 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reinforcement Learning in Factored MDPs with Application to Constrained RL
Sep 15, 2020Reinforcement learning (RL) in episodic, factored Markov decision processes (FMDPs) is studied. We propose an algorithm called FMDP-BF, which leverages the factorization structure of FMDP. The regret of FMDP-BF is shown to be exponentially smaller than that of optimal algorithms designed for non-factored MDPs, and improves on the best previous result for FMDPs~\citep{osband2014near} by a factored of $\sqrt{H|\mathcal{S}_i|}$, where $|\mathcal{S}_i|$ is the cardinality of the factored state subspace and $H$ is the planning horizon. To show the optimality of our bounds, we also provide a lower bound for FMDP, which indicates that our algorithm is near-optimal w.r.t. timestep $T$, horizon $H$ and factored state-action subspace cardinality. Finally, as an application, we study a new formulation of constrained RL, known as RL with knapsack constraints (RLwK), and provides the first sample-efficient algorithm based on FMDP-BF.
GraphNorm: A Principled Approach to Accelerating Graph Neural Network Training
Sep 07, 2020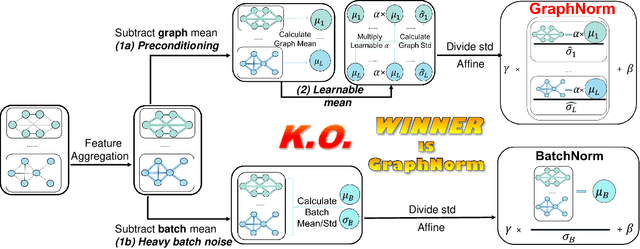
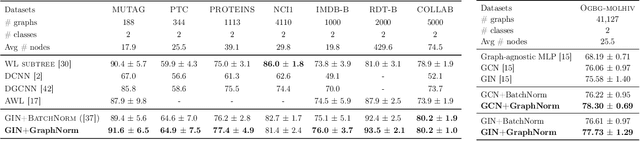
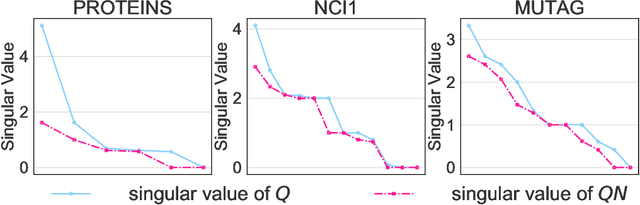
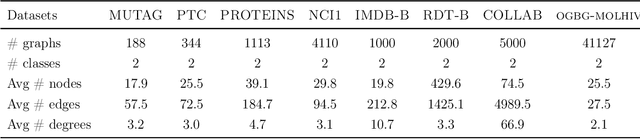
Normalization plays an important role in the optimization of deep neural networks. While there are standard normalization methods in computer vision and natural language processing, there is limited understanding of how to effectively normalize neural networks for graph representation learning. In this paper, we propose a principled normalization method, Graph Normalization (GraphNorm), where the key idea is to normalize the feature values across all nodes for each individual graph with a learnable shift. Theoretically, we show that GraphNorm serves as a preconditioner that smooths the distribution of the graph aggregation's spectrum, leading to faster optimization. Such an improvement cannot be well obtained if we use currently popular normalization methods, such as BatchNorm, which normalizes the nodes in a batch rather than in individual graphs, due to heavy batch noises. Moreover, we show that for some highly regular graphs, the mean of the feature values contains graph structural information, and directly subtracting the mean may lead to an expressiveness degradation. The learnable shift in GraphNorm enables the model to learn to avoid such degradation for those cases. Empirically, Graph neural networks (GNNs) with GraphNorm converge much faster compared to GNNs with other normalization methods, e.g., BatchNorm. GraphNorm also improves generalization of GNNs, achieving better performance on graph classification benchmarks.
