 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycleISP: Real Image Restoration via Improved Data Synthesis
Mar 17, 2020
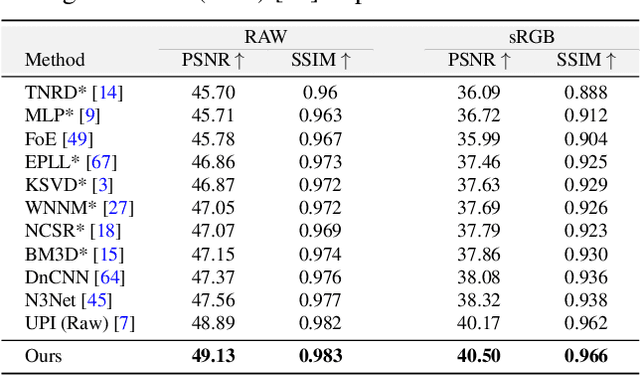
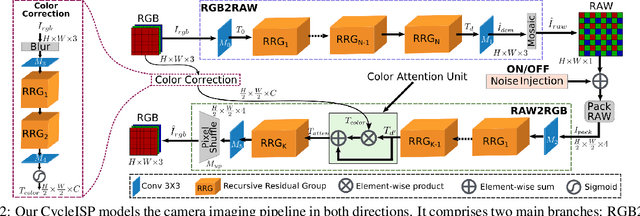
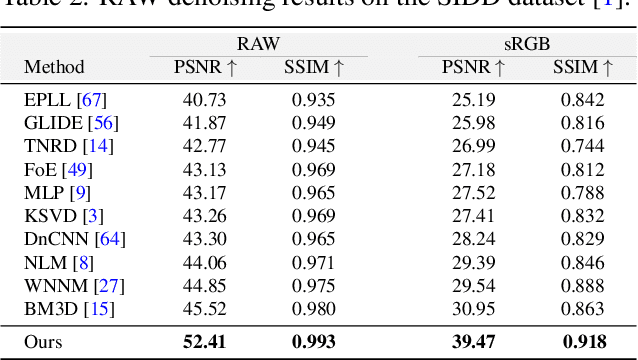
The availability of large-scale datasets has helped unleash the true potential of deep convolutional neural networks (CNNs). However, for the single-image denoising problem, capturing a real dataset is an unacceptably expensive and cumbersome procedure. Consequently, image denoising algorithms are mostly developed and evaluated on synthetic data that is usually generated with a widespread assumption of additive white Gaussian noise (AWGN). While the CNNs achieve impressive results on these synthetic datasets, they do not perform well when applied on real camera images, as reported in recent benchmark datasets. This is mainly because the AWGN is not adequate for modeling the real camera noise which is signal-dependent and heavily transformed by the camera imaging pipeline. In this paper, we present a framework that models camera imaging pipeline in forward and reverse directions. It allows us to produce any number of realistic image pairs for denoising both in RAW and sRGB spaces. By training a new image denoising network on realistic synthetic data, we achieve the state-of-the-art performance on real camera benchmark datasets. The parameters in our model are ~5 times lesser than the previous best method for RAW denoising. Furthermore, we demonstrate that the proposed framework generalizes beyond image denoising problem e.g., for color matching in stereoscopic cinema. The source code and pre-trained models are available at https://github.com/swz30/CycleISP.
Incremental Object Detection via Meta-Learning
Mar 17, 2020

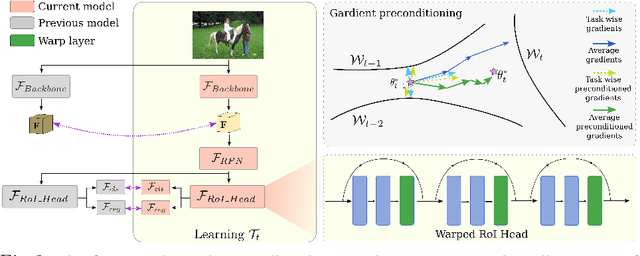

In a real-world setting, object instances from new classes may be continuously encountered by object detectors. When existing object detectors are applied to such scenarios, their performance on old classes deteriorates significantly. A few efforts have been reported to address this limitation, all of which apply variants of knowledge distillation to avoid catastrophic forgetting. We note that although distillation helps to retain previous learning, it obstructs fast adaptability to new tasks, which is a critical requirement for incremental learning. In this pursuit, we propose a meta-learning approach that learns to reshape model gradients, such that information across incremental tasks is optimally shared. This ensures a seamless information transfer via a meta-learned gradient preconditioning that minimizes forgetting and maximizes knowledge transfer. In comparison to existing meta-learning methods, our approach is task-agnostic, allows incremental addition of new-classes and scales to large-sized models for object detection. We evaluate our approach on a variety of incremental settings defined on PASCAL-VOC and MS COCO datasets, demonstrating significant improvements over state-of-the-art.
