 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Cross-View Gait Identification with Evidence: A Discriminant Gait GAN (DiGGAN) Approach on 10000 People
Nov 26, 2018
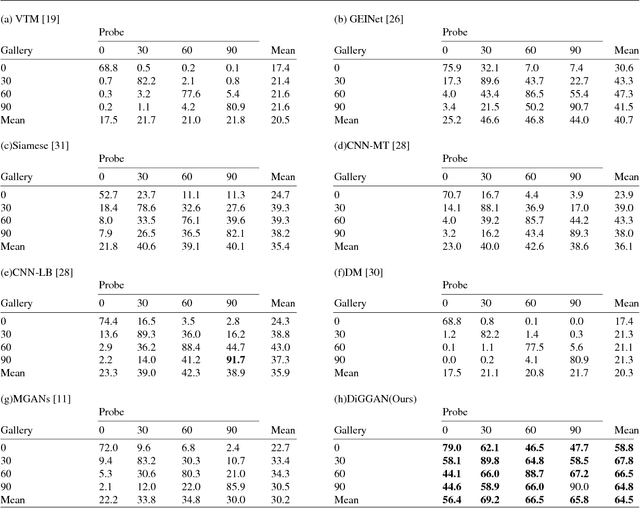
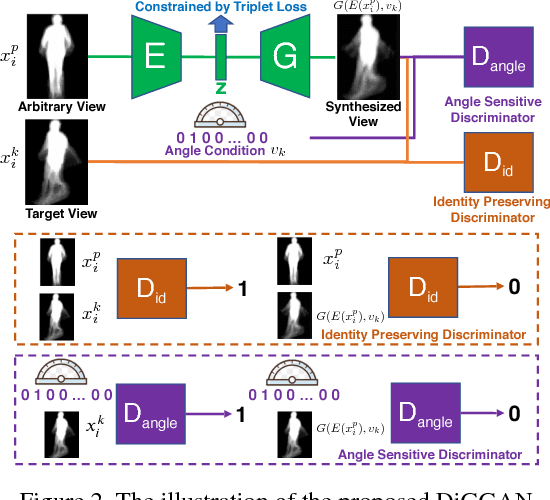
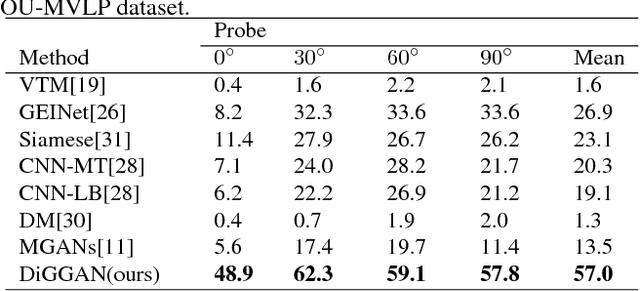
Gait is an important biometric trait for surveillance and forensic applications, which can be used to identify individuals at a large distance through CCTV cameras. However, it is very difficult to develop robust automated gait recognition systems, since gait may be affected by many covariate factors such as clothing, walking surface, walking speed, camera view angle, etc. Out of them, large view angle was deemed as the most challenging factor since it may alter the overall gait appearance substantially. Recently, some deep learning approaches (such as CNNs) have been employed to extract view-invariant features, and achieved encouraging results on small datasets. However, they do not scale well to large dataset, and the performance decreases significantly w.r.t. number of subjects, which is impractical to large-scale surveillance applications. To address this issue, in this work we propose a Discriminant Gait Generative Adversarial Network (DiGGAN) framework, which not only can learn view-invariant gait features for cross-view gait recognition tasks, but also can be used to reconstruct the gait templates in all views --- serving as important evidences for forensic applications. We evaluated our DiGGAN framework on the world's largest multi-view OU-MVLP dataset (which includes more than 10000 subjects), and our method outperforms state-of-the-art algorithms significantly on various cross-view gait identification scenarios (e.g., cooperative/uncooperative mode). Our DiGGAN framework also has the best results on the popular CASIA-B dataset, and it shows great generalisation capability across different datasets.
Dual-reference Face Retrieval
Nov 22, 2017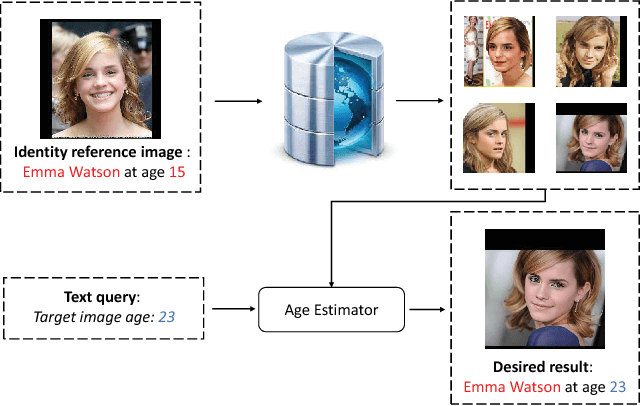

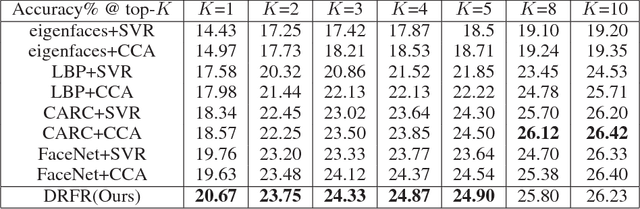
Face retrieval has received much attention over the past few decades, and many efforts have been made in retrieving face images against pose, illumination, and expression variations. However, the conventional works fail to meet the requirements of a potential and novel task --- retrieving a person's face image at a specific age, especially when the specific 'age' is not given as a numeral, i.e. 'retrieving someone's image at the similar age period shown by another person's image'. To tackle this problem, we propose a dual reference face retrieval framework in this paper, where the system takes two inputs: an identity reference image which indicates the target identity and an age reference image which reflects the target age. In our framework, the raw images are first projected on a joint manifold, which preserves both the age and identity locality. Then two similarity metrics of age and identity are exploited and optimized by utilizing our proposed quartet-based model. The experiments show promising results, outperforming hierarchical methods.