 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Generation of Product-Image Sequence in E-commerce
Jun 26, 2022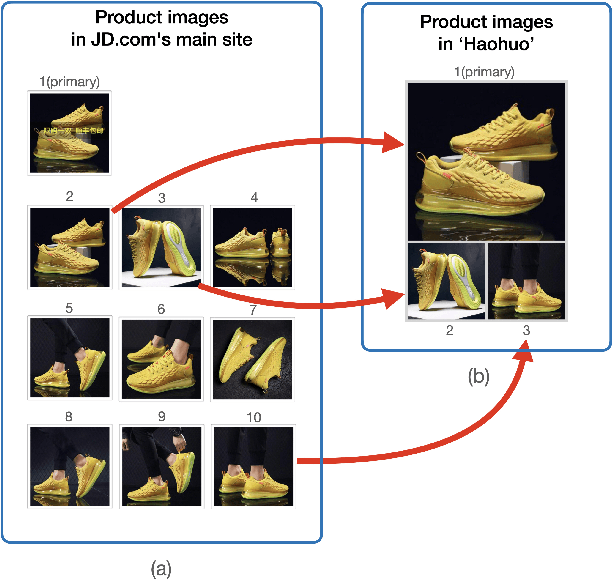

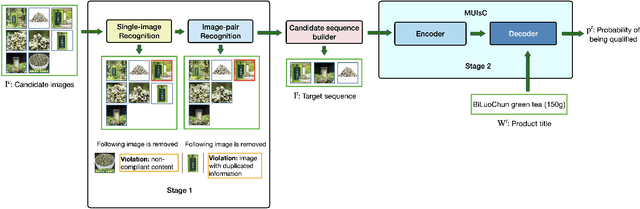
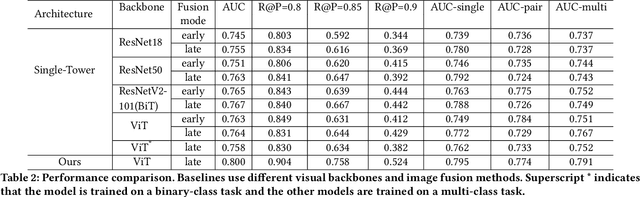
Product images are essential for providing desirable user experience in an e-commerce platform. For a platform with billions of products, it is extremely time-costly and labor-expensive to manually pick and organize qualified images. Furthermore, there are the numerous and complicated image rules that a product image needs to comply in order to be generated/selected. To address these challenges, in this paper, we present a new learning framework in order to achieve Automatic Generation of Product-Image Sequence (AGPIS) in e-commerce. To this end, we propose a Multi-modality Unified Image-sequence Classifier (MUIsC), which is able to simultaneously detect all categories of rule violations through learning. MUIsC leverages textual review feedback as the additional training target and utilizes product textual description to provide extra semantic information. Based on offline evaluations, we show that the proposed MUIsC significantly outperforms various baselines. Besides MUIsC, we also integrate some other important modules in the proposed framework, such as primary image selection, noncompliant content detection, and image deduplication. With all these modules, our framework works effectively and efficiently in JD.com recommendation platform. By Dec 2021, our AGPIS framework has generated high-standard images for about 1.5 million products and achieves 13.6% in reject rate.
