 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraining Temporal Relationship for Action Localization
Feb 18, 2020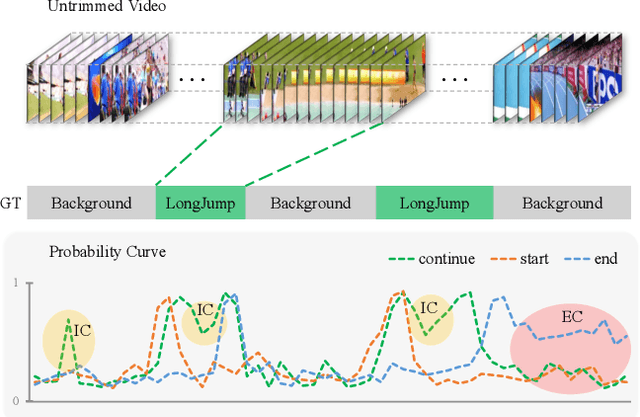
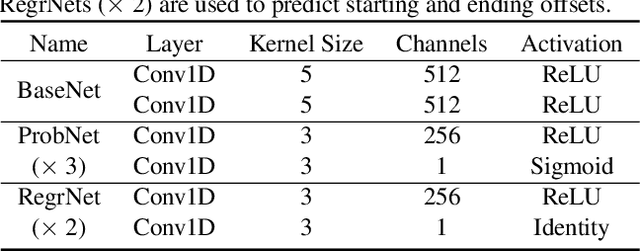
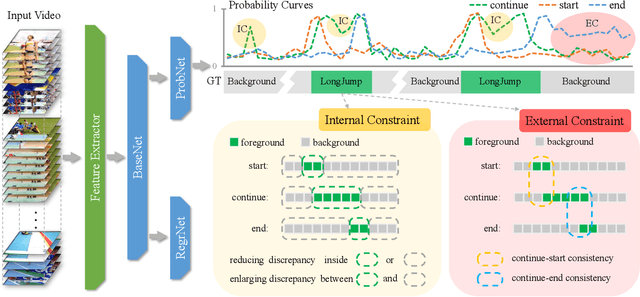
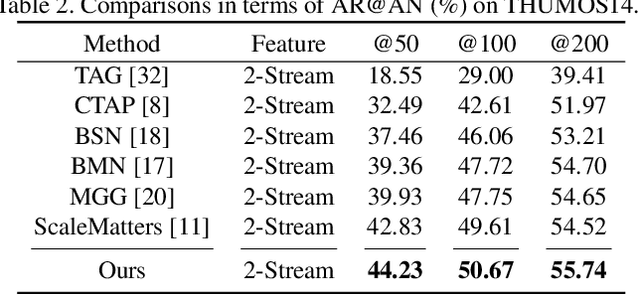
Recently, temporal action localization (TAL), i.e., finding specific action segments in untrimmed videos, has attracted increasing attentions of the computer vision community. State-of-the-art solutions for TAL involves predicting three values at each time point, corresponding to the probabilities that the action starts, continues and ends, and post-processing these curves for the final localization. This paper delves deep into this mechanism, and argues that existing approaches mostly ignored the potential relationship of these curves, and results in low quality of action proposals. To alleviate this problem, we add extra constraints to these curves, e.g., the probability of ''action continues'' should be relatively high between probability peaks of ''action starts'' and ''action ends'', so that the entire framework is aware of these latent constraints during an end-to-end optimization process. Experiments are performed on two popular TAL datasets, THUMOS14 and ActivityNet1.3. Our approach clearly outperforms the baseline both quantitatively (in terms of the AR@AN and mAP) and qualitatively (the curves in the testing stage become much smoother). In particular, when we build our constraints beyond TSA-Net and PGCN, we achieve the state-of-the-art performance especially at strict high IoU settings. The code will be available.
