 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWMNav: Integrating Vision-Language Models into World Models for Object Goal Navigation
Mar 04, 2025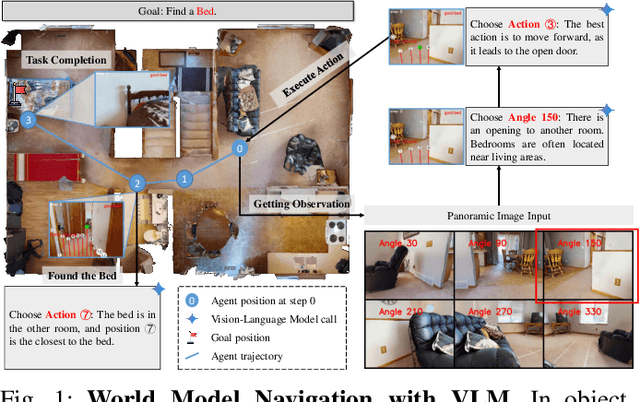
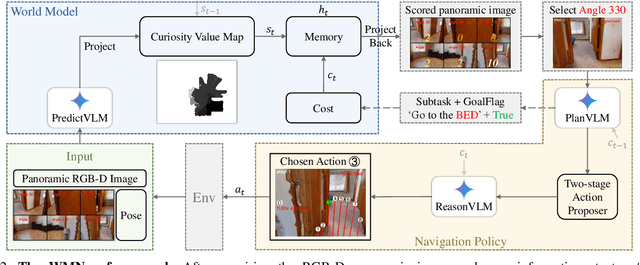
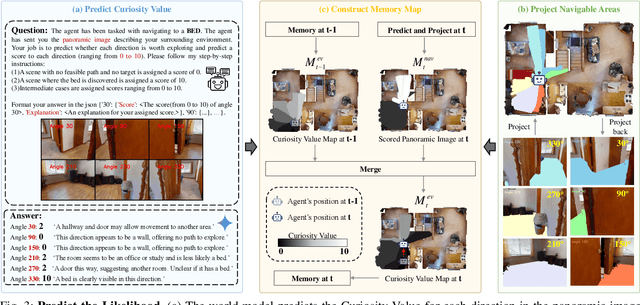

Object Goal Navigation-requiring an agent to locate a specific object in an unseen environment-remains a core challenge in embodied AI. Although recent progress in Vision-Language Model (VLM)-based agents has demonstrated promising perception and decision-making abilities through prompting, none has yet established a fully modular world model design that reduces risky and costly interactions with the environment by predicting the future state of the world. We introduce WMNav, a novel World Model-based Navigation framework powered by Vision-Language Models (VLMs). It predicts possible outcomes of decisions and builds memories to provide feedback to the policy module. To retain the predicted state of the environment, WMNav proposes the online maintained Curiosity Value Map as part of the world model memory to provide dynamic configuration for navigation policy. By decomposing according to a human-like thinking process, WMNav effectively alleviates the impact of model hallucination by making decisions based on the feedback difference between the world model plan and observation. To further boost efficiency, we implement a two-stage action proposer strategy: broad exploration followed by precise localization. Extensive evaluation on HM3D and MP3D validates WMNav surpasses existing zero-shot benchmarks in both success rate and exploration efficiency (absolute improvement: +3.2% SR and +3.2% SPL on HM3D, +13.5% SR and +1.1% SPL on MP3D). Project page: https://b0b8k1ng.github.io/WMNav/.
Tuning-Free Structured Sparse PCA via Deep Unfolding Networks
Feb 28, 2025Sparse principal component analysis (PCA) is a well-established dimensionality reduction technique that is often used for unsupervised feature selection (UFS). However, determining the regularization parameters is rather challenging, and conventional approaches, including grid search and Bayesian optimization, not only bring great computational costs but also exhibit high sensitivity. To address these limitations, we first establish a structured sparse PCA formulation by integrating $\ell_1$-norm and $\ell_{2,1}$-norm to capture the local and global structures, respectively. Building upon the off-the-shelf alternating direction method of multipliers (ADMM) optimization framework, we then design an interpretable deep unfolding network that translates iterative optimization steps into trainable neural architectures. This innovation enables automatic learning of the regularization parameters, effectively bypassing the empirical tuning requirements of conventional methods. Numerical experiments on benchmark datasets validate the advantages of our proposed method over the existing state-of-the-art methods. Our code will be accessible at https://github.com/xianchaoxiu/SPCA-Net.
Learning Humanoid Locomotion with World Model Reconstruction
Feb 22, 2025Humanoid robots are designed to navigate environments accessible to humans using their legs. However, classical research has primarily focused on controlled laboratory settings, resulting in a gap in developing controllers for navigating complex real-world terrains. This challenge mainly arises from the limitations and noise in sensor data, which hinder the robot's understanding of itself and the environment. In this study, we introduce World Model Reconstruction (WMR), an end-to-end learning-based approach for blind humanoid locomotion across challenging terrains. We propose training an estimator to explicitly reconstruct the world state and utilize it to enhance the locomotion policy. The locomotion policy takes inputs entirely from the reconstructed information. The policy and the estimator are trained jointly; however, the gradient between them is intentionally cut off. This ensures that the estimator focuses solely on world reconstruction, independent of the locomotion policy's updates. We evaluated our model on rough, deformable, and slippery surfaces in real-world scenarios, demonstrating robust adaptability and resistance to interference. The robot successfully completed a 3.2 km hike without any human assistance, mastering terrains covered with ice and snow.
SleepGMUformer: A gated multimodal temporal neural network for sleep staging
Feb 20, 2025