Input-agnostic Certified Group Fairness via Gaussian Parameter Smoothing
Jun 22, 2022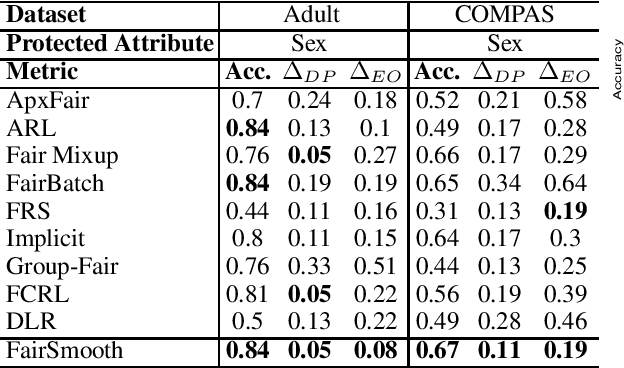
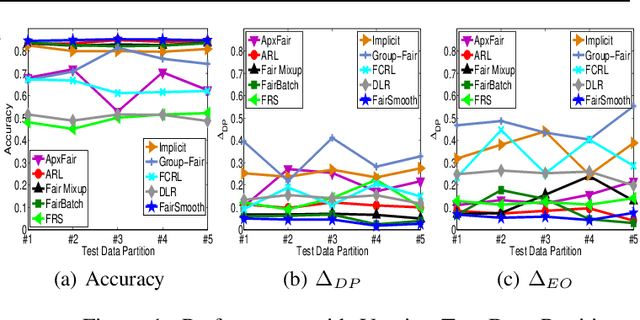
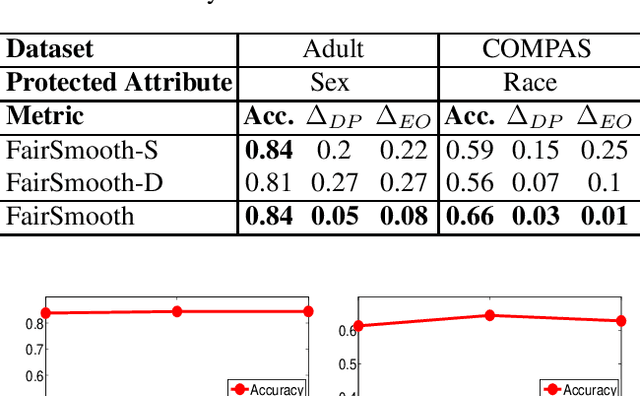
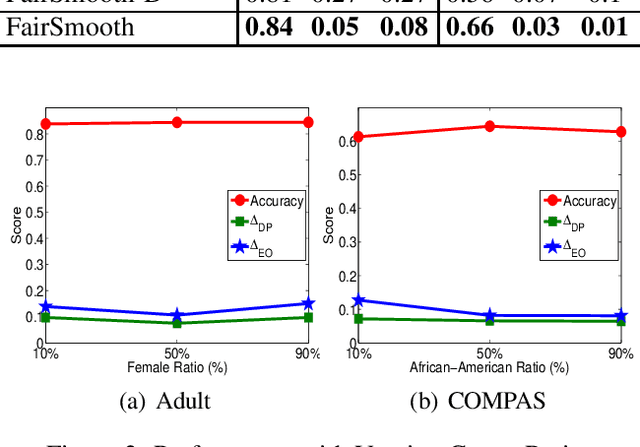
Only recently, researchers attempt to provide classification algorithms with provable group fairness guarantees. Most of these algorithms suffer from harassment caused by the requirement that the training and deployment data follow the same distribution. This paper proposes an input-agnostic certified group fairness algorithm, FairSmooth, for improving the fairness of classification models while maintaining the remarkable prediction accuracy. A Gaussian parameter smoothing method is developed to transform base classifiers into their smooth versions. An optimal individual smooth classifier is learnt for each group with only the data regarding the group and an overall smooth classifier for all groups is generated by averaging the parameters of all the individual smooth ones. By leveraging the theory of nonlinear functional analysis, the smooth classifiers are reformulated as output functions of a Nemytskii operator. Theoretical analysis is conducted to derive that the Nemytskii operator is smooth and induces a Frechet differentiable smooth manifold. We theoretically demonstrate that the smooth manifold has a global Lipschitz constant that is independent of the domain of the input data, which derives the input-agnostic certified group fairness.
