 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEAD: LiDAR Extender for Autonomous Driving
Feb 16, 2021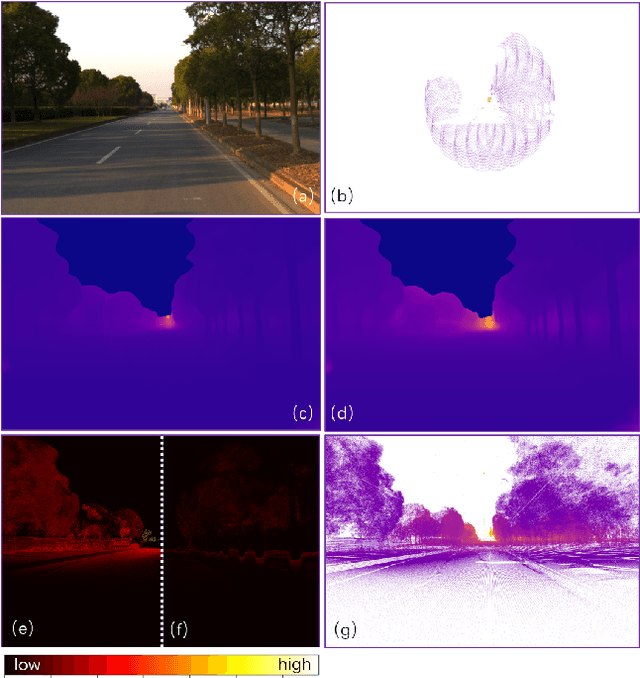
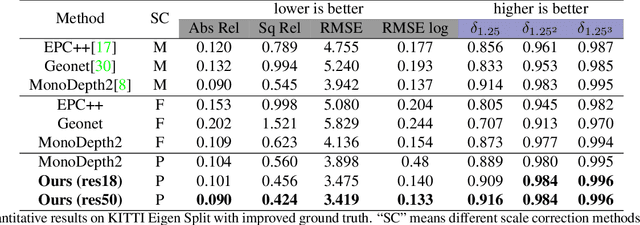
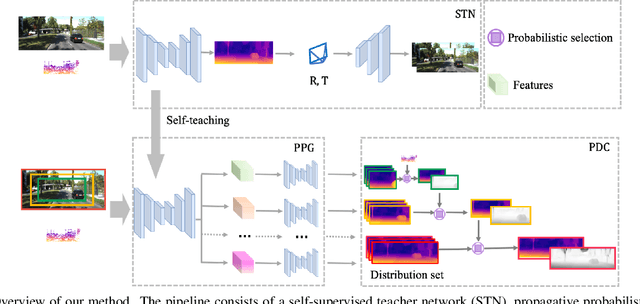
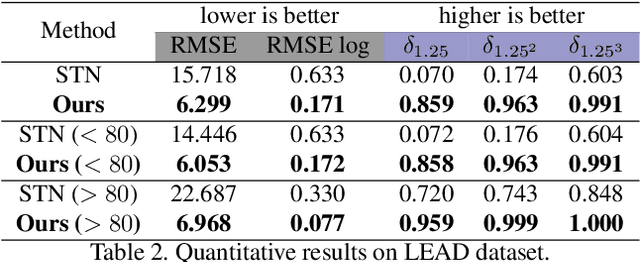
3D perception using sensors under vehicle industrial standard is the rigid demand in autonomous driving. MEMS LiDAR emerges with irresistible trend due to its lower cost, more robust, and meeting the mass-production standards. However, it suffers small field of view (FoV), slowing down the step of its population. In this paper, we propose LEAD, i.e., LiDAR Extender for Autonomous Driving, to extend the MEMS LiDAR by coupled image w.r.t both FoV and range. We propose a multi-stage propagation strategy based on depth distributions and uncertainty map, which shows effective propagation ability. Moreover, our depth outpainting/propagation network follows a teacher-student training fashion, which transfers depth estimation ability to depth completion network without any scale error passed. To validate the LiDAR extension quality, we utilize a high-precise laser scanner to generate a ground-truth dataset. Quantitative and qualitative evaluations show that our scheme outperforms SOTAs with a large margin. We believe the proposed LEAD along with the dataset would benefit the community w.r.t depth researches.
