 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Adaptive Activity Recognition Across Video Domains
Mar 29, 2022



This paper strives for activity recognition under domain shift, for example caused by change of scenery or camera viewpoint. The leading approaches reduce the shift in activity appearance by adversarial training and self-supervised learning. Different from these vision-focused works we leverage activity sounds for domain adaptation as they have less variance across domains and can reliably indicate which activities are not happening. We propose an audio-adaptive encoder and associated learning methods that discriminatively adjust the visual feature representation as well as addressing shifts in the semantic distribution. To further eliminate domain-specific features and include domain-invariant activity sounds for recognition, an audio-infused recognizer is proposed, which effectively models the cross-modal interaction across domains. We also introduce the new task of actor shift, with a corresponding audio-visual dataset, to challenge our method with situations where the activity appearance changes dramatically. Experiments on this dataset, EPIC-Kitchens and CharadesEgo show the effectiveness of our approach.
RGBD Object Tracking: An In-depth Review
Mar 26, 2022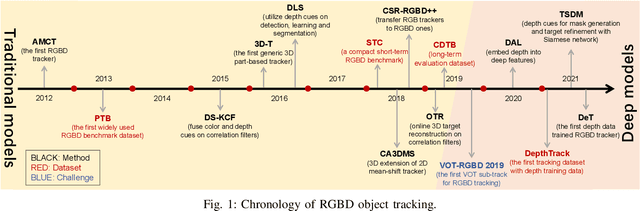
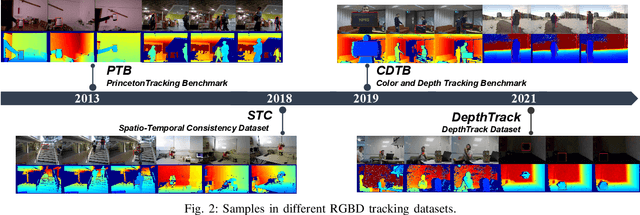
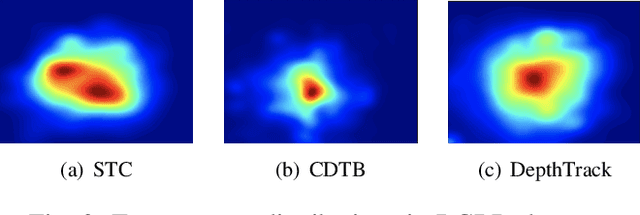
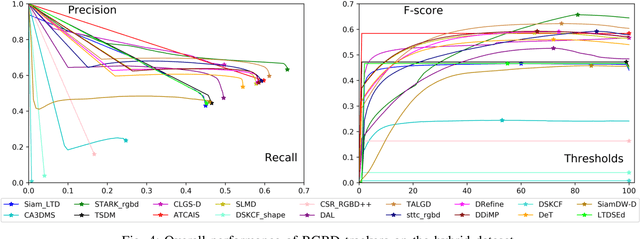
RGBD object tracking is gaining momentum in computer vision research thanks to the development of depth sensors. Although numerous RGBD trackers have been proposed with promising performance, an in-depth review for comprehensive understanding of this area is lacking. In this paper, we firstly review RGBD object trackers from different perspectives, including RGBD fusion, depth usage, and tracking framework. Then, we summarize the existing datasets and the evaluation metrics. We benchmark a representative set of RGBD trackers, and give detailed analyses based on their performances. Particularly, we are the first to provide depth quality evaluation and analysis of tracking results in depth-friendly scenarios in RGBD tracking. For long-term settings in most RGBD tracking videos, we give an analysis of trackers' performance on handling target disappearance. To enable better understanding of RGBD trackers, we propose robustness evaluation against input perturbations. Finally, we summarize the challenges and provide open directions for this community. All resources are publicly available at https://github.com/memoryunreal/RGBD-tracking-review.
