 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEsignBench: Exploring and Benchmarking DALL-E 3 for Imagining Visual Design
Oct 23, 2023We introduce DEsignBench, a text-to-image (T2I) generation benchmark tailored for visual design scenarios. Recent T2I models like DALL-E 3 and others, have demonstrated remarkable capabilities in generating photorealistic images that align closely with textual inputs. While the allure of creating visually captivating images is undeniable, our emphasis extends beyond mere aesthetic pleasure. We aim to investigate the potential of using these powerful models in authentic design contexts. In pursuit of this goal, we develop DEsignBench, which incorporates test samples designed to assess T2I models on both "design technical capability" and "design application scenario." Each of these two dimensions is supported by a diverse set of specific design categories. We explore DALL-E 3 together with other leading T2I models on DEsignBench, resulting in a comprehensive visual gallery for side-by-side comparisons. For DEsignBench benchmarking, we perform human evaluations on generated images in DEsignBench gallery, against the criteria of image-text alignment, visual aesthetic, and design creativity. Our evaluation also considers other specialized design capabilities, including text rendering, layout composition, color harmony, 3D design, and medium style. In addition to human evaluations, we introduce the first automatic image generation evaluator powered by GPT-4V. This evaluator provides ratings that align well with human judgments, while being easily replicable and cost-efficient. A high-resolution version is available at https://github.com/design-bench/design-bench.github.io/raw/main/designbench.pdf?download=
Idea2Img: Iterative Self-Refinement with GPT-4V(ision) for Automatic Image Design and Generation
Oct 12, 2023We introduce ``Idea to Image,'' a system that enables multimodal iterative self-refinement with GPT-4V(ision) for automatic image design and generation. Humans can quickly identify the characteristics of different text-to-image (T2I) models via iterative explorations. This enables them to efficiently convert their high-level generation ideas into effective T2I prompts that can produce good images. We investigate if systems based on large multimodal models (LMMs) can develop analogous multimodal self-refinement abilities that enable exploring unknown models or environments via self-refining tries. Idea2Img cyclically generates revised T2I prompts to synthesize draft images, and provides directional feedback for prompt revision, both conditioned on its memory of the probed T2I model's characteristics. The iterative self-refinement brings Idea2Img various advantages over vanilla T2I models. Notably, Idea2Img can process input ideas with interleaved image-text sequences, follow ideas with design instructions, and generate images of better semantic and visual qualities. The user preference study validates the efficacy of multimodal iterative self-refinement on automatic image design and generation.
OpenLEAF: Open-Domain Interleaved Image-Text Generation and Evaluation
Oct 11, 2023



This work investigates a challenging task named open-domain interleaved image-text generation, which generates interleaved texts and images following an input query. We propose a new interleaved generation framework based on prompting large-language models (LLMs) and pre-trained text-to-image (T2I) models, namely OpenLEAF. In OpenLEAF, the LLM generates textual descriptions, coordinates T2I models, creates visual prompts for generating images, and incorporates global contexts into the T2I models. This global context improves the entity and style consistencies of images in the interleaved generation. For model assessment, we first propose to use large multi-modal models (LMMs) to evaluate the entity and style consistencies of open-domain interleaved image-text sequences. According to the LMM evaluation on our constructed evaluation set, the proposed interleaved generation framework can generate high-quality image-text content for various domains and applications, such as how-to question answering, storytelling, graphical story rewriting, and webpage/poster generation tasks. Moreover, we validate the effectiveness of the proposed LMM evaluation technique with human assessment. We hope our proposed framework, benchmark, and LMM evaluation could help establish the intriguing interleaved image-text generation task.