HRank: Filter Pruning using High-Rank Feature Map
Mar 16, 2020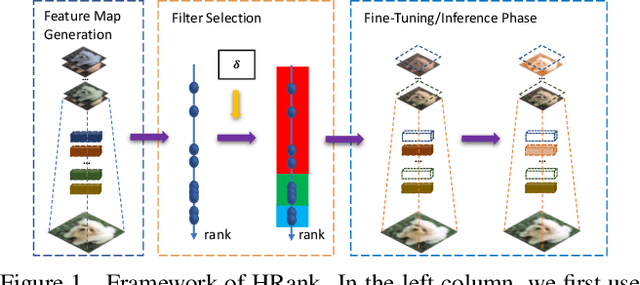
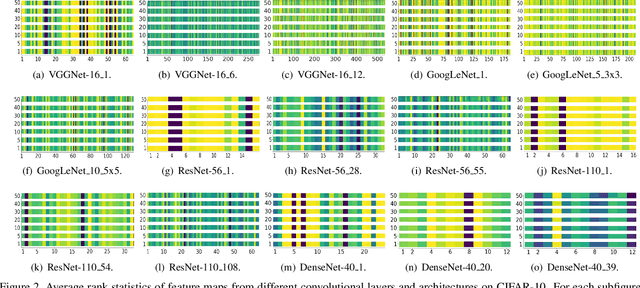
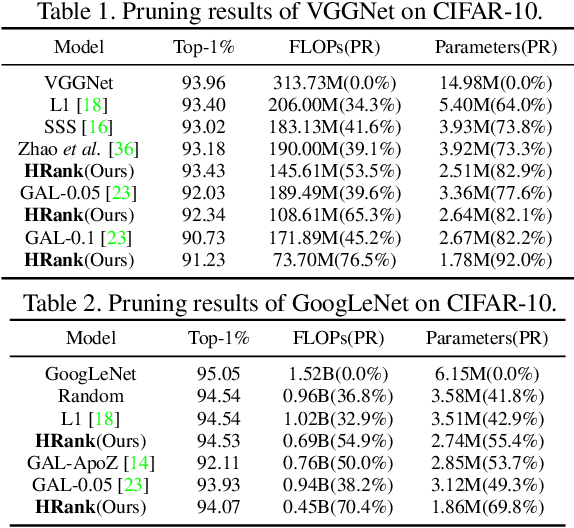
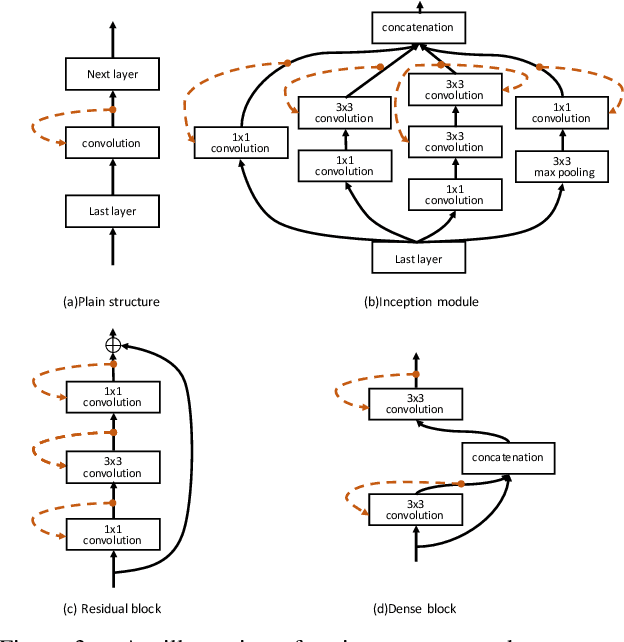
Neural network pruning offers a promising prospect to facilitate deploying deep neural networks on resource-limited devices. However, existing methods are still challenged by the training inefficiency and labor cost in pruning designs, due to missing theoretical guidance of non-salient network components. In this paper, we propose a novel filter pruning method by exploring the High Rank of feature maps (HRank). Our HRank is inspired by the discovery that the average rank of multiple feature maps generated by a single filter is always the same, regardless of the number of image batches CNNs receive. Based on HRank, we develop a method that is mathematically formulated to prune filters with low-rank feature maps. The principle behind our pruning is that low-rank feature maps contain less information, and thus pruned results can be easily reproduced. Besides, we experimentally show that weights with high-rank feature maps contain more important information, such that even when a portion is not updated, very little damage would be done to the model performance. Without introducing any additional constraints, HRank leads to significant improvements over the state-of-the-arts in terms of FLOPs and parameters reduction, with similar accuracies. For example, with ResNet-110, we achieve a 58.2%-FLOPs reduction by removing 59.2% of the parameters, with only a small loss of 0.14% in top-1 accuracy on CIFAR-10. With Res-50, we achieve a 43.8%-FLOPs reduction by removing 36.7% of the parameters, with only a loss of 1.17% in the top-1 accuracy on ImageNet. The codes can be available at https://github.com/lmbxmu/HRank.