Automatic Controllable Product Copywriting for E-Commerce
Jun 21, 2022
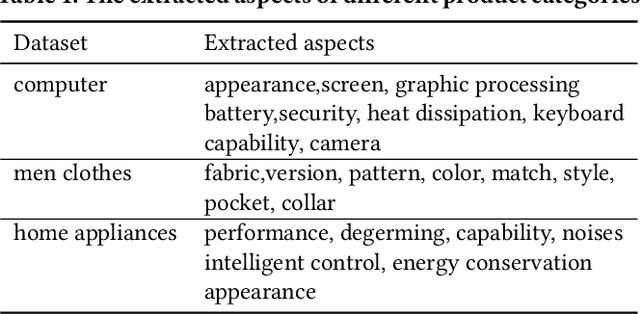
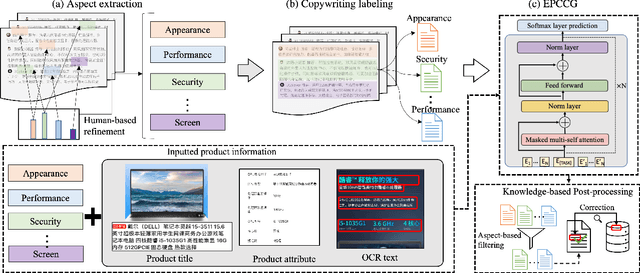
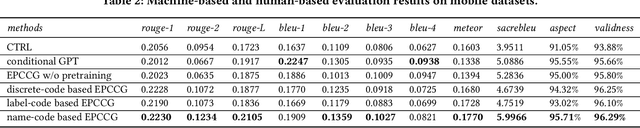
Automatic product description generation for e-commerce has witnessed significant advancement in the past decade. Product copywriting aims to attract users' interest and improve user experience by highlighting product characteristics with textual descriptions. As the services provided by e-commerce platforms become diverse, it is necessary to adapt the patterns of automatically-generated descriptions dynamically. In this paper, we report our experience in deploying an E-commerce Prefix-based Controllable Copywriting Generation (EPCCG) system into the JD.com e-commerce product recommendation platform. The development of the system contains two main components: 1) copywriting aspect extraction; 2) weakly supervised aspect labeling; 3) text generation with a prefix-based language model; 4) copywriting quality control. We conduct experiments to validate the effectiveness of the proposed EPCCG. In addition, we introduce the deployed architecture which cooperates with the EPCCG into the real-time JD.com e-commerce recommendation platform and the significant payoff since deployment.
TeKo: Text-Rich Graph Neural Networks with External Knowledge
Jun 15, 2022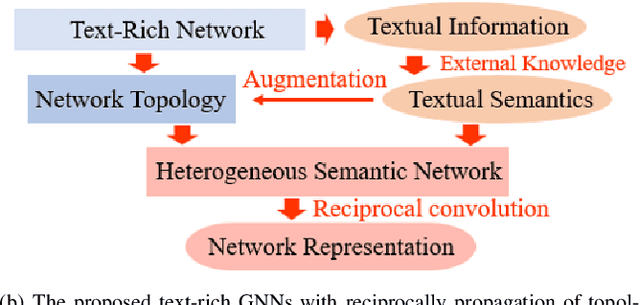
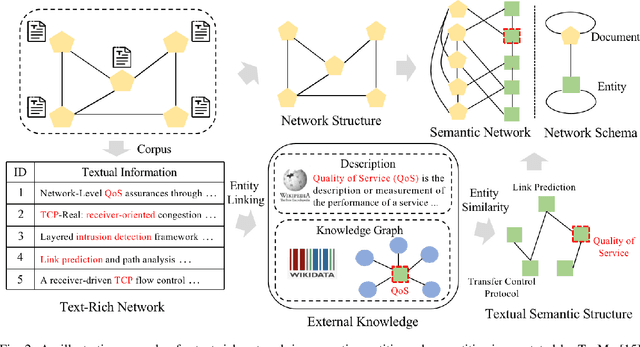
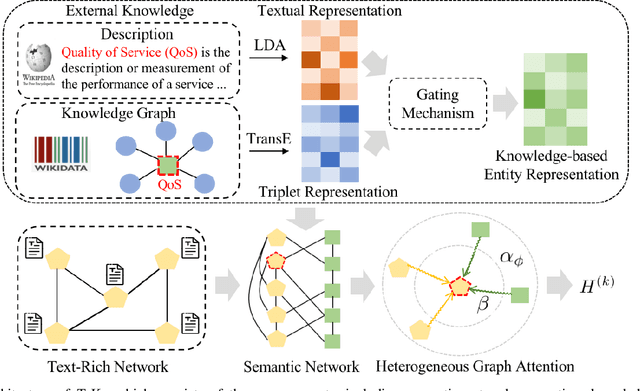

Graph Neural Networks (GNNs) have gained great popularity in tackling various analytical tasks on graph-structured data (i.e., networks). Typical GNNs and their variants follow a message-passing manner that obtains network representations by the feature propagation process along network topology, which however ignore the rich textual semantics (e.g., local word-sequence) that exist in many real-world networks. Existing methods for text-rich networks integrate textual semantics by mainly utilizing internal information such as topics or phrases/words, which often suffer from an inability to comprehensively mine the text semantics, limiting the reciprocal guidance between network structure and text semantics. To address these problems, we propose a novel text-rich graph neural network with external knowledge (TeKo), in order to take full advantage of both structural and textual information within text-rich networks. Specifically, we first present a flexible heterogeneous semantic network that incorporates high-quality entities and interactions among documents and entities. We then introduce two types of external knowledge, that is, structured triplets and unstructured entity description, to gain a deeper insight into textual semantics. We further design a reciprocal convolutional mechanism for the constructed heterogeneous semantic network, enabling network structure and textual semantics to collaboratively enhance each other and learn high-level network representations. Extensive experimental results on four public text-rich networks as well as a large-scale e-commerce searching dataset illustrate the superior performance of TeKo over state-of-the-art baselines.
