (Geolocation Competition Dataset), a large-scale dataset collected from a geolocation game platform involving 740K users over two years. It comprises 25 million entries of metadata and 3 million geo-tagged locations spanning much of the globe, with each location annotated thousands to tens of thousands of times by human users. The dataset offers diverse difficulty levels for detailed analysis and highlights key gaps in current models. Building on this dataset, we propose Geographical Chain-of-Thought (GeoCoT), a novel multi-step reasoning framework designed to enhance the reasoning capabilities of Large Vision Models (LVMs) in geolocation tasks. GeoCoT improves performance by integrating contextual and spatial cues through a multi-step process that mimics human geolocation reasoning. Finally, using the GeoEval metric, we demonstrate that GeoCoT significantly boosts geolocation accuracy by up to 25% while enhancing interpretability.
Enhancing Input-Label Mapping in In-Context Learning with Contrastive Decoding
Feb 19, 2025Large language models (LLMs) excel at a range of tasks through in-context learning (ICL), where only a few task examples guide their predictions. However, prior research highlights that LLMs often overlook input-label mapping information in ICL, relying more on their pre-trained knowledge. To address this issue, we introduce In-Context Contrastive Decoding (ICCD), a novel method that emphasizes input-label mapping by contrasting the output distributions between positive and negative in-context examples. Experiments on 7 natural language understanding (NLU) tasks show that our ICCD method brings consistent and significant improvement (up to +2.1 improvement on average) upon 6 different scales of LLMs without requiring additional training. Our approach is versatile, enhancing performance with various demonstration selection methods, demonstrating its broad applicability and effectiveness. The code and scripts will be publicly released.
MTPChat: A Multimodal Time-Aware Persona Dataset for Conversational Agents
Feb 09, 2025Understanding temporal dynamics is critical for conversational agents, enabling effective content analysis and informed decision-making. However, time-aware datasets, particularly for persona-grounded conversations, are still limited, which narrows their scope and diminishes their complexity. To address this gap, we introduce MTPChat, a multimodal, time-aware persona dialogue dataset that integrates linguistic, visual, and temporal elements within dialogue and persona memory. Leveraging MTPChat, we propose two time-sensitive tasks: Temporal Next Response Prediction (TNRP) and Temporal Grounding Memory Prediction (TGMP), both designed to assess a model's ability to understand implicit temporal cues and dynamic interactions. Additionally, we present an innovative framework featuring an adaptive temporal module to effectively integrate multimodal streams and capture temporal dependencies. Experimental results validate the challenges posed by MTPChat and demonstrate the effectiveness of our framework in multimodal time-sensitive scenarios.
Who Can Withstand Chat-Audio Attacks? An Evaluation Benchmark for Large Language Models
Nov 22, 2024Adversarial audio attacks pose a significant threat to the growing use of large language models (LLMs) in voice-based human-machine interactions. While existing research has primarily focused on model-specific adversarial methods, real-world applications demand a more generalizable and universal approach to audio adversarial attacks. In this paper, we introduce the Chat-Audio Attacks (CAA) benchmark including four distinct types of audio attacks, which aims to explore the the vulnerabilities of LLMs to these audio attacks in conversational scenarios. To evaluate the robustness of LLMs, we propose three evaluation strategies: Standard Evaluation, utilizing traditional metrics to quantify model performance under attacks; GPT-4o-Based Evaluation, which simulates real-world conversational complexities; and Human Evaluation, offering insights into user perception and trust. We evaluate six state-of-the-art LLMs with voice interaction capabilities, including Gemini-1.5-Pro, GPT-4o, and others, using three distinct evaluation methods on the CAA benchmark. Our comprehensive analysis reveals the impact of four types of audio attacks on the performance of these models, demonstrating that GPT-4o exhibits the highest level of resilience.
RuAG: Learned-rule-augmented Generation for Large Language Models
Nov 04, 2024



In-context learning (ICL) and Retrieval-Augmented Generation (RAG) have gained attention for their ability to enhance LLMs' reasoning by incorporating external knowledge but suffer from limited contextual window size, leading to insufficient information injection. To this end, we propose a novel framework, RuAG, to automatically distill large volumes of offline data into interpretable first-order logic rules, which are injected into LLMs to boost their reasoning capabilities. Our method begins by formulating the search process relying on LLMs' commonsense, where LLMs automatically define head and body predicates. Then, RuAG applies Monte Carlo Tree Search (MCTS) to address the combinational searching space and efficiently discover logic rules from data. The resulting logic rules are translated into natural language, allowing targeted knowledge injection and seamless integration into LLM prompts for LLM's downstream task reasoning. We evaluate our framework on public and private industrial tasks, including natural language processing, time-series, decision-making, and industrial tasks, demonstrating its effectiveness in enhancing LLM's capability over diverse tasks.
MedINST: Meta Dataset of Biomedical Instructions
Oct 17, 2024