Auto-Encoding Twin-Bottleneck Hashing
Mar 16, 2020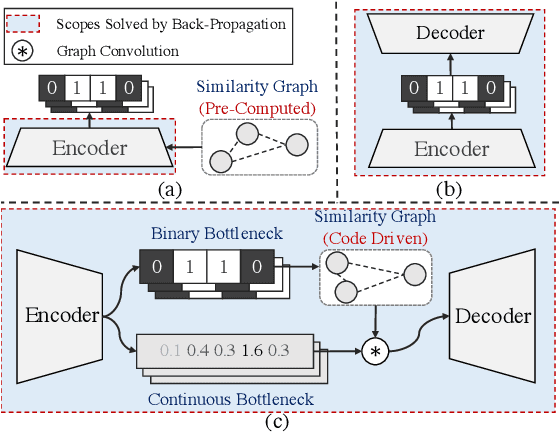
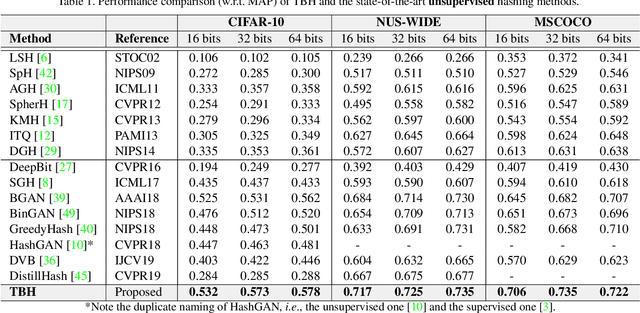
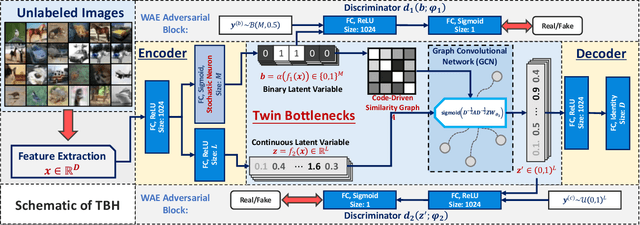
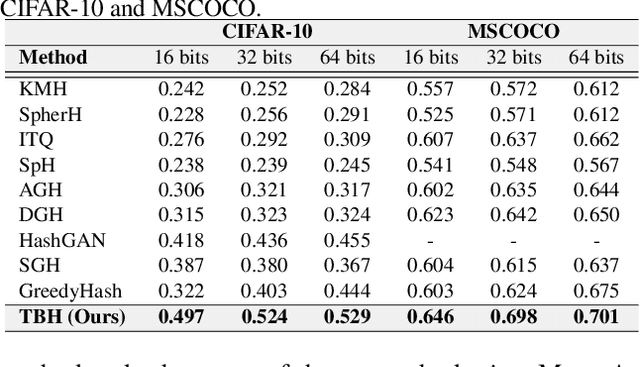
Conventional unsupervised hashing methods usually take advantage of similarity graphs, which are either pre-computed in the high-dimensional space or obtained from random anchor points. On the one hand, existing methods uncouple the procedures of hash function learning and graph construction. On the other hand, graphs empirically built upon original data could introduce biased prior knowledge of data relevance, leading to sub-optimal retrieval performance. In this paper, we tackle the above problems by proposing an efficient and adaptive code-driven graph, which is updated by decoding in the context of an auto-encoder. Specifically, we introduce into our framework twin bottlenecks (i.e., latent variables) that exchange crucial information collaboratively. One bottleneck (i.e., binary codes) conveys the high-level intrinsic data structure captured by the code-driven graph to the other (i.e., continuous variables for low-level detail information), which in turn propagates the updated network feedback for the encoder to learn more discriminative binary codes. The auto-encoding learning objective literally rewards the code-driven graph to learn an optimal encoder. Moreover, the proposed model can be simply optimized by gradient descent without violating the binary constraints. Experiments on benchmarked datasets clearly show the superiority of our framework over the state-of-the-art hashing methods. Our source code can be found at https://github.com/ymcidence/TBH.
Learning Enriched Features for Real Image Restoration and Enhancement
Mar 15, 2020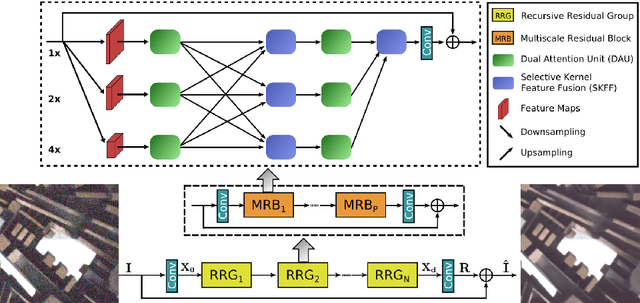

