 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn2Reg: comprehensive multi-task medical image registration challenge, dataset and evaluation in the era of deep learning
Dec 23, 2021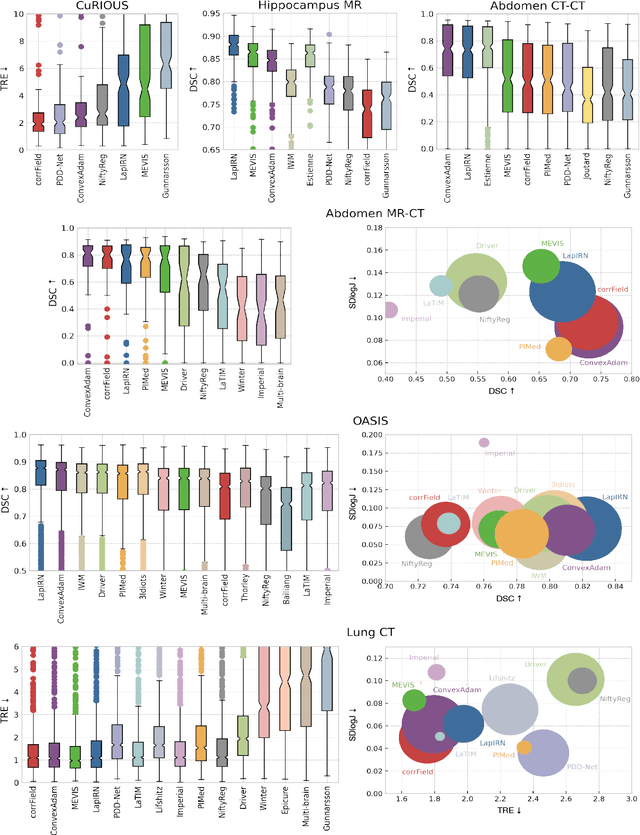
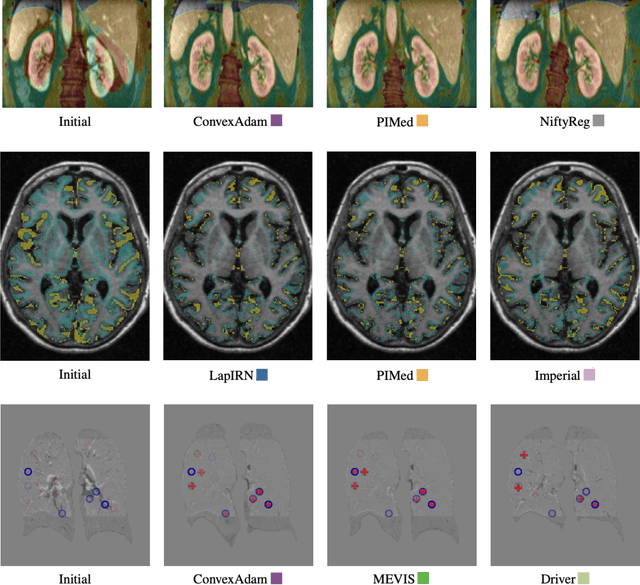
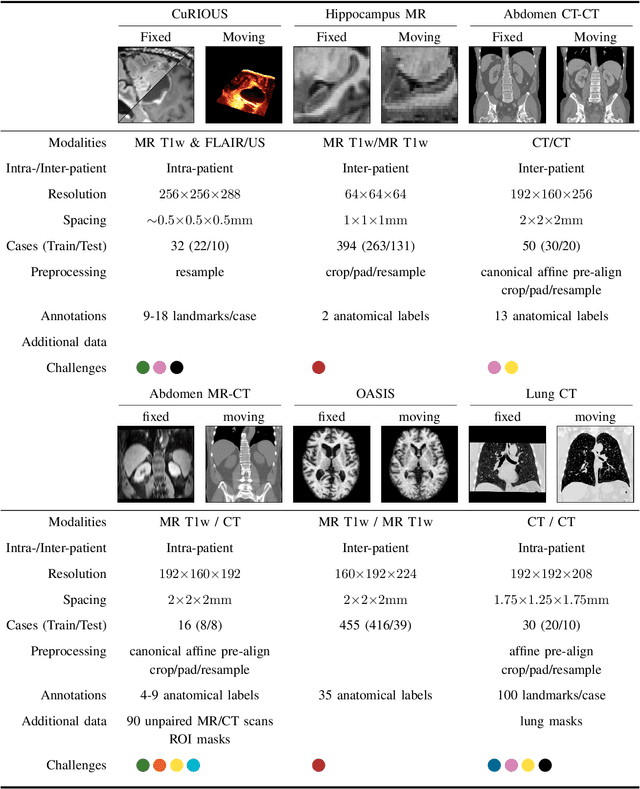
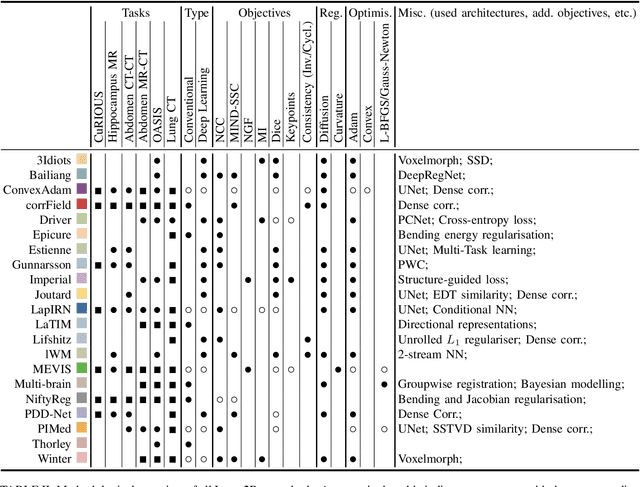
Image registration is a fundamental medical image analysis task, and a wide variety of approaches have been proposed. However, only a few studies have comprehensively compared medical image registration approaches on a wide range of clinically relevant tasks, in part because of the lack of availability of such diverse data. This limits the development of registration methods, the adoption of research advances into practice, and a fair benchmark across competing approaches. The Learn2Reg challenge addresses these limitations by providing a multi-task medical image registration benchmark for comprehensive characterisation of deformable registration algorithms. A continuous evaluation will be possible at https://learn2reg.grand-challenge.org. Learn2Reg covers a wide range of anatomies (brain, abdomen, and thorax), modalities (ultrasound, CT, MR), availability of annotations, as well as intra- and inter-patient registration evaluation. We established an easily accessible framework for training and validation of 3D registration methods, which enabled the compilation of results of over 65 individual method submissions from more than 20 unique teams. We used a complementary set of metrics, including robustness, accuracy, plausibility, and runtime, enabling unique insight into