Robust Meta-learning with Sampling Noise and Label Noise via Eigen-Reptile
Jun 04, 2022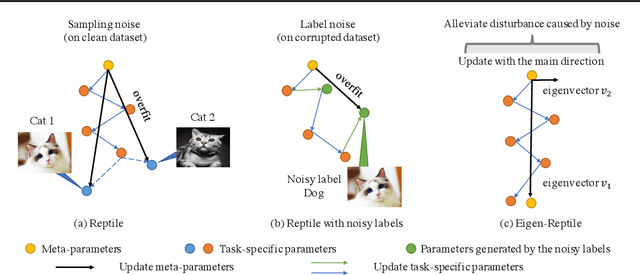
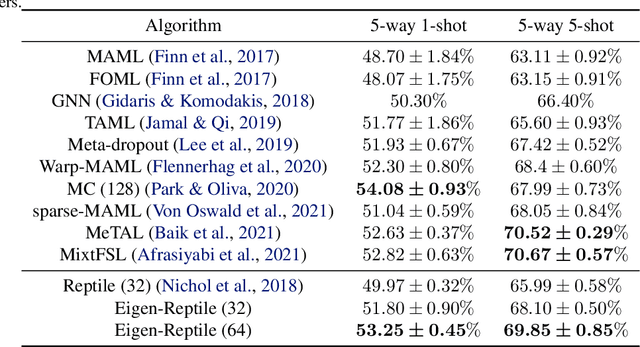
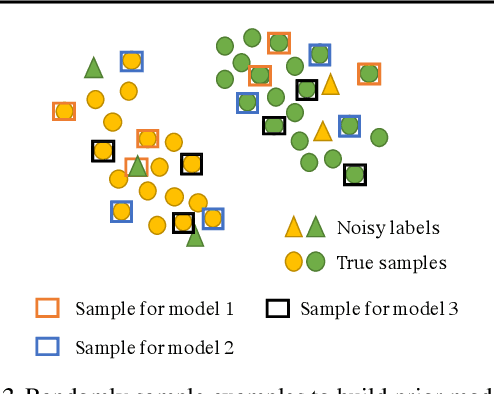
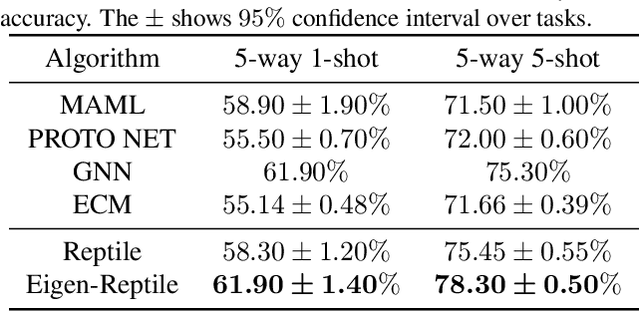
Recent years have seen a surge of interest in meta-learning techniques for tackling the few-shot learning (FSL) problem. However, the meta-learner is prone to overfitting since there are only a few available samples, which can be identified as sampling noise on a clean dataset. Moreover, when handling the data with noisy labels, the meta-learner could be extremely sensitive to label noise on a corrupted dataset. To address these two challenges, we present Eigen-Reptile (ER) that updates the meta-parameters with the main direction of historical task-specific parameters to alleviate sampling and label noise. Specifically, the main direction is computed in a fast way, where the scale of the calculated matrix is related to the number of gradient steps instead of the number of parameters. Furthermore, to obtain a more accurate main direction for Eigen-Reptile in the presence of many noisy labels, we further propose Introspective Self-paced Learning (ISPL). We have theoretically and experimentally demonstrated the soundness and effectiveness of the proposed Eigen-Reptile and ISPL. Particularly, our experiments on different tasks show that the proposed method is able to outperform or achieve highly competitive performance compared with other gradient-based methods with or without noisy labels. The code and data for the proposed method are provided for research purposes https://github.com/Anfeather/Eigen-Reptile.