Large-scale neuromorphic optoelectronic computing with a reconfigurable diffractive processing unit
Aug 26, 2020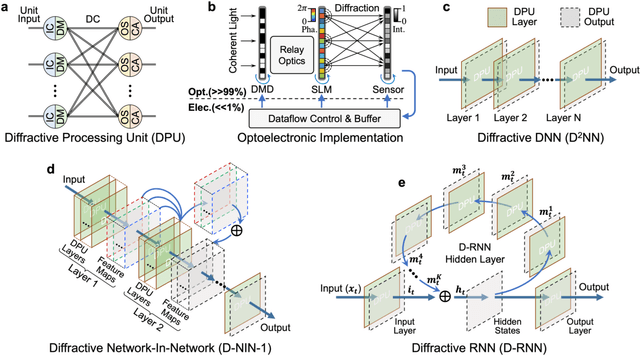
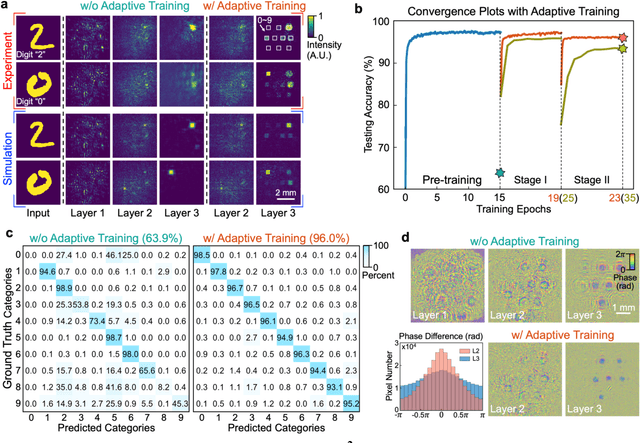
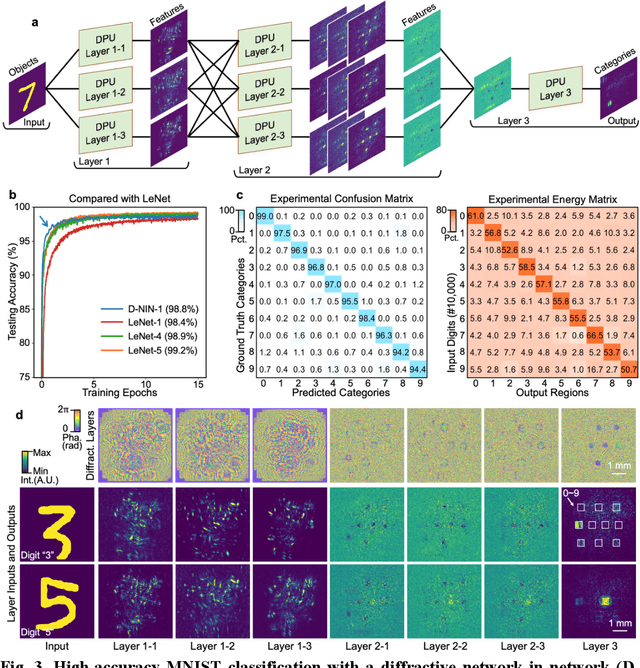
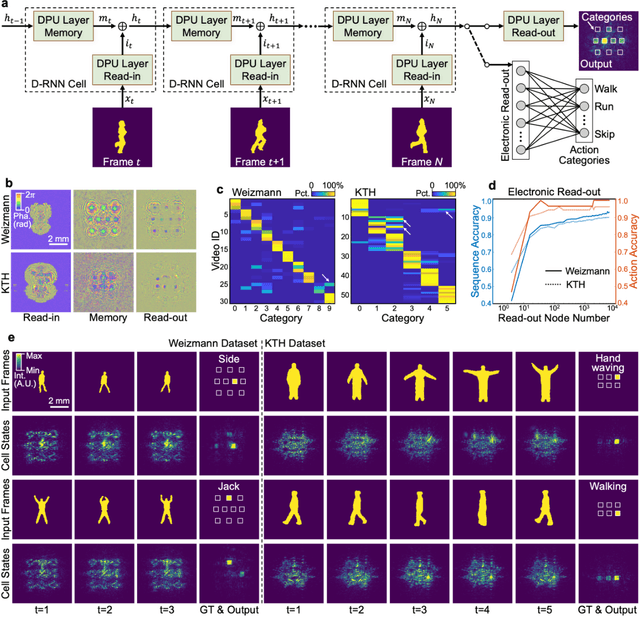
Application-specific optical processors have been considered disruptive technologies for modern computing that can fundamentally accelerate the development of artificial intelligence (AI) by offering substantially improved computing performance. Recent advancements in optical neural network architectures for neural information processing have been applied to perform various machine learning tasks. However, the existing architectures have limited complexity and performance; and each of them requires its own dedicated design that cannot be reconfigured to switch between different neural network models for different applications after deployment. Here, we propose an optoelectronic reconfigurable computing paradigm by constructing a diffractive processing unit (DPU) that can efficiently support different neural networks and achieve a high model complexity with millions of neurons. It allocates almost all of its computational operations optically and achieves extremely high speed of data modulation and large-scale network parameter updating by dynamically programming optical modulators and photodetectors. We demonstrated the reconfiguration of the DPU to implement various diffractive feedforward and recurrent neural networks and developed a novel adaptive training approach to circumvent the system imperfections. We applied the trained networks for high-speed classifying of handwritten digit images and human action videos