The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)
Oct 11, 2023Large multimodal models (LMMs) extend large language models (LLMs) with multi-sensory skills, such as visual understanding, to achieve stronger generic intelligence. In this paper, we analyze the latest model, GPT-4V(ision), to deepen the understanding of LMMs. The analysis focuses on the intriguing tasks that GPT-4V can perform, containing test samples to probe the quality and genericity of GPT-4V's capabilities, its supported inputs and working modes, and the effective ways to prompt the model. In our approach to exploring GPT-4V, we curate and organize a collection of carefully designed qualitative samples spanning a variety of domains and tasks. Observations from these samples demonstrate that GPT-4V's unprecedented ability in processing arbitrarily interleaved multimodal inputs and the genericity of its capabilities together make GPT-4V a powerful multimodal generalist system. Furthermore, GPT-4V's unique capability of understanding visual markers drawn on input images can give rise to new human-computer interaction methods such as visual referring prompting. We conclude the report with in-depth discussions on the emerging application scenarios and the future research directions for GPT-4V-based systems. We hope that this preliminary exploration will inspire future research on the next-generation multimodal task formulation, new ways to exploit and enhance LMMs to solve real-world problems, and gaining better understanding of multimodal foundation models. Finally, we acknowledge that the model under our study is solely the product of OpenAI's innovative work, and they should be fully credited for its development. Please see the GPT-4V contributions paper for the authorship and credit attribution: https://cdn.openai.com/contributions/gpt-4v.pdf
Multimodal Foundation Models: From Specialists to General-Purpose Assistants
Sep 18, 2023This paper presents a comprehensive survey of the taxonomy and evolution of multimodal foundation models that demonstrate vision and vision-language capabilities, focusing on the transition from specialist models to general-purpose assistants. The research landscape encompasses five core topics, categorized into two classes. (i) We start with a survey of well-established research areas: multimodal foundation models pre-trained for specific purposes, including two topics -- methods of learning vision backbones for visual understanding and text-to-image generation. (ii) Then, we present recent advances in exploratory, open research areas: multimodal foundation models that aim to play the role of general-purpose assistants, including three topics -- unified vision models inspired by large language models (LLMs), end-to-end training of multimodal LLMs, and chaining multimodal tools with LLMs. The target audiences of the paper are researchers, graduate students, and professionals in computer vision and vision-language multimodal communities who are eager to learn the basics and recent advances in multimodal foundation models.
ORES: Open-vocabulary Responsible Visual Synthesis
Aug 26, 2023



Avoiding synthesizing specific visual concepts is an essential challenge in responsible visual synthesis. However, the visual concept that needs to be avoided for responsible visual synthesis tends to be diverse, depending on the region, context, and usage scenarios. In this work, we formalize a new task, Open-vocabulary Responsible Visual Synthesis (ORES), where the synthesis model is able to avoid forbidden visual concepts while allowing users to input any desired content. To address this problem, we present a Two-stage Intervention (TIN) framework. By introducing 1) rewriting with learnable instruction through a large-scale language model (LLM) and 2) synthesizing with prompt intervention on a diffusion synthesis model, it can effectively synthesize images avoiding any concepts but following the user's query as much as possible. To evaluate on ORES, we provide a publicly available dataset, baseline models, and benchmark. Experimental results demonstrate the effectiveness of our method in reducing risks of image generation. Our work highlights the potential of LLMs in responsible visual synthesis. Our code and dataset is public available.
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Aug 04, 2023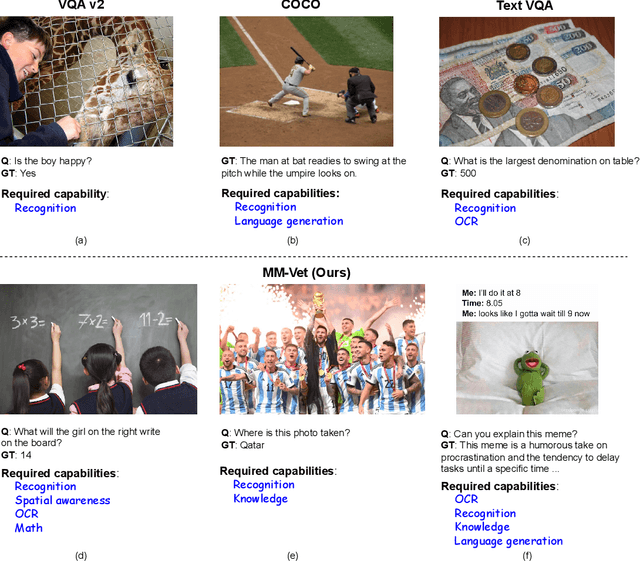

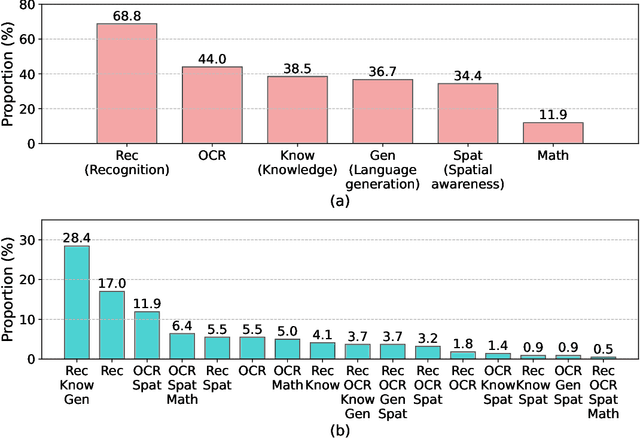