Disassembling the Dataset: A Camera Alignment Mechanism for Multiple Tasks in Person Re-identification
Jan 23, 2020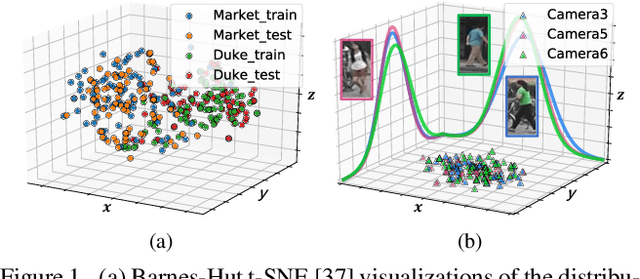
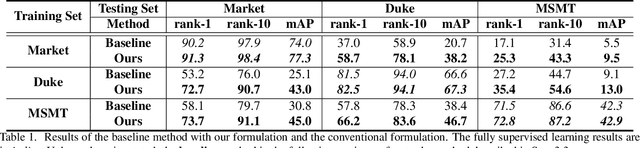
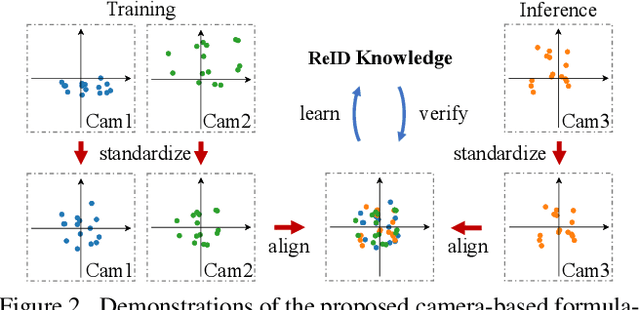
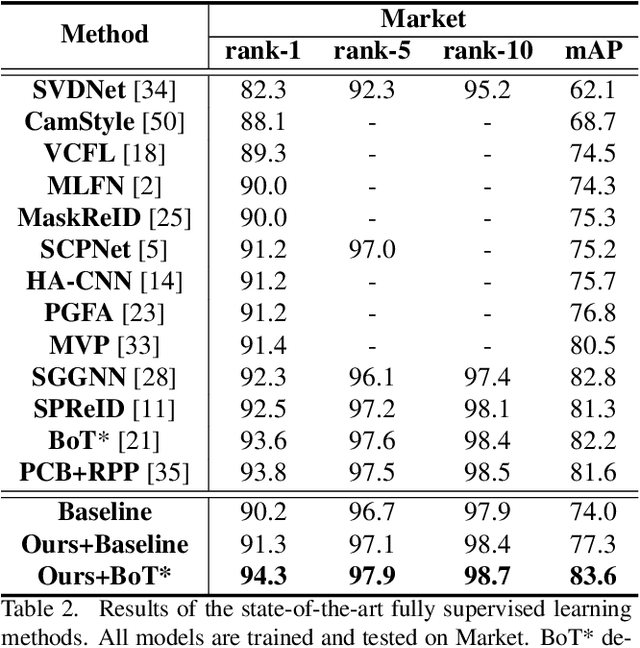
In person re-identification (ReID), one of the main challenges is the distribution inconsistency among different datasets. Previous researchers have defined several seemingly individual topics, such as fully supervised learning, direct transfer, domain adaptation, and incremental learning, each with different settings of training and testing scenarios. These topics are designed in a dataset-wise manner, i.e., images from the same dataset, even from disjoint cameras, are presumed to follow the same distribution. However, such distribution is coarse and training-set-specific, and the ReID knowledge learned in such manner works well only on the corresponding scenarios. To address this issue, we propose a fine-grained distribution alignment formulation, which disassembles the dataset and aligns all training and testing cameras. It connects all topics above and guarantees that ReID knowledge is always learned, accumulated, and verified in the aligned distributions. In practice, we devise the Camera-based Batch Normalization, which is easy for integration and nearly cost-free for existing ReID methods. Extensive experiments on the above four ReID tasks demonstrate the superiority of our approach. The code will be publicly available.
Latency-Aware Differentiable Neural Architecture Search
Jan 17, 2020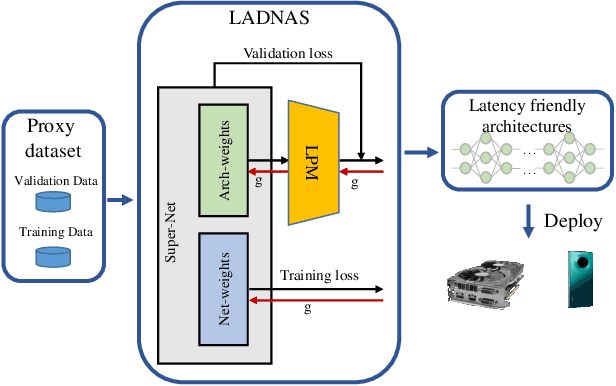

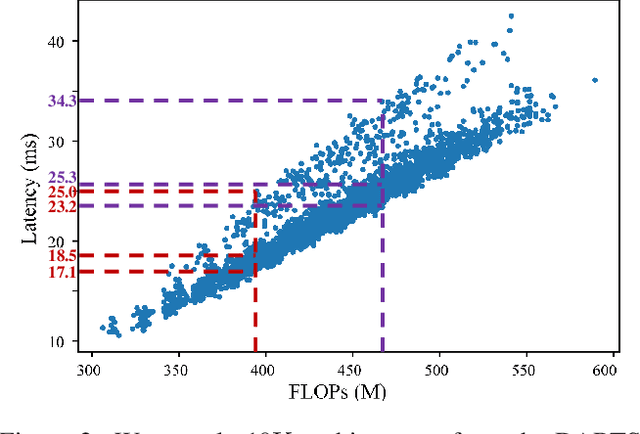
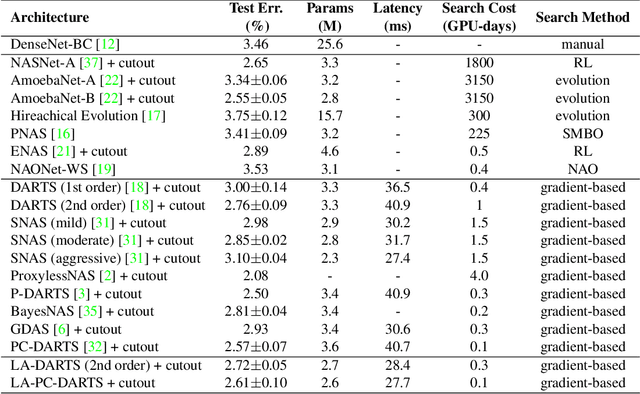
Differentiable neural architecture search methods became popular in automated machine learning, mainly due to their low search costs and flexibility in designing the search space. However, these methods suffer the difficulty in optimizing network, so that the searched network is often unfriendly to hardware. This paper deals with this problem by adding a differentiable latency loss term into optimization, so that the search process can tradeoff between accuracy and latency with a balancing coefficient. The core of latency prediction is to encode each network architecture and feed it into a multi-layer regressor, with the training data being collected from randomly sampling a number of architectures and evaluating them on the hardware. We evaluate our approach on NVIDIA Tesla-P100 GPUs. With 100K sampled architectures (requiring a few hours), the latency prediction module arrives at a relative error of lower than 10\%. Equipped with this module, the search method can reduce the latency by 20% meanwhile preserving the accuracy. Our approach also enjoys the ability of being transplanted to a wide range of hardware platforms with very few efforts, or being used to optimizing other non-differentiable factors such as power consumption.