over benchmark datasets, and the experimental results revealed a comparable classification accuracy to the electronic computing approaches. Furthermore, our prototype system built with off-the-shelf optoelectronic components surpasses the performance of state-of-the-art graphics processing units (GPUs) by several times on computing speed and more than an order of magnitude on system energy efficiency.
Spatial-Angular Attention Network for Light Field Reconstruction
Jul 05, 2020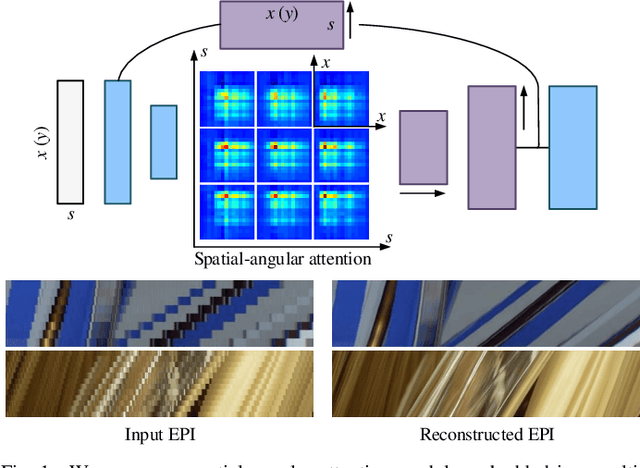
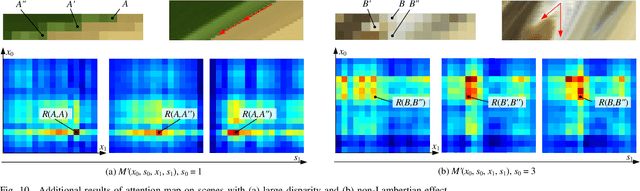

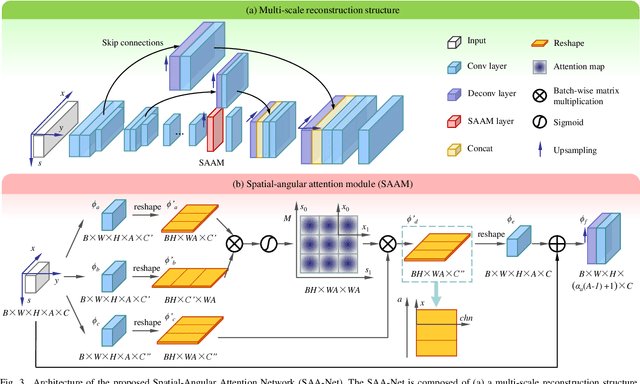
Learning-based light field reconstruction methods demand in constructing a large receptive field by deepening the network to capture correspondences between input views. In this paper, we propose a spatial-angular attention network to perceive correspondences in the light field non-locally, and reconstruction high angular resolution light field in an end-to-end manner. Motivated by the non-local attention mechanism, a spatial-angular attention module specifically for the high-dimensional light field data is introduced to compute the responses from all the positions in the epipolar plane for each pixel in the light field, and generate an attention map that captures correspondences along the angular dimension. We then propose a multi-scale reconstruction structure to efficiently implement the non-local attention in the low spatial scale, while also preserving the high frequency components in the high spatial scales. Extensive experiments demonstrate the superior performance of the proposed spatial-angular attention network for reconstructing sparsely-sampled light fields with non-Lambertian effects.
