 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Linguistic Diversity of Large Language Models with Possibility Exploration Fine-Tuning
Dec 04, 2024



While Large Language Models (LLMs) have made significant strides in replicating human-like abilities, there are concerns about a reduction in the linguistic diversity of their outputs. This results in the homogenization of viewpoints and perspectives, as well as the underrepresentation of specific demographic groups. Although several fine-tuning and prompting techniques have been suggested to tackle the issue, they are often tailored to specific tasks or come with a substantial increase in computational cost and latency. This makes them challenging to apply to applications that demand very low latency, such as chatbots and virtual assistants. We propose Possibility Exploration Fine-Tuning (PEFT), a task-agnostic framework that enhances the text diversity of LLMs without increasing latency or computational cost. Given the same prompt, models fine-tuned with PEFT can simultaneously generate multiple diverse responses, each corresponding with a controllable possibility number. Experiments on dialogue and story generation tasks demonstrate that PEFT significantly enhances the diversity of LLM outputs, as evidenced by lower similarity between candidate responses. Since PEFT emphasizes semantic diversity over lexical diversity, it can also notably reduce demographic bias in dialogue systems. The implementations and datasets are available in our repository: https://github.com/mailong25/peft_diversity
Empowering Visual Creativity: A Vision-Language Assistant to Image Editing Recommendations
May 31, 2024



Advances in text-based image generation and editing have revolutionized content creation, enabling users to create impressive content from imaginative text prompts. However, existing methods are not designed to work well with the oversimplified prompts that are often encountered in typical scenarios when users start their editing with only vague or abstract purposes in mind. Those scenarios demand elaborate ideation efforts from the users to bridge the gap between such vague starting points and the detailed creative ideas needed to depict the desired results. In this paper, we introduce the task of Image Editing Recommendation (IER). This task aims to automatically generate diverse creative editing instructions from an input image and a simple prompt representing the users' under-specified editing purpose. To this end, we introduce Creativity-Vision Language Assistant~(Creativity-VLA), a multimodal framework designed specifically for edit-instruction generation. We train Creativity-VLA on our edit-instruction dataset specifically curated for IER. We further enhance our model with a novel 'token-for-localization' mechanism, enabling it to support both global and local editing operations. Our experimental results demonstrate the effectiveness of \ours{} in suggesting instructions that not only contain engaging creative elements but also maintain high relevance to both the input image and the user's initial hint.
SPICED: News Similarity Detection Dataset with Multiple Topics and Complexity Levels
Sep 21, 2023



Nowadays, the use of intelligent systems to detect redundant information in news articles has become especially prevalent with the proliferation of news media outlets in order to enhance user experience. However, the heterogeneous nature of news can lead to spurious findings in these systems: Simple heuristics such as whether a pair of news are both about politics can provide strong but deceptive downstream performance. Segmenting news similarity datasets into topics improves the training of these models by forcing them to learn how to distinguish salient characteristics under more narrow domains. However, this requires the existence of topic-specific datasets, which are currently lacking. In this article, we propose a new dataset of similar news, SPICED, which includes seven topics: Crime & Law, Culture & Entertainment, Disasters & Accidents, Economy & Business, Politics & Conflicts, Science & Technology, and Sports. Futhermore, we present four distinct approaches for generating news pairs, which are used in the creation of datasets specifically designed for news similarity detection task. We benchmarked the created datasets using MinHash, BERT, SBERT, and SimCSE models.
MagicProp: Diffusion-based Video Editing via Motion-aware Appearance Propagation
Sep 02, 2023This paper addresses the issue of modifying the visual appearance of videos while preserving their motion. A novel framework, named MagicProp, is proposed, which disentangles the video editing process into two stages: appearance editing and motion-aware appearance propagation. In the first stage, MagicProp selects a single frame from the input video and applies image-editing techniques to modify the content and/or style of the frame. The flexibility of these techniques enables the editing of arbitrary regions within the frame. In the second stage, MagicProp employs the edited frame as an appearance reference and generates the remaining frames using an autoregressive rendering approach. To achieve this, a diffusion-based conditional generation model, called PropDPM, is developed, which synthesizes the target frame by conditioning on the reference appearance, the target motion, and its previous appearance. The autoregressive editing approach ensures temporal consistency in the resulting videos. Overall, MagicProp combines the flexibility of image-editing techniques with the superior temporal consistency of autoregressive modeling, enabling flexible editing of object types and aesthetic styles in arbitrary regions of input videos while maintaining good temporal consistency across frames. Extensive experiments in various video editing scenarios demonstrate the effectiveness of MagicProp.
Enhancing conversational quality in language learning chatbots: An evaluation of GPT4 for ASR error correction
Jul 19, 2023The integration of natural language processing (NLP) technologies into educational applications has shown promising results, particularly in the language learning domain. Recently, many spoken open-domain chatbots have been used as speaking partners, helping language learners improve their language skills. However, one of the significant challenges is the high word-error-rate (WER) when recognizing non-native/non-fluent speech, which interrupts conversation flow and leads to disappointment for learners. This paper explores the use of GPT4 for ASR error correction in conversational settings. In addition to WER, we propose to use semantic textual similarity (STS) and next response sensibility (NRS) metrics to evaluate the impact of error correction models on the quality of the conversation. We find that transcriptions corrected by GPT4 lead to higher conversation quality, despite an increase in WER. GPT4 also outperforms standard error correction methods without the need for in-domain training data.
Unsupervised domain adaptation for speech recognition with unsupervised error correction
Sep 24, 2022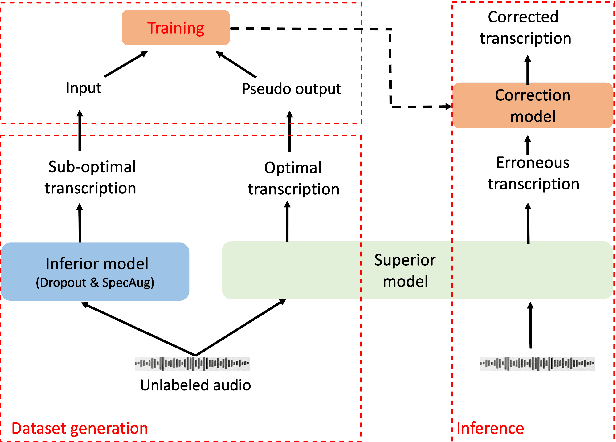
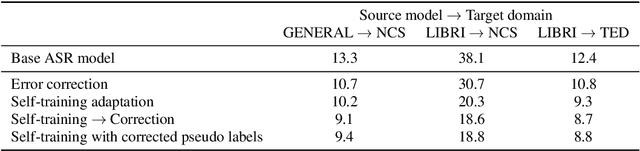
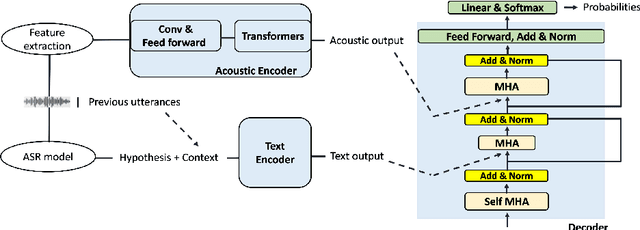