Progressive DARTS: Bridging the Optimization Gap for NAS in the Wild
Jan 06, 2020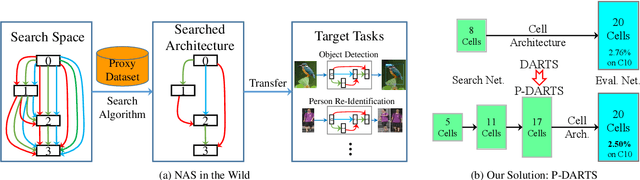
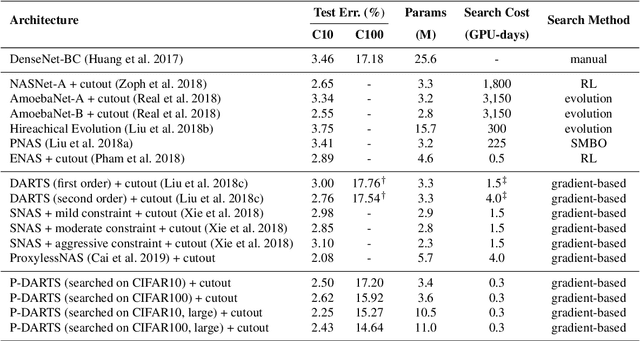
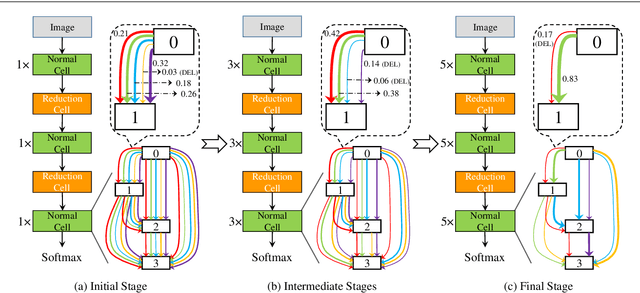
With the rapid development of neural architecture search (NAS), researchers found powerful network architectures for a wide range of vision tasks. However, it remains unclear if the searched architecture can transfer across different types of tasks as manually designed ones did. This paper puts forward this problem, referred to as NAS in the wild, which explores the possibility of finding the optimal architecture in a proxy dataset and then deploying it to mostly unseen scenarios. We instantiate this setting using a currently popular algorithm named differentiable architecture search (DARTS), which often suffers unsatisfying performance while being transferred across different tasks. We argue that the accuracy drop originates from the formulation that uses a super-network for search but a sub-network for re-training. The different properties of these stages have resulted in a significant optimization gap, and consequently, the architectural parameters "over-fit" the super-network. To alleviate the gap, we present a progressive method that gradually increases the network depth during the search stage, which leads to the Progressive DARTS (P-DARTS) algorithm. With a reduced search cost (7 hours on a single GPU), P-DARTS achieves improved performance on both the proxy dataset (CIFAR10) and a few target problems (ImageNet classification, COCO detection and three ReID benchmarks). Our code is available at \url{https://github.com/chenxin061/pdarts}.