the current state-of-the-art of medical image registration. This paper describes datasets, tasks, evaluation methods and results of the challenge, and the results of further analysis of transferability to new datasets, the importance of label supervision, and resulting bias.
Inter Extreme Points Geodesics for Weakly Supervised Segmentation
Jul 01, 2021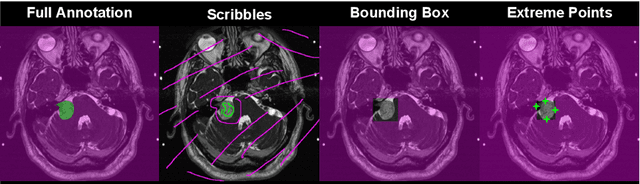
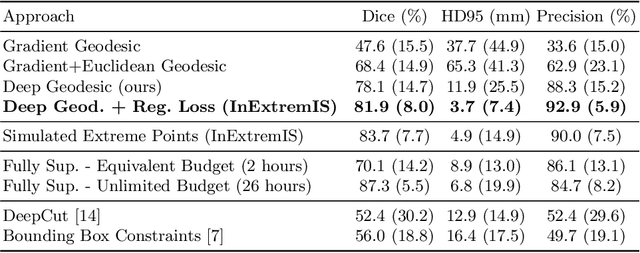
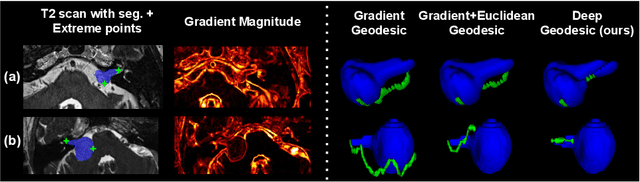
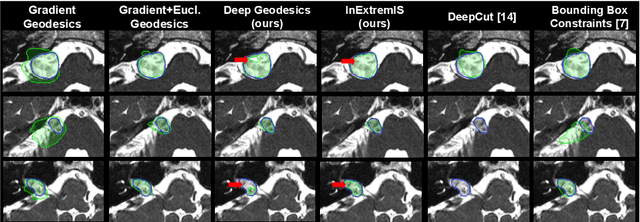
We introduce $\textit{InExtremIS}$, a weakly supervised 3D approach to train a deep image segmentation network using particularly weak train-time annotations: only 6 extreme clicks at the boundary of the objects of interest. Our fully-automatic method is trained end-to-end and does not require any test-time annotations. From the extreme points, 3D bounding boxes are extracted around objects of interest. Then, deep geodesics connecting extreme points are generated to increase the amount of "annotated" voxels within the bounding boxes. Finally, a weakly supervised regularised loss derived from a Conditional Random Field formulation is used to encourage prediction consistency over homogeneous regions. Extensive experiments are performed on a large open dataset for Vestibular Schwannoma segmentation. $\textit{InExtremIS}$ obtained competitive performance, approaching full supervision and outperforming significantly other weakly supervised techniques based on bounding boxes. Moreover, given a fixed annotation time budget, $\textit{InExtremIS}$ outperforms full supervision. Our code and data are available online.