Improving One-stage Visual Grounding by Recursive Sub-query Construction
Aug 03, 2020

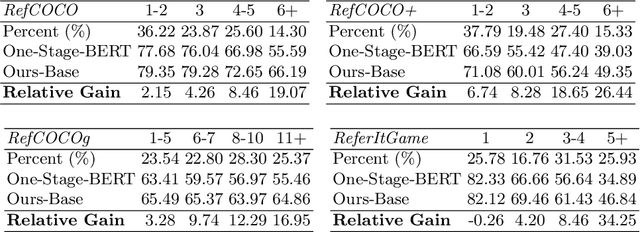
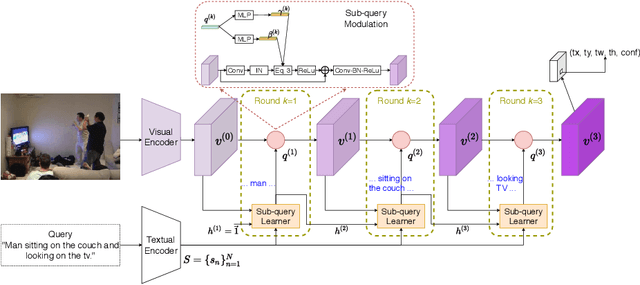
We improve one-stage visual grounding by addressing current limitations on grounding long and complex queries. Existing one-stage methods encode the entire language query as a single sentence embedding vector, e.g., taking the embedding from BERT or the hidden state from LSTM. This single vector representation is prone to overlooking the detailed descriptions in the query. To address this query modeling deficiency, we propose a recursive sub-query construction framework, which reasons between image and query for multiple rounds and reduces the referring ambiguity step by step. We show our new one-stage method obtains 5.0%, 4.5%, 7.5%, 12.8% absolute improvements over the state-of-the-art one-stage baseline on ReferItGame, RefCOCO, RefCOCO+, and RefCOCOg, respectively. In particular, superior performances on longer and more complex queries validates the effectiveness of our query modeling.
RANDOM MASK: Towards Robust Convolutional Neural Networks
Jul 27, 2020
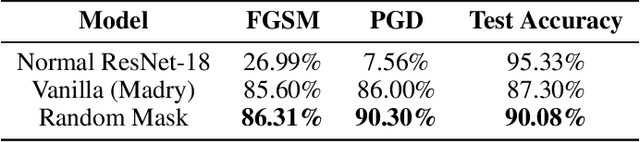
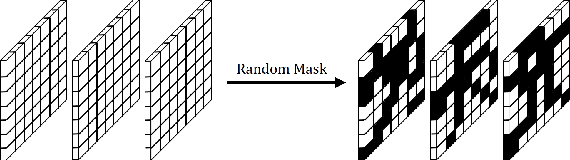
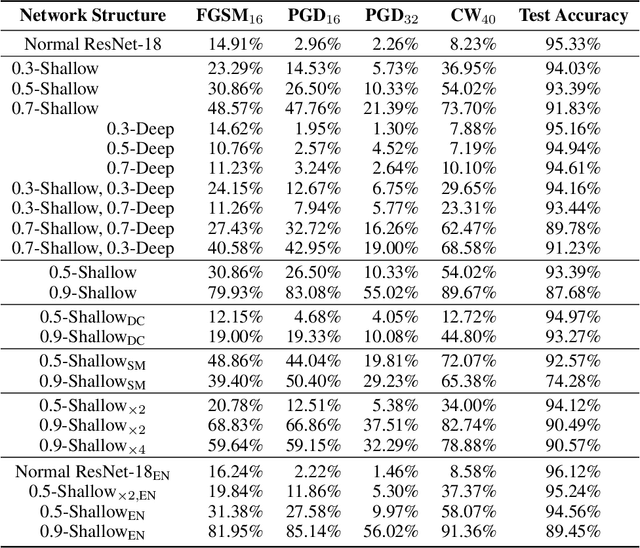
Robustness of neural networks has recently been highlighted by the adversarial examples, i.e., inputs added with well-designed perturbations which are imperceptible to humans but can cause the network to give incorrect outputs. In this paper, we design a new CNN architecture that by itself has good robustness. We introduce a simple but powerful technique, Random Mask, to modify existing CNN structures. We show that CNN with Random Mask achieves state-of-the-art performance against black-box adversarial attacks without applying any adversarial training. We next investigate the adversarial examples which 'fool' a CNN with Random Mask. Surprisingly, we find that these adversarial examples often 'fool' humans as well. This raises fundamental questions on how to define adversarial examples and robustness properly.
