 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Sample Effective and Diverse Prompts for Text-to-Image Generation
Feb 17, 2025Recent advances in text-to-image diffusion models have achieved impressive image generation capabilities. However, it remains challenging to control the generation process with desired properties (e.g., aesthetic quality, user intention), which can be expressed as black-box reward functions. In this paper, we focus on prompt adaptation, which refines the original prompt into model-preferred prompts to generate desired images. While prior work uses reinforcement learning (RL) to optimize prompts, we observe that applying RL often results in generating similar postfixes and deterministic behaviors. To this end, we introduce \textbf{P}rompt \textbf{A}daptation with \textbf{G}FlowNets (\textbf{PAG}), a novel approach that frames prompt adaptation as a probabilistic inference problem. Our key insight is that leveraging Generative Flow Networks (GFlowNets) allows us to shift from reward maximization to sampling from an unnormalized density function, enabling both high-quality and diverse prompt generation. However, we identify that a naive application of GFlowNets suffers from mode collapse and uncovers a previously overlooked phenomenon: the progressive loss of neural plasticity in the model, which is compounded by inefficient credit assignment in sequential prompt generation. To address this critical challenge, we develop a systematic approach in PAG with flow reactivation, reward-prioritized sampling, and reward decomposition for prompt adaptation. Extensive experiments validate that PAG successfully learns to sample effective and diverse prompts for text-to-image generation. We also show that PAG exhibits strong robustness across various reward functions and transferability to different text-to-image models.
Pre-Trained Video Generative Models as World Simulators
Feb 10, 2025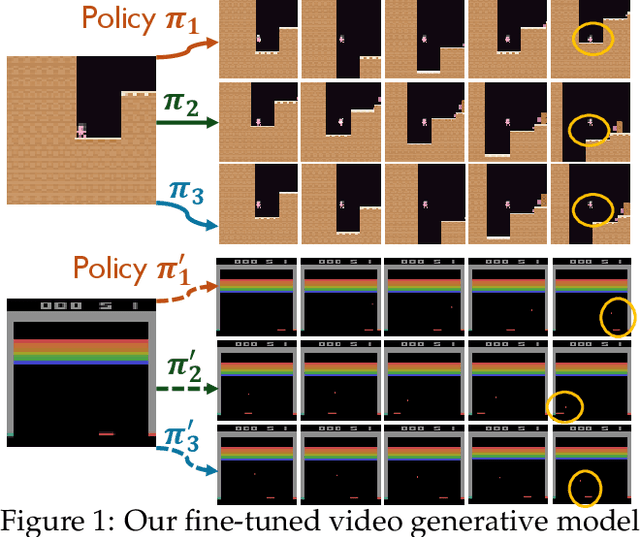

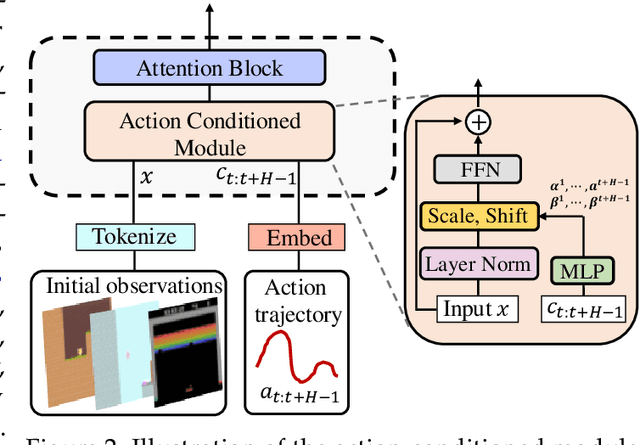
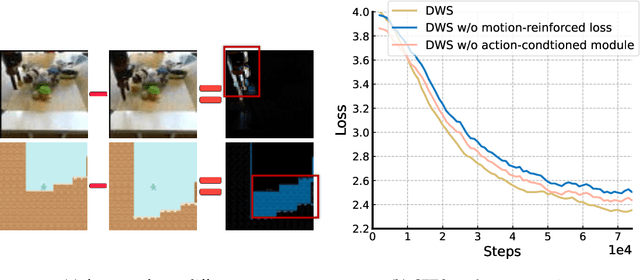
Video generative models pre-trained on large-scale internet datasets have achieved remarkable success, excelling at producing realistic synthetic videos. However, they often generate clips based on static prompts (e.g., text or images), limiting their ability to model interactive and dynamic scenarios. In this paper, we propose Dynamic World Simulation (DWS), a novel approach to transform pre-trained video generative models into controllable world simulators capable of executing specified action trajectories. To achieve precise alignment between conditioned actions and generated visual changes, we introduce a lightweight, universal action-conditioned module that seamlessly integrates into any existing model. Instead of focusing on complex visual details, we demonstrate that consistent dynamic transition modeling is the key to building powerful world simulators. Building upon this insight, we further introduce a motion-reinforced loss that enhances action controllability by compelling the model to capture dynamic changes more effectively. Experiments demonstrate that DWS can be versatilely applied to both diffusion and autoregressive transformer models, achieving significant improvements in generating action-controllable, dynamically consistent videos across games and robotics domains. Moreover, to facilitate the applications of the learned world simulator in downstream tasks such as model-based reinforcement learning, we propose prioritized imagination to improve sample efficiency, demonstrating competitive performance compared with state-of-the-art methods.