Robust joint registration of multiple stains and MRI for multimodal 3D histology reconstruction: Application to the Allen human brain atlas
May 04, 2021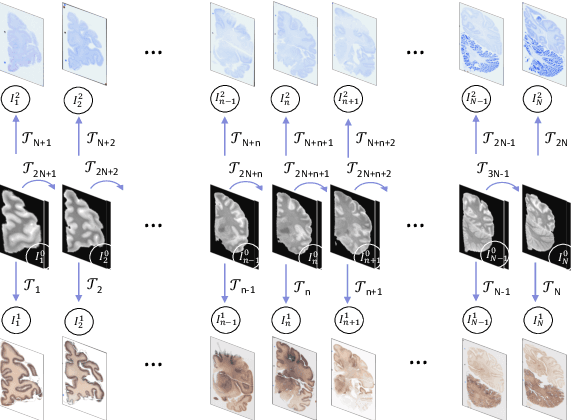
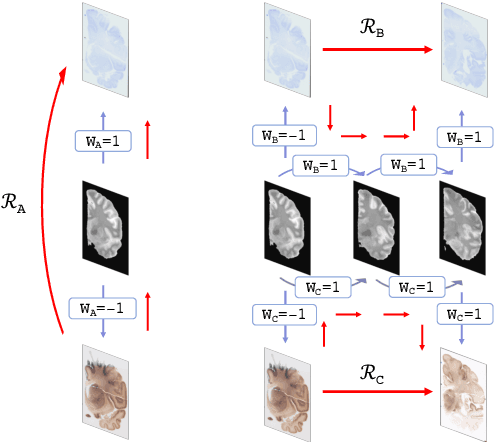
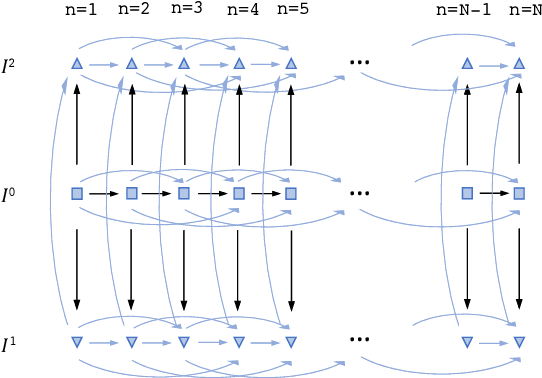
Joint registration of a stack of 2D histological sections to recover 3D structure (3D histology reconstruction) finds application in areas such as atlas building and validation of in vivo imaging. Straighforward pairwise registration of neighbouring sections yields smooth reconstructions but has well-known problems such as banana effect (straightening of curved structures) and z-shift (drift). While these problems can be alleviated with an external, linearly aligned reference (e.g., Magnetic Resonance images), registration is often inaccurate due to contrast differences and the strong nonlinear distortion of the tissue, including artefacts such as folds and tears. In this paper, we present a probabilistic model of spatial deformation that yields reconstructions for multiple histological stains that that are jointly smooth, robust to outliers, and follow the reference shape. The model relies on a spanning tree of latent transforms connecting all the sections and slices, and assumes that the registration between any pair of images can be see as a noisy version of the composition of (possibly inverted) latent transforms connecting the two images. Bayesian inference is used to compute the most likely latent transforms given a set of pairwise registrations between image pairs within and across modalities. Results on synthetic deformations on multiple MR modalities, show that our method can accurately and robustly register multiple contrasts even in the presence of outliers. The 3D histology reconstruction of two stains (Nissl and parvalbumin) from the Allen human brain atlas, show its benefits on real data with severe distortions. We also provide the correspondence to MNI space, bridging the gap between two of the most used atlases in histology and MRI. Data is available at https://openneuro.org/datasets/ds003590 and code at https://github.com/acasamitjana/3dhirest.