Transferred Discrepancy: Quantifying the Difference Between Representations
Jul 24, 2020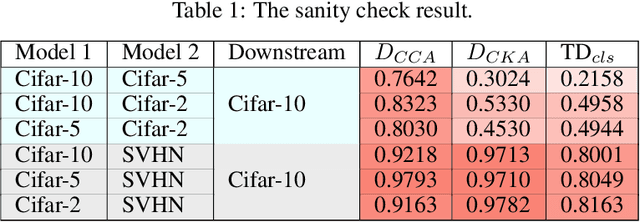
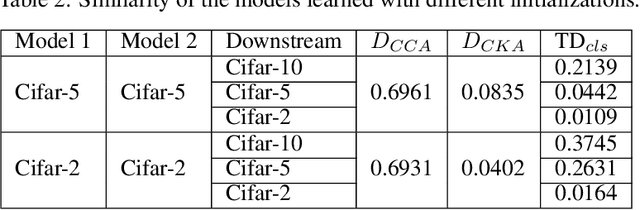
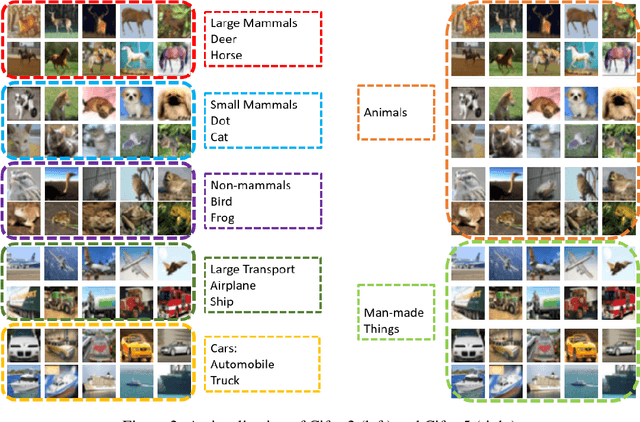
Understanding what information neural networks capture is an essential problem in deep learning, and studying whether different models capture similar features is an initial step to achieve this goal. Previous works sought to define metrics over the feature matrices to measure the difference between two models. However, different metrics sometimes lead to contradictory conclusions, and there has been no consensus on which metric is suitable to use in practice. In this work, we propose a novel metric that goes beyond previous approaches. Recall that one of the most practical scenarios of using the learned representations is to apply them to downstream tasks. We argue that we should design the metric based on a similar principle. For that, we introduce the transferred discrepancy (TD), a new metric that defines the difference between two representations based on their downstream-task performance. Through an asymptotic analysis, we show how TD correlates with downstream tasks and the necessity to define metrics in such a task-dependent fashion. In particular, we also show that under specific conditions, the TD metric is closely related to previous metrics. Our experiments show that TD can provide fine-grained information for varied downstream tasks, and for the models trained from different initializations, the learned features are not the same in terms of downstream-task predictions. We find that TD may also be used to evaluate the effectiveness of different training strategies. For example, we demonstrate that the models trained with proper data augmentations that improve the generalization capture more similar features in terms of TD, while those with data augmentations that hurt the generalization will not. This suggests a training strategy that leads to more robust representation also trains models that generalize better.
