 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-Distribution Runtime Adaptation with Conformalized Neural Network Ensembles
Jun 04, 2024

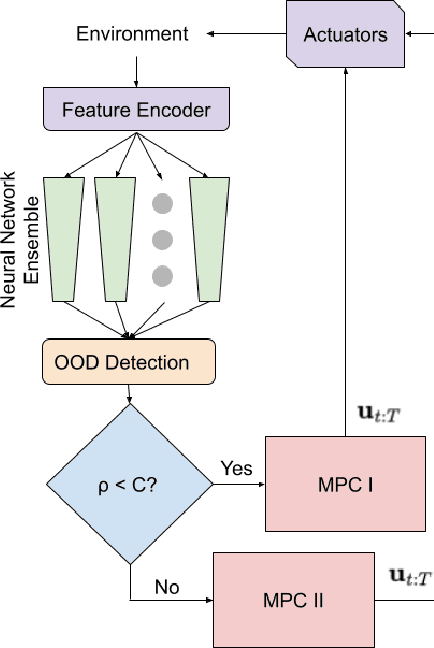

We present a method to integrate real-time out-of-distribution (OOD) detection for neural network trajectory predictors, and to adapt the control strategy of a robot (e.g., a self-driving car or drone) to preserve safety while operating in OOD regimes. Specifically, we use a neural network ensemble to predict the trajectory for a dynamic obstacle (such as a pedestrian), and use the maximum singular value of the empirical covariance among the ensemble as a signal for OOD detection. We calibrate this signal with a small fraction of held-out training data using the methodology of conformal prediction, to derive an OOD detector with probabilistic guarantees on the false-positive rate of the detector, given a user-specified confidence level. During in-distribution operation, we use an MPC controller to avoid collisions with the obstacle based on the trajectory predicted by the neural network ensemble. When OOD conditions are detected, we switch to a reachability-based controller to guarantee safety under the worst-case actions of the obstacle. We verify our method in extensive autonomous driving simulations in a pedestrian crossing scenario, showing that our OOD detector obtains the desired accuracy rate within a theoretically-predicted range. We also demonstrate the effectiveness of our method with real pedestrian data. We show improved safety and less conservatism in comparison with two state-of-the-art methods that also use conformal prediction, but without OOD adaptation.
Splat-MOVER: Multi-Stage, Open-Vocabulary Robotic Manipulation via Editable Gaussian Splatting
May 14, 2024



We present Splat-MOVER, a modular robotics stack for open-vocabulary robotic manipulation, which leverages the editability of Gaussian Splatting (GSplat) scene representations to enable multi-stage manipulation tasks. Splat-MOVER consists of: (i) ASK-Splat, a GSplat representation that distills latent codes for language semantics and grasp affordance into the 3D scene. ASK-Splat enables geometric, semantic, and affordance understanding of 3D scenes, which is critical for many robotics tasks; (ii) SEE-Splat, a real-time scene-editing module using 3D semantic masking and infilling to visualize the motions of objects that result from robot interactions in the real-world. SEE-Splat creates a "digital twin" of the evolving environment throughout the manipulation task; and (iii) Grasp-Splat, a grasp generation module that uses ASK-Splat and SEE-Splat to propose candidate grasps for open-world objects. ASK-Splat is trained in real-time from RGB images in a brief scanning phase prior to operation, while SEE-Splat and Grasp-Splat run in real-time during operation. We demonstrate the superior performance of Splat-MOVER in hardware experiments on a Kinova robot compared to two recent baselines in four single-stage, open-vocabulary manipulation tasks, as well as in four multi-stage manipulation tasks using the edited scene to reflect scene changes due to prior manipulation stages, which is not possible with the existing baselines. Code for this project and a link to the project page will be made available soon.
How Generalizable Is My Behavior Cloning Policy? A Statistical Approach to Trustworthy Performance Evaluation
May 08, 2024



