 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Digital Camera Pipeline for Extreme Low-Light Imaging
Apr 11, 2019


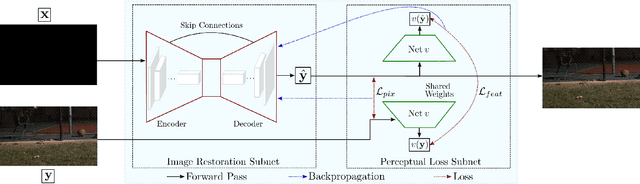
In low-light conditions, a conventional camera imaging pipeline produces sub-optimal images that are usually dark and noisy due to a low photon count and low signal-to-noise ratio (SNR). We present a data-driven approach that learns the desired properties of well-exposed images and reflects them in images that are captured in extremely low ambient light environments, thereby significantly improving the visual quality of these low-light images. We propose a new loss function that exploits the characteristics of both pixel-wise and perceptual metrics, enabling our deep neural network to learn the camera processing pipeline to transform the short-exposure, low-light RAW sensor data to well-exposed sRGB images. The results show that our method outperforms the state-of-the-art according to psychophysical tests as well as pixel-wise standard metrics and recent learning-based perceptual image quality measures.
Adversarial Defense by Restricting the Hidden Space of Deep Neural Networks
Apr 07, 2019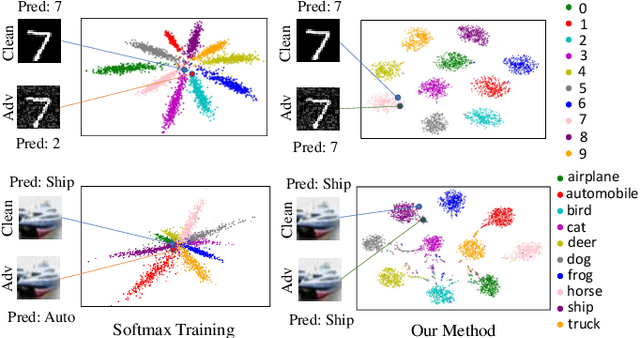
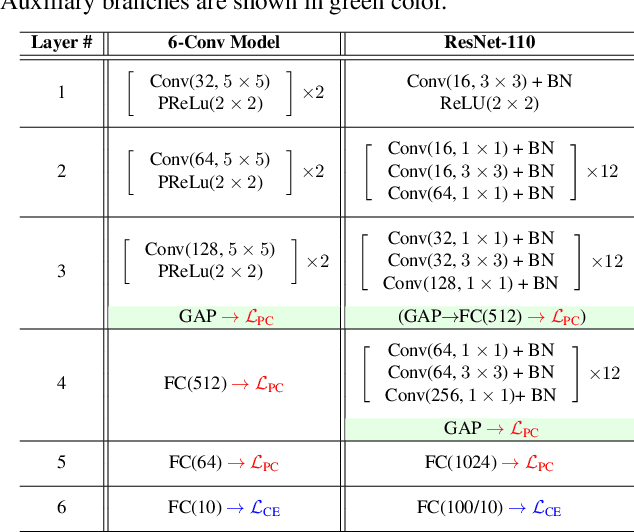
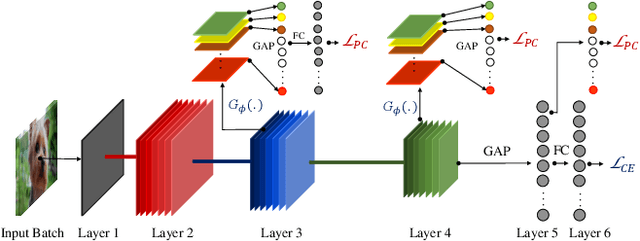
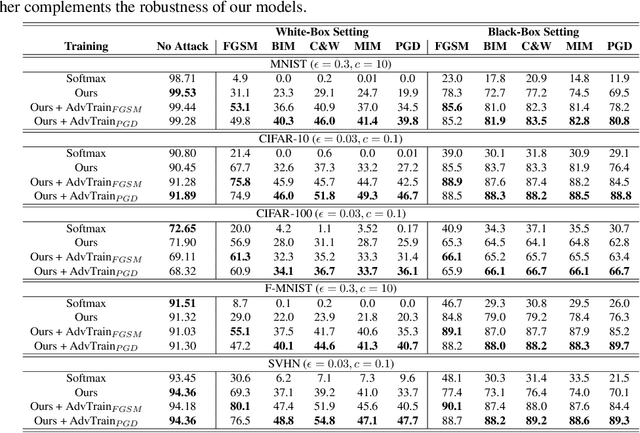
Deep neural networks are vulnerable to adversarial attacks, which can fool them by adding minuscule perturbations to the input images. The robustness of existing defenses suffers greatly under white-box attack settings, where an adversary has full knowledge about the network and can iterate several times to find strong perturbations. We observe that the main reason for the existence of such perturbations is the close proximity of different class samples in the learned feature space. This allows model decisions to be totally changed by adding an imperceptible perturbation in the inputs. To counter this, we propose to class-wise disentangle the intermediate feature representations of deep networks. Specifically, we force the features for each class to lie inside a convex