 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLION-FS: Fast & Slow Video-Language Thinker as Online Video Assistant
Mar 05, 2025



First-person video assistants are highly anticipated to enhance our daily lives through online video dialogue. However, existing online video assistants often sacrifice assistant efficacy for real-time efficiency by processing low-frame-rate videos with coarse-grained visual features.To overcome the trade-off between efficacy and efficiency, we propose "Fast & Slow Video-Language Thinker" as an onLIne videO assistaNt, LION-FS, achieving real-time, proactive, temporally accurate, and contextually precise responses. LION-FS adopts a two-stage optimization strategy: 1)Fast Path: Routing-Based Response Determination evaluates frame-by-frame whether an immediate response is necessary. To enhance response determination accuracy and handle higher frame-rate inputs efficiently, we employ Token Aggregation Routing to dynamically fuse spatiotemporal features without increasing token numbers, while utilizing Token Dropping Routing to eliminate redundant features. 2)Slow Path: Multi-granularity Keyframe Augmentation optimizes keyframes during response generation. To provide comprehensive and detailed responses beyond atomic actions constrained by training data, fine-grained spatial features and human-environment interaction features are extracted through multi-granular pooling. These features are further integrated into a meticulously designed multimodal Thinking Template to guide more precise response generation. Comprehensive evaluations on online video tasks demonstrate that LION-FS achieves state-of-the-art efficacy and efficiency.
HAIC: Improving Human Action Understanding and Generation with Better Captions for Multi-modal Large Language Models
Feb 28, 2025

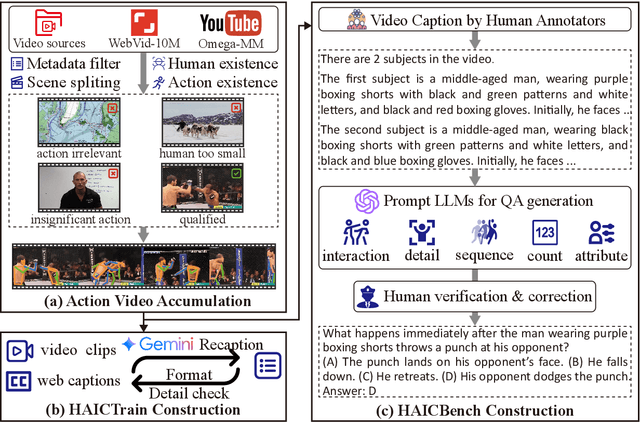
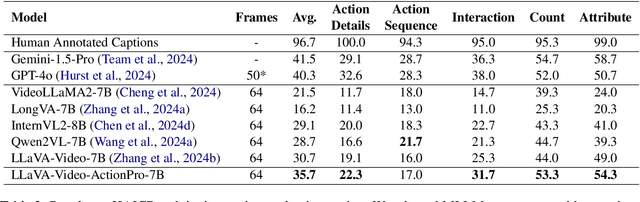
Recent Multi-modal Large Language Models (MLLMs) have made great progress in video understanding. However, their performance on videos involving human actions is still limited by the lack of high-quality data. To address this, we introduce a two-stage data annotation pipeline. First, we design strategies to accumulate videos featuring clear human actions from the Internet. Second, videos are annotated in a standardized caption format that uses human attributes to distinguish individuals and chronologically details their actions and interactions. Through this pipeline, we curate two datasets, namely HAICTrain and HAICBench. \textbf{HAICTrain} comprises 126K video-caption pairs generated by Gemini-Pro and verified for training purposes. Meanwhile, \textbf{HAICBench} includes 500 manually annotated video-caption pairs and 1,400 QA pairs, for a comprehensive evaluation of human action understanding. Experimental results demonstrate that training with HAICTrain not only significantly enhances human understanding abilities across 4 benchmarks, but can also improve text-to-video generation results. Both the HAICTrain and HAICBench are released at https://huggingface.co/datasets/KuaishouHAIC/HAIC.
3D-AffordanceLLM: Harnessing Large Language Models for Open-Vocabulary Affordance Detection in 3D Worlds
Feb 27, 20253D Affordance detection is a challenging problem with broad applications on various robotic tasks. Existing methods typically formulate the detection paradigm as a label-based semantic segmentation task. This paradigm relies on predefined labels and lacks the ability to comprehend complex natural language, resulting in limited generalization in open-world scene. To address these limitations, we reformulate the traditional affordance detection paradigm into \textit{Instruction Reasoning Affordance Segmentation} (IRAS) task. This task is designed to output a affordance mask region given a query reasoning text, which avoids fixed categories of input labels. We accordingly propose the \textit{3D-AffordanceLLM} (3D-ADLLM), a framework designed for reasoning affordance detection in 3D open-scene. Specifically, 3D-ADLLM introduces large language models (LLMs) to 3D affordance perception with a custom-designed decoder for generating affordance masks, thus achieving open-world reasoning affordance detection. In addition, given the scarcity of 3D affordance datasets for training large models, we seek to extract knowledge from general segmentation data and transfer it to affordance detection. Thus, we propose a multi-stage training strategy that begins with a novel pre-training task, i.e., \textit{Referring Object Part Segmentation}~(ROPS). This stage is designed to equip the model with general recognition and segmentation capabilities at the object-part level. Then followed by fine-tuning with the IRAS task, 3D-ADLLM obtains the reasoning ability for affordance detection. In summary, 3D-ADLLM leverages the rich world knowledge and human-object interaction reasoning ability of LLMs, achieving approximately an 8\% improvement in mIoU on open-vocabulary affordance detection tasks.
Optimus-2: Multimodal Minecraft Agent with Goal-Observation-Action Conditioned Policy
Feb 27, 2025