Scalable NAS with Factorizable Architectural Parameters
Dec 31, 2019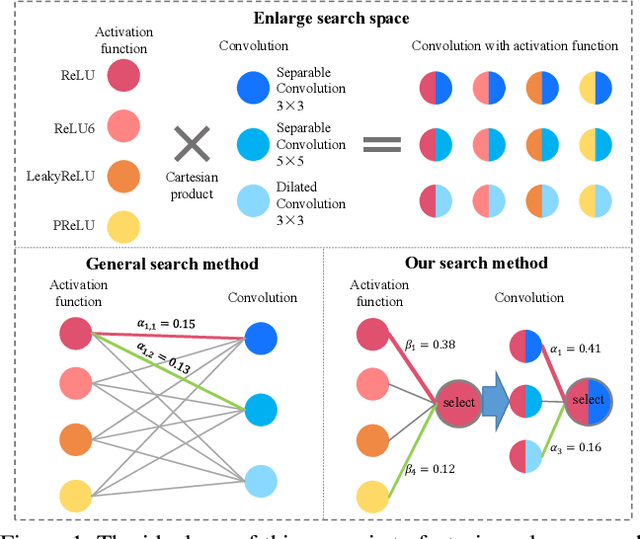
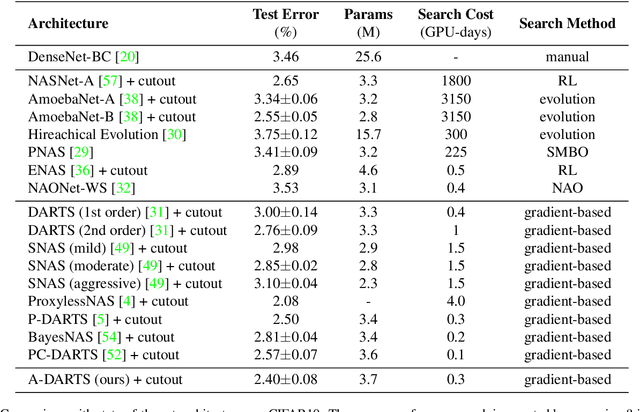
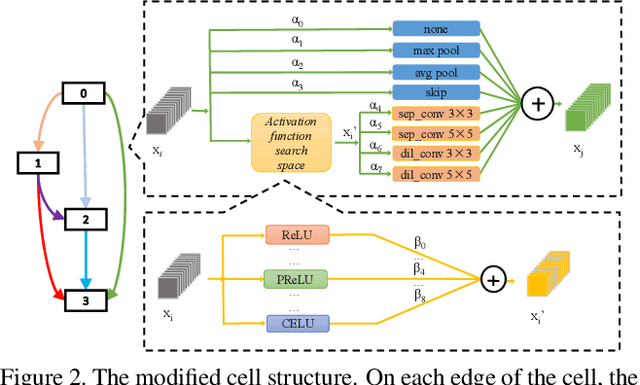
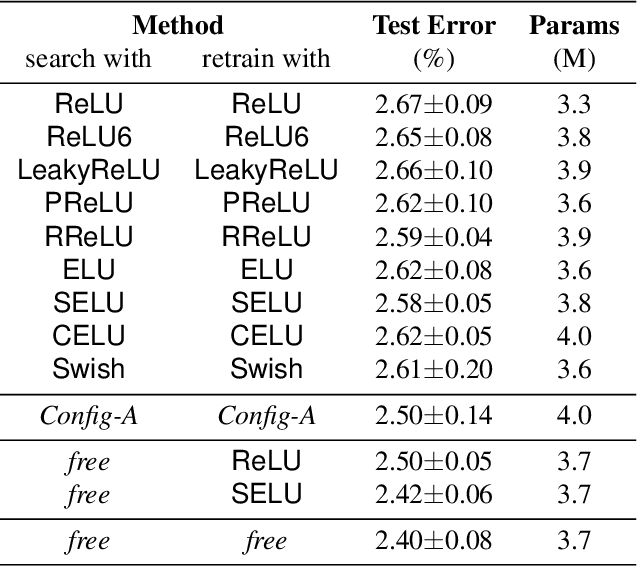
Neural architecture search (NAS) is an emerging topic in machine learning and computer vision. The fundamental ideology of NAS is using an automatic mechanism to replace manual designs for exploring powerful network architectures. One of the key factors of NAS is to scale-up the search space, e.g., increasing the number of operators, so that more possibilities are covered, but existing search algorithms often get lost in a large number of operators. This paper presents a scalable NAS algorithm by designing a factorizable set of architectural parameters, so that the size of the search space goes up quadratically while the burden of optimization increases linearly. As a practical example, we add a set of activation functions to the original set containing convolution, pooling and skip-connect, etc. With a marginal increase in search costs and no extra costs in retraining, we can find interesting architectures that were not explored before and achieve state-of-the-art performance in CIFAR10 and ImageNet, two standard image classification benchmarks.