polytope that is maximally separated from the polytopes of other classes. In this manner, the network is forced to learn distinct and distant decision regions for each class. We observe that this simple constraint on the features greatly enhances the robustness of learned models, even against the strongest white-box attacks, without degrading the classification performance on clean images. We report extensive evaluations in both black-box and white-box attack scenarios and show significant gains in comparison to state-of-the art defenses.
Iterative Normalization: Beyond Standardization towards Efficient Whitening
Apr 06, 2019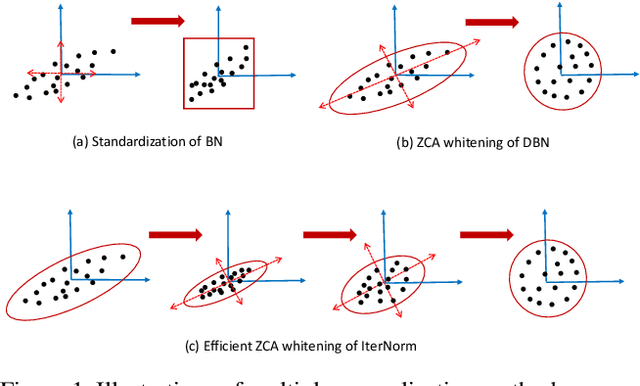
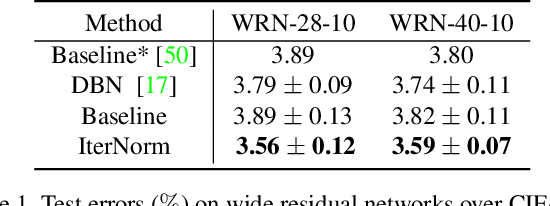
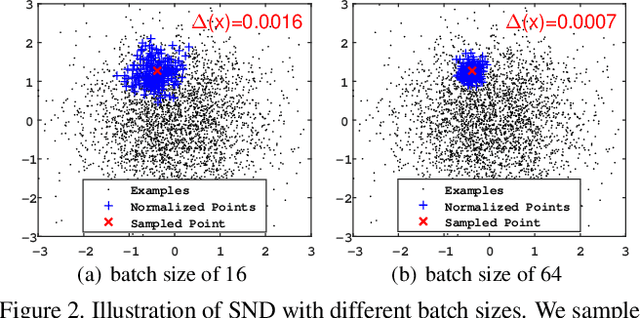
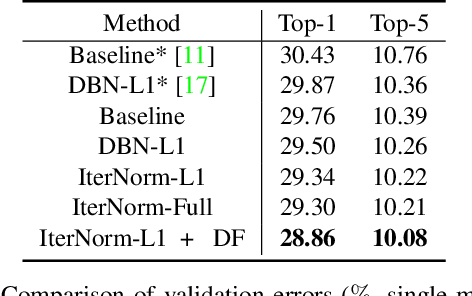
Batch Normalization (BN) is ubiquitously employed for accelerating neural network training and improving the generalization capability by performing standardization within mini-batches. Decorrelated Batch Normalization (DBN) further boosts the above effectiveness by whitening. However, DBN relies heavily on either a large batch size, or eigen-decomposition that suffers from poor efficiency on GPUs. We propose Iterative Normalization (IterNorm), which employs Newton's iterations for much more efficient whitening, while simultaneously avoiding the eigen-decomposition. Furthermore, we develop a comprehensive study to show IterNorm has better trade-off between optimization and generalization, with theoretical and experimental support. To this end, we exclusively introduce Stochastic Normalization Disturbance (SND), which measures the inherent stochastic uncertainty of samples when applied to normalization operations. With the support of SND, we provide natural explanations to several phenomena from the perspective of optimization, e.g., why group-wise whitening of DBN generally outperforms full-whitening and why the accuracy of BN degenerates with reduced batch sizes. We demonstrate the consistently improved performance of IterNorm with extensive experiments on CIFAR-10 and ImageNet over BN and DBN.