Comprehensive Image Captioning via Scene Graph Decomposition
Jul 23, 2020
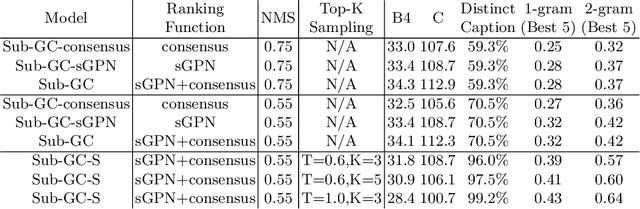
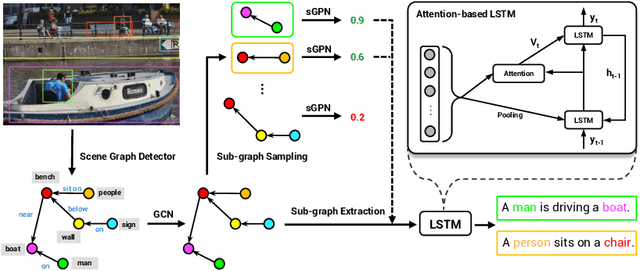
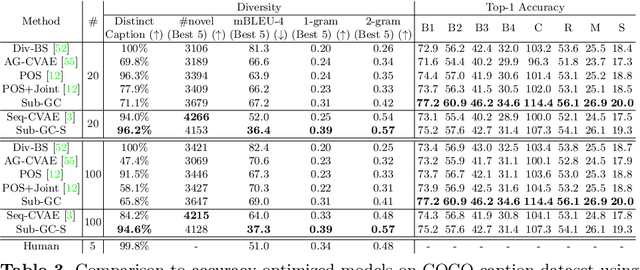
We address the challenging problem of image captioning by revisiting the representation of image scene graph. At the core of our method lies the decomposition of a scene graph into a set of sub-graphs, with each sub-graph capturing a semantic component of the input image. We design a deep model to select important sub-graphs, and to decode each selected sub-graph into a single target sentence. By using sub-graphs, our model is able to attend to different components of the image. Our method thus accounts for accurate, diverse, grounded and controllable captioning at the same time. We present extensive experiments to demonstrate the benefits of our comprehensive captioning model. Our method establishes new state-of-the-art results in caption diversity, grounding, and controllability, and compares favourably to latest methods in caption quality. Our project website can be found at http://pages.cs.wisc.edu/~yiwuzhong/Sub-GC.html.
RepPoints V2: Verification Meets Regression for Object Detection
Jul 16, 2020
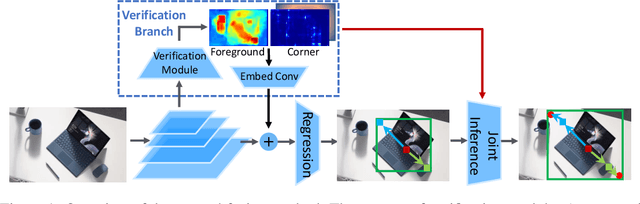
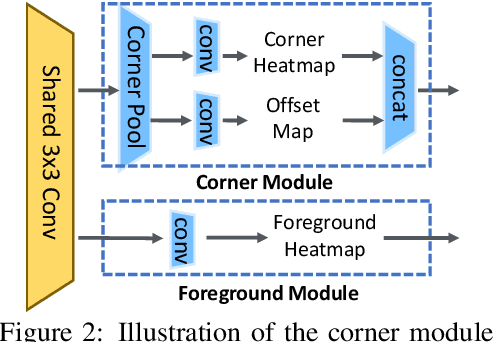
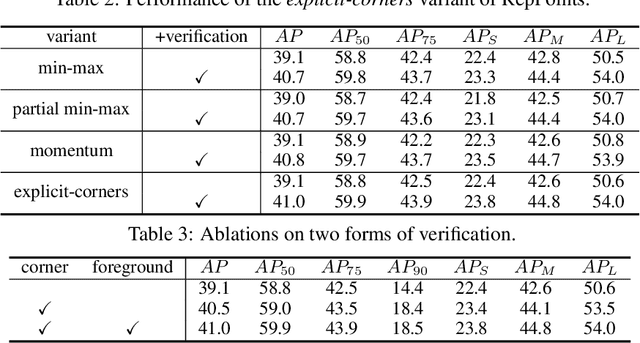
Verification and regression are two general methodologies for prediction in neural networks. Each has its own strengths: verification can be easier to infer accurately, and regression is more efficient and applicable to continuous target variables. Hence, it is often beneficial to carefully combine them to take advantage of their benefits. In this paper, we take this philosophy to improve state-of-the-art object detection, specifically by RepPoints. Though RepPoints provides high performance, we find that its heavy reliance on regression for object localization leaves room for improvement. We introduce verification tasks into the localization prediction of RepPoints, producing RepPoints v2, which provides consistent improvements of about 2.0 mAP over the original RepPoints on the COCO object detection benchmark using different backbones and training methods. RepPoints v2 also achieves 52.1 mAP on COCO \texttt{test-dev} by a single model. Moreover, we show that the proposed approach can more generally elevate other object detection frameworks as well as applications such as instance segmentation. The code is available at https://github.com/Scalsol/RepPointsV2.