Machine Learning and Glioblastoma: Treatment Response Monitoring Biomarkers in 2021
Apr 15, 2021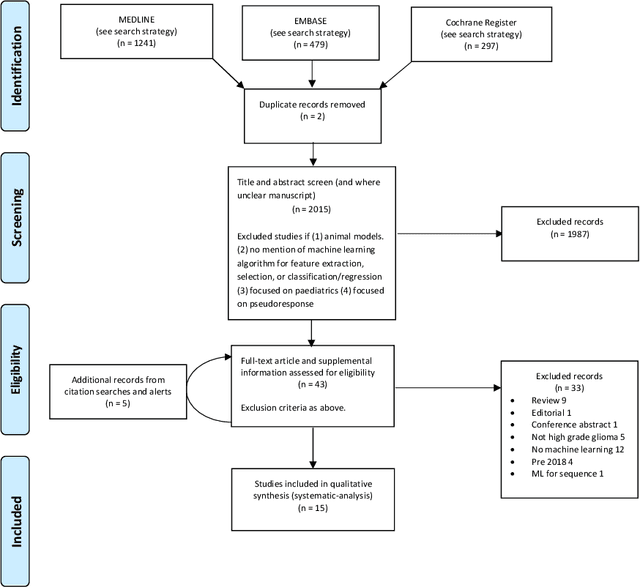
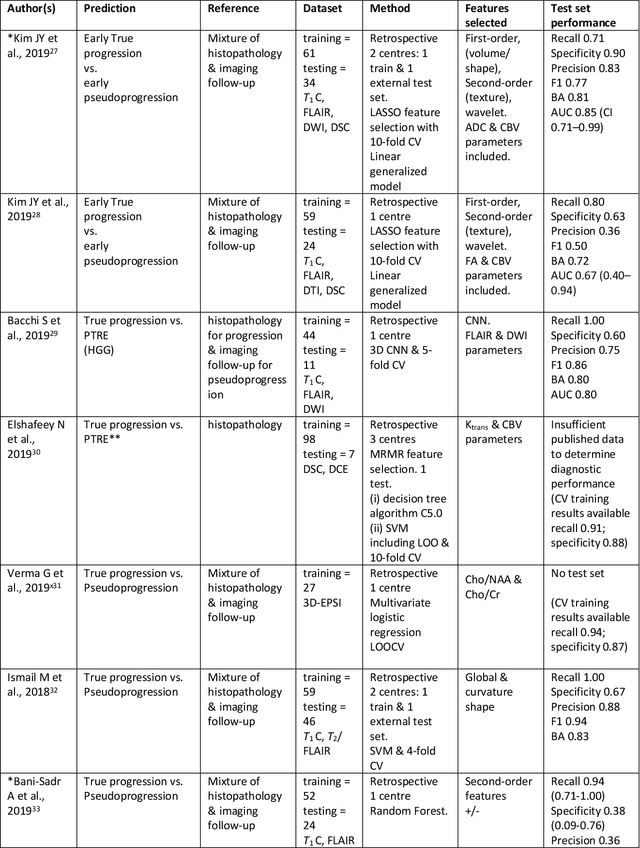
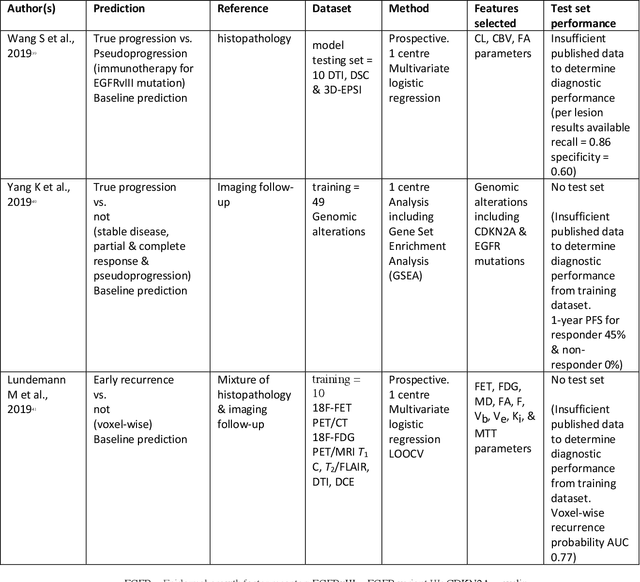
The aim of the systematic review was to assess recently published studies on diagnostic test accuracy of glioblastoma treatment response monitoring biomarkers in adults, developed through machine learning (ML). Articles were searched for using MEDLINE, EMBASE, and the Cochrane Register. Included study participants were adult patients with high grade glioma who had undergone standard treatment (maximal resection, radiotherapy with concomitant and adjuvant temozolomide) and subsequently underwent follow-up imaging to determine treatment response status. Risk of bias and applicability was assessed with QUADAS 2 methodology. Contingency tables were created for hold-out test sets and recall, specificity, precision, F1-score, balanced accuracy calculated. Fifteen studies were included with 1038 patients in training sets and 233 in test sets. To determine whether there was progression or a mimic, the reference standard combination of follow-up imaging and histopathology at re-operation was applied in 67% of studies. The small numbers of patient included in studies, the high risk of bias and concerns of applicability in the study designs (particularly in relation to the reference standard and patient selection due to confounding), and the low level of evidence, suggest that limited conclusions can be drawn from the data. There is likely good diagnostic performance of machine learning models that use MRI features to distinguish between progression and mimics. The diagnostic performance of ML using implicit features did not appear to be superior to ML using explicit features. There are a range of ML-based solutions poised to become treatment response monitoring biomarkers for glioblastoma. To achieve this, the development and validation of ML models require large, well-annotated datasets where the potential for confounding in the study design has been carefully considered.