Appending Adversarial Frames for Universal Video Attack
Dec 10, 2019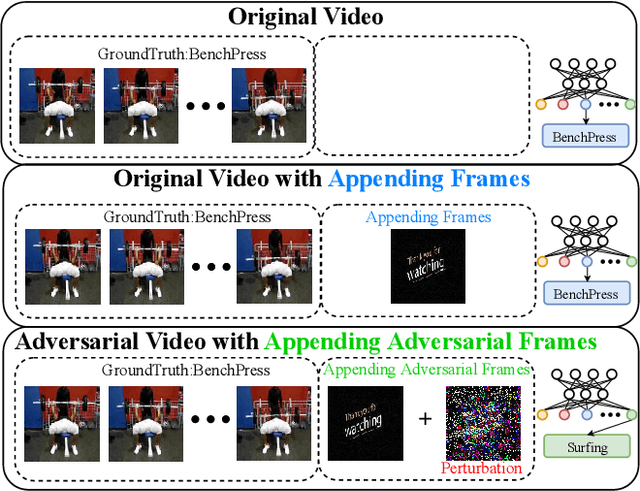
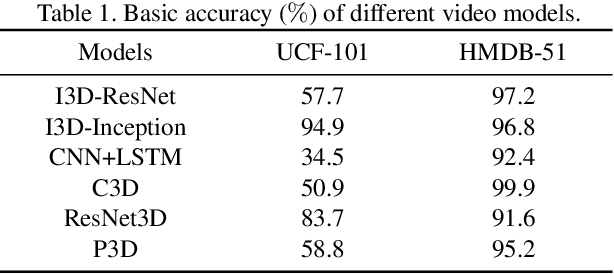
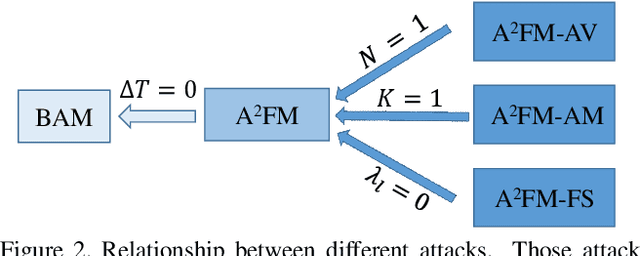
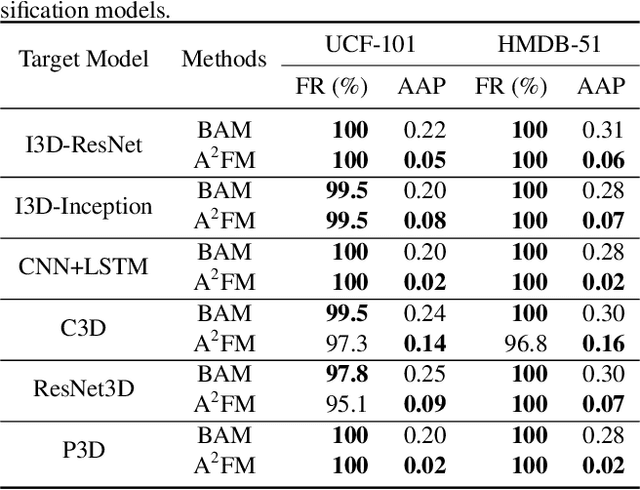
There have been many efforts in attacking image classification models with adversarial perturbations, but the same topic on video classification has not yet been thoroughly studied. This paper presents a novel idea of video-based attack, which appends a few dummy frames (e.g., containing the texts of `thanks for watching') to a video clip and then adds adversarial perturbations only on these new frames. Our approach enjoys three major benefits, namely, a high success rate, a low perceptibility, and a strong ability in transferring across different networks. These benefits mostly come from the common dummy frame which pushes all samples towards the boundary of classification. On the other hand, such attacks are easily to be concealed since most people would not notice the abnormality behind the perturbed video clips. We perform experiments on two popular datasets with six state-of-the-art video classification models, and demonstrate the effectiveness of our approach in the scenario of universal video attacks.
Stabilizing DARTS with Amended Gradient Estimation on Architectural Parameters
Nov 11, 2019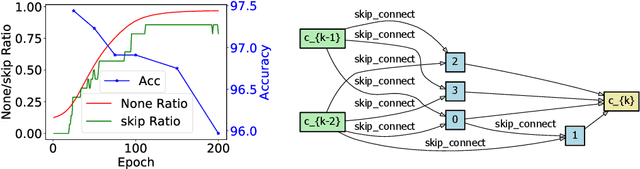
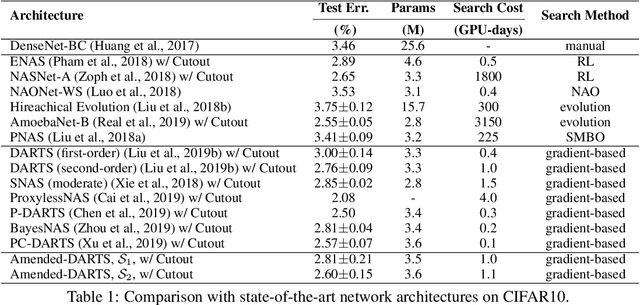
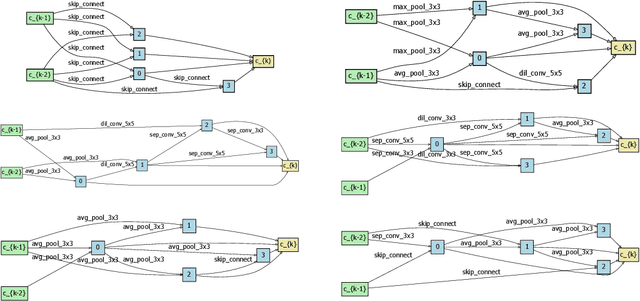
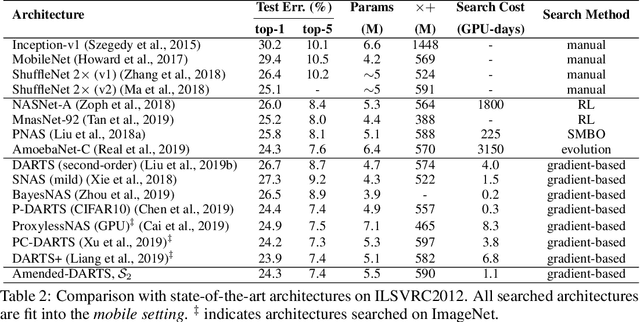
Differentiable neural architecture search has been a popular methodology of exploring architectures for deep learning. Despite the great advantage of search efficiency, it often suffers weak stability, which obstacles it from being applied to a large search space or being flexibly adjusted to different scenarios. This paper investigates DARTS, the currently most popular differentiable search algorithm, and points out an important factor of instability, which lies in its approximation