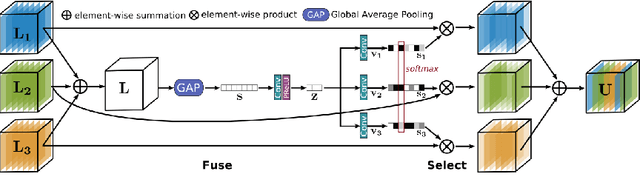
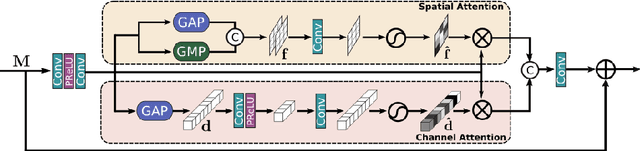
With the goal of recovering high-quality image content from its degraded version, image restoration enjoys numerous applications, such as in surveillance, computational photography, medical imaging, and remote sensing. Recently, convolutional neural networks (CNNs) have achieved dramatic improvements over conventional approaches for image restoration task. Existing CNN-based methods typically operate either on full-resolution or on progressively low-resolution representations. In the former case, spatially precise but contextually less robust results are achieved, while in the latter case, semantically reliable but spatially less accurate outputs are generated. In this paper, we present a novel architecture with the collective goals of maintaining spatially-precise high-resolution representations through the entire network, and receiving strong contextual information from the low-resolution representations. The core of our approach is a multi-scale residual block containing several key elements: (a) parallel multi-resolution convolution streams for extracting multi-scale features, (b) information exchange across the multi-resolution streams, (c) spatial and channel attention mechanisms for capturing contextual information, and (d) attention based multi-scale feature aggregation. In the nutshell, our approach learns an enriched set of features that combines contextual information from multiple scales, while simultaneously preserving the high-resolution spatial details. Extensive experiments on five real image benchmark datasets demonstrate that our method, named as MIRNet, achieves state-of-the-art results for a variety of image processing tasks, including image denoising, super-resolution and image enhancement.
