 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObj2Seq: Formatting Objects as Sequences with Class Prompt for Visual Tasks
Sep 28, 2022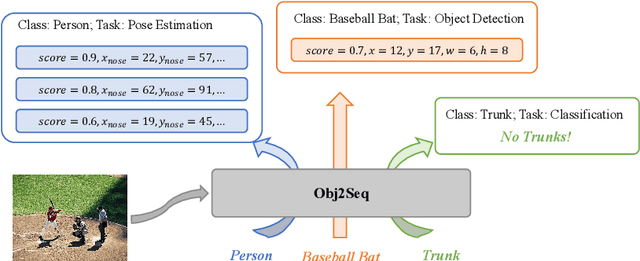
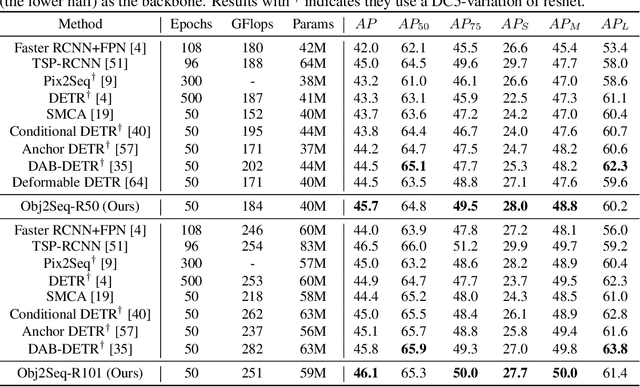
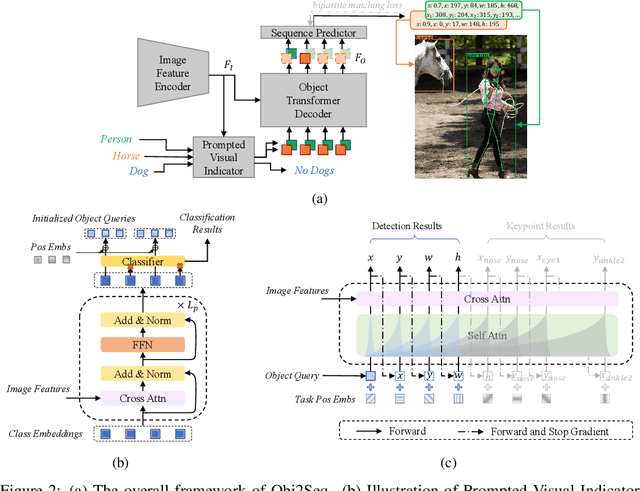
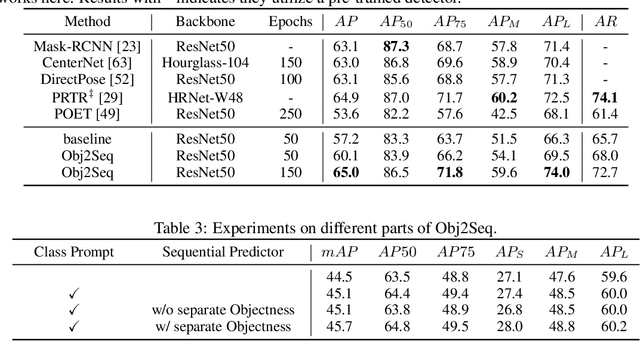
Visual tasks vary a lot in their output formats and concerned contents, therefore it is hard to process them with an identical structure. One main obstacle lies in the high-dimensional outputs in object-level visual tasks. In this paper, we propose an object-centric vision framework, Obj2Seq. Obj2Seq takes objects as basic units, and regards most object-level visual tasks as sequence generation problems of objects. Therefore, these visual tasks can be decoupled into two steps. First recognize objects of given categories, and then generate a sequence for each of these objects. The definition of the output sequences varies for different tasks, and the model is supervised by matching these sequences with ground-truth targets. Obj2Seq is able to flexibly determine input categories to satisfy customized requirements, and be easily extended to different visual tasks. When experimenting on MS COCO, Obj2Seq achieves 45.7% AP on object detection, 89.0% AP on multi-label classification and 65.0% AP on human pose estimation. These results demonstrate its potential to be generally applied to different visual tasks. Code has been made available at: https://github.com/CASIA-IVA-Lab/Obj2Seq.