on the gradients of architectural parameters. In the current status, the optimization algorithm can converge to another point which results in dramatic inaccuracy in the re-training process. Based on this analysis, we propose an amending term for computing architectural gradients by making use of a direct property of the optimality of network parameter optimization. Our approach mathematically guarantees that gradient estimation follows a roughly correct direction, which leads the search stage to converge on reasonable architectures. In practice, our algorithm is easily implemented and added to DARTS-based approaches efficiently. Experiments on CIFAR and ImageNet demonstrate that our approach enjoys accuracy gain and, more importantly, enables DARTS-based approaches to explore much larger search spaces that have not been studied before.
Pruning from Scratch
Sep 27, 2019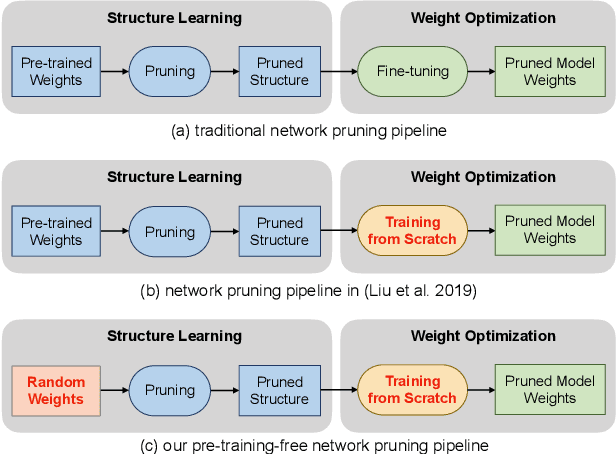
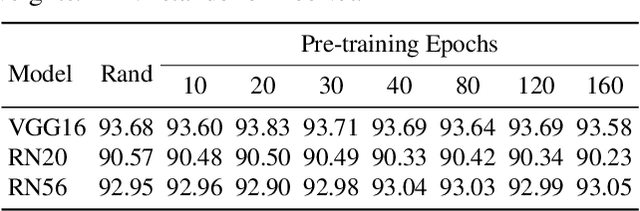
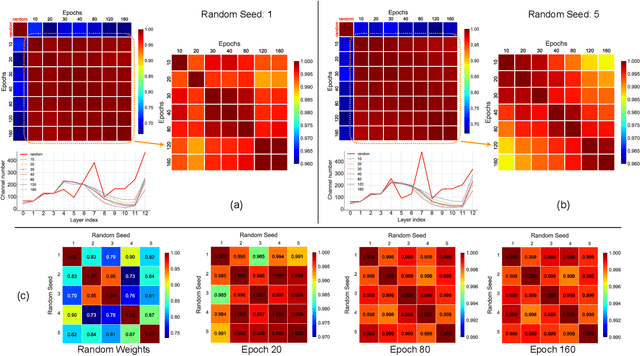
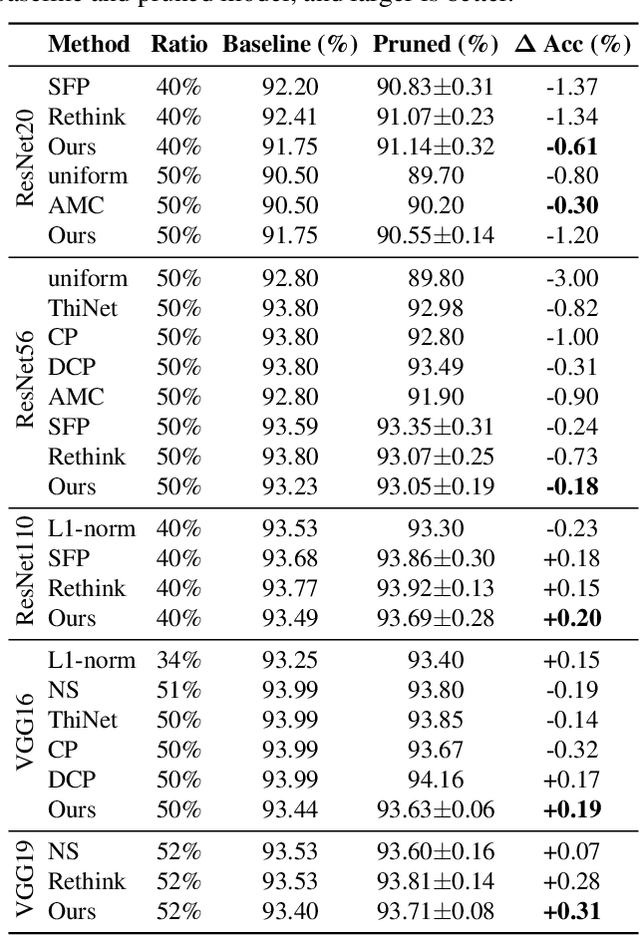
Network pruning is an important research field aiming at reducing computational costs of neural networks. Conventional approaches follow a fixed paradigm which first trains a large and redundant network, and then determines which units (e.g., channels) are less important and thus can be removed. In this work, we find that pre-training an over-parameterized model is not necessary for obtaining the target pruned structure. In fact, a fully-trained over-parameterized model will reduce the search space for the pruned structure. We empirically show that more diverse pruned structures can be directly pruned from randomly initialized weights, including potential models with better performance. Therefore, we propose a novel network pruning pipeline which allows pruning from scratch. In the experiments for compressing classification models on CIFAR10 and ImageNet datasets, our approach not only greatly reduces the pre-training burden of traditional pruning methods, but also achieves similar or even higher accuracy under the same computation budgets. Our results facilitate the community to rethink the effectiveness of existing techniques used for network pruning.