High-resolution Iterative Feedback Network for Camouflaged Object Detection
Mar 22, 2022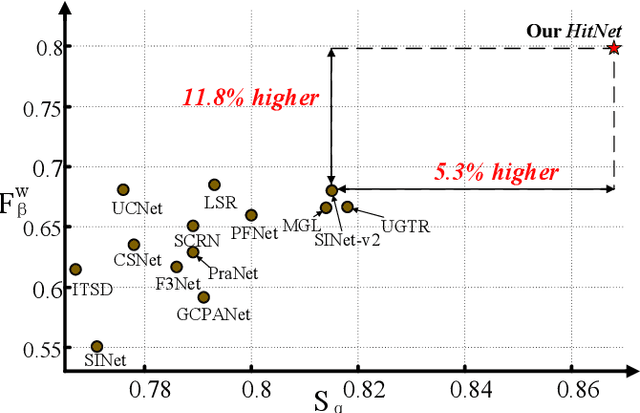



Spotting camouflaged objects that are visually assimilated into the background is tricky for both object detection algorithms and humans who are usually confused or cheated by the perfectly intrinsic similarities between the foreground objects and the background surroundings. To tackle this challenge, we aim to extract the high-resolution texture details to avoid the detail degradation that causes blurred vision in edges and boundaries. We introduce a novel HitNet to refine the low-resolution representations by high-resolution features in an iterative feedback manner, essentially a global loop-based connection among the multi-scale resolutions. In addition, an iterative feedback loss is proposed to impose more constraints on each feedback connection. Extensive experiments on four challenging datasets demonstrate that our \ourmodel~breaks the performance bottleneck and achieves significant improvements compared with 29 state-of-the-art methods. To address the data scarcity in camouflaged scenarios, we provide an application example by employing cross-domain learning to extract the features that can reflect the camouflaged object properties and embed the features into salient objects, thereby generating more camouflaged training samples from the diverse salient object datasets The code will be available at https://github.com/HUuxiaobin/HitNet.
Highly Accurate Dichotomous Image Segmentation
Mar 08, 2022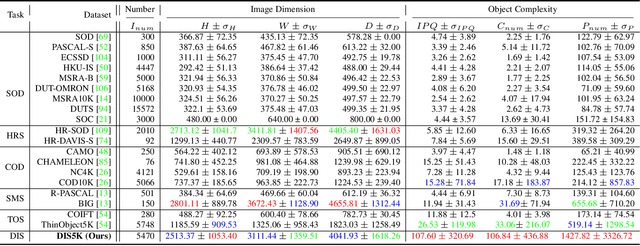
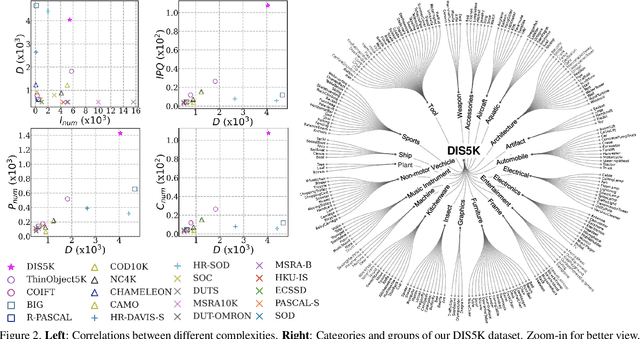
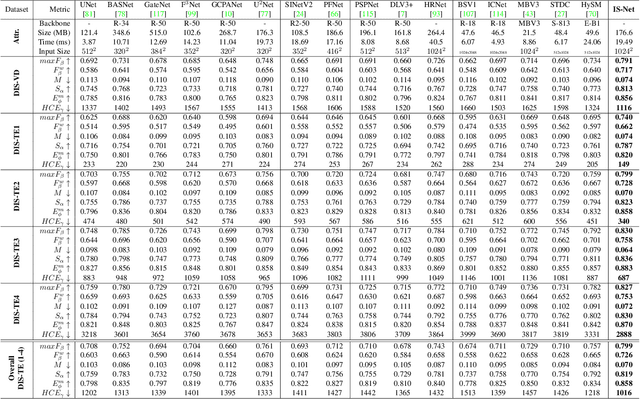

We present a systematic study on a new task called dichotomous image segmentation (DIS), which aims to segment highly accurate objects from natural images. To this end, we collected the first large-scale dataset, called DIS5K, which contains 5,470 high-resolution (e.g., 2K, 4K or larger) images covering camouflaged, salient, or meticulous objects in various backgrounds. All images are annotated with extremely fine-grained labels. In addition, we introduce a simple intermediate supervision baseline (IS-Net) using both feature-level and mask-level guidance for DIS model training. Without tricks, IS-Net outperforms various cutting-edge baselines on the proposed DIS5K, making it a general self-learned supervision network that can help facilitate future research in DIS. Further, we design a new metric called human correction efforts (HCE) which approximates the number of mouse clicking operations required to correct the false positives and false negatives. HCE is utilized to measure the gap between models and real-world applications and thus can complement existing metrics. Finally, we conduct the largest-scale benchmark, evaluating 16 representative segmentation models, providing a more insightful discussion regarding object complexities, and showing several potential applications (e.g., background removal, art design, 3D reconstruction). Hoping these efforts can open up promising directions for both academic and industries. We will release our DIS5K dataset, IS-Net baseline, HCE metric, and the complete benchmark results.