With the rise of stochastic generative models in robot policy learning, end-to-end visuomotor policies are increasingly successful at solving complex tasks by learning from human demonstrations. Nevertheless, since real-world evaluation costs afford users only a small number of policy rollouts, it remains a challenge to accurately gauge the performance of such policies. This is exacerbated by distribution shifts causing unpredictable changes in performance during deployment. To rigorously evaluate behavior cloning policies, we present a framework that provides a tight lower-bound on robot performance in an arbitrary environment, using a minimal number of experimental policy rollouts. Notably, by applying the standard stochastic ordering to robot performance distributions, we provide a worst-case bound on the entire distribution of performance (via bounds on the cumulative distribution function) for a given task. We build upon established statistical results to ensure that the bounds hold with a user-specified confidence level and tightness, and are constructed from as few policy rollouts as possible. In experiments we evaluate policies for visuomotor manipulation in both simulation and hardware. Specifically, we (i) empirically validate the guarantees of the bounds in simulated manipulation settings, (ii) find the degree to which a learned policy deployed on hardware generalizes to new real-world environments, and (iii) rigorously compare two policies tested in out-of-distribution settings. Our experimental data, code, and implementation of confidence bounds are open-source.
$\textbf{Splat-MOVER}$: Multi-Stage, Open-Vocabulary Robotic Manipulation via Editable Gaussian Splatting
May 07, 2024We present Splat-MOVER, a modular robotics stack for open-vocabulary robotic manipulation, which leverages the editability of Gaussian Splatting (GSplat) scene representations to enable multi-stage manipulation tasks. Splat-MOVER consists of: (i) $\textit{ASK-Splat}$, a GSplat representation that distills latent codes for language semantics and grasp affordance into the 3D scene. ASK-Splat enables geometric, semantic, and affordance understanding of 3D scenes, which is critical for many robotics tasks; (ii) $\textit{SEE-Splat}$, a real-time scene-editing module using 3D semantic masking and infilling to visualize the motions of objects that result from robot interactions in the real-world. SEE-Splat creates a "digital twin" of the evolving environment throughout the manipulation task; and (iii) $\textit{Grasp-Splat}$, a grasp generation module that uses ASK-Splat and SEE-Splat to propose candidate grasps for open-world objects. ASK-Splat is trained in real-time from RGB images in a brief scanning phase prior to operation, while SEE-Splat and Grasp-Splat run in real-time during operation. We demonstrate the superior performance of Splat-MOVER in hardware experiments on a Kinova robot compared to two recent baselines in four single-stage, open-vocabulary manipulation tasks, as well as in four multi-stage manipulation tasks using the edited scene to reflect scene changes due to prior manipulation stages, which is not possible with the existing baselines. Code for this project and a link to the project page will be made available soon.
CLIPSwarm: Generating Drone Shows from Text Prompts with Vision-Language Models
Mar 20, 2024



This paper introduces CLIPSwarm, a new algorithm designed to automate the modeling of swarm drone formations based on natural language. The algorithm begins by enriching a provided word, to compose a text prompt that serves as input to an iterative approach to find the formation that best matches the provided word. The algorithm iteratively refines formations of robots to align with the textual description, employing different steps for "exploration" and "exploitation". Our framework is currently evaluated on simple formation targets, limited to contour shapes. A formation is visually represented through alpha-shape contours and the most representative color is automatically found for the input word. To measure the similarity between the description and the visual representation of the formation, we use CLIP [1], encoding text and images into vectors and assessing their similarity. Subsequently, the algorithm rearranges the formation to visually represent the word more effectively, within the given constraints of available drones. Control actions are then assigned to the drones, ensuring robotic behavior and collision-free movement. Experimental results demonstrate the system's efficacy in accurately modeling robot formations from natural language descriptions. The algorithm's versatility is showcased through the execution of drone shows in photorealistic simulation with varying shapes. We refer the reader to the supplementary video for a visual reference of the results.
Touch-GS: Visual-Tactile Supervised 3D Gaussian Splatting
Mar 18, 2024In this work, we propose a novel method to supervise 3D Gaussian Splatting (3DGS) scenes using optical tactile sensors. Optical tactile sensors have become widespread in their use in robotics for manipulation and object representation; however, raw optical tactile sensor data is unsuitable to directly supervise a 3DGS scene. Our representation leverages a Gaussian Process Implicit Surface to implicitly represent the object, combining many touches into a unified representation with uncertainty. We merge this model with a monocular depth estimation network, which is aligned in a two stage process, coarsely aligning with a depth camera and then finely adjusting to match our touch data. For every training image, our method produces a corresponding fused depth and uncertainty map. Utilizing this additional information, we propose a new loss function, variance weighted depth supervised loss, for training the 3DGS scene model. We leverage the DenseTact optical tactile sensor and RealSense RGB-D camera to show that combining touch and vision in this manner leads to quantitatively and qualitatively better results than vision or touch alone in a few-view scene syntheses on opaque as well as on reflective and transparent objects. Please see our project page at http://armlabstanford.github.io/touch-gs
Splat-Nav: Safe Real-Time Robot Navigation in Gaussian Splatting Maps
Mar 05, 2024We present Splat-Nav, a navigation pipeline that consists of a real-time safe planning module and a robust state estimation module designed to operate in the Gaussian Splatting (GSplat) environment representation, a popular emerging 3D scene representation from computer vision. We formulate rigorous collision constraints that can be computed quickly to build a guaranteed-safe polytope corridor through the map. We then optimize a B-spline trajectory through this corridor. We also develop a real-time, robust state estimation module by interpreting the GSplat representation as a point cloud. The module enables the robot to localize its global pose with zero prior knowledge from RGB-D images using point cloud alignment, and then track its own pose as it moves through the scene from RGB images using image-to-point cloud localization. We also incorporate semantics into the GSplat in order to obtain better images for localization. All of these modules operate mainly on CPU, freeing up GPU resources for tasks like real-time scene reconstruction. We demonstrate the safety and robustness of our pipeline in both simulation and hardware, where we show re-planning at 5 Hz and pose estimation at 20 Hz, an order of magnitude faster than Neural Radiance Field (NeRF)-based navigation methods, thereby enabling real-time navigation.
CineMPC: A Fully Autonomous Drone Cinematography System Incorporating Zoom, Focus, Pose, and Scene Composition
Jan 10, 2024We present CineMPC, a complete cinematographic system that autonomously controls a drone to film multiple targets recording user-specified aesthetic objectives. Existing solutions in autonomous cinematography control only the camera extrinsics, namely its position, and orientation. In contrast, CineMPC is the first solution that includes the camera intrinsic parameters in the control loop, which are essential tools for controlling cinematographic effects like focus, depth-of-field, and zoom. The system estimates the relative poses between the targets and the camera from an RGB-D image and optimizes a trajectory for the extrinsic and intrinsic camera parameters to film the artistic and technical requirements specified by the user. The drone and the camera are controlled in a nonlinear Model Predicted Control (MPC) loop by re-optimizing the trajectory at each time step in response to current conditions in the scene. The perception system of CineMPC can track the targets' position and orientation despite the camera effects. Experiments in a photorealistic simulation and with a real platform demonstrate the capabilities of the system to achieve a full array of cinematographic effects that are not possible without the control of the intrinsics of the camera. Code for CineMPC is implemented following a modular architecture in ROS and released to the community.
Foundation Models in Robotics: Applications, Challenges, and the Future
Dec 13, 2023