TrustGNN: Graph Neural Network based Trust Evaluation via Learnable Propagative and Composable Nature
May 25, 2022
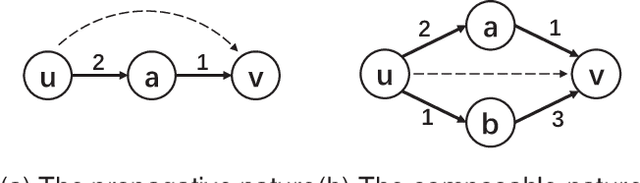
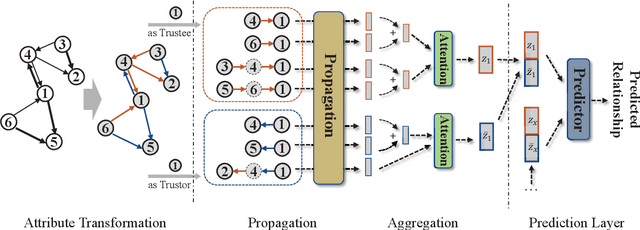
Trust evaluation is critical for many applications such as cyber security, social communication and recommender systems. Users and trust relationships among them can be seen as a graph. Graph neural networks (GNNs) show their powerful ability for analyzing graph-structural data. Very recently, existing work attempted to introduce the attributes and asymmetry of edges into GNNs for trust evaluation, while failed to capture some essential properties (e.g., the propagative and composable nature) of trust graphs. In this work, we propose a new GNN based trust evaluation method named TrustGNN, which integrates smartly the propagative and composable nature of trust graphs into a GNN framework for better trust evaluation. Specifically, TrustGNN designs specific propagative patterns for different propagative processes of trust, and distinguishes the contribution of different propagative processes to create new trust. Thus, TrustGNN can learn comprehensive node embeddings and predict trust relationships based on these embeddings. Experiments on some widely-used real-world datasets indicate that TrustGNN significantly outperforms the state-of-the-art methods. We further perform analytical experiments to demonstrate the effectiveness of the key designs in TrustGNN.