Kaleidoscope: Learnable Masks for Heterogeneous Multi-agent Reinforcement Learning
Oct 11, 2024



In multi-agent reinforcement learning (MARL), parameter sharing is commonly employed to enhance sample efficiency. However, the popular approach of full parameter sharing often leads to homogeneous policies among agents, potentially limiting the performance benefits that could be derived from policy diversity. To address this critical limitation, we introduce \emph{Kaleidoscope}, a novel adaptive partial parameter sharing scheme that fosters policy heterogeneity while still maintaining high sample efficiency. Specifically, Kaleidoscope maintains one set of common parameters alongside multiple sets of distinct, learnable masks for different agents, dictating the sharing of parameters. It promotes diversity among policy networks by encouraging discrepancy among these masks, without sacrificing the efficiencies of parameter sharing. This design allows Kaleidoscope to dynamically balance high sample efficiency with a broad policy representational capacity, effectively bridging the gap between full parameter sharing and non-parameter sharing across various environments. We further extend Kaleidoscope to critic ensembles in the context of actor-critic algorithms, which could help improve value estimations.Our empirical evaluations across extensive environments, including multi-agent particle environment, multi-agent MuJoCo and StarCraft multi-agent challenge v2, demonstrate the superior performance of Kaleidoscope compared with existing parameter sharing approaches, showcasing its potential for performance enhancement in MARL. The code is publicly available at \url{https://github.com/LXXXXR/Kaleidoscope}.
Neuroplastic Expansion in Deep Reinforcement Learning
Oct 10, 2024



The loss of plasticity in learning agents, analogous to the solidification of neural pathways in biological brains, significantly impedes learning and adaptation in reinforcement learning due to its non-stationary nature. To address this fundamental challenge, we propose a novel approach, Neuroplastic Expansion (NE), inspired by cortical expansion in cognitive science. NE maintains learnability and adaptability throughout the entire training process by dynamically growing the network from a smaller initial size to its full dimension. Our method is designed with three key components: (1) elastic neuron generation based on potential gradients, (2) dormant neuron pruning to optimize network expressivity, and (3) neuron consolidation via experience review to strike a balance in the plasticity-stability dilemma. Extensive experiments demonstrate that NE effectively mitigates plasticity loss and outperforms state-of-the-art methods across various tasks in MuJoCo and DeepMind Control Suite environments. NE enables more adaptive learning in complex, dynamic environments, which represents a crucial step towards transitioning deep reinforcement learning from static, one-time training paradigms to more flexible, continually adapting models.