We survey applications of pretrained foundation models in robotics. Traditional deep learning models in robotics are trained on small datasets tailored for specific tasks, which limits their adaptability across diverse applications. In contrast, foundation models pretrained on internet-scale data appear to have superior generalization capabilities, and in some instances display an emergent ability to find zero-shot solutions to problems that are not present in the training data. Foundation models may hold the potential to enhance various components of the robot autonomy stack, from perception to decision-making and control. For example, large language models can generate code or provide common sense reasoning, while vision-language models enable open-vocabulary visual recognition. However, significant open research challenges remain, particularly around the scarcity of robot-relevant training data, safety guarantees and uncertainty quantification, and real-time execution. In this survey, we study recent papers that have used or built foundation models to solve robotics problems. We explore how foundation models contribute to improving robot capabilities in the domains of perception, decision-making, and control. We discuss the challenges hindering the adoption of foundation models in robot autonomy and provide opportunities and potential pathways for future advancements. The GitHub project corresponding to this paper (Preliminary release. We are committed to further enhancing and updating this work to ensure its quality and relevance) can be found here: https://github.com/robotics-survey/Awesome-Robotics-Foundation-Models
CLIPSwarm: Converting text into formations of robots
Nov 18, 2023



We present CLIPSwarm, an algorithm to generate robot swarm formations from natural language descriptions. CLIPSwarm receives an input text and finds the position of the robots to form a shape that corresponds to the given text. To do so, we implement a variation of the Montecarlo particle filter to obtain a matching formation iteratively. In every iteration, we generate a set of new formations and evaluate their Clip Similarity with the given text, selecting the best formations according to this metric. This metric is obtained using Clip, [1], an existing foundation model trained to encode images and texts into vectors within a common latent space. The comparison between these vectors determines how likely the given text describes the shapes. Our initial proof of concept shows the potential of this solution to generate robot swarm formations just from natural language descriptions and demonstrates a novel application of foundation models, such as CLIP, in the field of multi-robot systems. In this first approach, we create formations using a Convex-Hull approach. Next steps include more robust and generic representation and optimization steps in the process of obtaining a suitable swarm formation.
* Please cite this article as "P. Pueyo, E. Montijano, A. C. Murillo, and M. Schwager, CLIPSwarm: Converting text into formations of robots. ICRA 2023 Workshop on Multi-Robot Learning"