Single Camera Training for Person Re-identification
Sep 24, 2019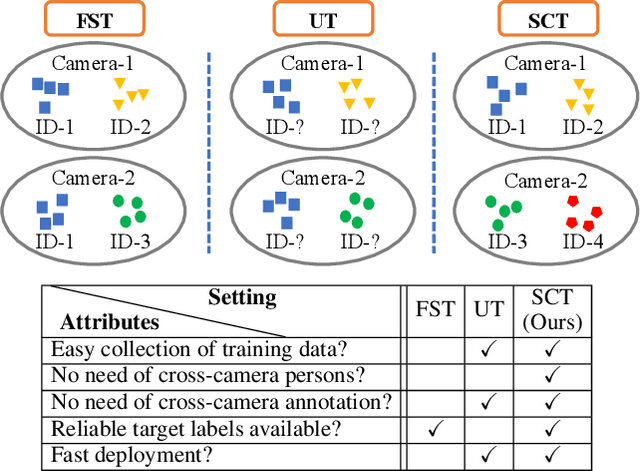
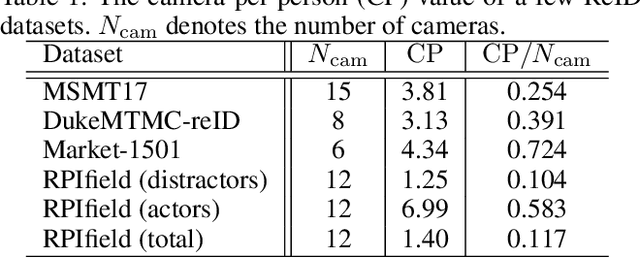
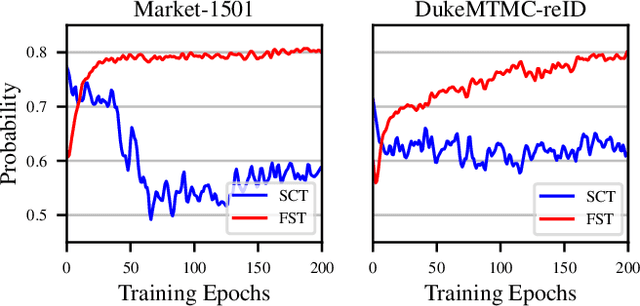
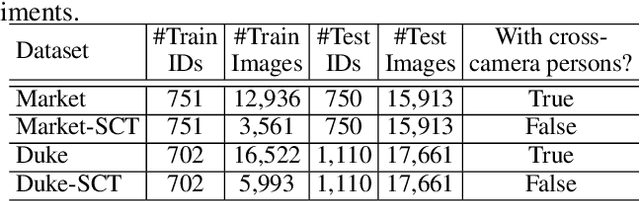
Person re-identification (ReID) aims at finding the same person in different cameras. Training such systems usually requires a large amount of cross-camera pedestrians to be annotated from surveillance videos, which is labor-consuming especially when the number of cameras is large. Differently, this paper investigates ReID in an unexplored single-camera-training (SCT) setting, where each person in the training set appears in only one camera. To the best of our knowledge, this setting was never studied before. SCT enjoys the advantage of low-cost data collection and annotation, and thus eases ReID systems to be trained in a brand new environment. However, it raises major challenges due to the lack of cross-camera person occurrences, which conventional approaches heavily rely on to extract discriminative features. The key to dealing with the challenges in the SCT setting lies in designing an effective mechanism to complement cross-camera annotation. We start with a regular deep network for feature extraction, upon which we propose a novel loss function named multi-camera negative loss (MCNL). This is a metric learning loss motivated by probability, suggesting that in a multi-camera system, one image is more likely to be closer to the most similar negative sample in other cameras than to the most similar negative sample in the same camera. In experiments, MCNL significantly boosts ReID accuracy in the SCT setting, which paves the way of fast deployment of ReID systems with good performance on new target scenes.