Few-Shot Deep Adversarial Learning for Video-based Person Re-identification
Mar 29, 2019
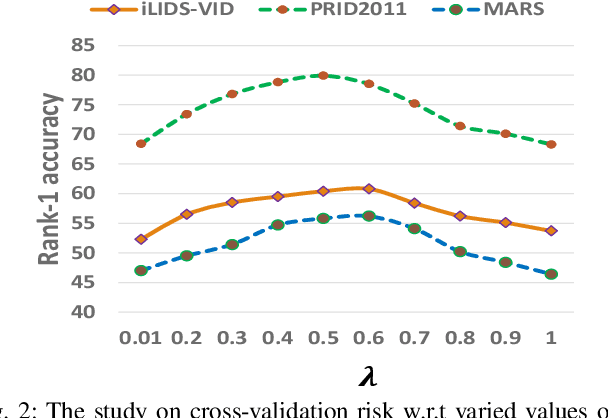
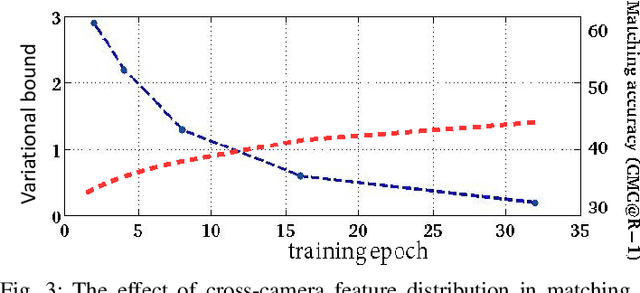
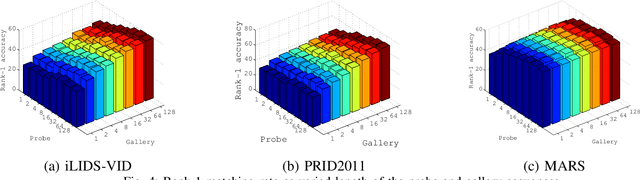
Video-based person re-identification (re-ID) refers to matching people across camera views from arbitrary unaligned video footages. Existing methods rely on supervision signals to optimise a projected space under which the distances between inter/intra-videos are maximised/minimised. However, this demands exhaustively labelling people across camera views, rendering them unable to be scaled in large networked cameras. Also, it is noticed that learning effective video representations with view invariance is not explicitly addressed for which features exhibit different distributions otherwise. Thus, matching videos for person re-ID demands flexible models to capture the dynamics in time-series observations and learn view-invariant representations with access to limited labeled training samples. In this paper, we propose a novel few-shot deep learning approach to video-based person re-ID, to learn comparable representations that are discriminative and view-invariant. The proposed method is developed on the variational recurrent neural networks (VRNNs) and trained adversarially to produce latent variables with temporal dependencies that are highly discriminative yet view-invariant in matching persons. Through extensive experiments conducted on three benchmark datasets, we empirically show the capability of our method in creating view-invariant temporal features and state-of-the-art performance achieved by our method.