Local and Global GANs with Semantic-Aware Upsampling for Image Generation
Feb 28, 2022
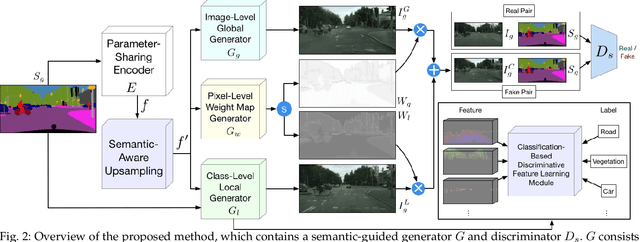
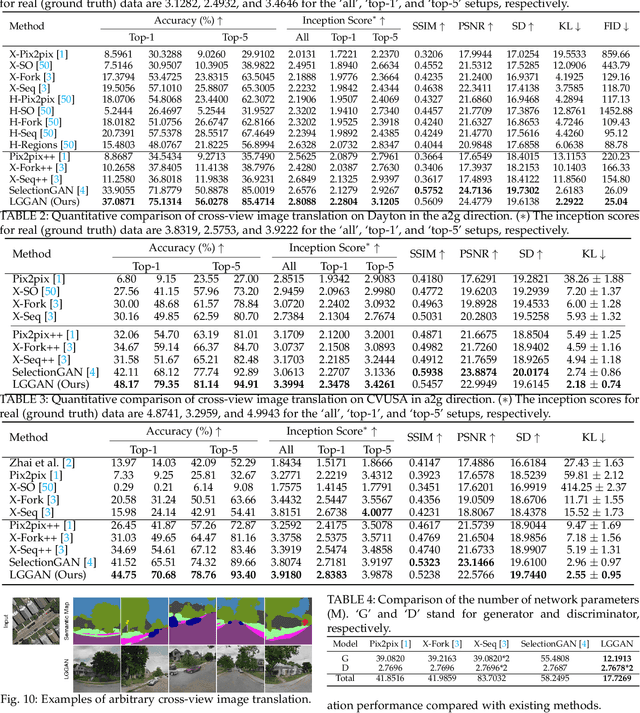
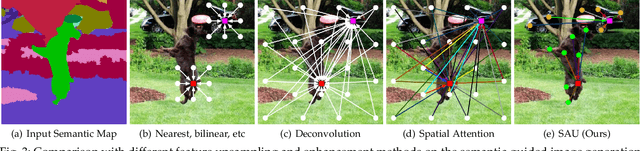
In this paper, we address the task of semantic-guided image generation. One challenge common to most existing image-level generation methods is the difficulty in generating small objects and detailed local textures. To address this, in this work we consider generating images using local context. As such, we design a local class-specific generative network using semantic maps as guidance, which separately constructs and learns subgenerators for different classes, enabling it to capture finer details. To learn more discriminative class-specific feature representations for the local generation, we also propose a novel classification module. To combine the advantages of both global image-level and local class-specific generation, a joint generation network is designed with an attention fusion module and a dual-discriminator structure embedded. Lastly, we propose a novel semantic-aware upsampling method, which has a larger receptive field and can take far-away pixels that are semantically related for feature upsampling, enabling it to better preserve semantic consistency for instances with the same semantic labels. Extensive experiments on two image generation tasks show the superior performance of the proposed method. State-of-the-art results are established by large margins on both tasks and on nine challenging public benchmarks. The source code and trained models are available at https://github.com/Ha0Tang/LGGAN.