Learning from Future: A Novel Self-Training Framework for Semantic Segmentation
Sep 18, 2022



Self-training has shown great potential in semi-supervised learning. Its core idea is to use the model learned on labeled data to generate pseudo-labels for unlabeled samples, and in turn teach itself. To obtain valid supervision, active attempts typically employ a momentum teacher for pseudo-label prediction yet observe the confirmation bias issue, where the incorrect predictions may provide wrong supervision signals and get accumulated in the training process. The primary cause of such a drawback is that the prevailing self-training framework acts as guiding the current state with previous knowledge, because the teacher is updated with the past student only. To alleviate this problem, we propose a novel self-training strategy, which allows the model to learn from the future. Concretely, at each training step, we first virtually optimize the student (i.e., caching the gradients without applying them to the model weights), then update the teacher with the virtual future student, and finally ask the teacher to produce pseudo-labels for the current student as the guidance. In this way, we manage to improve the quality of pseudo-labels and thus boost the performance. We also develop two variants of our future-self-training (FST) framework through peeping at the future both deeply (FST-D) and widely (FST-W). Taking the tasks of unsupervised domain adaptive semantic segmentation and semi-supervised semantic segmentation as the instances, we experimentally demonstrate the effectiveness and superiority of our approach under a wide range of settings. Code will be made publicly available.
Uni6Dv2: Noise Elimination for 6D Pose Estimation
Aug 15, 2022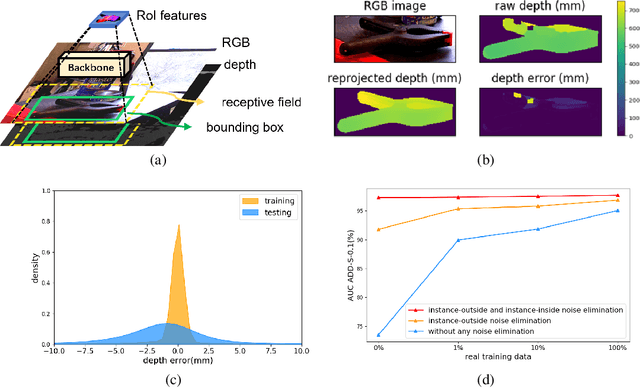
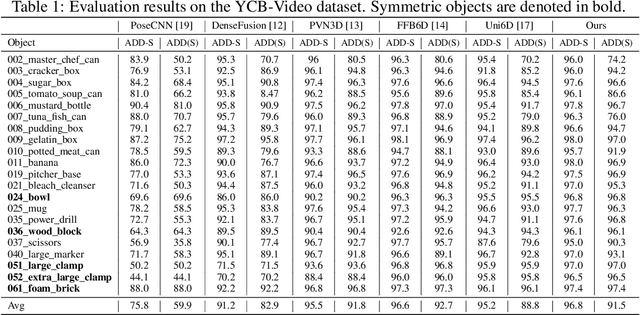
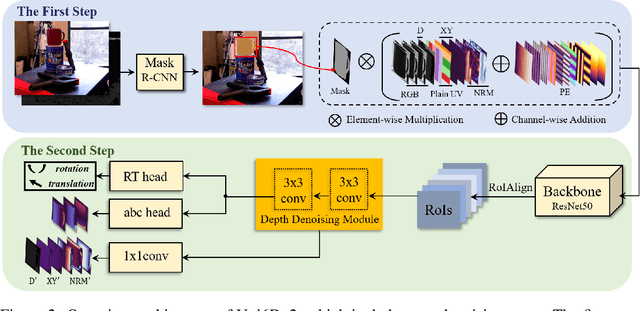
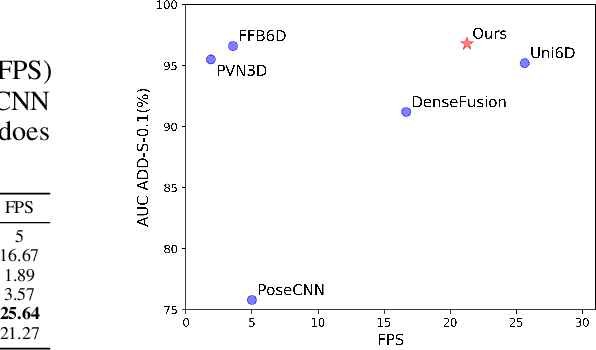
