 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining and Inference Efficiency of Encoder-Decoder Speech Models
Mar 07, 2025



Attention encoder-decoder model architecture is the backbone of several recent top performing foundation speech models: Whisper, Seamless, OWSM, and Canary-1B. However, the reported data and compute requirements for their training are prohibitive for many in the research community. In this work, we focus on the efficiency angle and ask the questions of whether we are training these speech models efficiently, and what can we do to improve? We argue that a major, if not the most severe, detrimental factor for training efficiency is related to the sampling strategy of sequential data. We show that negligence in mini-batch sampling leads to more than 50% computation being spent on padding. To that end, we study, profile, and optimize Canary-1B training to show gradual improvement in GPU utilization leading up to 5x increase in average batch sizes versus its original training settings. This in turn allows us to train an equivalent model using 4x less GPUs in the same wall time, or leverage the original resources and train it in 2x shorter wall time. Finally, we observe that the major inference bottleneck lies in the autoregressive decoder steps. We find that adjusting the model architecture to transfer model parameters from the decoder to the encoder results in a 3x inference speedup as measured by inverse real-time factor (RTFx) while preserving the accuracy and compute requirements for convergence. The training code and models will be available as open-source.
Label-Looping: Highly Efficient Decoding for Transducers
Jun 10, 2024



This paper introduces a highly efficient greedy decoding algorithm for Transducer inference. We propose a novel data structure using CUDA tensors to represent partial hypotheses in a batch that supports parallelized hypothesis manipulations. During decoding, our algorithm maximizes GPU parallelism by adopting a nested-loop design, where the inner loop consumes all blank predictions, while non-blank predictions are handled in the outer loop. Our algorithm is general-purpose and can work with both conventional Transducers and Token-and-Duration Transducers. Experiments show that the label-looping algorithm can bring a speedup up to 2.0X compared to conventional batched decoding algorithms when using batch size 32, and can be combined with other compiler or GPU call-related techniques to bring more speedup. We will open-source our implementation to benefit the research community.
Speed of Light Exact Greedy Decoding for RNN-T Speech Recognition Models on GPU
Jun 06, 2024



The vast majority of inference time for RNN Transducer (RNN-T) models today is spent on decoding. Current state-of-the-art RNN-T decoding implementations leave the GPU idle ~80% of the time. Leveraging a new CUDA 12.4 feature, CUDA graph conditional nodes, we present an exact GPU-based implementation of greedy decoding for RNN-T models that eliminates this idle time. Our optimizations speed up a 1.1 billion parameter RNN-T model end-to-end by a factor of 2.5x. This technique can applied to the "label looping" alternative greedy decoding algorithm as well, achieving 1.7x and 1.4x end-to-end speedups when applied to 1.1 billion parameter RNN-T and Token and Duration Transducer models respectively. This work enables a 1.1 billion parameter RNN-T model to run only 16% slower than a similarly sized CTC model, contradicting the common belief that RNN-T models are not suitable for high throughput inference. The implementation is available in NVIDIA NeMo.
GPU-Accelerated WFST Beam Search Decoder for CTC-based Speech Recognition
Nov 08, 2023



While Connectionist Temporal Classification (CTC) models deliver state-of-the-art accuracy in automated speech recognition (ASR) pipelines, their performance has been limited by CPU-based beam search decoding. We introduce a GPU-accelerated Weighted Finite State Transducer (WFST) beam search decoder compatible with current CTC models. It increases pipeline throughput and decreases latency, supports streaming inference, and also supports advanced features like utterance-specific word boosting via on-the-fly composition. We provide pre-built DLPack-based python bindings for ease of use with Python-based machine learning frameworks at https://github.com/nvidia-riva/riva-asrlib-decoder. We evaluated our decoder for offline and online scenarios, demonstrating that it is the fastest beam search decoder for CTC models. In the offline scenario it achieves up to 7 times more throughput than the current state-of-the-art CPU decoder and in the online streaming scenario, it achieves nearly 8 times lower latency, with same or better word error rate.
Speech Wikimedia: A 77 Language Multilingual Speech Dataset
Aug 30, 2023