Building an agent that can mimic human behavior patterns to accomplish various open-world tasks is a long-term goal. To enable agents to effectively learn behavioral patterns across diverse tasks, a key challenge lies in modeling the intricate relationships among observations, actions, and language. To this end, we propose Optimus-2, a novel Minecraft agent that incorporates a Multimodal Large Language Model (MLLM) for high-level planning, alongside a Goal-Observation-Action Conditioned Policy (GOAP) for low-level control. GOAP contains (1) an Action-guided Behavior Encoder that models causal relationships between observations and actions at each timestep, then dynamically interacts with the historical observation-action sequence, consolidating it into fixed-length behavior tokens, and (2) an MLLM that aligns behavior tokens with open-ended language instructions to predict actions auto-regressively. Moreover, we introduce a high-quality Minecraft Goal-Observation-Action (MGOA)} dataset, which contains 25,000 videos across 8 atomic tasks, providing about 30M goal-observation-action pairs. The automated construction method, along with the MGOA dataset, can contribute to the community's efforts to train Minecraft agents. Extensive experimental results demonstrate that Optimus-2 exhibits superior performance across atomic tasks, long-horizon tasks, and open-ended instruction tasks in Minecraft.
A Comprehensive Survey on Composed Image Retrieval
Feb 19, 2025



Composed Image Retrieval (CIR) is an emerging yet challenging task that allows users to search for target images using a multimodal query, comprising a reference image and a modification text specifying the user's desired changes to the reference image. Given its significant academic and practical value, CIR has become a rapidly growing area of interest in the computer vision and machine learning communities, particularly with the advances in deep learning. To the best of our knowledge, there is currently no comprehensive review of CIR to provide a timely overview of this field. Therefore, we synthesize insights from over 120 publications in top conferences and journals, including ACM TOIS, SIGIR, and CVPR In particular, we systematically categorize existing supervised CIR and zero-shot CIR models using a fine-grained taxonomy. For a comprehensive review, we also briefly discuss approaches for tasks closely related to CIR, such as attribute-based CIR and dialog-based CIR. Additionally, we summarize benchmark datasets for evaluation and analyze existing supervised and zero-shot CIR methods by comparing experimental results across multiple datasets. Furthermore, we present promising future directions in this field, offering practical insights for researchers interested in further exploration.
Benchmarking Post-Training Quantization in LLMs: Comprehensive Taxonomy, Unified Evaluation, and Comparative Analysis
Feb 18, 2025



Post-training Quantization (PTQ) technique has been extensively adopted for large language models (LLMs) compression owing to its efficiency and low resource requirement. However, current research lacks a in-depth analysis of the superior and applicable scenarios of each PTQ strategy. In addition, existing algorithms focus primarily on performance, overlooking the trade-off among model size, performance, and quantization bitwidth. To mitigate these confusions, we provide a novel benchmark for LLMs PTQ in this paper. Firstly, in order to support our benchmark, we propose a comprehensive taxonomy for existing mainstream methods by scrutinizing their computational strategies (e.g., optimization-based, compensation-based, etc.). Then, we conduct extensive experiments with the baseline within each class, covering models with various sizes (7B-70B), bitwidths, training levels (LLaMA1/2/3/3.1), architectures (Mixtral, DeepSeekMoE and Mamba) and modality (LLaVA1.5 and VILA1.5) on a wide range of evaluation metrics.Through comparative analysis on the results, we summarize the superior of each PTQ strategy and modelsize-bitwidth trade-off considering the performance. For example, our benchmark reveals that compensation-based technique demonstrates outstanding cross-architecture robustness and extremely low-bit PTQ for ultra large models should be reexamined. Finally, we further accordingly claim that a practical combination of compensation and other PTQ strategy can achieve SOTA various robustness. We believe that our benchmark will provide valuable recommendations for the deployment of LLMs and future research on PTQ approaches.
FALCON: Resolving Visual Redundancy and Fragmentation in High-resolution Multimodal Large Language Models via Visual Registers
Jan 27, 2025