Zoom in to the details of human-centric videos
May 27, 2020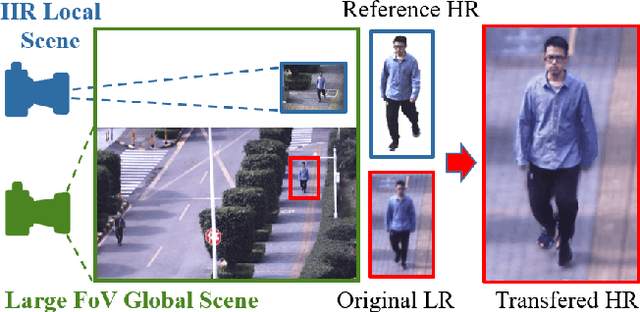
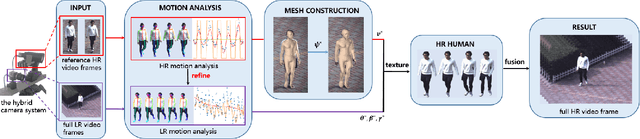
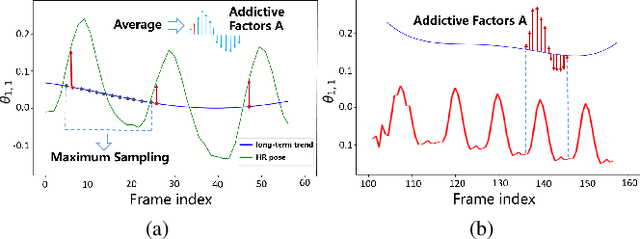

Presenting high-resolution (HR) human appearance is always critical for the human-centric videos. However, current imagery equipment can hardly capture HR details all the time. Existing super-resolution algorithms barely mitigate the problem by only considering universal and low-level priors of im-age patches. In contrast, our algorithm is under bias towards the human body super-resolution by taking advantage of high-level prior defined by HR human appearance. Firstly, a motion analysis module extracts inherent motion pattern from the HR reference video to refine the pose estimation of the low-resolution (LR) sequence. Furthermore, a human body reconstruction module maps the HR texture in the reference frames onto a 3D mesh model. Consequently, the input LR videos get super-resolved HR human sequences are generated conditioned on the original LR videos as well as few HR reference frames. Experiments on an existing dataset and real-world data captured by hybrid cameras show that our approach generates superior visual quality of human body compared with the traditional method.