Data Augmentation Revisited: Rethinking the Distribution Gap between Clean and Augmented Data
Sep 19, 2019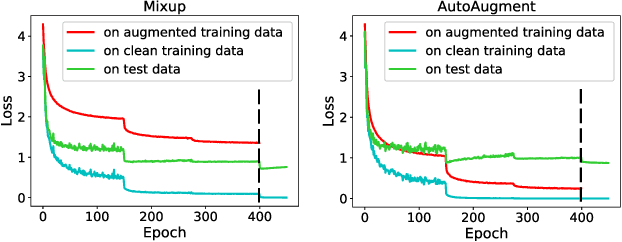
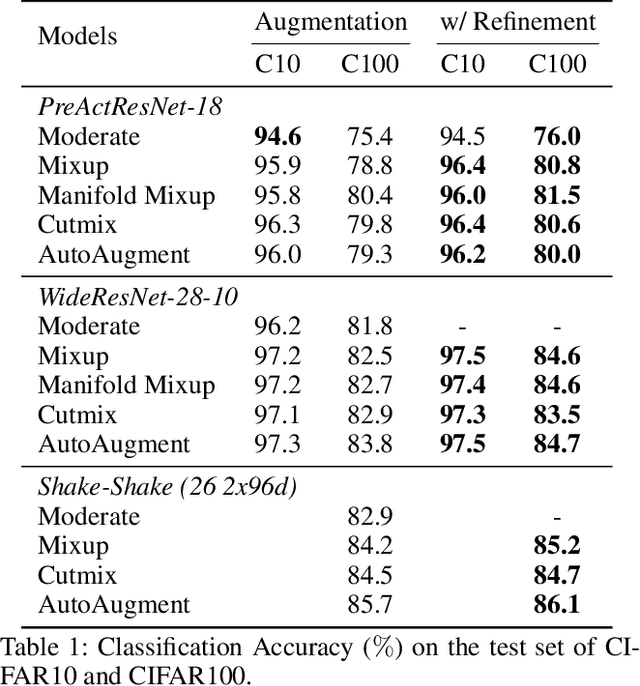
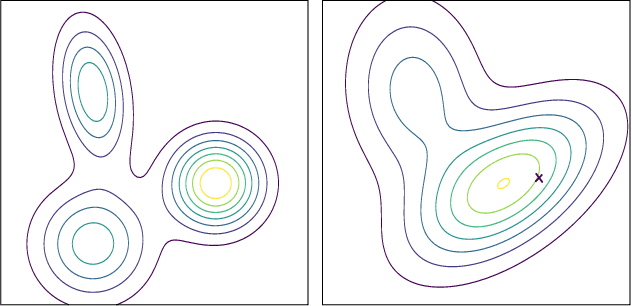
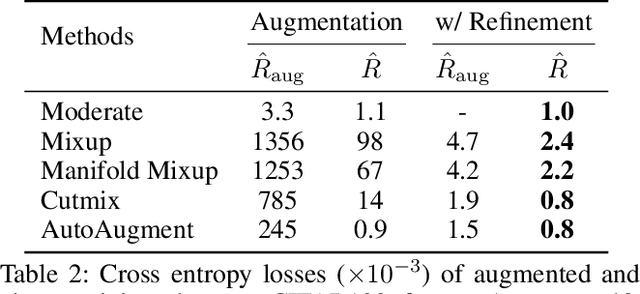
Data augmentation has been widely applied as an effective methodology to prevent over-fitting in particular when training very deep neural networks. The essential benefit comes from introducing additional priors in visual invariance, and thus generate images in different appearances but containing the same semantics. Recently, researchers proposed a few powerful data augmentation techniques which indeed improved accuracy, yet we notice that these methods have also caused a considerable gap between clean and augmented data. This paper revisits this problem from an analytical perspective, for which we estimate the upper-bound of testing loss using two terms, named empirical risk and generalization error, respectively. Data augmentation significantly reduces the generalization error, but meanwhile leads to a larger empirical risk, which can be alleviated by a simple algorithm, i.e. using less-augmented data to refine the model trained on fully-augmented data. We validate our approach on a few popular image classification datasets including CIFAR and ImageNet, and demonstrate consistent accuracy gain. We also conjecture that this simple strategy implies a generalized approach to circumvent local minima, which is of value to future research on model optimization.