Learning to Generalize across Domains on Single Test Samples
Feb 16, 2022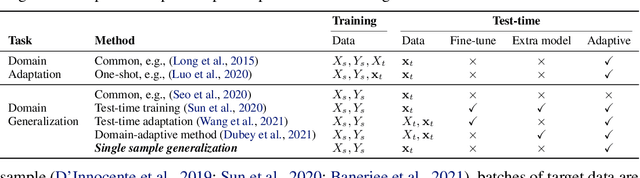
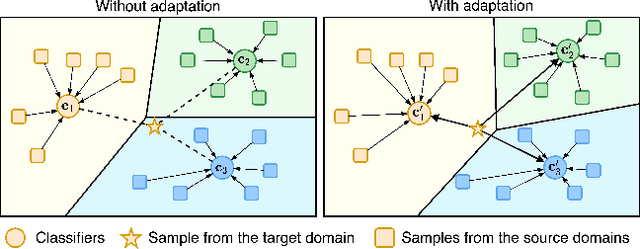
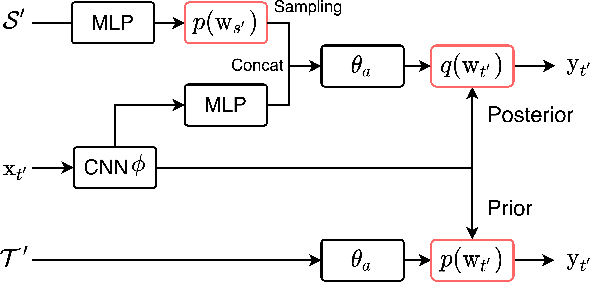
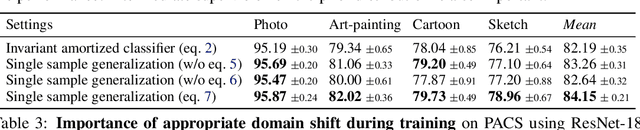
We strive to learn a model from a set of source domains that generalizes well to unseen target domains. The main challenge in such a domain generalization scenario is the unavailability of any target domain data during training, resulting in the learned model not being explicitly adapted to the unseen target domains. We propose learning to generalize across domains on single test samples. We leverage a meta-learning paradigm to learn our model to acquire the ability of adaptation with single samples at training time so as to further adapt itself to each single test sample at test time. We formulate the adaptation to the single test sample as a variational Bayesian inference problem, which incorporates the test sample as a conditional into the generation of model parameters. The adaptation to each test sample requires only one feed-forward computation at test time without any fine-tuning or self-supervised training on additional data from the unseen domains. Extensive ablation studies demonstrate that our model learns the ability to adapt models to each single sample by mimicking domain shifts during training. Further, our model achieves at least comparable -- and often better -- performance than state-of-the-art methods on multiple benchmarks for domain generalization.