Improving Weakly Supervised Visual Grounding by Contrastive Knowledge Distillation
Jul 03, 2020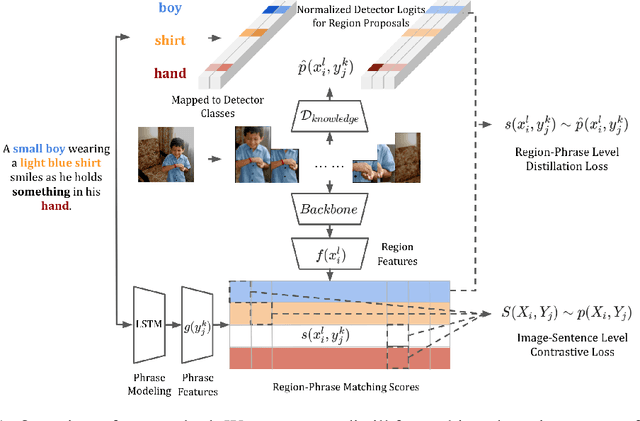
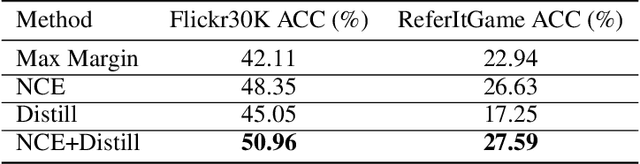

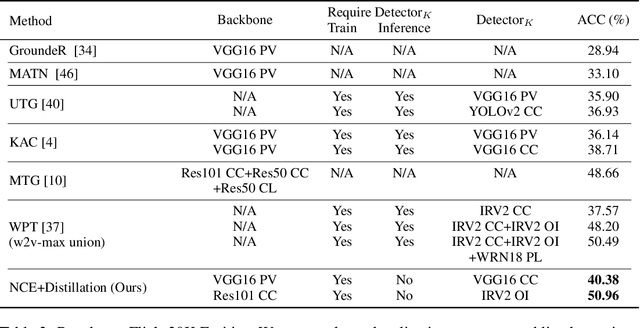
Weakly supervised phrase grounding aims at learning region-phrase correspondences using only image-sentence pairs. A major challenge thus lies in the missing links between image regions and sentence phrases during training. To address this challenge, we leverage a generic object detector at training time, and propose a contrastive learning framework that accounts for both region-phrase and image-sentence matching. Our core innovation is the learning of a region-phrase score function, based on which an image-sentence score function is further constructed. Importantly, our region-phrase score function is learned by distilling from soft matching scores between the detected object class names and candidate phrases within an image-sentence pair, while the image-sentence score function is supervised by ground-truth image-sentence pairs. The design of such score functions removes the need of object detection at test time, thereby significantly reducing the inference cost. Without bells and whistles, our approach achieves state-of-the-art results on the task of visual phrase grounding, surpassing previous methods that require expensive object detectors at test time.