SurfaceNet+: An End-to-end 3D Neural Network for Very Sparse Multi-view Stereopsis
May 26, 2020
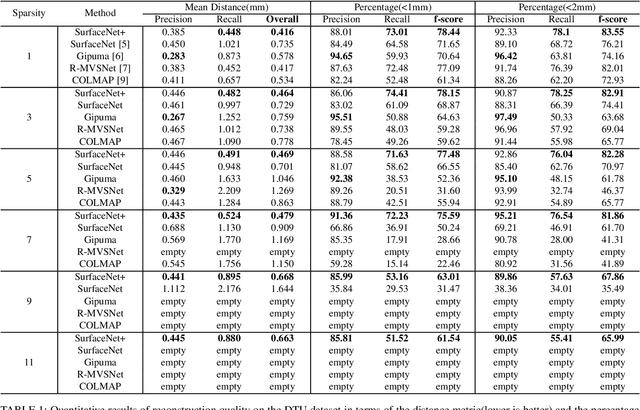
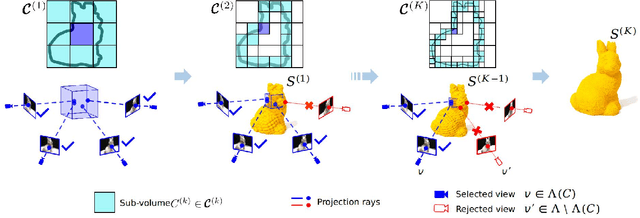
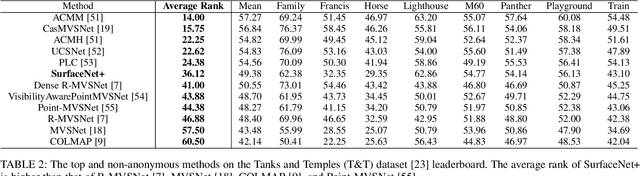
Multi-view stereopsis (MVS) tries to recover the 3D model from 2D images. As the observations become sparser, the significant 3D information loss makes the MVS problem more challenging. Instead of only focusing on densely sampled conditions, we investigate sparse-MVS with large baseline angles since the sparser sensation is more practical and more cost-efficient. By investigating various observation sparsities, we show that the classical depth-fusion pipeline becomes powerless for the case with a larger baseline angle that worsens the photo-consistency check. As another line of the solution, we present SurfaceNet+, a volumetric method to handle the 'incompleteness' and the 'inaccuracy' problems induced by a very sparse MVS setup. Specifically, the former problem is handled by a novel volume-wise view selection approach. It owns superiority in selecting valid views while discarding invalid occluded views by considering the geometric prior. Furthermore, the latter problem is handled via a multi-scale strategy that consequently refines the recovered geometry around the region with the repeating pattern. The experiments demonstrate the tremendous performance gap between SurfaceNet+ and state-of-the-art methods in terms of precision and recall. Under the extreme sparse-MVS settings in two datasets, where existing methods can only return very few points, SurfaceNet+ still works as well as in the dense MVS setting. The benchmark and the implementation are publicly available at https://github.com/mjiUST/SurfaceNet-plus.
* Accepted by IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), May 2020
MulayCap: Multi-layer Human Performance Capture Using A Monocular Video Camera
Apr 19, 2020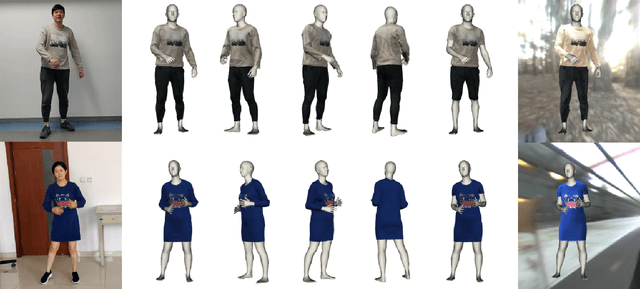
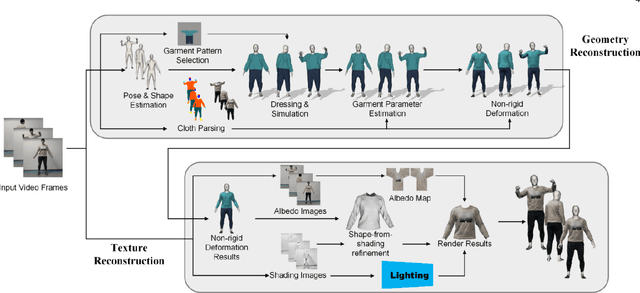
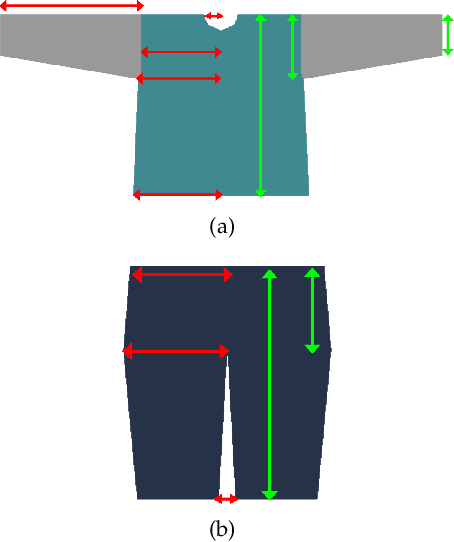
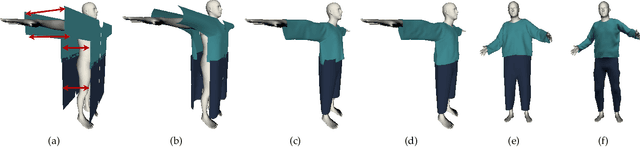