Motion-Attentive Transition for Zero-Shot Video Object Segmentation
Mar 15, 2020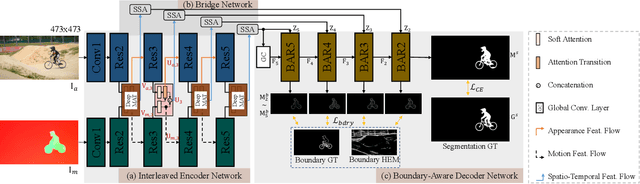
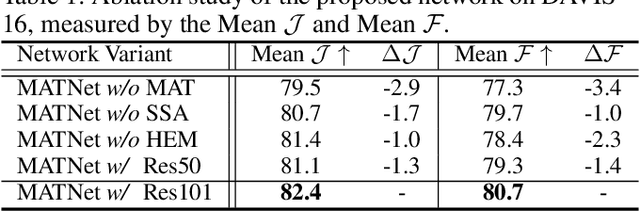
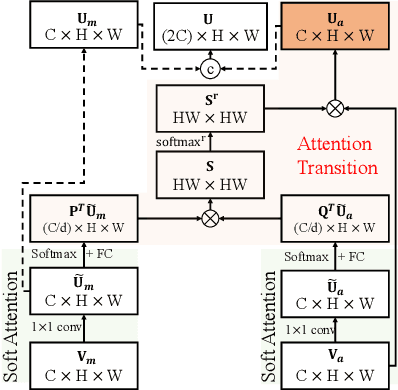
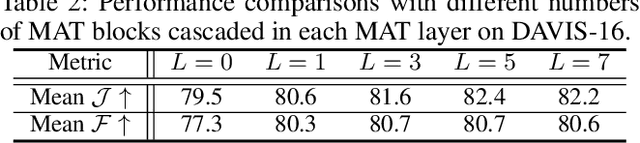
In this paper, we present a novel Motion-Attentive Transition Network (MATNet) for zero-shot video object segmentation, which provides a new way of leveraging motion information to reinforce spatio-temporal object representation. An asymmetric attention block, called Motion-Attentive Transition (MAT), is designed within a two-stream encoder, which transforms appearance features into motion-attentive representations at each convolutional stage. In this way, the encoder becomes deeply interleaved, allowing for closely hierarchical interactions between object motion and appearance. This is superior to the typical two-stream architecture, which treats motion and appearance separately in each stream and often suffers from overfitting to appearance information. Additionally, a bridge network is proposed to obtain a compact, discriminative and scale-sensitive representation for multi-level encoder features, which is further fed into a decoder to achieve segmentation results. Extensive experiments on three challenging public benchmarks (i.e. DAVIS-16, FBMS and Youtube-Objects) show that our model achieves compelling performance against the state-of-the-arts.
Layer-wise Conditioning Analysis in Exploring the Learning Dynamics of DNNs
Mar 11, 2020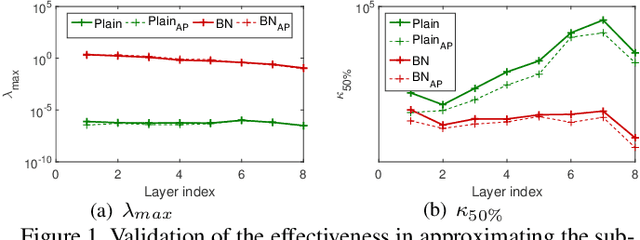

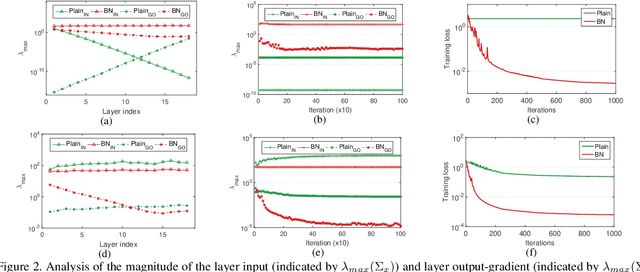

Conditioning analysis uncovers the landscape of an optimization objective by exploring the spectrum of its curvature matrix. This has been well explored theoretically for linear models. We extend this analysis to deep neural networks (DNNs) in order to investigate their learning dynamics. To this end, we propose layer-wise conditioning analysis, which explores the optimization landscape with respect to each layer independently. Such an analysis is theoretically supported under mild assumptions that approximately hold in practice. Based on our analysis, we show that batch normalization (BN) can stabilize the training, but sometimes result in the false impression of a local minimum, which has detrimental effects on the learning. Besides, we experimentally observe that BN can improve the layer-wise conditioning of the optimization problem. Finally, we find that the last linear layer of a very deep residual network displays ill-conditioned behavior. We solve this problem by only adding one BN layer before the last linear layer, which achieves improved performance over the original and pre-activation residual networks.