Meta Policy Learning for Cold-Start Conversational Recommendation
May 24, 2022
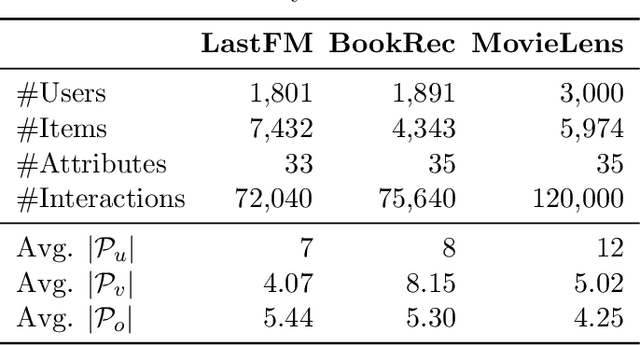
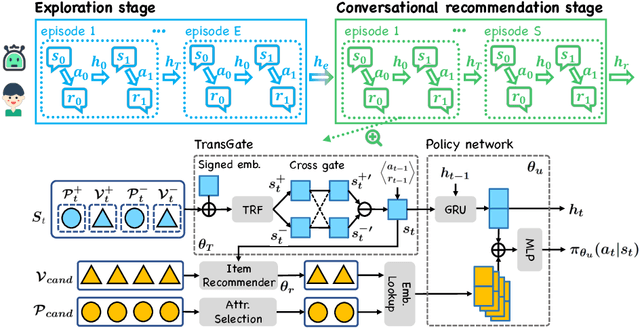
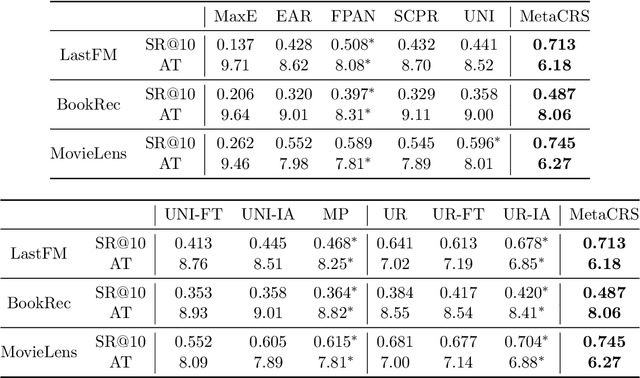
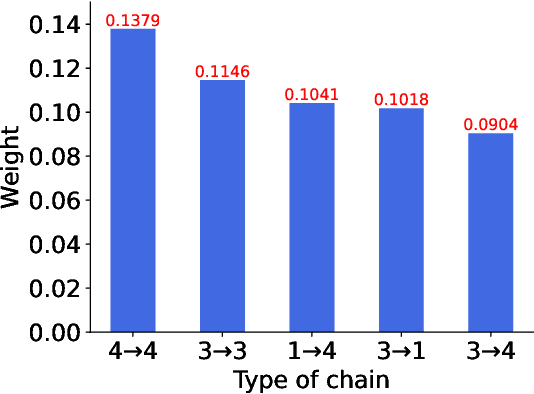
Conversational recommender systems (CRS) explicitly solicit users' preferences for improved recommendations on the fly. Most existing CRS solutions employ reinforcement learning methods to train a single policy for a population of users. However, for users new to the system, such a global policy becomes ineffective to produce conversational recommendations, i.e., the cold-start challenge. In this paper, we study CRS policy learning for cold-start users via meta reinforcement learning. We propose to learn a meta policy and adapt it to new users with only a few trials of conversational recommendations. To facilitate policy adaptation, we design three synergetic components. First is a meta-exploration policy dedicated to identify user preferences via exploratory conversations. Second is a Transformer-based state encoder to model a user's both positive and negative feedback during the conversation. And third is an adaptive item recommender based on the embedded states. Extensive experiments on three datasets demonstrate the advantage of our solution in serving new users, compared with a rich set of state-of-the-art CRS solutions.
Scenario-based Multi-product Advertising Copywriting Generation for E-Commerce
May 21, 2022

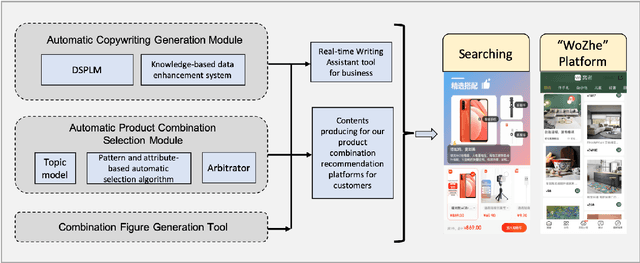
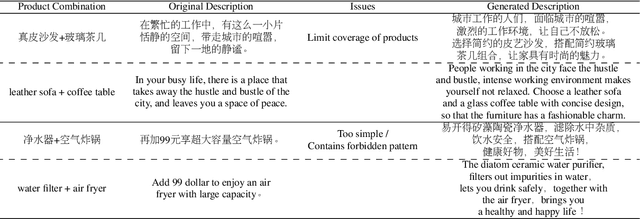
In this paper, we proposed an automatic Scenario-based Multi-product Advertising Copywriting Generation system (SMPACG) for E-Commerce, which has been deployed on a leading Chinese e-commerce platform. The proposed SMPACG consists of two main components: 1) an automatic multi-product combination selection module, which itself is consisted of a topic prediction model, a pattern and attribute-based selection model and an arbitrator model; and 2) an automatic multi-product advertising copywriting generation module, which combines our proposed domain-specific pretrained language model and knowledge-based data enhancement model. The SMPACG is the first system that realizes automatic scenario-based multi-product advertising contents generation, which achieves significant improvements over other state-of-the-art methods. The SMPACG has been not only developed for directly serving for our e-commerce recommendation system, but also used as a real-time writing assistant tool for merchants.