Pixel-aware Deep Function-mixture Network for Spectral Super-Resolution
Mar 24, 2019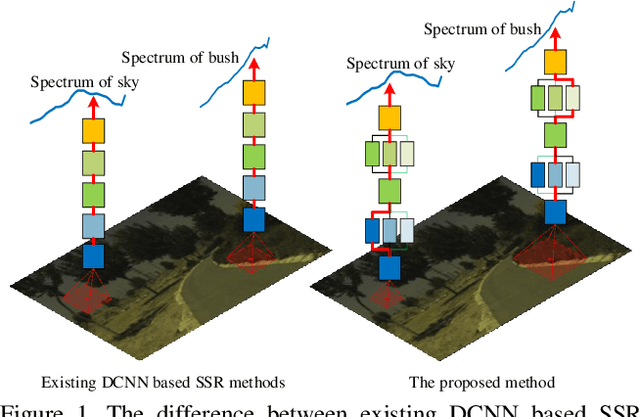
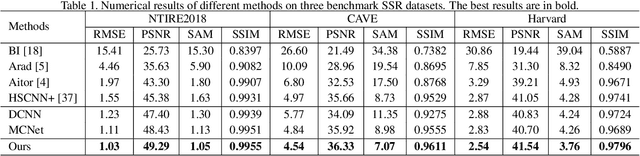
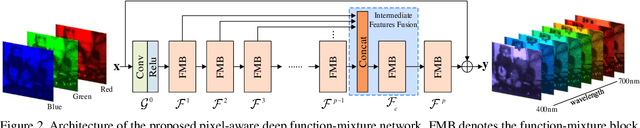
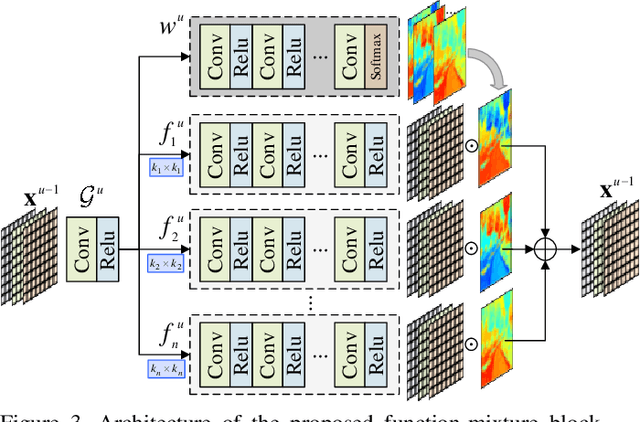
Spectral super-resolution (SSR) aims at generating a hyperspectral image (HSI) from a given RGB image. Recently, a promising direction for SSR is to learn a complicated mapping function from the RGB image to the HSI counterpart using a deep convolutional neural network. This essentially involves mapping the RGB context within a size-specific receptive field centered at each pixel to its spectrum in the HSI. The focus thereon is to appropriately determine the receptive field size and establish the mapping function from RGB context to the corresponding spectrum. Due to their differences in category or spatial position, pixels in HSIs often require different-sized receptive fields and distinct mapping functions. However, few efforts have been invested to explicitly exploit this prior. To address this problem, we propose a pixel-aware deep function-mixture network for SSR, which is composed of a new class of modules, termed function-mixture (FM) blocks. Each FM block is equipped with some basis functions, i.e., parallel subnets of different-sized receptive fields. Besides, it incorporates an extra subnet as a mixing function to generate pixel-wise weights, and then linearly mixes the outputs of all basis functions with those generated weights. This enables us to pixel-wisely determine the receptive field size and the mapping function. Moreover, we stack several such FM blocks to further increase the flexibility of the network in learning the pixel-wise mapping. To encourage feature reuse, intermediate features generated by the FM blocks are fused in late stage, which proves to be effective for boosting the SSR performance. Experimental results on three benchmark HSI datasets demonstrate the superiority of the proposed method.
Object Counting and Instance Segmentation with Image-level Supervision
Mar 06, 2019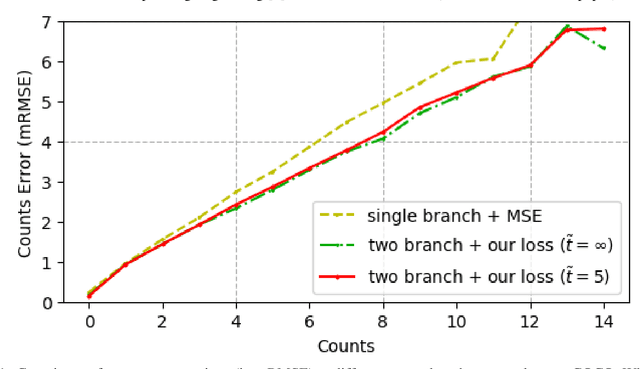



Common object counting in a natural scene is a challenging problem in computer vision with numerous real-world applications. Existing image-level supervised common object counting approaches only predict the global object count and rely on additional instance-level supervision to also determine object locations. We propose an image-level supervised approach that provides both the global object count and the spatial distribution of object instances by constructing an object category density map. Motivated by psychological studies, we further reduce image-level supervision using a limited object count information (up to four). To the best of our knowledge, we are the first to propose image-level supervised density map estimation for common object counting and demonstrate its effectiveness in image-level supervised instance segmentation. Comprehensive experiments are performed on the PASCAL VOC and COCO datasets. Our approach outperforms existing methods, including those using instance-level supervision, on both datasets for common object counting. Moreover, our approach improves state-of-the-art image-level supervised instance segmentation with a relative gain of 17.8% in terms of average best overlap, on the PASCAL VOC 2012 dataset.