Deep Generative Modeling for Mechanistic-based Learning and Design of Metamaterial Systems
Jun 27, 2020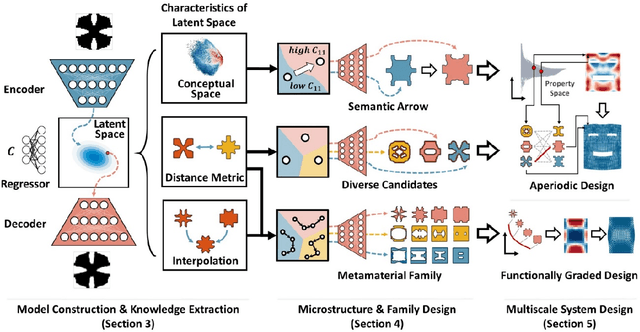
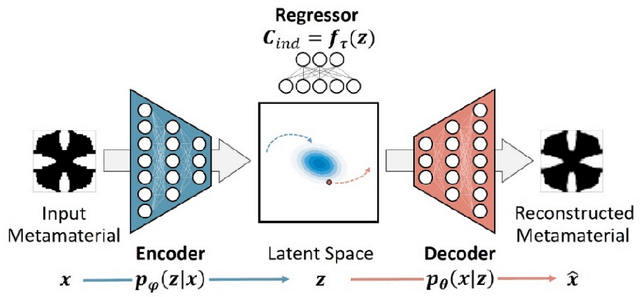
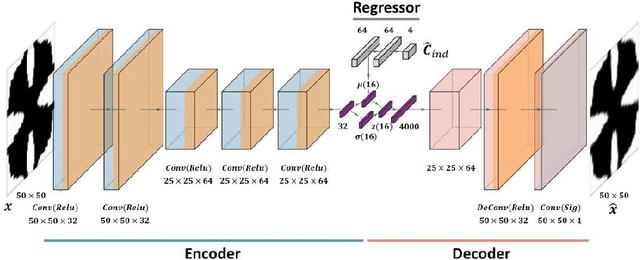
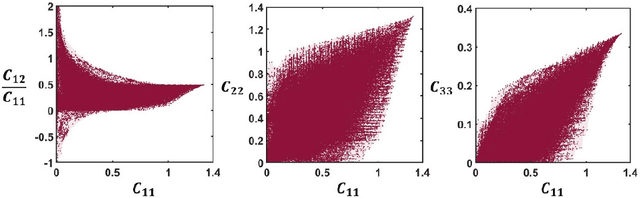
The inverse design of metamaterials is difficult due to a high-dimensional topological design space and presence of multiple local optima. Computational cost is even more demanding for design of multiscale metamaterial systems with aperiodic microstructures and spatially-varying or functionally gradient properties. Despite the growing interest in applying data-driven methods to address this hurdle, current methods either only focus on microstructure generation or adopt an unscalable framework for the multiscale design. In this study, we propose a novel data-driven metamaterial design framework based on deep generative modeling. A deep neural network model consisting of a variational autoencoder (VAE) and a regressor for property prediction is trained on a large metamaterial database to map complex microstructures into a low-dimensional, continuous and organized latent space. Our study shows several advantages of the VAE based generative model. First, the latent space of VAE provides a distance metric to measure shape similarity, enabling interpolation between microstructures and encoding meaningful patterns of variation in geometries and properties. For microstructure design, the tuning of mechanical properties and complex manipulations of microstructures are easily achieved by simple vector operations in the latent space. Second, the vector operation can be further extended to form metamaterial families with controlled gradation of mechanical properties. Third, for multiscale metamaterial systems design, a diverse set of microstructures can be rapidly generated based on target properties at different locations and then assembled by an efficient graph-based optimization method to ensure compatibility between adjacent microstructures. We demonstrate our framework by designing both functionally graded and heterogeneous metamaterial systems that achieve desired distortion behaviors.