Few prior 6D pose estimation methods use a backbone network to extract features from RGB and depth images, and Uni6D is the pioneer to do so. We find that primary causes of the performance limitation in Uni6D are Instance-Outside and Instance-Inside noise. Uni6D inevitably introduces Instance-Outside noise from background pixels in the receptive field due to its inherently straightforward pipeline design and ignores the Instance-Inside noise in the input depth data. In this work, we propose a two-step denoising method to handle aforementioned noise in Uni6D. In the first step, an instance segmentation network is used to crop and mask the instance to remove noise from non-instance regions. In the second step, a lightweight depth denoising module is proposed to calibrate the depth feature before feeding it into the pose regression network. Extensive experiments show that our method called Uni6Dv2 is able to eliminate the noise effectively and robustly, outperforming Uni6D without sacrificing too much inference efficiency. It also reduces the need for annotated real data that requires costly labeling.
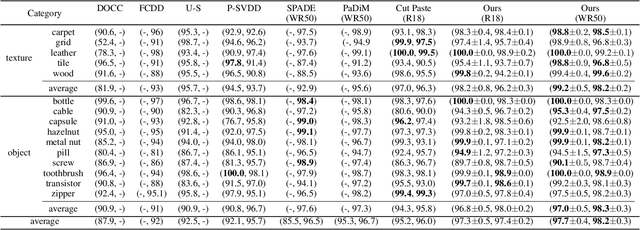
Benchmarking Unsupervised Anomaly Detection and Localization
May 30, 2022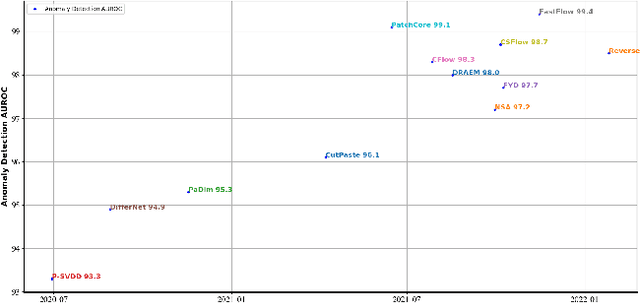
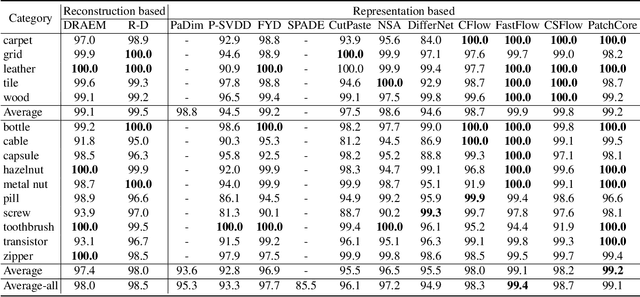
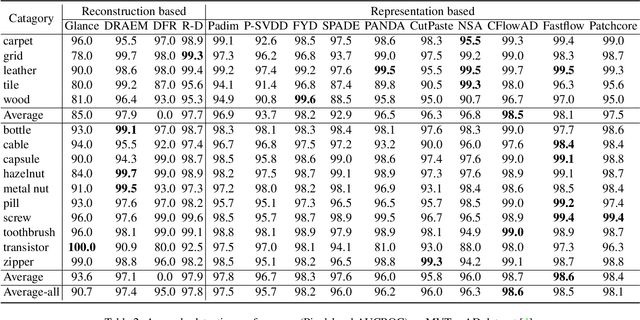
Unsupervised anomaly detection and localization, as of one the most practical and challenging problems in computer vision, has received great attention in recent years. From the time the MVTec AD dataset was proposed to the present, new research methods that are constantly being proposed push its precision to saturation. It is the time to conduct a comprehensive comparison of existing methods to inspire further research. This paper extensively compares 13 papers in terms of the performance in unsupervised anomaly detection and localization tasks, and adds a comparison of inference efficiency previously ignored by the community. Meanwhile, analysis of the MVTec AD dataset are also given, especially the label ambiguity that affects the model fails to achieve full marks. Moreover, considering the proposal of the new MVTec 3D-AD dataset, this paper also conducts experiments using the existing state-of-the-art 2D methods on this new dataset, and reports the corresponding results with analysis.