Crowd Counting and Density Estimation by Trellis Encoder-Decoder Network
Mar 03, 2019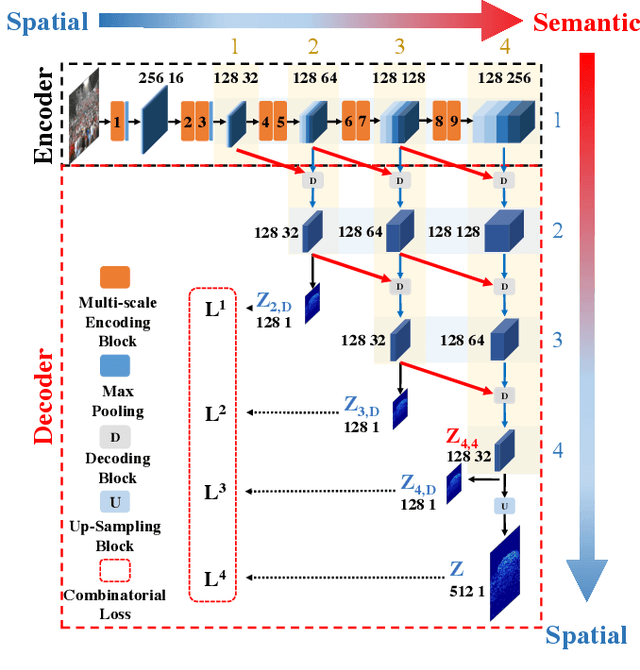
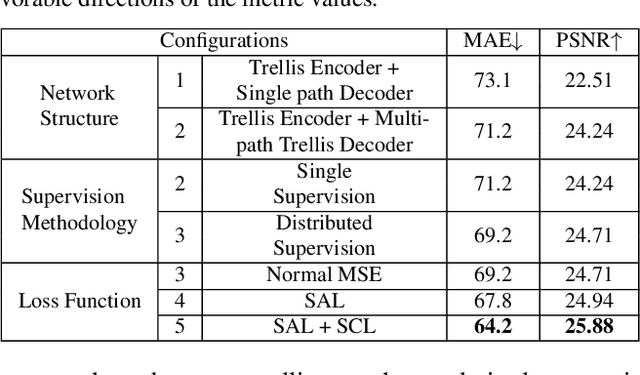
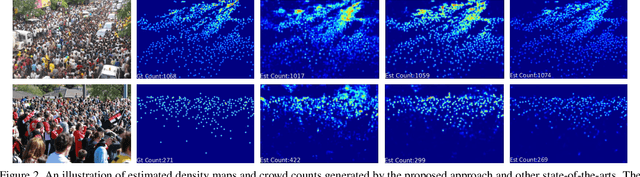
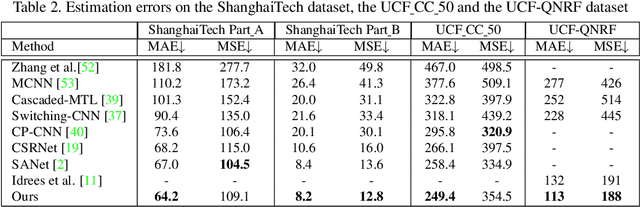
Crowd counting has recently attracted increasing interest in computer vision but remains a challenging problem. In this paper, we propose a trellis encoder-decoder network (TEDnet) for crowd counting, which focuses on generating high-quality density estimation maps. The major contributions are four-fold. First, we develop a new trellis architecture that incorporates multiple decoding paths to hierarchically aggregate features at different encoding stages, which can handle large variations of objects. Second, we design dense skip connections interleaved across paths to facilitate sufficient multi-scale feature fusions and to absorb the supervision information. Third, we propose a new combinatorial loss to enforce local coherence and spatial correlation in density maps. By distributedly imposing this combinatorial loss on intermediate outputs, gradient vanishing can be largely alleviated for better back-propagation and faster convergence. Finally, our TEDnet achieves new state-of-the art performance on four benchmarks, with an improvement up to 14% in terms of MAE.