We introduce MulayCap, a novel human performance capture method using a monocular video camera without the need for pre-scanning. The method uses "multi-layer" representations for geometry reconstruction and texture rendering, respectively. For geometry reconstruction, we decompose the clothed human into multiple geometry layers, namely a body mesh layer and a garment piece layer. The key technique behind is a Garment-from-Video (GfV) method for optimizing the garment shape and reconstructing the dynamic cloth to fit the input video sequence, based on a cloth simulation model which is effectively solved with gradient descent. For texture rendering, we decompose each input image frame into a shading layer and an albedo layer, and propose a method for fusing a fixed albedo map and solving for detailed garment geometry using the shading layer. Compared with existing single view human performance capture systems, our "multi-layer" approach bypasses the tedious and time consuming scanning step for obtaining a human specific mesh template. Experimental results demonstrate that MulayCap produces realistic rendering of dynamically changing details that has not been achieved in any previous monocular video camera systems. Benefiting from its fully semantic modeling, MulayCap can be applied to various important editing applications, such as cloth editing, re-targeting, relighting, and AR applications.
OccuSeg: Occupancy-aware 3D Instance Segmentation
Apr 08, 2020
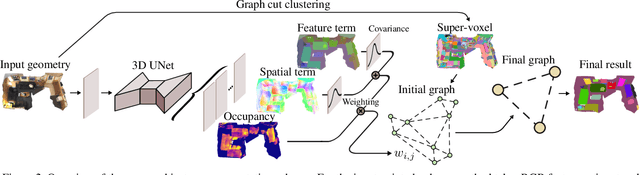
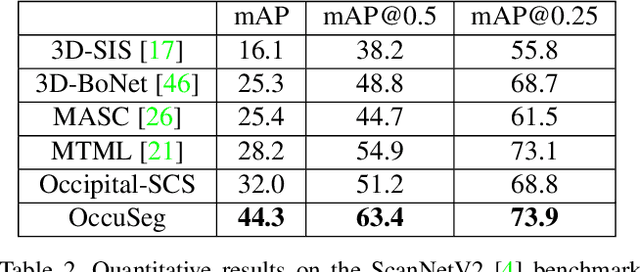

3D instance segmentation, with a variety of applications in robotics and augmented reality, is in large demands these days. Unlike 2D images that are projective observations of the environment, 3D models provide metric reconstruction of the scenes without occlusion or scale ambiguity. In this paper, we define "3D occupancy size", as the number of voxels occupied by each instance. It owns advantages of robustness in prediction, on which basis, OccuSeg, an occupancy-aware 3D instance segmentation scheme is proposed. Our multi-task learning produces both occupancy signal and embedding representations, where the training of spatial and feature embeddings varies with their difference in scale-aware. Our clustering scheme benefits from the reliable comparison between the predicted occupancy size and the clustered occupancy size, which encourages hard samples being correctly clustered and avoids over segmentation. The proposed approach achieves state-of-the-art performance on 3 real-world datasets, i.e. ScanNetV2, S3DIS and SceneNN, while maintaining high efficiency.