The integration of large language model (LLM) techniques in the field of medical analysis has brought about significant advancements, yet the scarcity of large, diverse, and well-annotated datasets remains a major challenge. Medical data and tasks, which vary in format, size, and other parameters, require extensive preprocessing and standardization for effective use in training LLMs. To address these challenges, we introduce MedINST, the Meta Dataset of Biomedical Instructions, a novel multi-domain, multi-task instructional meta-dataset. MedINST comprises 133 biomedical NLP tasks and over 7 million training samples, making it the most comprehensive biomedical instruction dataset to date. Using MedINST as the meta dataset, we curate MedINST32, a challenging benchmark with different task difficulties aiming to evaluate LLMs' generalization ability. We fine-tune several LLMs on MedINST and evaluate on MedINST32, showcasing enhanced cross-task generalization.
Robust RL with LLM-Driven Data Synthesis and Policy Adaptation for Autonomous Driving
Oct 16, 2024



The integration of Large Language Models (LLMs) into autonomous driving systems demonstrates strong common sense and reasoning abilities, effectively addressing the pitfalls of purely data-driven methods. Current LLM-based agents require lengthy inference times and face challenges in interacting with real-time autonomous driving environments. A key open question is whether we can effectively leverage the knowledge from LLMs to train an efficient and robust Reinforcement Learning (RL) agent. This paper introduces RAPID, a novel \underline{\textbf{R}}obust \underline{\textbf{A}}daptive \underline{\textbf{P}}olicy \underline{\textbf{I}}nfusion and \underline{\textbf{D}}istillation framework, which trains specialized mix-of-policy RL agents using data synthesized by an LLM-based driving agent and online adaptation. RAPID features three key designs: 1) utilization of offline data collected from an LLM agent to distil expert knowledge into RL policies for faster real-time inference; 2) introduction of robust distillation in RL to inherit both performance and robustness from LLM-based teacher; and 3) employment of a mix-of-policy approach for joint decision decoding with a policy adapter. Through fine-tuning via online environment interaction, RAPID reduces the forgetting of LLM knowledge while maintaining adaptability to different tasks. Extensive experiments demonstrate RAPID's capability to effectively integrate LLM knowledge into scaled-down RL policies in an efficient, adaptable, and robust way. Code and checkpoints will be made publicly available upon acceptance.
OpenR: An Open Source Framework for Advanced Reasoning with Large Language Models
Oct 12, 2024



In this technical report, we introduce OpenR, an open-source framework designed to integrate key components for enhancing the reasoning capabilities of large language models (LLMs). OpenR unifies data acquisition, reinforcement learning training (both online and offline), and non-autoregressive decoding into a cohesive software platform. Our goal is to establish an open-source platform and community to accelerate the development of LLM reasoning. Inspired by the success of OpenAI's o1 model, which demonstrated improved reasoning abilities through step-by-step reasoning and reinforcement learning, OpenR integrates test-time compute, reinforcement learning, and process supervision to improve reasoning in LLMs. Our work is the first to provide an open-source framework that explores the core techniques of OpenAI's o1 model with reinforcement learning, achieving advanced reasoning capabilities beyond traditional autoregressive methods. We demonstrate the efficacy of OpenR by evaluating it on the MATH dataset, utilising publicly available data and search methods. Our initial experiments confirm substantial gains, with relative improvements in reasoning and performance driven by test-time computation and reinforcement learning through process reward models. The OpenR framework, including code, models, and datasets, is accessible at https://openreasoner.github.io.
Enhancing Temporal Sensitivity and Reasoning for Time-Sensitive Question Answering
Sep 25, 2024Time-Sensitive Question Answering (TSQA) demands the effective utilization of specific temporal contexts, encompassing multiple time-evolving facts, to address time-sensitive questions. This necessitates not only the parsing of temporal information within questions but also the identification and understanding of time-evolving facts to generate accurate answers. However, current large language models still have limited sensitivity to temporal information and their inadequate temporal reasoning capabilities.In this paper, we propose a novel framework that enhances temporal awareness and reasoning through Temporal Information-Aware Embedding and Granular Contrastive Reinforcement Learning. Experimental results on four TSQA datasets demonstrate that our framework significantly outperforms existing LLMs in TSQA tasks, marking a step forward in bridging the performance gap between machine and human temporal understanding and reasoning.