Data-Driven Topology Optimization with Multiclass Microstructures using Latent Variable Gaussian Process
Jun 27, 2020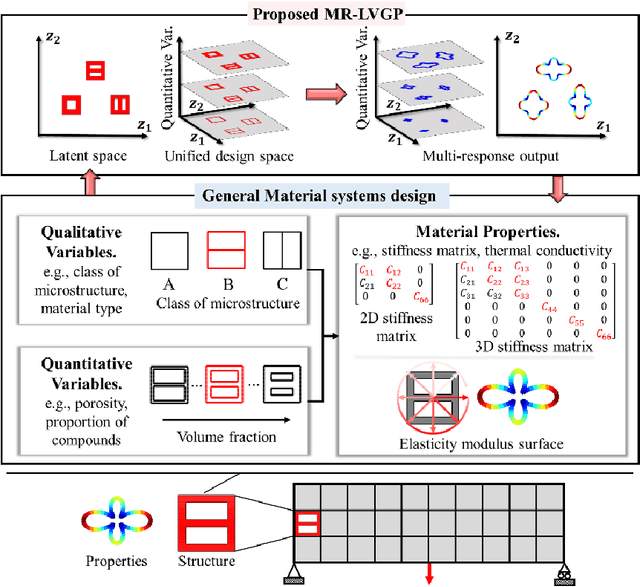
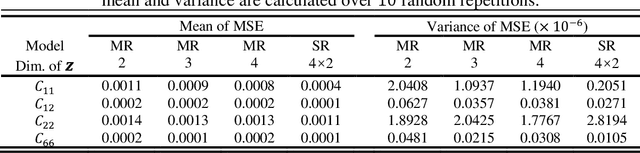
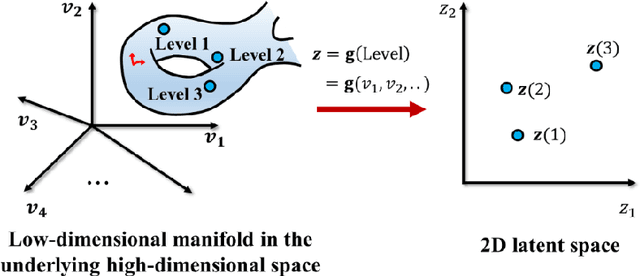
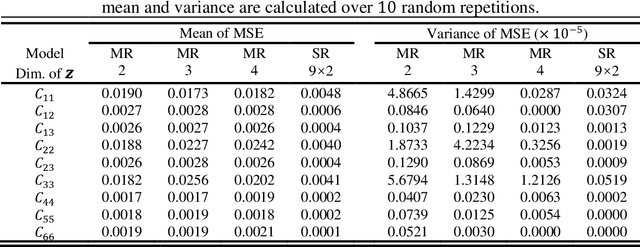
The data-driven approach is emerging as a promising method for the topological design of multiscale structures with greater efficiency. However, existing data-driven methods mostly focus on a single class of microstructures without considering multiple classes to accommodate spatially varying desired properties. The key challenge is the lack of an inherent ordering or distance measure between different classes of microstructures in meeting a range of properties. To overcome this hurdle, we extend the newly developed latent-variable Gaussian process (LVGP) models to create multi-response LVGP (MR-LVGP) models for the microstructure libraries of metamaterials, taking both qualitative microstructure concepts and quantitative microstructure design variables as mixed-variable inputs. The MR-LVGP model embeds the mixed variables into a continuous design space based on their collective effects on the responses, providing substantial insights into the interplay between different geometrical classes and material parameters of microstructures. With this model, we can easily obtain a continuous and differentiable transition between different microstructure concepts that can render gradient information for multiscale topology optimization. We demonstrate its benefits through multiscale topology optimization with aperiodic microstructures. Design examples reveal that considering multiclass microstructures can lead to improved performance due to the consistent load-transfer paths for micro- and macro-structures.