Improving Long Tailed Document-Level Relation Extraction via Easy Relation Augmentation and Contrastive Learning
May 21, 2022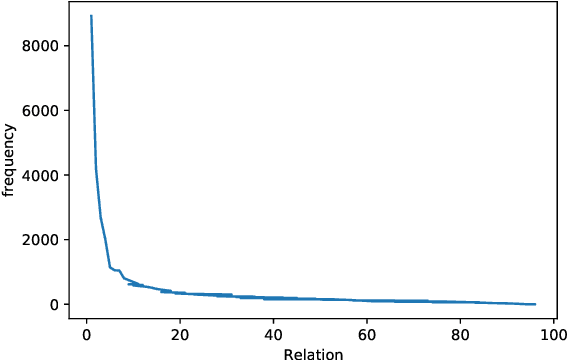
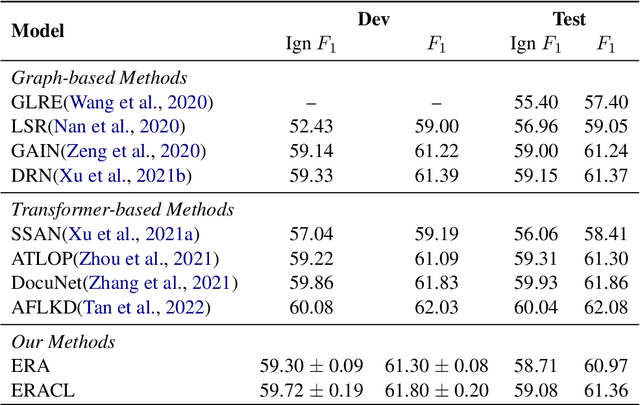
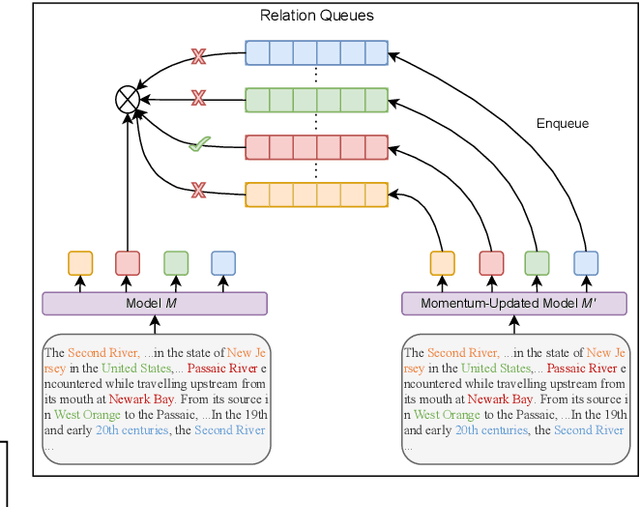
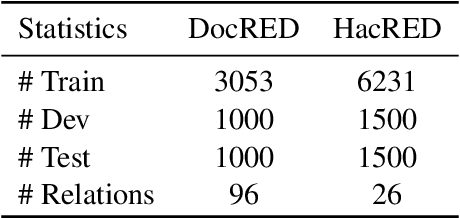
Towards real-world information extraction scenario, research of relation extraction is advancing to document-level relation extraction(DocRE). Existing approaches for DocRE aim to extract relation by encoding various information sources in the long context by novel model architectures. However, the inherent long-tailed distribution problem of DocRE is overlooked by prior work. We argue that mitigating the long-tailed distribution problem is crucial for DocRE in the real-world scenario. Motivated by the long-tailed distribution problem, we propose an Easy Relation Augmentation(ERA) method for improving DocRE by enhancing the performance of tailed relations. In addition, we further propose a novel contrastive learning framework based on our ERA, i.e., ERACL, which can further improve the model performance on tailed relations and achieve competitive overall DocRE performance compared to the state-of-arts.