Uni6D: A Unified CNN Framework without Projection Breakdown for 6D Pose Estimation
Apr 05, 2022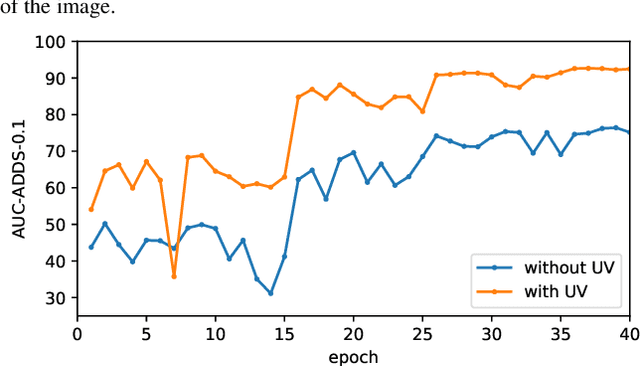
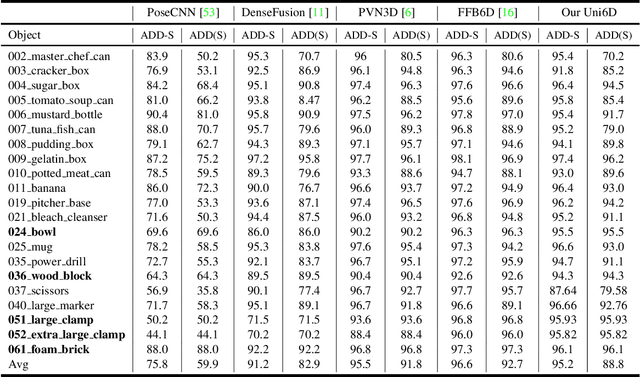
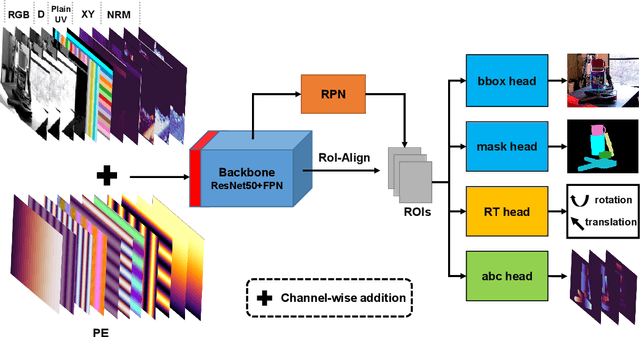
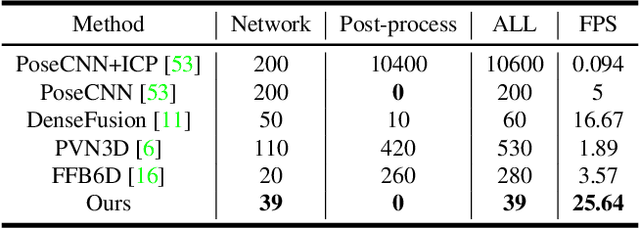
As RGB-D sensors become more affordable, using RGB-D images to obtain high-accuracy 6D pose estimation results becomes a better option. State-of-the-art approaches typically use different backbones to extract features for RGB and depth images. They use a 2D CNN for RGB images and a per-pixel point cloud network for depth data, as well as a fusion network for feature fusion. We find that the essential reason for using two independent backbones is the "projection breakdown" problem. In the depth image plane, the projected 3D structure of the physical world is preserved by the 1D depth value and its built-in 2D pixel coordinate (UV). Any spatial transformation that modifies UV, such as resize, flip, crop, or pooling operations in the CNN pipeline, breaks the binding between the pixel value and UV coordinate. As a consequence, the 3D structure is no longer preserved by a modified depth image or feature. To address this issue, we propose a simple yet effective method denoted as Uni6D that explicitly takes the extra UV data along with RGB-D images as input. Our method has a Unified CNN framework for 6D pose estimation with a single CNN backbone. In particular, the architecture of our method is based on Mask R-CNN with two extra heads, one named RT head for directly predicting 6D pose and the other named abc head for guiding the network to map the visible points to their coordinates in the 3D model as an auxiliary module. This end-to-end approach balances simplicity and accuracy, achieving comparable accuracy with state of the arts and 7.2x faster inference speed on the YCB-Video dataset.
Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
Mar 14, 2022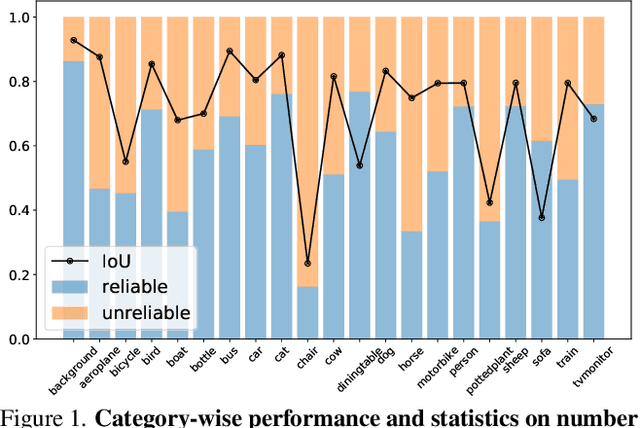
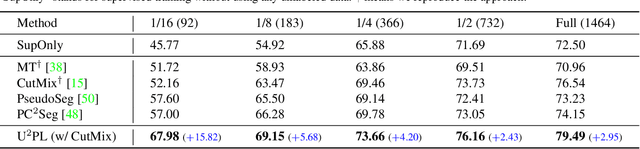
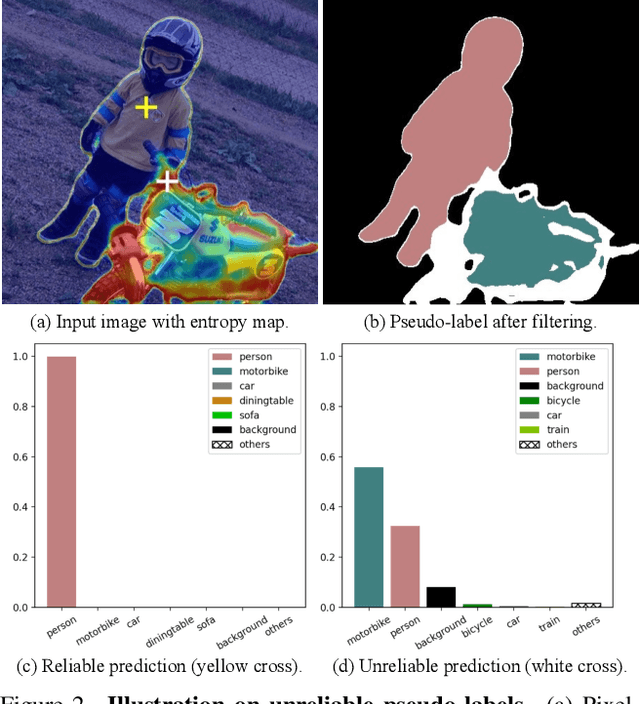
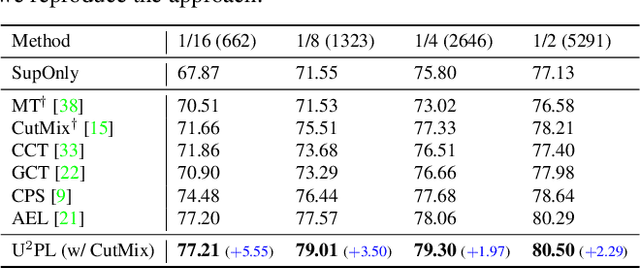
The crux of semi-supervised semantic segmentation is to assign adequate pseudo-labels to the pixels of unlabeled images. A common practice is to select the highly confident predictions as the pseudo ground-truth, but it leads to a problem that most pixels may be left unused due to their unreliability. We argue that every pixel matters to the model training, even its prediction is ambiguous. Intuitively, an unreliable prediction may get confused among the top classes (i.e., those with the highest probabilities), however, it should be confident about the pixel not belonging to the remaining classes. Hence, such a pixel can be convincingly treated as a negative sample to those most unlikely categories. Based on this insight, we develop an effective pipeline to make sufficient use of unlabeled data. Concretely, we separate reliable and unreliable pixels via the entropy of predictions, push each unreliable pixel to a category-wise queue that consists of negative samples, and manage to train the model with all candidate pixels. Considering the training evolution, where the prediction becomes more and more accurate, we adaptively adjust the threshold for the reliable-unreliable partition. Experimental results on various benchmarks and training settings demonstrate the superiority of our approach over the state-of-the-art alternatives.
UniVIP: A Unified Framework for Self-Supervised Visual Pre-training
Mar 14, 2022Self-supervised learning (SSL) holds promise in leveraging large amounts of unlabeled data. However, the success of popular SSL methods has limited on single-centric-object images like those in ImageNet and ignores the correlation among the scene and instances, as well as the semantic difference of instances in the scene. To address the above problems, we propose a Unified Self-supervised Visual Pre-training (UniVIP), a novel self-supervised framework to learn versatile visual representations on either single-centric-object or non-iconic dataset. The framework takes into account the representation learning at three levels: 1) the similarity of scene-scene, 2) the correlation of scene-instance, 3) the discrimination of instance-instance. During the learning, we adopt the optimal transport algorithm to automatically measure the discrimination of instances. Massive experiments show that UniVIP pre-trained on non-iconic COCO achieves state-of-the-art transfer performance on a variety of downstream tasks, such as image classification, semi-supervised learning, object detection and segmentation. Furthermore, our method can also exploit single-centric-object dataset such as ImageNet and outperforms BYOL by 2.5% with the same pre-training epochs in linear probing, and surpass current self-supervised object detection methods on COCO dataset, demonstrating its universality and potential.