Sleep staging is a key method for assessing sleep quality and diagnosing sleep disorders. However, current deep learning methods face challenges: 1) postfusion techniques ignore the varying contributions of different modalities; 2) unprocessed sleep data can interfere with frequency-domain information. To tackle these issues, this paper proposes a gated multimodal temporal neural network for multidomain sleep data, including heart rate, motion, steps, EEG (Fpz-Cz, Pz-Oz), and EOG from WristHR-Motion-Sleep and SleepEDF-78. The model integrates: 1) a pre-processing module for feature alignment, missing value handling, and EEG de-trending; 2) a feature extraction module for complex sleep features in the time dimension; and 3) a dynamic fusion module for real-time modality weighting.Experiments show classification accuracies of 85.03% on SleepEDF-78 and 94.54% on WristHR-Motion-Sleep datasets. The model handles heterogeneous datasets and outperforms state-of-the-art models by 1.00%-4.00%.
Neuromorphic Readout for Hadron Calorimeters
Feb 18, 2025We simulate hadrons impinging on a homogeneous lead-tungstate (PbWO4) calorimeter to investigate how the resulting light yield and its temporal structure, as detected by an array of light-sensitive sensors, can be processed by a neuromorphic computing system. Our model encodes temporal photon distributions as spike trains and employs a fully connected spiking neural network to estimate the total deposited energy, as well as the position and spatial distribution of the light emissions within the sensitive material. The extracted primitives offer valuable topological information about the shower development in the material, achieved without requiring a segmentation of the active medium. A potential nanophotonic implementation using III-V semiconductor nanowires is discussed. It can be both fast and energy efficient.
KARST: Multi-Kernel Kronecker Adaptation with Re-Scaling Transmission for Visual Classification
Feb 10, 2025



Fine-tuning pre-trained vision models for specific tasks is a common practice in computer vision. However, this process becomes more expensive as models grow larger. Recently, parameter-efficient fine-tuning (PEFT) methods have emerged as a popular solution to improve training efficiency and reduce storage needs by tuning additional low-rank modules within pre-trained backbones. Despite their advantages, they struggle with limited representation capabilities and misalignment with pre-trained intermediate features. To address these issues, we introduce an innovative Multi-Kernel Kronecker Adaptation with Re-Scaling Transmission (KARST) for various recognition tasks. Specifically, its multi-kernel design extends Kronecker projections horizontally and separates adaptation matrices into multiple complementary spaces, reducing parameter dependency and creating more compact subspaces. Besides, it incorporates extra learnable re-scaling factors to better align with pre-trained feature distributions, allowing for more flexible and balanced feature aggregation. Extensive experiments validate that our KARST outperforms other PEFT counterparts with a negligible inference cost due to its re-parameterization characteristics. Code is publicly available at: https://github.com/Lucenova/KARST.
Taking A Closer Look at Interacting Objects: Interaction-Aware Open Vocabulary Scene Graph Generation
Feb 06, 2025Today's open vocabulary scene graph generation (OVSGG) extends traditional SGG by recognizing novel objects and relationships beyond predefined categories, leveraging the knowledge from pre-trained large-scale models. Most existing methods adopt a two-stage pipeline: weakly supervised pre-training with image captions and supervised fine-tuning (SFT) on fully annotated scene graphs. Nonetheless, they omit explicit modeling of interacting objects and treat all objects equally, resulting in mismatched relation pairs. To this end, we propose an interaction-aware OVSGG framework INOVA. During pre-training, INOVA employs an interaction-aware target generation strategy to distinguish interacting objects from non-interacting ones. In SFT, INOVA devises an interaction-guided query selection tactic to prioritize interacting objects during bipartite graph matching. Besides, INOVA is equipped with an interaction-consistent knowledge distillation to enhance the robustness by pushing interacting object pairs away from the background. Extensive experiments on two benchmarks (VG and GQA) show that INOVA achieves state-of-the-art performance, demonstrating the potential of interaction-aware mechanisms for real-world applications.
FAS: Fast ANN-SNN Conversion for Spiking Large Language Models
Feb 06, 2025