Hierarchical Human Parsing with Typed Part-Relation Reasoning
Mar 11, 2020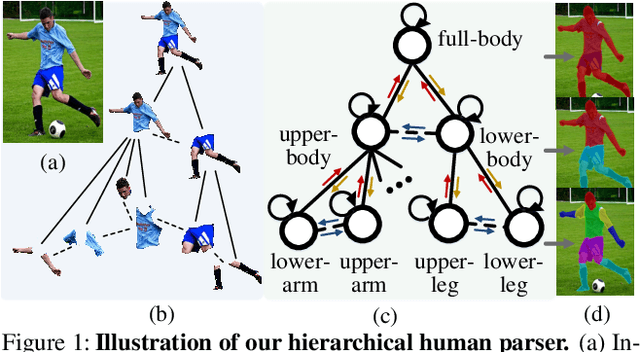
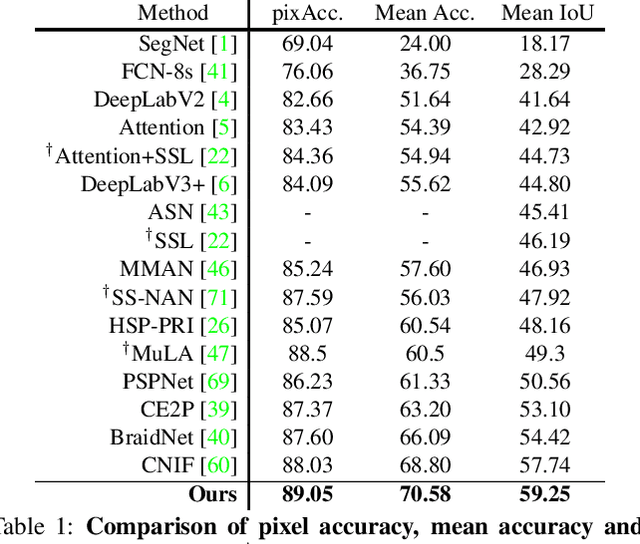
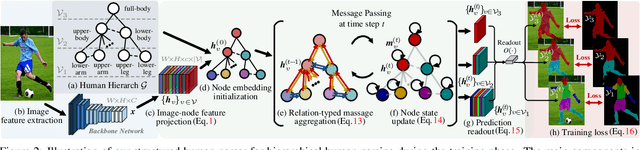
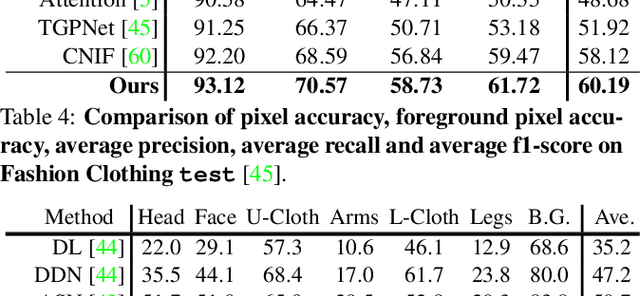
Human parsing is for pixel-wise human semantic understanding. As human bodies are underlying hierarchically structured, how to model human structures is the central theme in this task. Focusing on this, we seek to simultaneously exploit the representational capacity of deep graph networks and the hierarchical human structures. In particular, we provide following two contributions. First, three kinds of part relations, i.e., decomposition, composition, and dependency, are, for the first time, completely and precisely described by three distinct relation networks. This is in stark contrast to previous parsers, which only focus on a portion of the relations and adopt a type-agnostic relation modeling strategy. More expressive relation information can be captured by explicitly imposing the parameters in the relation networks to satisfy the specific characteristics of different relations. Second, previous parsers largely ignore the need for an approximation algorithm over the loopy human hierarchy, while we instead address an iterative reasoning process, by assimilating generic message-passing networks with their edge-typed, convolutional counterparts. With these efforts, our parser lays the foundation for more sophisticated and flexible human relation patterns of reasoning. Comprehensive experiments on five datasets demonstrate that our parser sets a new state-of-the-art on each.