Value-Based Deep Multi-Agent Reinforcement Learning with Dynamic Sparse Training
Sep 28, 2024Deep Multi-agent Reinforcement Learning (MARL) relies on neural networks with numerous parameters in multi-agent scenarios, often incurring substantial computational overhead. Consequently, there is an urgent need to expedite training and enable model compression in MARL. This paper proposes the utilization of dynamic sparse training (DST), a technique proven effective in deep supervised learning tasks, to alleviate the computational burdens in MARL training. However, a direct adoption of DST fails to yield satisfactory MARL agents, leading to breakdowns in value learning within deep sparse value-based MARL models. Motivated by this challenge, we introduce an innovative Multi-Agent Sparse Training (MAST) framework aimed at simultaneously enhancing the reliability of learning targets and the rationality of sample distribution to improve value learning in sparse models. Specifically, MAST incorporates the Soft Mellowmax Operator with a hybrid TD-($\lambda$) schema to establish dependable learning targets. Additionally, it employs a dual replay buffer mechanism to enhance the distribution of training samples. Building upon these aspects, MAST utilizes gradient-based topology evolution to exclusively train multiple MARL agents using sparse networks. Our comprehensive experimental investigation across various value-based MARL algorithms on multiple benchmarks demonstrates, for the first time, significant reductions in redundancy of up to $20\times$ in Floating Point Operations (FLOPs) for both training and inference, with less than $3\%$ performance degradation.
Rectifying Reinforcement Learning for Reward Matching
Jun 04, 2024



The Generative Flow Network (GFlowNet) is a probabilistic framework in which an agent learns a stochastic policy and flow functions to sample objects with probability proportional to an unnormalized reward function. GFlowNets share a strong resemblance to reinforcement learning (RL), that typically aims to maximize reward, due to their sequential decision-making processes. Recent works have studied connections between GFlowNets and maximum entropy (MaxEnt) RL, which modifies the standard objective of RL agents by learning an entropy-regularized objective. However, a critical theoretical gap persists: despite the apparent similarities in their sequential decision-making nature, a direct link between GFlowNets and standard RL has yet to be discovered, while bridging this gap could further unlock the potential of both fields. In this paper, we establish a new connection between GFlowNets and policy evaluation for a uniform policy. Surprisingly, we find that the resulting value function for the uniform policy has a close relationship to the flows in GFlowNets. Leveraging these insights, we further propose a novel rectified policy evaluation (RPE) algorithm, which achieves the same reward-matching effect as GFlowNets, offering a new perspective. We compare RPE, MaxEnt RL, and GFlowNets in a number of benchmarks, and show that RPE achieves competitive results compared to previous approaches. This work sheds light on the previously unexplored connection between (non-MaxEnt) RL and GFlowNets, potentially opening new avenues for future research in both fields.
Bifurcated Generative Flow Networks
Jun 04, 2024

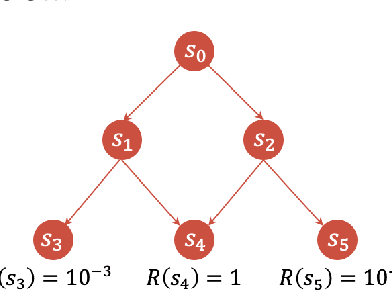
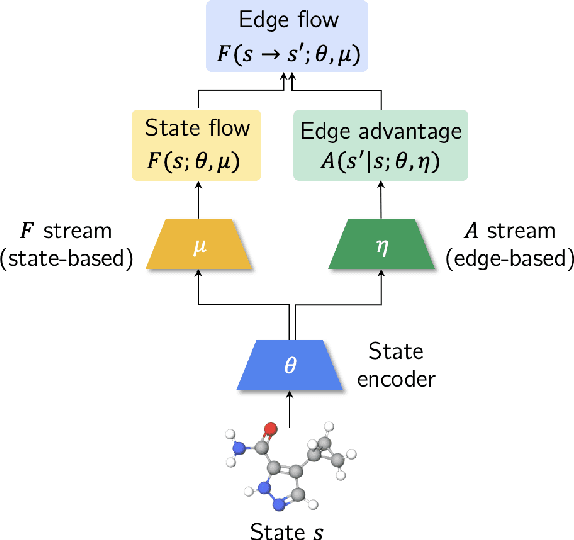
Generative Flow Networks (GFlowNets), a new family of probabilistic samplers, have recently emerged as a promising framework for learning stochastic policies that generate high-quality and diverse objects proportionally to their rewards. However, existing GFlowNets often suffer from low data efficiency due to the direct parameterization of edge flows or reliance on backward policies that may struggle to scale up to large action spaces. In this paper, we introduce Bifurcated GFlowNets (BN), a novel approach that employs a bifurcated architecture to factorize the flows into separate representations for state flows and edge-based flow allocation. This factorization enables BN to learn more efficiently from data and better handle large-scale problems while maintaining the convergence guarantee. Through extensive experiments on standard evaluation benchmarks, we demonstrate that BN significantly improves learning efficiency and effectiveness compared to strong baselines.
