 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Theory of Mind: A Decentralized Diffusion Architecture for Cooperative Manipulation
May 14, 2025



We present Latent Theory of Mind (LatentToM), a decentralized diffusion policy architecture for collaborative robot manipulation. Our policy allows multiple manipulators with their own perception and computation to collaborate with each other towards a common task goal with or without explicit communication. Our key innovation lies in allowing each agent to maintain two latent representations: an ego embedding specific to the robot, and a consensus embedding trained to be common to both robots, despite their different sensor streams and poses. We further let each robot train a decoder to infer the other robot's ego embedding from their consensus embedding, akin to theory of mind in latent space. Training occurs centrally, with all the policies' consensus encoders supervised by a loss inspired by sheaf theory, a mathematical theory for clustering data on a topological manifold. Specifically, we introduce a first-order cohomology loss to enforce sheaf-consistent alignment of the consensus embeddings. To preserve the expressiveness of the consensus embedding, we further propose structural constraints based on theory of mind and a directional consensus mechanism. Execution can be fully distributed, requiring no explicit communication between policies. In which case, the information is exchanged implicitly through each robot's sensor stream by observing the actions of the other robots and their effects on the scene. Alternatively, execution can leverage direct communication to share the robots' consensus embeddings, where the embeddings are shared once during each inference step and are aligned using the sheaf Laplacian. In our hardware experiments, LatentToM outperforms a naive decentralized diffusion baseline, and shows comparable performance with a state-of-the-art centralized diffusion policy for bi-manual manipulation. Project website: https://stanfordmsl.github.io/LatentToM/.
Demystifying Diffusion Policies: Action Memorization and Simple Lookup Table Alternatives
May 09, 2025Diffusion policies have demonstrated remarkable dexterity and robustness in intricate, high-dimensional robot manipulation tasks, while training from a small number of demonstrations. However, the reason for this performance remains a mystery. In this paper, we offer a surprising hypothesis: diffusion policies essentially memorize an action lookup table -- and this is beneficial. We posit that, at runtime, diffusion policies find the closest training image to the test image in a latent space, and recall the associated training action sequence, offering reactivity without the need for action generalization. This is effective in the sparse data regime, where there is not enough data density for the model to learn action generalization. We support this claim with systematic empirical evidence. Even when conditioned on wildly out of distribution (OOD) images of cats and dogs, the Diffusion Policy still outputs an action sequence from the training data. With this insight, we propose a simple policy, the Action Lookup Table (ALT), as a lightweight alternative to the Diffusion Policy. Our ALT policy uses a contrastive image encoder as a hash function to index the closest corresponding training action sequence, explicitly performing the computation that the Diffusion Policy implicitly learns. We show empirically that for relatively small datasets, ALT matches the performance of a diffusion model, while requiring only 0.0034 of the inference time and 0.0085 of the memory footprint, allowing for much faster closed-loop inference with resource constrained robots. We also train our ALT policy to give an explicit OOD flag when the distance between the runtime image is too far in the latent space from the training images, giving a simple but effective runtime monitor. More information can be found at: https://stanfordmsl.github.io/alt/.
Touch-GS: Visual-Tactile Supervised 3D Gaussian Splatting
Mar 18, 2024In this work, we propose a novel method to supervise 3D Gaussian Splatting (3DGS) scenes using optical tactile sensors. Optical tactile sensors have become widespread in their use in robotics for manipulation and object representation; however, raw optical tactile sensor data is unsuitable to directly supervise a 3DGS scene. Our representation leverages a Gaussian Process Implicit Surface to implicitly represent the object, combining many touches into a unified representation with uncertainty. We merge this model with a monocular depth estimation network, which is aligned in a two stage process, coarsely aligning with a depth camera and then finely adjusting to match our touch data. For every training image, our method produces a corresponding fused depth and uncertainty map. Utilizing this additional information, we propose a new loss function, variance weighted depth supervised loss, for training the 3DGS scene model. We leverage the DenseTact optical tactile sensor and RealSense RGB-D camera to show that combining touch and vision in this manner leads to quantitatively and qualitatively better results than vision or touch alone in a few-view scene syntheses on opaque as well as on reflective and transparent objects. Please see our project page at http://armlabstanford.github.io/touch-gs
Learning Deep SDF Maps Online for Robot Navigation and Exploration
Aug 02, 2022
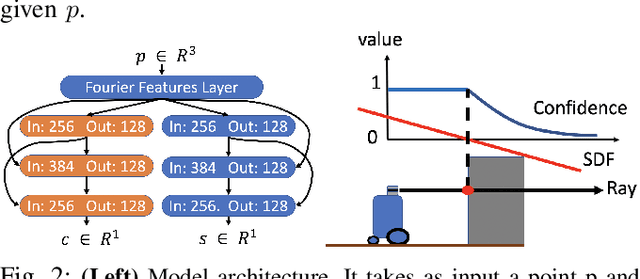

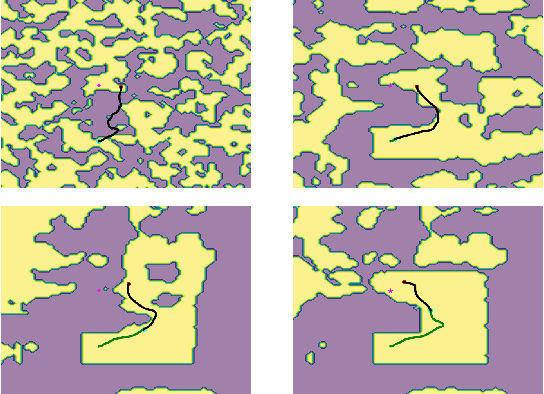
We propose an algorithm to (i) learn online a deep signed distance function (SDF) with a LiDAR-equipped robot to represent the 3D environment geometry, and (ii) plan collision-free trajectories given this deep learned map. Our algorithm takes a stream of incoming LiDAR scans and continually optimizes a neural network to represent the SDF of the environment around its current vicinity. When the SDF network quality saturates, we cache a copy of the network, along with a learned confidence metric, and initialize a new SDF network to continue mapping new regions of the environment. We then concatenate all the cached local SDFs through a confidence-weighted scheme to give a global SDF for planning. For planning, we make use of a sequential convex model predictive control (MPC) algorithm. The MPC planner optimizes a dynamically feasible trajectory for the robot while enforcing no collisions with obstacles mapped in the global SDF. We show that our online mapping algorithm produces higher-quality maps than existing methods for online SDF training. In the WeBots simulator, we further showcase the combined mapper and planner running online -- navigating autonomously and without collisions in an unknown environment.