Spiking Large Language Models have been shown as a good alternative to LLMs in various scenarios. Existing methods for creating Spiking LLMs, i.e., direct training and ANN-SNN conversion, often suffer from performance degradation and relatively high computational costs. To address these issues, we propose a novel Fast ANN-SNN conversion strategy (FAS) that transforms LLMs into spiking LLMs in two stages. The first stage employs a full-parameter fine-tuning of pre-trained models, so it does not need any direct training from scratch. The second stage introduces a coarse-to-fine calibration method to reduce conversion errors and improve accuracy. Our experiments on both language and vision-language tasks across four different scales of LLMs demonstrate that FAS can achieve state-of-the-art performance yet with significantly reduced inference latency and computational costs. For example, FAS only takes 8 timesteps to achieve an accuracy of 3% higher than that of the OPT-7B model, while reducing energy consumption by 96.63%.
3D Foundation AI Model for Generalizable Disease Detection in Head Computed Tomography
Feb 04, 2025



Head computed tomography (CT) imaging is a widely-used imaging modality with multitudes of medical indications, particularly in assessing pathology of the brain, skull, and cerebrovascular system. It is commonly the first-line imaging in neurologic emergencies given its rapidity of image acquisition, safety, cost, and ubiquity. Deep learning models may facilitate detection of a wide range of diseases. However, the scarcity of high-quality labels and annotations, particularly among less common conditions, significantly hinders the development of powerful models. To address this challenge, we introduce FM-CT: a Foundation Model for Head CT for generalizable disease detection, trained using self-supervised learning. Our approach pre-trains a deep learning model on a large, diverse dataset of 361,663 non-contrast 3D head CT scans without the need for manual annotations, enabling the model to learn robust, generalizable features. To investigate the potential of self-supervised learning in head CT, we employed both discrimination with self-distillation and masked image modeling, and we construct our model in 3D rather than at the slice level (2D) to exploit the structure of head CT scans more comprehensively and efficiently. The model's downstream classification performance is evaluated using internal and three external datasets, encompassing both in-distribution (ID) and out-of-distribution (OOD) data. Our results demonstrate that the self-supervised foundation model significantly improves performance on downstream diagnostic tasks compared to models trained from scratch and previous 3D CT foundation models on scarce annotated datasets. This work highlights the effectiveness of self-supervised learning in medical imaging and sets a new benchmark for head CT image analysis in 3D, enabling broader use of artificial intelligence for head CT-based diagnosis.
Nautilus: Locality-aware Autoencoder for Scalable Mesh Generation
Jan 27, 2025



Triangle meshes are fundamental to 3D applications, enabling efficient modification and rasterization while maintaining compatibility with standard rendering pipelines. However, current automatic mesh generation methods typically rely on intermediate representations that lack the continuous surface quality inherent to meshes. Converting these representations into meshes produces dense, suboptimal outputs. Although recent autoregressive approaches demonstrate promise in directly modeling mesh vertices and faces, they are constrained by the limitation in face count, scalability, and structural fidelity. To address these challenges, we propose Nautilus, a locality-aware autoencoder for artist-like mesh generation that leverages the local properties of manifold meshes to achieve structural fidelity and efficient representation. Our approach introduces a novel tokenization algorithm that preserves face proximity relationships and compresses sequence length through locally shared vertices and edges, enabling the generation of meshes with an unprecedented scale of up to 5,000 faces. Furthermore, we develop a Dual-stream Point Conditioner that provides multi-scale geometric guidance, ensuring global consistency and local structural fidelity by capturing fine-grained geometric features. Extensive experiments demonstrate that Nautilus significantly outperforms state-of-the-art methods in both fidelity and scalability. The project page will be released to https://nautilusmeshgen.github.io.