Pruning Networks with Cross-Layer Ranking & k-Reciprocal Nearest Filters
Feb 15, 2022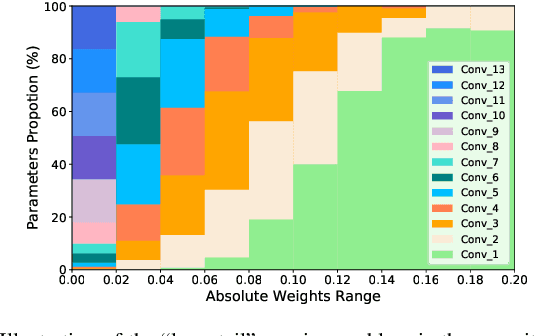
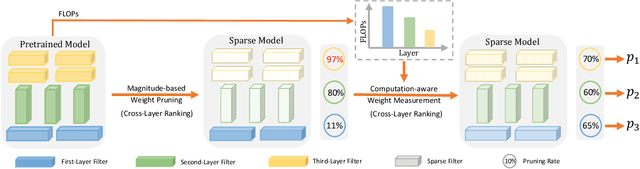
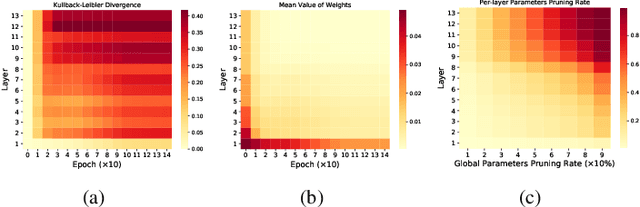
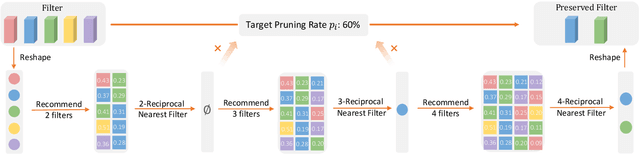
This paper focuses on filter-level network pruning. A novel pruning method, termed CLR-RNF, is proposed. We first reveal a "long-tail" long-tail pruning problem in magnitude-based weight pruning methods, and then propose a computation-aware measurement for individual weight importance, followed by a Cross-Layer Ranking (CLR) of weights to identify and remove the bottom-ranked weights. Consequently, the per-layer sparsity makes up of the pruned network structure in our filter pruning. Then, we introduce a recommendation-based filter selection scheme where each filter recommends a group of its closest filters. To pick the preserved filters from these recommended groups, we further devise a k-Reciprocal Nearest Filter (RNF) selection scheme where the selected filters fall into the intersection of these recommended groups. Both our pruned network structure and the filter selection are non-learning processes, which thus significantly reduce the pruning complexity, and differentiate our method from existing works. We conduct image classification on CIFAR-10 and ImageNet to demonstrate the superiority of our CLR-RNF over the state-of-the-arts. For example, on CIFAR-10, CLR-RNF removes 74.1% FLOPs and 95.0% parameters from VGGNet-16 with even 0.3\% accuracy improvements. On ImageNet, it removes 70.2% FLOPs and 64.8% parameters from ResNet-50 with only 1.7% top-5 accuracy drops. Our project is at https://github.com/lmbxmu/CLR-RNF.
Consistency and Diversity induced Human Motion Segmentation
Feb 10, 2022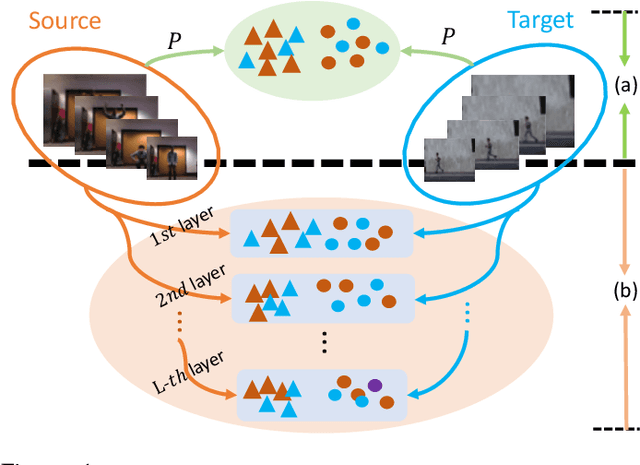

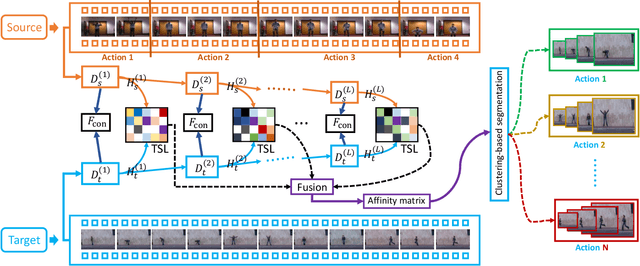
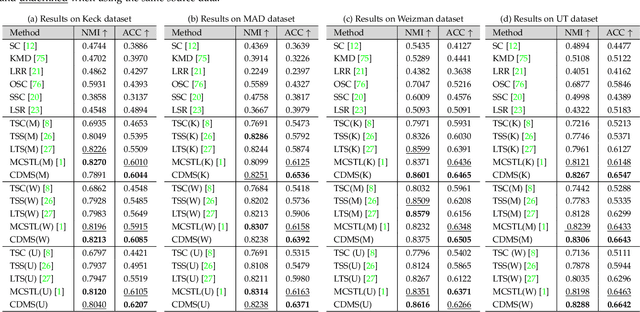
Subspace clustering is a classical technique that has been widely used for human motion segmentation and other related tasks. However, existing segmentation methods often cluster data without guidance from prior knowledge, resulting in unsatisfactory segmentation results. To this end, we propose a novel Consistency and Diversity induced human Motion Segmentation (CDMS) algorithm. Specifically, our model factorizes the source and target data into distinct multi-layer feature spaces, in which transfer subspace learning is conducted on different layers to capture multi-level information. A multi-mutual consistency learning strategy is carried out to reduce the domain gap between the source and target data. In this way, the domain-specific knowledge and domain-invariant properties can