Pixelated Semantic Colorization
Feb 07, 2019
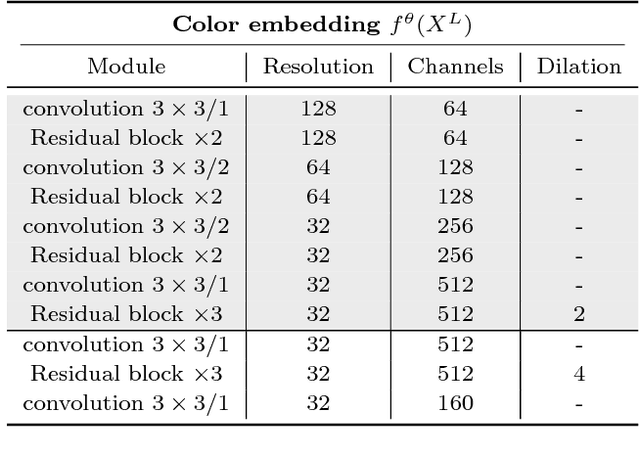
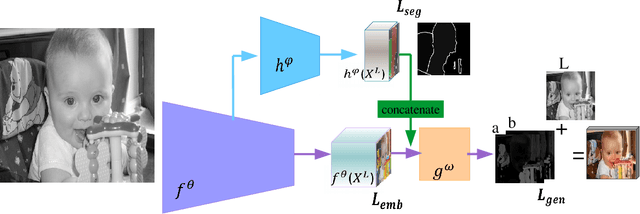
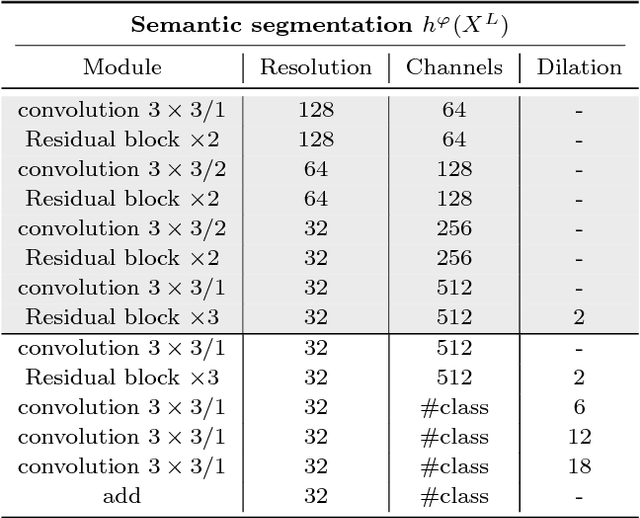
While many image colorization algorithms have recently shown the capability of producing plausible color versions from gray-scale photographs, they still suffer from limited semantic understanding. To address this shortcoming, we propose to exploit pixelated object semantics to guide image colorization. The rationale is that human beings perceive and distinguish colors based on the semantic categories of objects. Starting from an autoregressive model, we generate image color distributions, from which diverse colored results are sampled. We propose two ways to incorporate object semantics into the colorization model: through a pixelated semantic embedding and a pixelated semantic generator. Specifically, the proposed convolutional neural network includes two branches. One branch learns what the object is, while the other branch learns the object colors. The network jointly optimizes a color embedding loss, a semantic segmentation loss and a color generation loss, in an end-to-end fashion. Experiments on PASCAL VOC2012 and COCO-stuff reveal that our network, when trained with semantic segmentation labels, produces more realistic and finer results compared to the colorization state-of-the-art.