The Speech Wikimedia Dataset is a publicly available compilation of audio with transcriptions extracted from Wikimedia Commons. It includes 1780 hours (195 GB) of CC-BY-SA licensed transcribed speech from a diverse set of scenarios and speakers, in 77 different languages. Each audio file has one or more transcriptions in different languages, making this dataset suitable for training speech recognition, speech translation, and machine translation models.
LSH methods for data deduplication in a Wikipedia artificial dataset
Dec 10, 2021This paper illustrates locality sensitive hasing (LSH) models for the identification and removal of nearly redundant data in a text dataset. To evaluate the different models, we create an artificial dataset for data deduplication using English Wikipedia articles. Area-Under-Curve (AUC) over 0.9 were observed for most models, with the best model reaching 0.96. Deduplication enables more effective model training by preventing the model from learning a distribution that differs from the real one as a result of the repeated data.
The People's Speech: A Large-Scale Diverse English Speech Recognition Dataset for Commercial Usage
Nov 17, 2021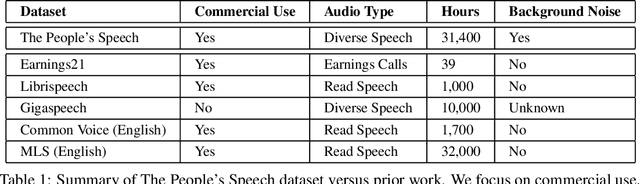
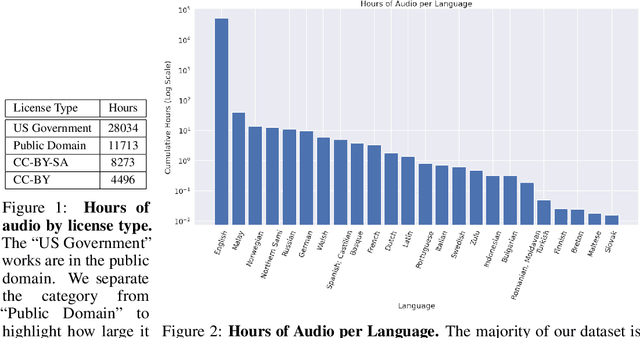

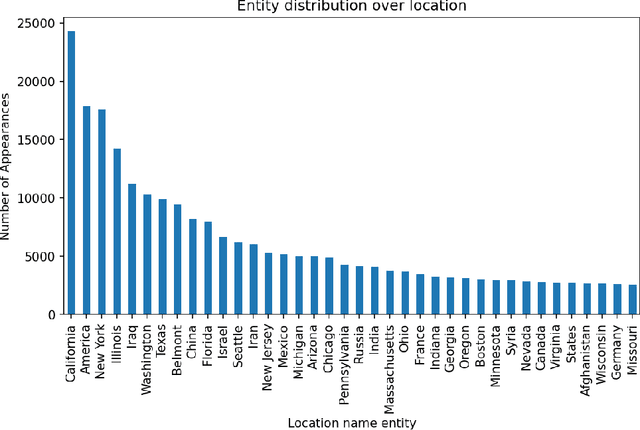
The People's Speech is a free-to-download 30,000-hour and growing supervised conversational English speech recognition dataset licensed for academic and commercial usage under CC-BY-SA (with a CC-BY subset). The data is collected via searching the Internet for appropriately licensed audio data with existing transcriptions. We describe our data collection methodology and release our data collection system under the Apache 2.0 license. We show that a model trained on this dataset achieves a 9.98% word error rate on Librispeech's test-clean test set.Finally, we discuss the legal and ethical issues surrounding the creation of a sizable machine learning corpora and plans for continued maintenance of the project under MLCommons's sponsorship.
Multiple-Instance, Cascaded Classification for Keyword Spotting in Narrow-Band Audio
Nov 21, 2017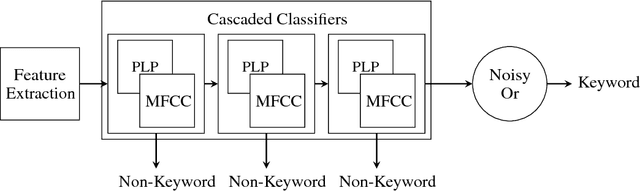
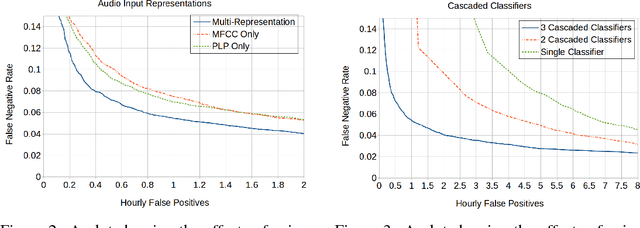
We propose using cascaded classifiers for a keyword spotting (KWS) task on narrow-band (NB), 8kHz audio acquired in non-IID environments --- a more challenging task than most state-of-the-art KWS systems face. We present a model that incorporates Deep Neural Networks (DNNs), cascading, multiple-feature representations, and multiple-instance learning. The cascaded classifiers handle the task's class imbalance and reduce power consumption on computationally-constrained devices via early termination. The KWS system achieves a false negative rate of 6% at an hourly false positive rate of 0.75