be explored simultaneously. Besides, a novel constraint based on the Hilbert Schmidt Independence Criterion (HSIC) is introduced to ensure the diversity of multi-level subspace representations, which enables the complementarity of multi-level representations to be explored to boost the transfer learning performance. Moreover, to preserve the temporal correlations, an enhanced graph regularizer is imposed on the learned representation coefficients and the multi-level representations of the source data. The proposed model can be efficiently solved using the Alternating Direction Method of Multipliers (ADMM) algorithm. Extensive experimental results on public human motion datasets demonstrate the effectiveness of our method against several state-of-the-art approaches.
Pedestrian Detection: Domain Generalization, CNNs, Transformers and Beyond
Jan 10, 2022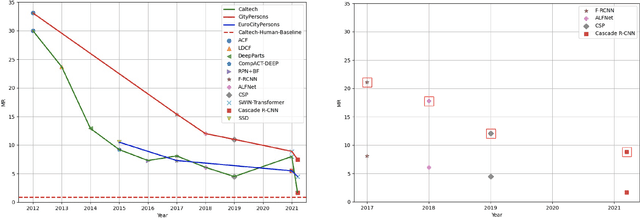
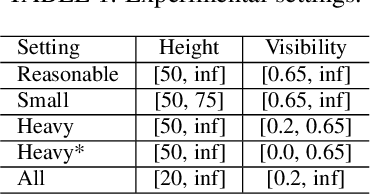


Pedestrian detection is the cornerstone of many vision based applications, starting from object tracking to video surveillance and more recently, autonomous driving. With the rapid development of deep learning in object detection, pedestrian detection has achieved very good performance in traditional single-dataset training and evaluation setting. However, in this study on generalizable pedestrian detectors, we show that, current pedestrian detectors poorly handle even small domain shifts in cross-dataset evaluation. We attribute the limited generalization to two main factors, the method and the current sources of data. Regarding the method, we illustrate that biasness present in the design choices (e.g anchor settings) of current pedestrian detectors are the main contributing factor to the limited generalization. Most modern pedestrian detectors are tailored towards target dataset, where they do achieve high performance in traditional single training and testing pipeline, but suffer a degrade in performance when evaluated through cross-dataset evaluation. Consequently, a general object detector performs better in cross-dataset evaluation compared with state of the art pedestrian detectors, due to its generic design. As for the data, we show that the autonomous driving benchmarks are monotonous in nature, that is, they are not diverse in scenarios and dense in pedestrians. Therefore, benchmarks curated by crawling the web (which contain diverse and dense scenarios), are an efficient source of pre-training for providing a more robust representation. Accordingly, we propose a progressive fine-tuning strategy which improves generalization. Code and models cab accessed at https://github.com/hasanirtiza/Pedestron.