MONAIfbs: MONAI-based fetal brain MRI deep learning segmentation
Mar 21, 2021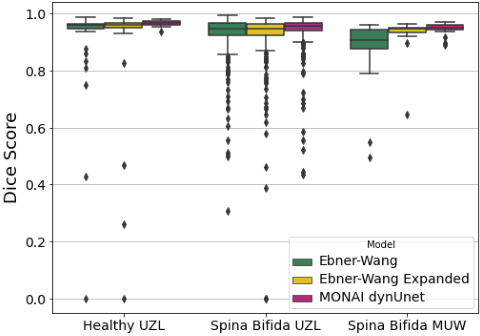
In fetal Magnetic Resonance Imaging, Super Resolution Reconstruction (SRR) algorithms are becoming popular tools to obtain high-resolution 3D volume reconstructions from low-resolution stacks of 2D slices, acquired at different orientations. To be effective, these algorithms often require accurate segmentation of the region of interest, such as the fetal brain in suspected pathological cases. In the case of Spina Bifida, Ebner, Wang et al. (NeuroImage, 2020) combined their SRR algorithm with a 2-step segmentation pipeline (2D localisation followed by a 2D segmentation network). However, if the localisation step fails, the second network is not able to recover a correct brain mask, thus requiring manual corrections for an effective SRR. In this work, we aim at improving the fetal brain segmentation for SRR in Spina Bifida. We hypothesise that a well-trained single-step UNet can achieve accurate performance, avoiding the need of a 2-step approach. We propose a new tool for fetal brain segmentation called MONAIfbs, which takes advantage of the Medical Open Network for Artificial Intelligence (MONAI) framework. Our network is based on the dynamic UNet (dynUNet), an adaptation of the nnU-Net framework. When compared to the original 2-step approach proposed in Ebner-Wang, and the same Ebner-Wang approach retrained with the expanded dataset available for this work, the dynUNet showed to achieve higher performance using a single step only. It also showed to reduce the number of outliers, as only 28 stacks obtained Dice score less than 0.9, compared to 68 for Ebner-Wang and 53 Ebner-Wang expanded. The proposed dynUNet model thus provides an improvement of the state-of-the-art fetal brain segmentation techniques, reducing the need for manual correction in automated SRR pipelines. Our code and our trained model are made publicly available at https://github.com/gift-surg/MONAIfbs.