The transcription quality of automatic speech recognition (ASR) systems degrades significantly when transcribing audios coming from unseen domains. We propose an unsupervised error correction method for unsupervised ASR domain adaption, aiming to recover transcription errors caused by domain mismatch. Unlike existing correction methods that rely on transcribed audios for training, our approach requires only unlabeled data of the target domains in which a pseudo-labeling technique is applied to generate correction training samples. To reduce over-fitting to the pseudo data, we also propose an encoder-decoder correction model that can take into account additional information such as dialogue context and acoustic features. Experiment results show that our method obtains a significant word error rate (WER) reduction over non-adapted ASR systems. The correction model can also be applied on top of other adaptation approaches to bring an additional improvement of 10% relatively.
Double Trouble: How to not explain a text classifier's decisions using counterfactuals synthesized by masked language models?
Oct 22, 2021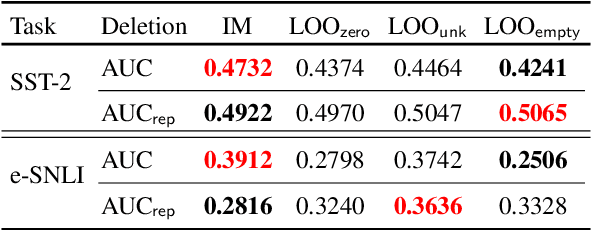
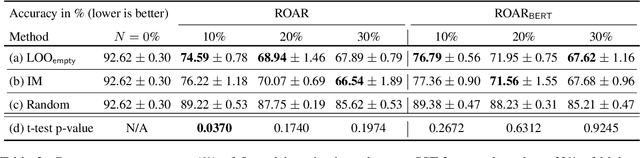

