 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention2Probability: Attention-Driven Terminology Probability Estimation for Robust Speech-to-Text System
Aug 26, 2025Recent advances in speech large language models (SLMs) have improved speech recognition and translation in general domains, but accurately generating domain-specific terms or neologisms remains challenging. To address this, we propose Attention2Probability: attention-driven terminology probability estimation for robust speech-to-text system, which is lightweight, flexible, and accurate. Attention2Probability converts cross-attention weights between speech and terminology into presence probabilities, and it further employs curriculum learning to enhance retrieval accuracy. Furthermore, to tackle the lack of data for speech-to-text tasks with terminology intervention, we create and release a new speech dataset with terminology to support future research in this area. Experimental results show that Attention2Probability significantly outperforms the VectorDB method on our test set. Specifically, its maximum recall rates reach 92.57% for Chinese and 86.83% for English. This high recall is achieved with a latency of only 8.71ms per query. Intervening in SLMs' recognition and translation tasks using Attention2Probability-retrieved terms improves terminology accuracy by 6-17%, while revealing that the current utilization of terminology by SLMs has limitations.
A GAN-Enhanced Deep Learning Framework for Rooftop Detection from Historical Aerial Imagery
Mar 29, 2025Accurate rooftop detection from historical aerial imagery is vital for examining long-term urban development and human settlement patterns. However, black-and-white analog photographs pose significant challenges for modern object detection frameworks due to their limited spatial resolution, lack of color information, and archival degradation. To address these limitations, this study introduces a two-stage image enhancement pipeline based on Generative Adversarial Networks (GANs): image colorization using DeOldify, followed by super-resolution enhancement with Real-ESRGAN. The enhanced images were then used to train and evaluate rooftop detection models, including Faster R-CNN, DETReg, and YOLOv11n. Results show that combining colorization with super-resolution substantially improves detection performance, with YOLOv11n achieving a mean Average Precision (mAP) exceeding 85%. This reflects an improvement of approximately 40% over original black-and-white images and 20% over images enhanced through colorization alone. The proposed method effectively bridges the gap between archival imagery and contemporary deep learning techniques, enabling more reliable extraction of building footprints from historical aerial photographs.
Classifier Clustering and Feature Alignment for Federated Learning under Distributed Concept Drift
Oct 24, 2024



Data heterogeneity is one of the key challenges in federated learning, and many efforts have been devoted to tackling this problem. However, distributed concept drift with data heterogeneity, where clients may additionally experience different concept drifts, is a largely unexplored area. In this work, we focus on real drift, where the conditional distribution $P(Y|X)$ changes. We first study how distributed concept drift affects the model training and find that local classifier plays a critical role in drift adaptation. Moreover, to address data heterogeneity, we study the feature alignment under distributed concept drift, and find two factors that are crucial for feature alignment: the conditional distribution $P(Y|X)$ and the degree of data heterogeneity. Motivated by the above findings, we propose FedCCFA, a federated learning framework with classifier clustering and feature alignment. To enhance collaboration under distributed concept drift, FedCCFA clusters local classifiers at class-level and generates clustered feature anchors according to the clustering results. Assisted by these anchors, FedCCFA adaptively aligns clients' feature spaces based on the entropy of label distribution $P(Y)$, alleviating the inconsistency in feature space. Our results demonstrate that FedCCFA significantly outperforms existing methods under various concept drift settings. Code is available at https://github.com/Chen-Junbao/FedCCFA.
Asymptotically Optimal Lazy Lifelong Sampling-based Algorithm for Efficient Motion Planning in Dynamic Environments
Sep 10, 2024



The paper introduces an asymptotically optimal lifelong sampling-based path planning algorithm that combines the merits of lifelong planning algorithms and lazy search algorithms for rapid replanning in dynamic environments where edge evaluation is expensive. By evaluating only sub-path candidates for the optimal solution, the algorithm saves considerable evaluation time and thereby reduces the overall planning cost. It employs a novel informed rewiring cascade to efficiently repair the search tree when the underlying search graph changes. Simulation results demonstrate that the algorithm outperforms various state-of-the-art sampling-based planners in addressing both static and dynamic motion planning problems.