PANDA: A Gigapixel-level Human-centric Video Dataset
Mar 10, 2020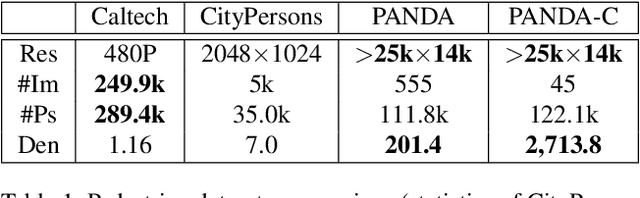

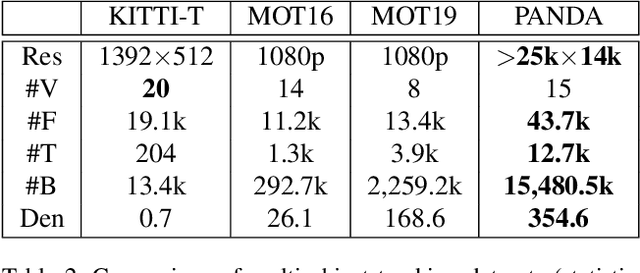
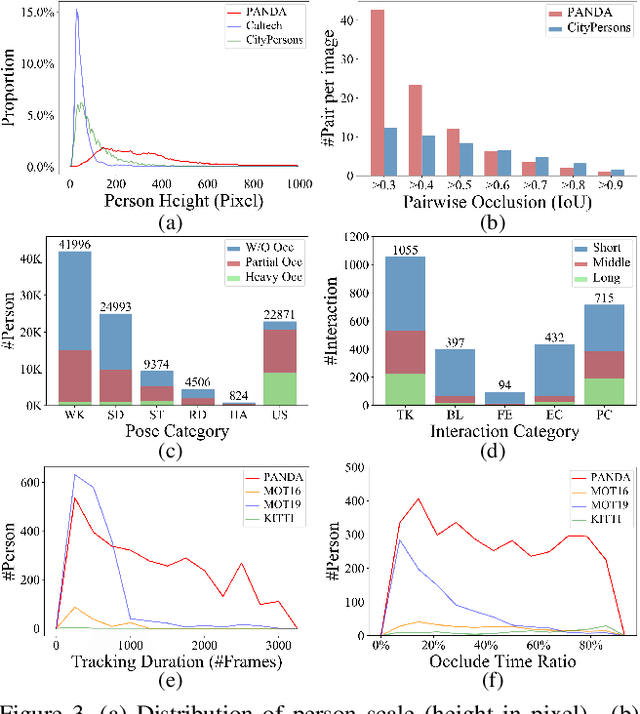
We present PANDA, the first gigaPixel-level humAN-centric viDeo dAtaset, for large-scale, long-term, and multi-object visual analysis. The videos in PANDA were captured by a gigapixel camera and cover real-world scenes with both wide field-of-view (~1 square kilometer area) and high-resolution details (~gigapixel-level/frame). The scenes may contain 4k head counts with over 100x scale variation. PANDA provides enriched and hierarchical ground-truth annotations, including 15,974.6k bounding boxes, 111.8k fine-grained attribute labels, 12.7k trajectories, 2.2k groups and 2.9k interactions. We benchmark the human detection and tracking tasks. Due to the vast variance of pedestrian pose, scale, occlusion and trajectory, existing approaches are challenged by both accuracy and efficiency. Given the uniqueness of PANDA with both wide FoV and high resolution, a new task of interaction-aware group detection is introduced. We design a 'global-to-local zoom-in' framework, where global trajectories and local interactions are simultaneously encoded, yielding promising results. We believe PANDA will contribute to the community of artificial intelligence and praxeology by understanding human behaviors and interactions in large-scale real-world scenes. PANDA Website: http://www.panda-dataset.com.