Looking Backward: Retrospective Backward Synthesis for Goal-Conditioned GFlowNets
Jun 03, 2024Generative Flow Networks (GFlowNets) are amortized sampling methods for learning a stochastic policy to sequentially generate compositional objects with probabilities proportional to their rewards. GFlowNets exhibit a remarkable ability to generate diverse sets of high-reward objects, in contrast to standard return maximization reinforcement learning approaches, which often converge to a single optimal solution. Recent works have arisen for learning goal-conditioned GFlowNets to acquire various useful properties, aiming to train a single GFlowNet capable of achieving different goals as the task specifies. However, training a goal-conditioned GFlowNet poses critical challenges due to extremely sparse rewards, which is further exacerbated in large state spaces. In this work, we propose a novel method named Retrospective Backward Synthesis (RBS) to address these challenges. Specifically, RBS synthesizes a new backward trajectory based on the backward policy in GFlowNets to enrich training trajectories with enhanced quality and diversity, thereby efficiently solving the sparse reward problem. Extensive empirical results show that our method improves sample efficiency by a large margin and outperforms strong baselines on various standard evaluation benchmarks.
Large-Scale Actionless Video Pre-Training via Discrete Diffusion for Efficient Policy Learning
Feb 22, 2024Learning a generalist embodied agent capable of completing multiple tasks poses challenges, primarily stemming from the scarcity of action-labeled robotic datasets. In contrast, a vast amount of human videos exist, capturing intricate tasks and interactions with the physical world. Promising prospects arise for utilizing actionless human videos for pre-training and transferring the knowledge to facilitate robot policy learning through limited robot demonstrations. In this paper, we introduce a novel framework that leverages a unified discrete diffusion to combine generative pre-training on human videos and policy fine-tuning on a small number of action-labeled robot videos. We start by compressing both human and robot videos into unified video tokens. In the pre-training stage, we employ a discrete diffusion model with a mask-and-replace diffusion strategy to predict future video tokens in the latent space. In the fine-tuning stage, we harness the imagined future videos to guide low-level action learning trained on a limited set of robot data. Experiments demonstrate that our method generates high-fidelity future videos for planning and enhances the fine-tuned policies compared to previous state-of-the-art approaches with superior generalization ability. Our project website is available at https://video-diff.github.io/.
QGFN: Controllable Greediness with Action Values
Feb 07, 2024



Generative Flow Networks (GFlowNets; GFNs) are a family of reward/energy-based generative methods for combinatorial objects, capable of generating diverse and high-utility samples. However, biasing GFNs towards producing high-utility samples is non-trivial. In this work, we leverage connections between GFNs and reinforcement learning (RL) and propose to combine the GFN policy with an action-value estimate, $Q$, to create greedier sampling policies which can be controlled by a mixing parameter. We show that several variants of the proposed method, QGFN, are able to improve on the number of high-reward samples generated in a variety of tasks without sacrificing diversity.