Unified Multimodal Punctuation Restoration Framework for Mixed-Modality Corpus
Jan 24, 2022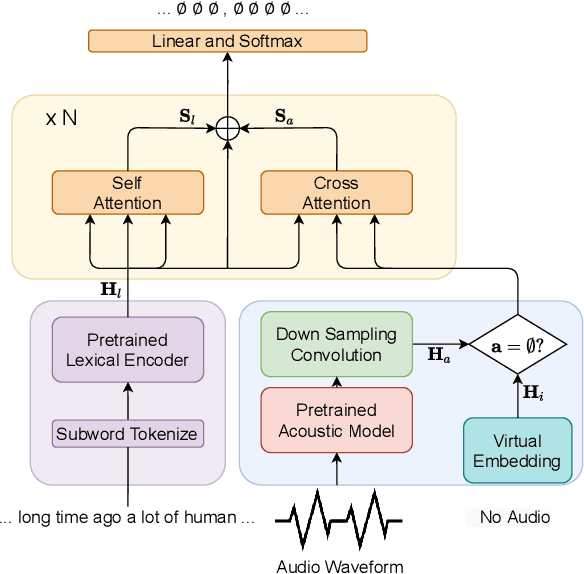
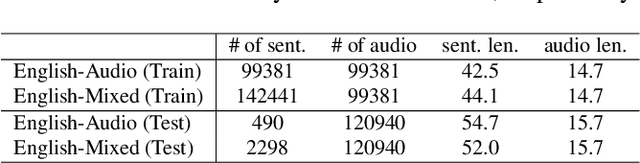
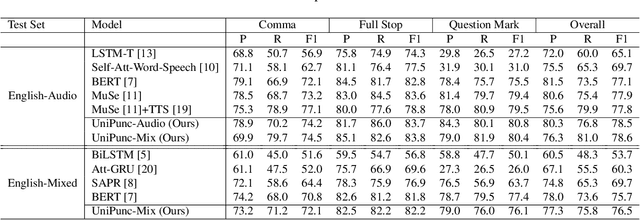
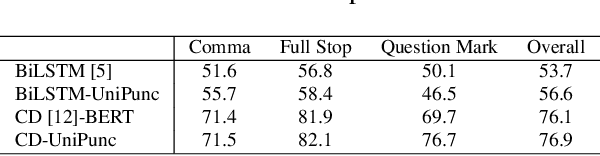
The punctuation restoration task aims to correctly punctuate the output transcriptions of automatic speech recognition systems. Previous punctuation models, either using text only or demanding the corresponding audio, tend to be constrained by real scenes, where unpunctuated sentences are a mixture of those with and without audio. This paper proposes a unified multimodal punctuation restoration framework, named UniPunc, to punctuate the mixed sentences with a single model. UniPunc jointly represents audio and non-audio samples in a shared latent space, based on which the model learns a hybrid representation and punctuates both kinds of samples. We validate the effectiveness of the UniPunc on real-world datasets, which outperforms various strong baselines (e.g. BERT, MuSe) by at least 0.8 overall F1 scores, making a new state-of-the-art. Extensive experiments show that UniPunc's design is a pervasive solution: by grafting onto previous models, UniPunc enables them to punctuate on the mixed corpus. Our code is available at github.com/Yaoming95/UniPunc
FastFlow: Unsupervised Anomaly Detection and Localization via 2D Normalizing Flows
Nov 16, 2021
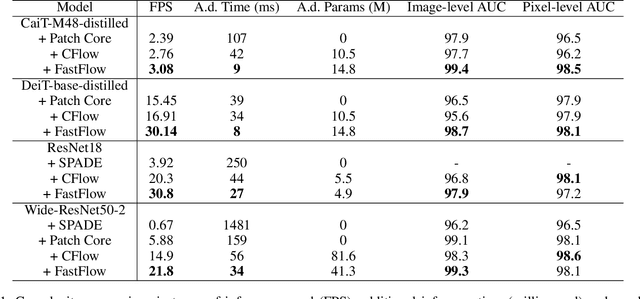
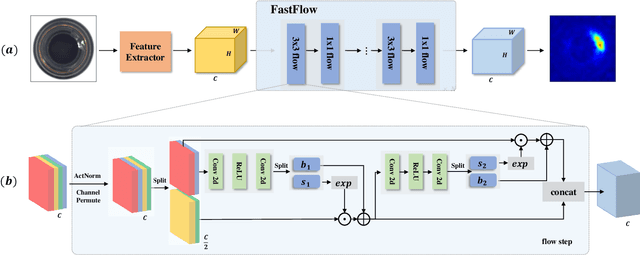

Unsupervised anomaly detection and localization is crucial to the practical application when collecting and labeling sufficient anomaly data is infeasible. Most existing representation-based approaches extract normal image features with a deep convolutional neural network and characterize the corresponding distribution through non-parametric distribution estimation methods. The anomaly score is calculated by measuring the distance between the feature of the test image and the estimated distribution. However, current methods can not effectively map image features to a tractable base distribution and ignore the relationship between local and global features which are important to identify anomalies. To this end, we propose FastFlow implemented with 2D normalizing flows and use it as the probability distribution estimator. Our FastFlow can be used as a plug-in module with arbitrary deep feature extractors such as ResNet and vision transformer for unsupervised anomaly detection and localization. In training phase, FastFlow learns to transform the input visual feature into a tractable distribution and obtains the likelihood to recognize anomalies in inference phase. Extensive experimental results on the MVTec AD dataset show that FastFlow surpasses previous state-of-the-art methods in terms of accuracy and inference efficiency with various backbone networks. Our approach achieves 99.4% AUC in anomaly detection with high inference efficiency.