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Dec 03, 2019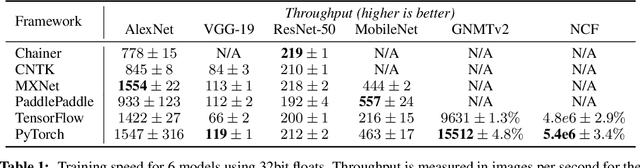

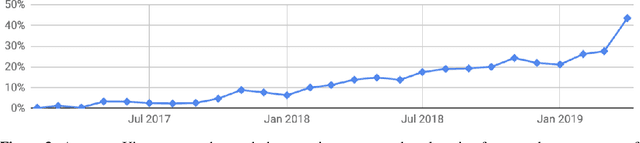
Deep learning frameworks have often focused on either usability or speed, but not both. PyTorch is a machine learning library that shows that these two goals are in fact compatible: it provides an imperative and Pythonic programming style that supports code as a model, makes debugging easy and is consistent with other popular scientific computing libraries, while remaining efficient and supporting hardware accelerators such as GPUs. In this paper, we detail the principles that drove the implementation of PyTorch and how they are reflected in its architecture. We emphasize that every aspect of PyTorch is a regular Python program under the full control of its user. We also explain how the careful and pragmatic implementation of the key components of its runtime enables them to work together to achieve compelling performance. We demonstrate the efficiency of individual subsystems, as well as the overall speed of PyTorch on several common benchmarks.
EventCap: Monocular 3D Capture of High-Speed Human Motions using an Event Camera
Aug 30, 2019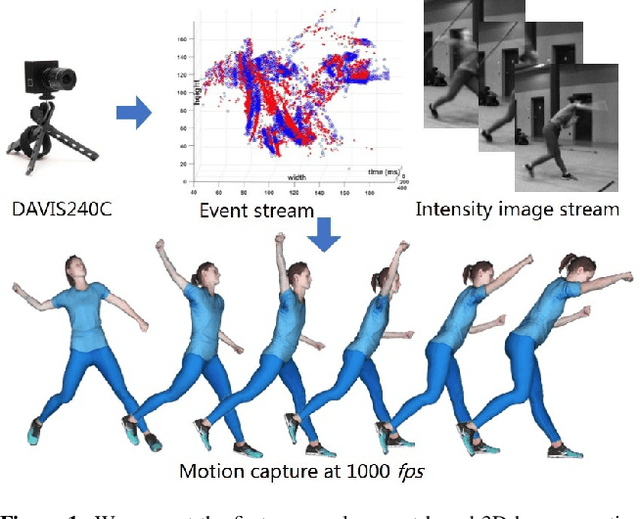
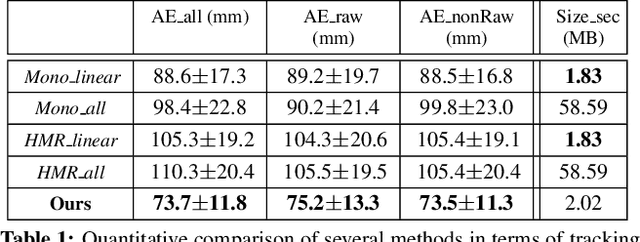
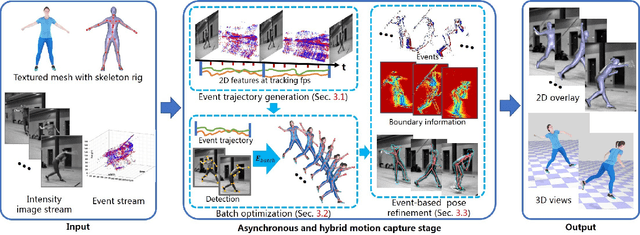
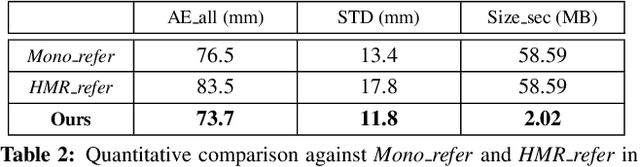
The high frame rate is a critical requirement for capturing fast human motions. In this setting, existing markerless image-based methods are constrained by the lighting requirement, the high data bandwidth and the consequent high computation overhead. In this paper, we propose EventCap --- the first approach for 3D capturing of high-speed human motions using a single event camera. Our method combines model-based optimization and CNN-based human pose detection to capture high-frequency motion details and to reduce the drifting in the tracking. As a result, we can capture fast motions at millisecond resolution with significantly higher data efficiency than using high frame rate videos. Experiments on our new event-based fast human motion dataset demonstrate the effectiveness and accuracy of our method, as well as its robustness to challenging lighting conditions.