Max-margin Class Imbalanced Learning with Gaussian Affinity
Jan 23, 2019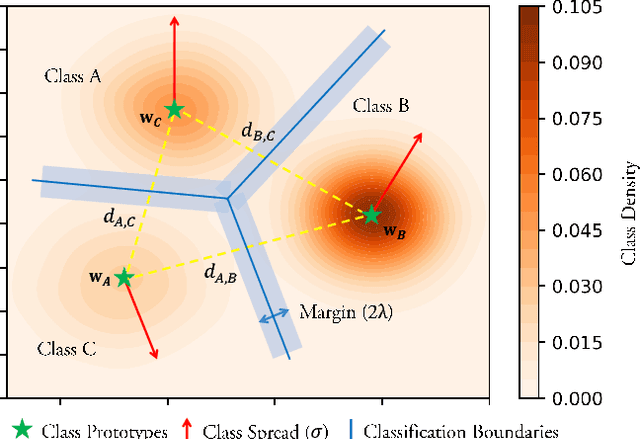
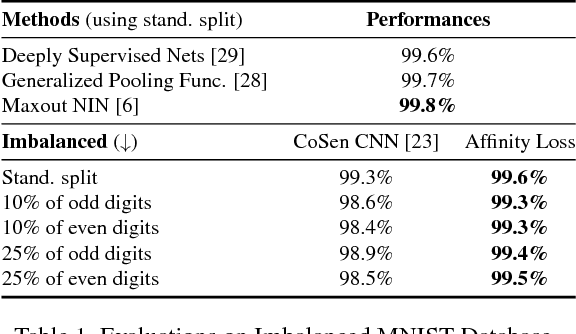
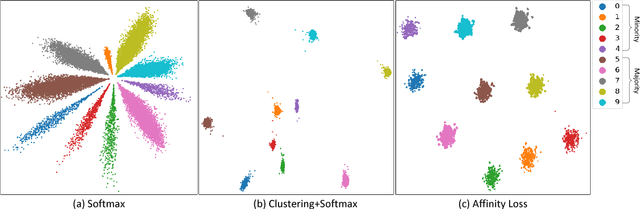
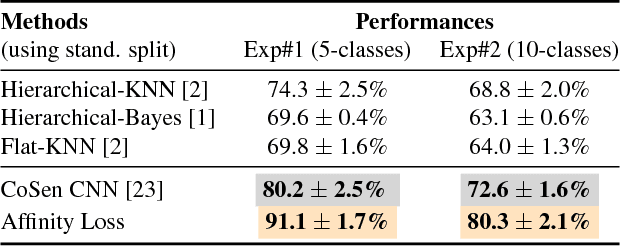
Real-world object classes appear in imbalanced ratios. This poses a significant challenge for classifiers which get biased towards frequent classes. We hypothesize that improving the generalization capability of a classifier should improve learning on imbalanced datasets. Here, we introduce the first hybrid loss function that jointly performs classification and clustering in a single formulation. Our approach is based on an `affinity measure' in Euclidean space that leads to the following benefits: (1) direct enforcement of maximum margin constraints on classification boundaries, (2) a tractable way to ensure uniformly spaced and equidistant cluster centers, (3) flexibility to learn multiple class prototypes to support diversity and discriminability in feature space. Our extensive experiments demonstrate the significant performance improvements on visual classification and verification tasks on multiple imbalanced datasets. The proposed loss can easily be plugged in any deep architecture as a differentiable block and demonstrates robustness against different levels of data imbalance and corrupted labels.