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Jul 05, 2024



Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
Deep-learning-based groupwise registration for motion correction of cardiac $T_1$ mapping
Jun 21, 2024Quantitative $T_1$ mapping by MRI is an increasingly important tool for clinical assessment of cardiovascular diseases. The cardiac $T_1$ map is derived by fitting a known signal model to a series of baseline images, while the quality of this map can be deteriorated by involuntary respiratory and cardiac motion. To correct motion, a template image is often needed to register all baseline images, but the choice of template is nontrivial, leading to inconsistent performance sensitive to image contrast. In this work, we propose a novel deep-learning-based groupwise registration framework, which omits the need for a template, and registers all baseline images simultaneously. We design two groupwise losses for this registration framework: the first is a linear principal component analysis (PCA) loss that enforces alignment of baseline images irrespective of the intensity variation, and the second is an auxiliary relaxometry loss that enforces adherence of intensity profile to the signal model. We extensively evaluated our method, termed ``PCA-Relax'', and other baseline methods on an in-house cardiac MRI dataset including both pre- and post-contrast $T_1$ sequences. All methods were evaluated under three distinct training-and-evaluation strategies, namely, standard, one-shot, and test-time-adaptation. The proposed PCA-Relax showed further improved performance of registration and mapping over well-established baselines. The proposed groupwise framework is generic and can be adapted to applications involving multiple images.
PCA-Relax: Deep-learning-based groupwise registration for motion correction of cardiac $T_1$ mapping
Jun 18, 2024Quantitative MRI (qMRI) is an increasingly important tool for clinical assessment of cardiovascular diseases. Quantitative maps are derived by fitting a known signal model to a series of baseline images, while the quality of the map can be deteriorated by involuntary respiratory and cardiac motion. To correct motion, a template image is often needed to register all baseline images, but the choice of template is nontrivial, leading to inconsistent performance sensitive to image contrast. In this work, we propose a novel deep-learning-based groupwise registration framework, which omits the need for a template, and registers all baseline images simultaneously. We design two groupwise losses for this registration framework: the first is a linear principal component analysis (PCA) loss that enforces alignment of baseline images irrespective of the intensity variation, and the second is an auxiliary relaxometry loss that enforces adherence of intensity profile to the signal model. We extensively evaluated our method, termed ``PCA-Relax'', and other baseline methods on an in-house cardiac MRI dataset including both pre- and post-contrast $T_1$ sequences. All methods were evaluated under three distinct training-and-evaluation strategies, namely, standard, one-shot, and test-time-adaptation. The proposed PCA-Relax showed further improved performance of registration and mapping over well-established baselines. The proposed groupwise framework is generic and can be adapted to applications involving multiple images.
Improving Large-scale Deep Biasing with Phoneme Features and Text-only Data in Streaming Transducer
Nov 15, 2023



Deep biasing for the Transducer can improve the recognition performance of rare words or contextual entities, which is essential in practical applications, especially for streaming Automatic Speech Recognition (ASR). However, deep biasing with large-scale rare words remains challenging, as the performance drops significantly when more distractors exist and there are words with similar grapheme sequences in the bias list. In this paper, we combine the phoneme and textual information of rare words in Transducers to distinguish words with similar pronunciation or spelling. Moreover, the introduction of training with text-only data containing more rare words benefits large-scale deep biasing. The experiments on the LibriSpeech corpus demonstrate that the proposed method achieves state-of-the-art performance on rare word error rate for different scales and levels of bias lists.
Text-only Domain Adaptation using Unified Speech-Text Representation in Transducer
Jun 07, 2023Domain adaptation using text-only corpus is challenging in end-to-end(E2E) speech recognition. Adaptation by synthesizing audio from text through TTS is resource-consuming. We present a method to learn Unified Speech-Text Representation in Conformer Transducer(USTR-CT) to enable fast domain adaptation using the text-only corpus. Different from the previous textogram method, an extra text encoder is introduced in our work to learn text representation and is removed during inference, so there is no modification for online deployment. To improve the efficiency of adaptation, single-step and multi-step adaptations are also explored. The experiments on adapting LibriSpeech to SPGISpeech show the proposed method reduces the word error rate(WER) by relatively 44% on the target domain, which is better than those of TTS method and textogram method. Also, it is shown the proposed method can be combined with internal language model estimation(ILME) to further improve the performance.