GuidedMix-Net: Semi-supervised Semantic Segmentation by Using Labeled Images as Reference
Dec 28, 2021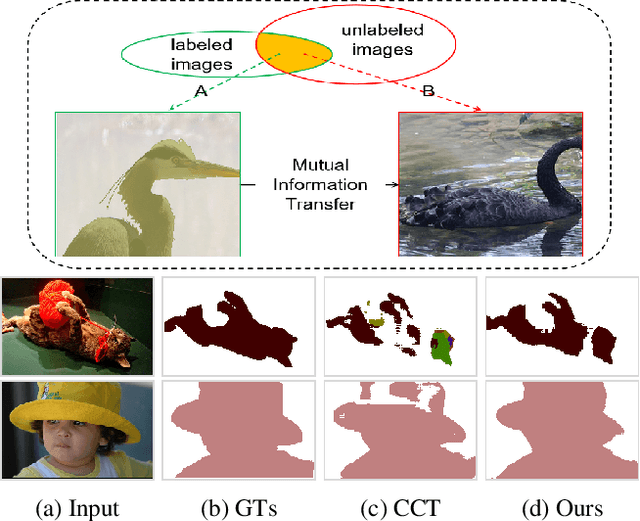
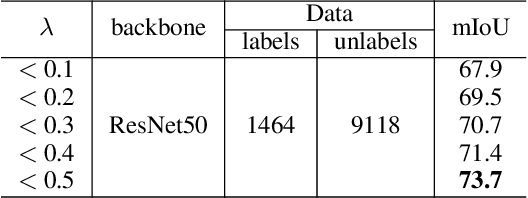
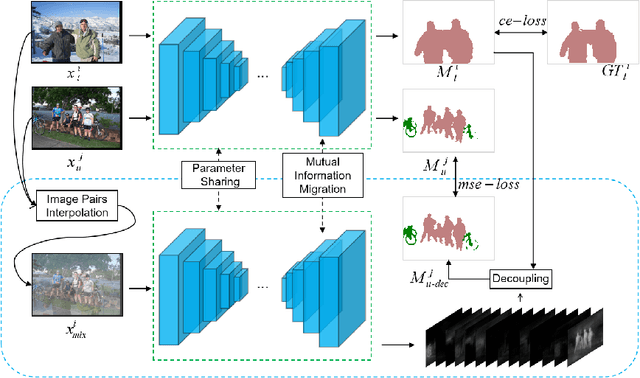
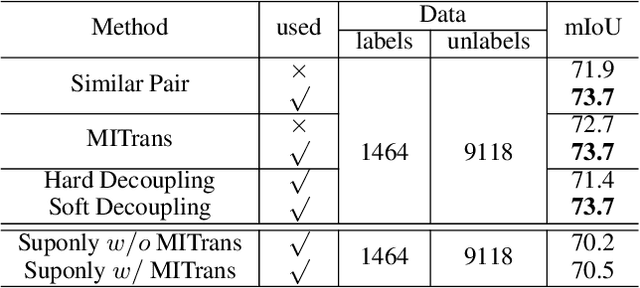
Semi-supervised learning is a challenging problem which aims to construct a model by learning from limited labeled examples. Numerous methods for this task focus on utilizing the predictions of unlabeled instances consistency alone to regularize networks. However, treating labeled and unlabeled data separately often leads to the discarding of mass prior knowledge learned from the labeled examples. %, and failure to mine the feature interaction between the labeled and unlabeled image pairs. In this paper, we propose a novel method for semi-supervised semantic segmentation named GuidedMix-Net, by leveraging labeled information to guide the learning of unlabeled instances. Specifically, GuidedMix-Net employs three operations: 1) interpolation of similar labeled-unlabeled image pairs; 2) transfer of mutual information; 3) generalization of pseudo masks. It enables segmentation models can learning the higher-quality pseudo masks of unlabeled data by transfer the knowledge from labeled samples to unlabeled data. Along with supervised learning for labeled data, the prediction of unlabeled data is jointly learned with the generated pseudo masks from the mixed data. Extensive experiments on PASCAL VOC 2012, and Cityscapes demonstrate the effectiveness of our GuidedMix-Net, which achieves competitive segmentation accuracy and significantly improves the mIoU by +7$\%$ compared to previous approaches.