Scale factor point spread function matching: Beyond aliasing in image resampling
Jan 16, 2021
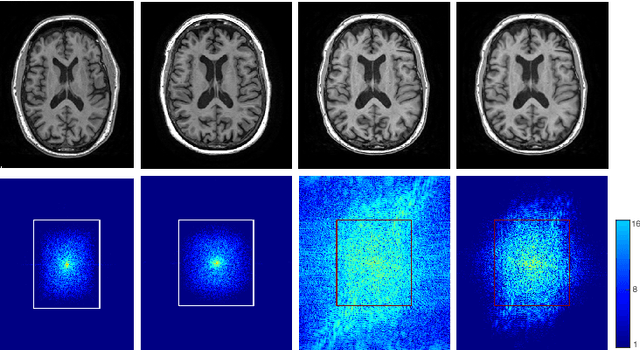
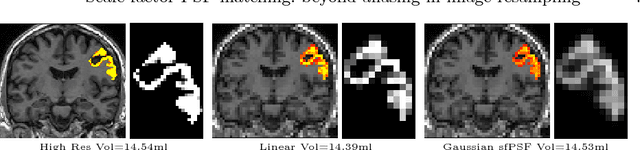
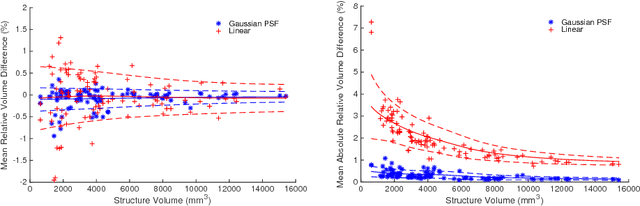
Imaging devices exploit the Nyquist-Shannon sampling theorem to avoid both aliasing and redundant oversampling by design. Conversely, in medical image resampling, images are considered as continuous functions, are warped by a spatial transformation, and are then sampled on a regular grid. In most cases, the spatial warping changes the frequency characteristics of the continuous function and no special care is taken to ensure that the resampling grid respects the conditions of the sampling theorem. This paper shows that this oversight introduces artefacts, including aliasing, that can lead to important bias in clinical applications. One notable exception to this common practice is when multi-resolution pyramids are constructed, with low-pass "anti-aliasing" filters being applied prior to downsampling. In this work, we illustrate why similar caution is needed when resampling images under general spatial transformations and propose a novel method that is more respectful of the sampling theorem, minimising aliasing and loss of information. We introduce the notion of scale factor point spread function (sfPSF) and employ Gaussian kernels to achieve a computationally tractable resampling scheme that can cope with arbitrary non-linear spatial transformations and grid sizes. Experiments demonstrate significant (p<1e-4) technical and clinical implications of the proposed method.
Scribble-based Domain Adaptation via Co-segmentation
Jul 07, 2020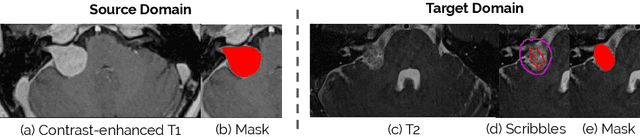
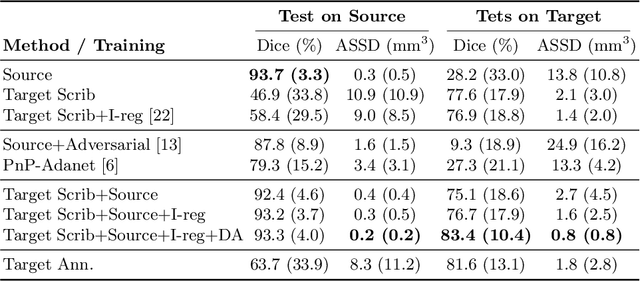
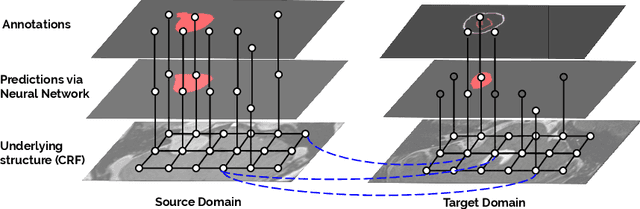
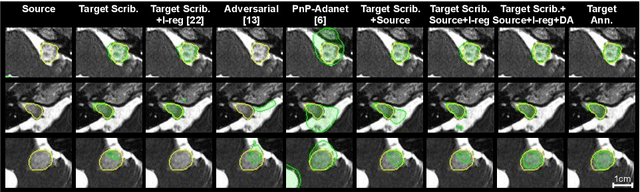
Although deep convolutional networks have reached state-of-the-art performance in many medical image segmentation tasks, they have typically demonstrated poor generalisation capability. To be able to generalise from one domain (e.g. one imaging modality) to another, domain adaptation has to be performed. While supervised methods may lead to good performance, they require to fully annotate additional data which may not be an option in practice. In contrast, unsupervised methods don't need additional annotations but are usually unstable and hard to train. In this work, we propose a novel weakly-supervised method. Instead of requiring detailed but time-consuming annotations, scribbles on the target domain are used to perform domain adaptation. This paper introduces a new formulation of domain adaptation based on structured learning and co-segmentation. Our method is easy to train, thanks to the introduction of a regularised loss. The framework is validated on Vestibular Schwannoma segmentation (T1 to T2 scans). Our proposed method outperforms unsupervised approaches and achieves comparable performance to a fully-supervised approach.