HMM-Free Encoder Pre-Training for Streaming RNN Transducer
Apr 02, 2021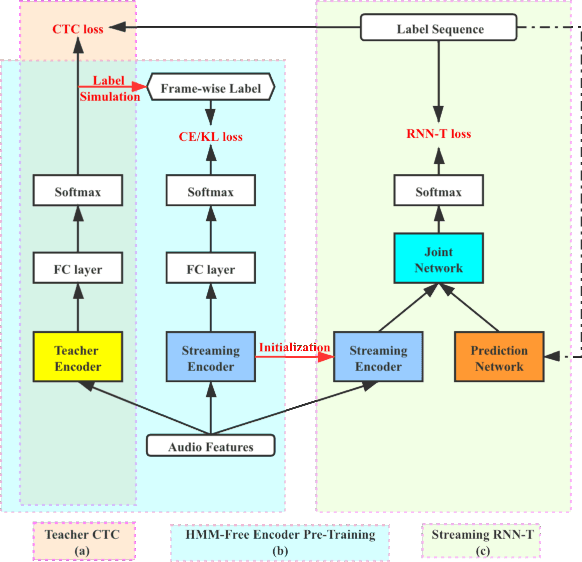
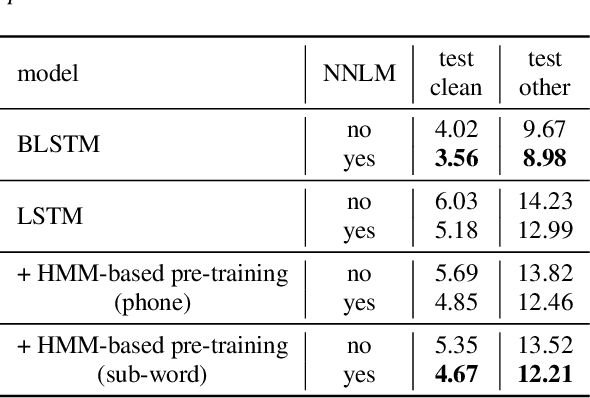
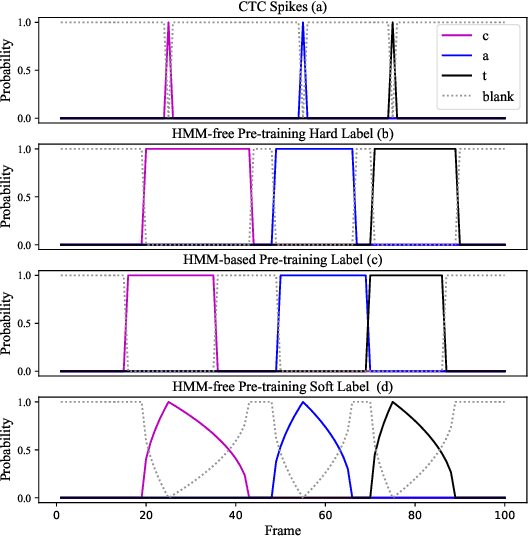
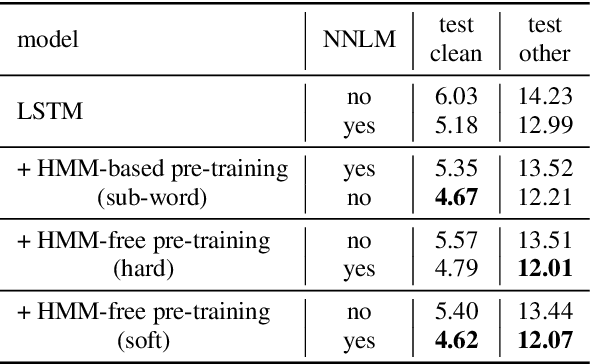
This work describes an encoder pre-training procedure using frame-wise label to improve the training of streaming recurrent neural network transducer (RNN-T) model. Streaming RNN-T trained from scratch usually performs worse and has high latency. Although it is common to address these issues through pre-training components of RNN-T with other criteria or frame-wise alignment guidance, the alignment is not easily available in end-to-end manner. In this work, frame-wise alignment, used to pre-train streaming RNN-T's encoder, is generated without using a HMM-based system. Therefore an all-neural framework equipping HMM-free encoder pre-training is constructed. This is achieved by expanding the spikes of CTC model to their left/right blank frames, and two expanding strategies are proposed. To our best knowledge, this is the first work to simulate HMM-based frame-wise label using CTC model. Experiments conducted on LibriSpeech and MLS English tasks show the proposed pre-training procedure, compared with random initialization, reduces the WER by relatively 5%~11% and the emission latency by 60 ms. Besides, the method is lexicon-free, so it is friendly to new languages without manually designed lexicon.