Striking the Right Balance with Uncertainty
Jan 22, 2019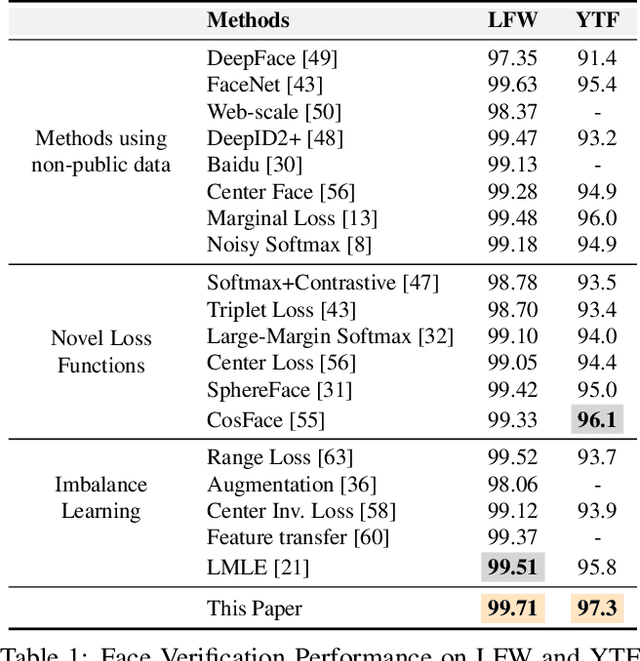
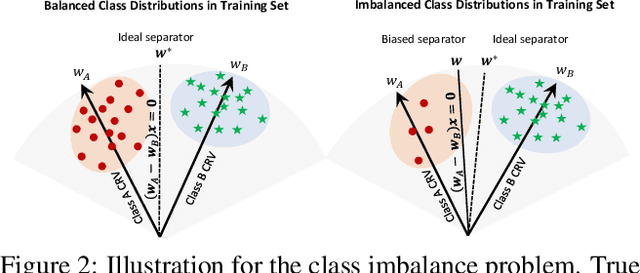
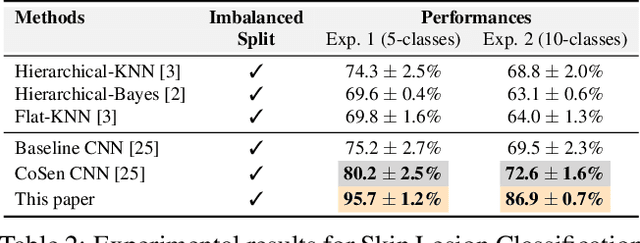
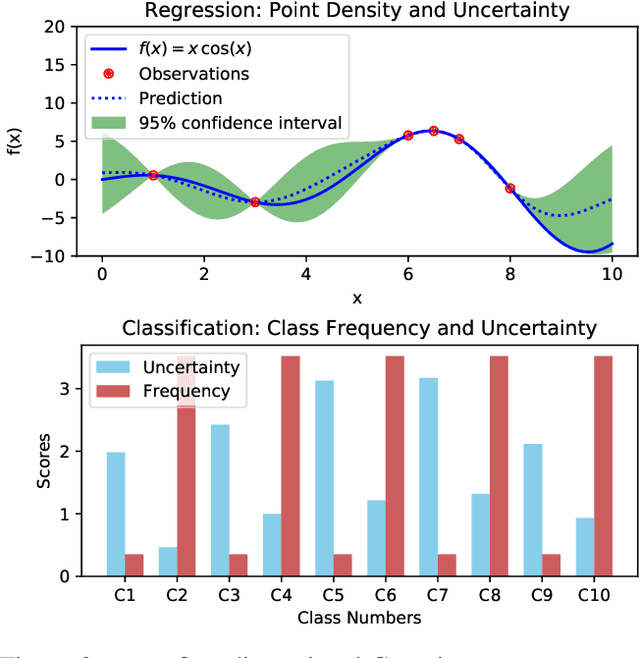
Learning unbiased models on imbalanced datasets is a significant challenge. Rare classes tend to get a concentrated representation in the classification space which hampers the generalization of learned boundaries to new test examples. In this paper, we demonstrate that the Bayesian uncertainty estimates directly correlate with the rarity of classes and the difficulty level of individual samples. Subsequently, we present a novel framework for uncertainty based class imbalance learning that follows two key insights: First, classification boundaries should be extended further away from a more uncertain (rare) class to avoid overfitting and enhance its generalization. Second, each sample should be modeled as a multi-variate Gaussian distribution with a mean vector and a covariance matrix defined by the sample's uncertainty. The learned boundaries should respect not only the individual samples but also their distribution in the feature space. Our proposed approach efficiently utilizes sample and class uncertainty information to learn robust features and more generalizable classifiers. We systematically study the class imbalance problem and derive a novel loss formulation for max-margin learning based on Bayesian uncertainty measure. The proposed method shows significant performance improvements on six benchmark datasets for face verification, attribute prediction, digit/object classification and skin lesion detection.