Pixel-In-Pixel Net: Towards Efficient Facial Landmark Detection in the Wild
Mar 08, 2020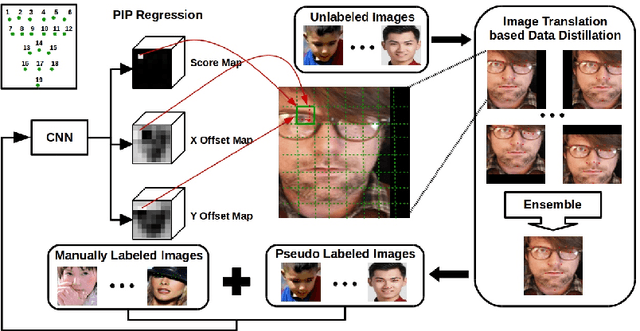

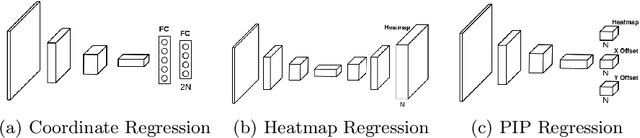

Recently, heatmap regression based models become popular because of their superior performance on locating facial landmarks. However, high-resolution feature maps have to be either generated repeatedly or maintained through the network for such models, which is computationally inefficient for practical applications. Moreover, their generalization capabilities across domains are rarely explored. To address these two problems, we propose Pixel-In-Pixel (PIP) Net for facial landmark detection. The proposed model is equipped with a novel detection head based on heatmap regression. Different from conventional heatmap regression, the new detection head conducts score prediction on low-resolution feature maps. To localize landmarks more precisely, it also conduct offset predictions within each heatmap pixel. By doing this, the inference time is largely reduced without losing accuracy. Besides, we also propose to leverage unlabeled images to improve the generalization capbility of our model through image translation based data distillation. Extensive experiments on four benchmarks show that PIP Net is comparable to state-of-the-arts while running at $27.8$ FPS on a CPU.
Infinitely Wide Graph Convolutional Networks: Semi-supervised Learning via Gaussian Processes
Feb 26, 2020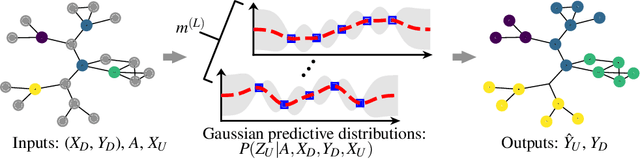


Graph convolutional neural networks~(GCNs) have recently demonstrated promising results on graph-based semi-supervised classification, but little work has been done to explore their theoretical properties. Recently, several deep neural networks, e.g., fully connected and convolutional neural networks, with infinite hidden units have been proved to be equivalent to Gaussian processes~(GPs). To exploit both the powerful representational capacity of GCNs and the great expressive power of GPs, we investigate similar properties of infinitely wide GCNs. More specifically, we propose a GP regression model via GCNs~(GPGC) for graph-based semi-supervised learning. In the process, we formulate the kernel matrix computation of GPGC in an iterative analytical form. Finally, we derive a conditional distribution for the labels of unobserved nodes based on the graph structure, labels for the observed nodes, and the feature matrix of all the nodes. We conduct extensive experiments to evaluate the semi-supervised classification performance of GPGC and demonstrate that it outperforms other state-of-the-art methods by a clear margin on all the datasets while being efficient.