The incorporation of high-resolution visual input equips multimodal large language models (MLLMs) with enhanced visual perception capabilities for real-world tasks. However, most existing high-resolution MLLMs rely on a cropping-based approach to process images, which leads to fragmented visual encoding and a sharp increase in redundant tokens. To tackle these issues, we propose the FALCON model. FALCON introduces a novel visual register technique to simultaneously: 1) Eliminate redundant tokens at the stage of visual encoding. To directly address the visual redundancy present in the output of vision encoder, we propose a Register-based Representation Compacting (ReCompact) mechanism. This mechanism introduces a set of learnable visual registers designed to adaptively aggregate essential information while discarding redundancy. It enables the encoder to produce a more compact visual representation with a minimal number of output tokens, thus eliminating the need for an additional compression module. 2) Ensure continuity in visual encoding. To address the potential encoding errors caused by fragmented visual inputs, we develop a Register Interactive Attention (ReAtten) module. This module facilitates effective and efficient information exchange across sub-images by enabling interactions between visual registers. It ensures the continuity of visual semantics throughout the encoding. We conduct comprehensive experiments with FALCON on high-resolution benchmarks across a wide range of scenarios. FALCON demonstrates superior performance with a remarkable 9-fold and 16-fold reduction in visual tokens.
Dynamic Multimodal Fusion via Meta-Learning Towards Micro-Video Recommendation
Jan 13, 2025



Multimodal information (e.g., visual, acoustic, and textual) has been widely used to enhance representation learning for micro-video recommendation. For integrating multimodal information into a joint representation of micro-video, multimodal fusion plays a vital role in the existing micro-video recommendation approaches. However, the static multimodal fusion used in previous studies is insufficient to model the various relationships among multimodal information of different micro-videos. In this paper, we develop a novel meta-learning-based multimodal fusion framework called Meta Multimodal Fusion (MetaMMF), which dynamically assigns parameters to the multimodal fusion function for each micro-video during its representation learning. Specifically, MetaMMF regards the multimodal fusion of each micro-video as an independent task. Based on the meta information extracted from the multimodal features of the input task, MetaMMF parameterizes a neural network as the item-specific fusion function via a meta learner. We perform extensive experiments on three benchmark datasets, demonstrating the significant improvements over several state-of-the-art multimodal recommendation models, like MMGCN, LATTICE, and InvRL. Furthermore, we lighten our model by adopting canonical polyadic decomposition to improve the training efficiency, and validate its effectiveness through experimental results. Codes are available at https://github.com/hanliu95/MetaMMF.
ReTaKe: Reducing Temporal and Knowledge Redundancy for Long Video Understanding
Dec 29, 2024Video Large Language Models (VideoLLMs) have achieved remarkable progress in video understanding. However, existing VideoLLMs often inherit the limitations of their backbone LLMs in handling long sequences, leading to challenges for long video understanding. Common solutions either simply uniformly sample videos' frames or compress visual tokens, which focus primarily on low-level temporal visual redundancy, overlooking high-level knowledge redundancy. This limits the achievable compression rate with minimal loss. To this end. we introduce a training-free method, $\textbf{ReTaKe}$, containing two novel modules DPSelect and PivotKV, to jointly model and reduce both temporal visual redundancy and knowledge redundancy for long video understanding. Specifically, DPSelect identifies keyframes with local maximum peak distance based on their visual features, which are closely aligned with human video perception. PivotKV employs the obtained keyframes as pivots and conducts KV-Cache compression for the non-pivot tokens with low attention scores, which are derived from the learned prior knowledge of LLMs. Experiments on benchmarks VideoMME, MLVU, and LVBench, show that ReTaKe can support 4x longer video sequences with minimal performance loss (<1%) and outperform all similar-size VideoLLMs with 3%-5%, even surpassing or on par with much larger ones. Our code is available at https://github.com/SCZwangxiao/video-ReTaKe
Technical Report for ICML 2024 TiFA Workshop MLLM Attack Challenge: Suffix Injection and Projected Gradient Descent Can Easily Fool An MLLM
Dec 20, 2024


This technical report introduces our top-ranked solution that employs two approaches, \ie suffix injection and projected gradient descent (PGD) , to address the TiFA workshop MLLM attack challenge. Specifically, we first append the text from an incorrectly labeled option (pseudo-labeled) to the original query as a suffix. Using this modified query, our second approach applies the PGD method to add imperceptible perturbations to the image. Combining these two techniques enables successful attacks on the LLaVA 1.5 model.