Focus Your Distribution: Coarse-to-Fine Non-Contrastive Learning for Anomaly Detection and Localization
Oct 09, 2021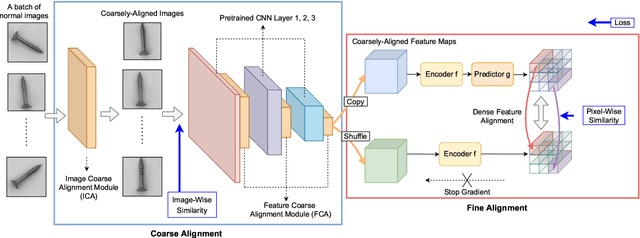
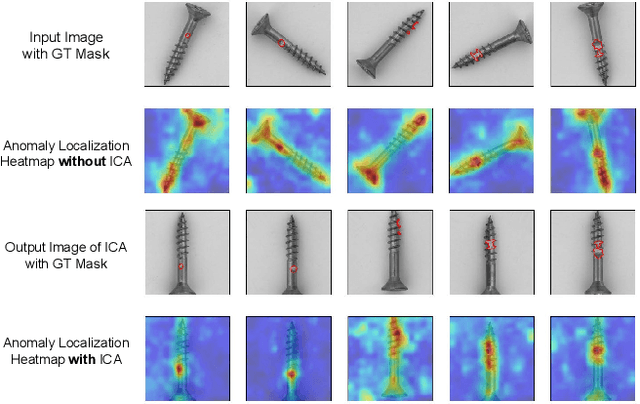
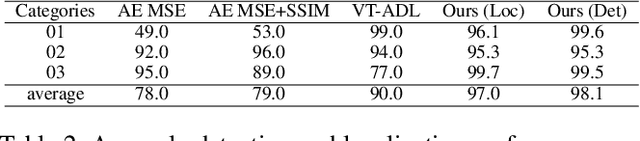
The essence of unsupervised anomaly detection is to learn the compact distribution of normal samples and detect outliers as anomalies in testing. Meanwhile, the anomalies in real-world are usually subtle and fine-grained in a high-resolution image especially for industrial applications. Towards this end, we propose a novel framework for unsupervised anomaly detection and localization. Our method aims at learning dense and compact distribution from normal images with a coarse-to-fine alignment process. The coarse alignment stage standardizes the pixel-wise position of objects in both image and feature levels. The fine alignment stage then densely maximizes the similarity of features among all corresponding locations in a batch. To facilitate the learning with only normal images, we propose a new pretext task called non-contrastive learning for the fine alignment stage. Non-contrastive learning extracts robust and discriminating normal image representations without making assumptions on abnormal samples, and it thus empowers our model to generalize to various anomalous scenarios. Extensive experiments on two typical industrial datasets of MVTec AD and BenTech AD demonstrate that our framework is effective in detecting various real-world defects and achieves a new state-of-the-art in industrial unsupervised anomaly detection.