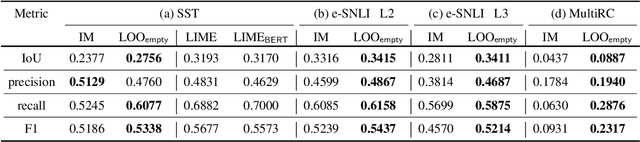
Explaining how important each input feature is to a classifier's decision is critical in high-stake applications. An underlying principle behind dozens of explanation methods is to take the prediction difference between before-and-after an input feature (here, a token) is removed as its attribution - the individual treatment effect in causal inference. A recent method called Input Marginalization (IM) (Kim et al., 2020) uses BERT to replace a token - i.e. simulating the do(.) operator - yielding more plausible counterfactuals. However, our rigorous evaluation using five metrics and on three datasets found IM explanations to be consistently more biased, less accurate, and less plausible than those derived from simply deleting a word.
Compositional Sketch Search
Jun 15, 2021
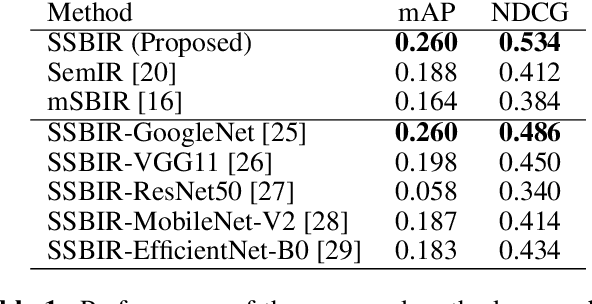
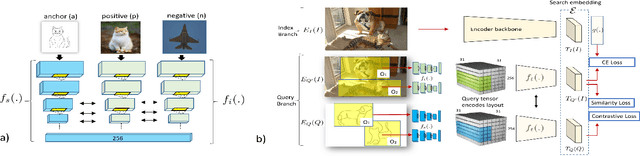
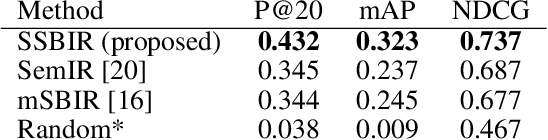
We present an algorithm for searching image collections using free-hand sketches that describe the appearance and relative positions of multiple objects. Sketch based image retrieval (SBIR) methods predominantly match queries containing a single, dominant object invariant to its position within an image. Our work exploits drawings as a concise and intuitive representation for specifying entire scene compositions. We train a convolutional neural network (CNN) to encode masked visual features from sketched objects, pooling these into a spatial descriptor encoding the spatial relationships and appearances of objects in the composition. Training the CNN backbone as a Siamese network under triplet loss yields a metric search embedding for measuring compositional similarity which may be efficiently leveraged for visual search by applying product quantization.
APES: Audiovisual Person Search in Untrimmed Video
Jun 03, 2021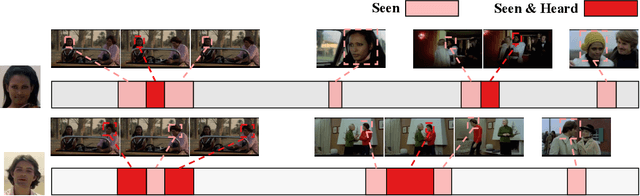
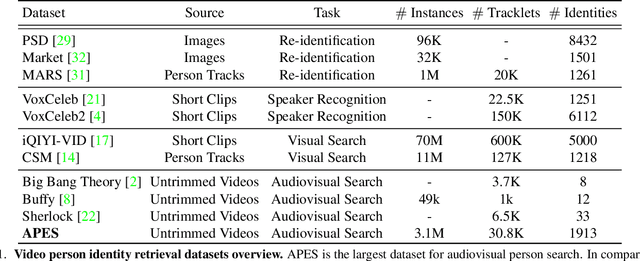


Humans are arguably one of the most important subjects in video streams, many real-world applications such as video summarization or video editing workflows often require the automatic search and retrieval of a person of interest. Despite tremendous efforts in the person reidentification and retrieval domains, few works have developed audiovisual search strategies. In this paper, we present the Audiovisual Person Search dataset (APES), a new dataset composed of untrimmed videos whose audio (voices) and visual (faces) streams are densely annotated. APES contains over 1.9K identities labeled along 36 hours of video, making it the largest dataset available for untrimmed audiovisual person search. A key property of APES is that it includes dense temporal annotations that link faces to speech segments of the same identity. To showcase the potential of our new dataset, we propose an audiovisual baseline and benchmark for person retrieval. Our study shows that modeling audiovisual cues benefits the recognition of people's identities. To enable reproducibility and promote future research, the dataset annotations and baseline code are available at: https://github.com/fuankarion/audiovisual-person-search
Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution Merging
May 28, 2021
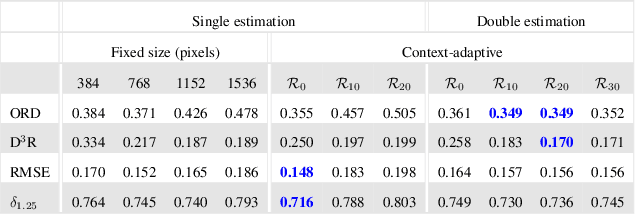


Neural networks have shown great abilities in estimating depth from a single image. However, the inferred depth maps are well below one-megapixel resolution and often lack fine-grained details, which limits their practicality. Our method builds on our analysis on how the input resolution and the scene structure affects depth estimation performance. We demonstrate that there is a trade-off between a consistent scene structure and the high-frequency details, and merge low- and high-resolution estimations to take advantage of this duality using a simple depth merging network. We present a double estimation method that improves the whole-image depth estimation and a patch selection method that adds local details to the final result. We demonstrate that by merging estimations at different resolutions with changing context, we can generate multi-megapixel depth maps with a high level of detail using a pre-trained model.
* For more details visit http://yaksoy.github.io/highresdepth/