Combining multimodal information for Metal Artefact Reduction: An unsupervised deep learning framework
Apr 20, 2020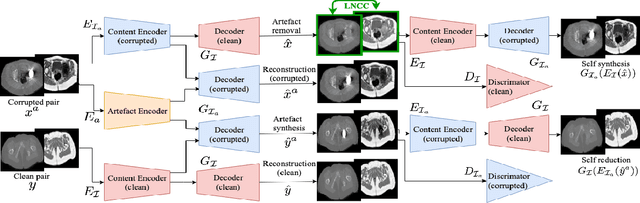
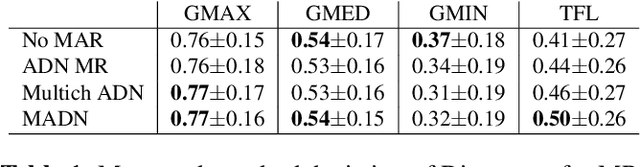
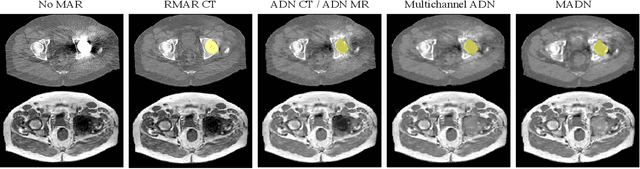
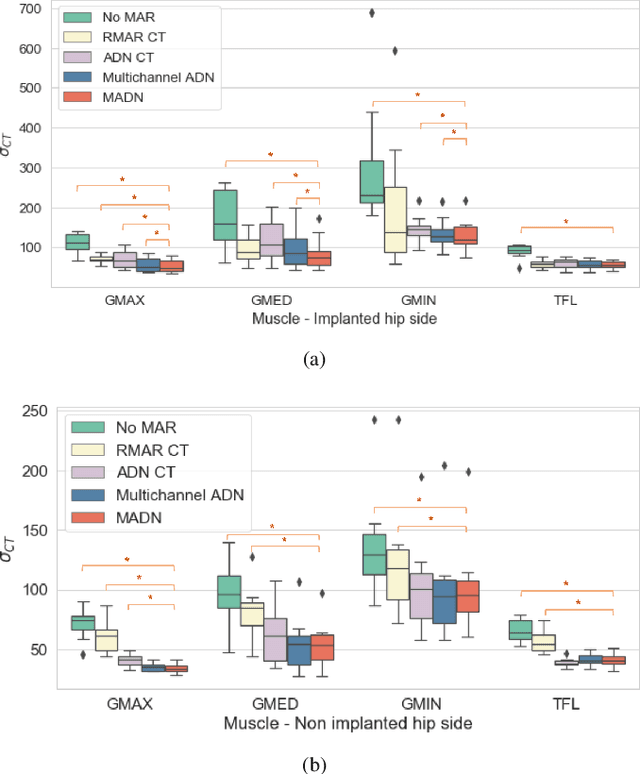
Metal artefact reduction (MAR) techniques aim at removing metal-induced noise from clinical images. In Computed Tomography (CT), supervised deep learning approaches have been shown effective but limited in generalisability, as they mostly rely on synthetic data. In Magnetic Resonance Imaging (MRI) instead, no method has yet been introduced to correct the susceptibility artefact, still present even in MAR-specific acquisitions. In this work, we hypothesise that a multimodal approach to MAR would improve both CT and MRI. Given their different artefact appearance, their complementary information can compensate for the corrupted signal in either modality. We thus propose an unsupervised deep learning method for multimodal MAR. We introduce the use of Locally Normalised Cross Correlation as a loss term to encourage the fusion of multimodal information. Experiments show that our approach favours a smoother correction in the CT, while promoting signal recovery in the MRI.