Heterogeneous Graph Neural Networks using Self-supervised Reciprocally Contrastive Learning
Apr 30, 2022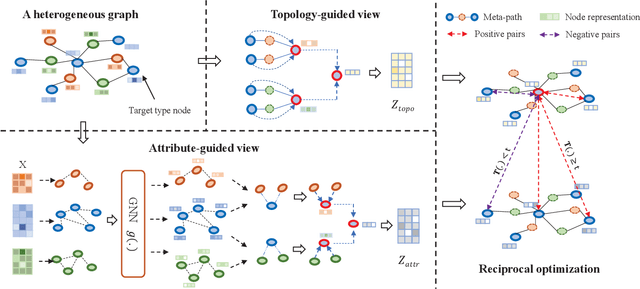
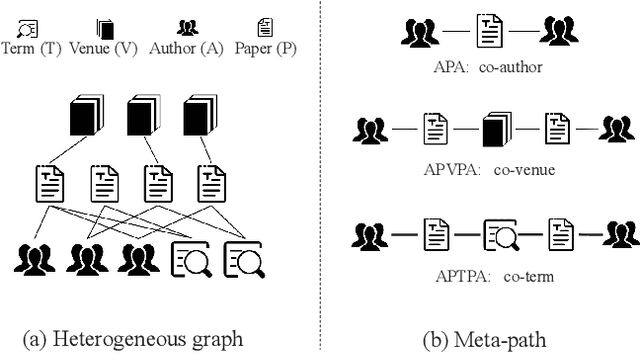
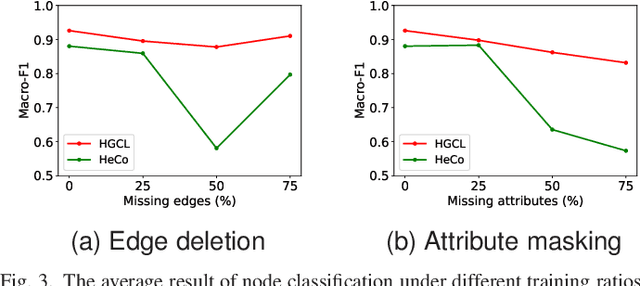
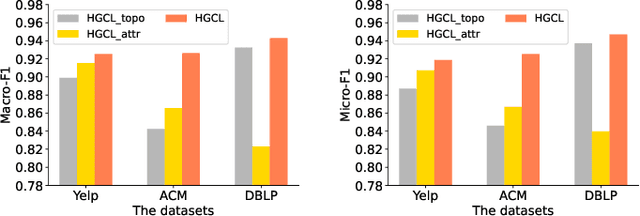
Heterogeneous graph neural network (HGNN) is a very popular technique for the modeling and analysis of heterogeneous graphs. Most existing HGNN-based approaches are supervised or semi-supervised learning methods requiring graphs to be annotated, which is costly and time-consuming. Self-supervised contrastive learning has been proposed to address the problem of requiring annotated data by mining intrinsic information hidden within the given data. However, the existing contrastive learning methods are inadequate for heterogeneous graphs because they construct contrastive views only based on data perturbation or pre-defined structural properties (e.g., meta-path) in graph data while ignore the noises that may exist in both node attributes and graph topologies. We develop for the first time a novel and robust heterogeneous graph contrastive learning approach, namely HGCL, which introduces two views on respective guidance of node attributes and graph topologies and integrates and enhances them by reciprocally contrastive mechanism to better model heterogeneous graphs. In this new approach, we adopt distinct but most suitable attribute and topology fusion mechanisms in the two views, which are conducive to mining relevant information in attributes and topologies separately. We further use both attribute similarity and topological correlation to construct high-quality contrastive samples. Extensive experiments on three large real-world heterogeneous graphs demonstrate the superiority and robustness of HGCL over state-of-the-art methods.