On the Initialization of Long Short-Term Memory Networks
Dec 22, 2019
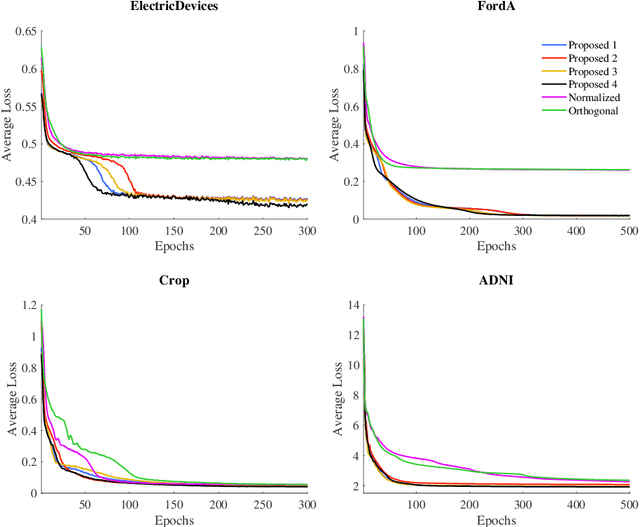
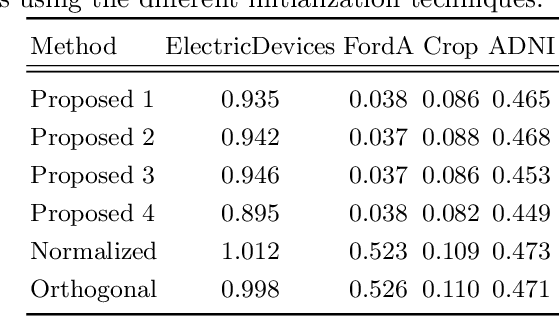
Weight initialization is important for faster convergence and stability of deep neural networks training. In this paper, a robust initialization method is developed to address the training instability in long short-term memory (LSTM) networks. It is based on a normalized random initialization of the network weights that aims at preserving the variance of the network input and output in the same range. The method is applied to standard LSTMs for univariate time series regression and to LSTMs robust to missing values for multivariate disease progression modeling. The results show that in all cases, the proposed initialization method outperforms the state-of-the-art initialization techniques in terms of training convergence and generalization performance of the obtained solution.
Multi-Domain Adaptation in Brain MRI through Paired Consistency and Adversarial Learning
Sep 17, 2019
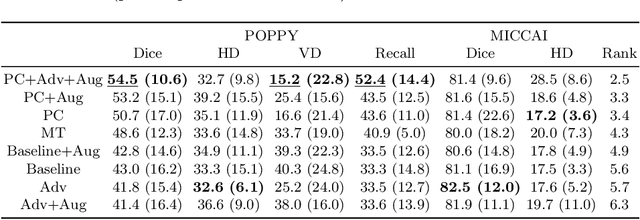
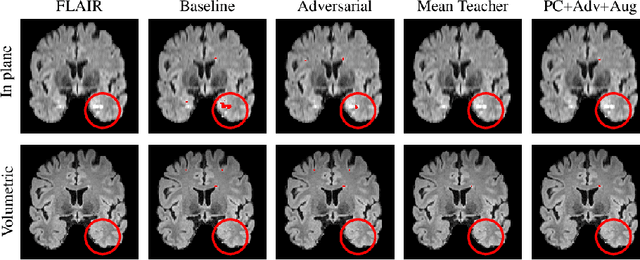
Supervised learning algorithms trained on medical images will often fail to generalize across changes in acquisition parameters. Recent work in domain adaptation addresses this challenge and successfully leverages labeled data in a source domain to perform well on an unlabeled target domain. Inspired by recent work in semi-supervised learning we introduce a novel method to adapt from one source domain to $n$ target domains (as long as there is paired data covering all domains). Our multi-domain adaptation method utilises a consistency loss combined with adversarial learning. We provide results on white matter lesion hyperintensity segmentation from brain MRIs using the MICCAI 2017 challenge data as the source domain and two target domains. The proposed method significantly outperforms other domain adaptation baselines.