We propose MM-Vet, an evaluation benchmark that examines large multimodal models (LMMs) on complicated multimodal tasks. Recent LMMs have shown various intriguing abilities, such as solving math problems written on the blackboard, reasoning about events and celebrities in news images, and explaining visual jokes. Rapid model advancements pose challenges to evaluation benchmark development. Problems include: (1) How to systematically structure and evaluate the complicated multimodal tasks; (2) How to design evaluation metrics that work well across question and answer types; and (3) How to give model insights beyond a simple performance ranking. To this end, we present MM-Vet, designed based on the insight that the intriguing ability to solve complicated tasks is often achieved by a generalist model being able to integrate different core vision-language (VL) capabilities. MM-Vet defines 6 core VL capabilities and examines the 16 integrations of interest derived from the capability combination. For evaluation metrics, we propose an LLM-based evaluator for open-ended outputs. The evaluator enables the evaluation across different question types and answer styles, resulting in a unified scoring metric. We evaluate representative LMMs on MM-Vet, providing insights into the capabilities of different LMM system paradigms and models. Code and data are available at https://github.com/yuweihao/MM-Vet.
Spatial-Frequency U-Net for Denoising Diffusion Probabilistic Models
Jul 27, 2023In this paper, we study the denoising diffusion probabilistic model (DDPM) in wavelet space, instead of pixel space, for visual synthesis. Considering the wavelet transform represents the image in spatial and frequency domains, we carefully design a novel architecture SFUNet to effectively capture the correlation for both domains. Specifically, in the standard denoising U-Net for pixel data, we supplement the 2D convolutions and spatial-only attention layers with our spatial frequency-aware convolution and attention modules to jointly model the complementary information from spatial and frequency domains in wavelet data. Our new architecture can be used as a drop-in replacement to the pixel-based network and is compatible with the vanilla DDPM training process. By explicitly modeling the wavelet signals, we find our model is able to generate images with higher quality on CIFAR-10, FFHQ, LSUN-Bedroom, and LSUN-Church datasets, than the pixel-based counterpart.
DisCo: Disentangled Control for Referring Human Dance Generation in Real World
Jun 30, 2023Generative AI has made significant strides in computer vision, particularly in image/video synthesis conditioned on text descriptions. Despite the advancements, it remains challenging especially in the generation of human-centric content such as dance synthesis. Existing dance synthesis methods struggle with the gap between synthesized content and real-world dance scenarios. In this paper, we define a new problem setting: Referring Human Dance Generation, which focuses on real-world dance scenarios with three important properties: (i) Faithfulness: the synthesis should retain the appearance of both human subject foreground and background from the reference image, and precisely follow the target pose; (ii) Generalizability: the model should generalize to unseen human subjects, backgrounds, and poses; (iii) Compositionality: it should allow for composition of seen/unseen subjects, backgrounds, and poses from different sources. To address these challenges, we introduce a novel approach, DISCO, which includes a novel model architecture with disentangled control to improve the faithfulness and compositionality of dance synthesis, and an effective human attribute pre-training for better generalizability to unseen humans. Extensive qualitative and quantitative results demonstrate that DISCO can generate high-quality human dance images and videos with diverse appearances and flexible motions. Code, demo, video and visualization are available at: https://disco-dance.github.io/.
Aligning Large Multi-Modal Model with Robust Instruction Tuning
Jun 26, 2023Despite the promising progress in multi-modal tasks, current large multi-modal models (LMM) are prone to hallucinating inconsistent descriptions with respect to the associated image and human instructions. This paper addresses this issue by introducing the first large and diverse visual instruction tuning dataset, named Large-scale Robust Visual (LRV)-Instruction. Our dataset consists of 120k visual instructions generated by GPT4, covering 16 vision-and-language tasks with open-ended instructions and answers. Unlike existing studies that primarily focus on positive instruction samples, we design LRV-Instruction to include both positive and negative instructions for more robust visual instruction tuning. Our negative instructions are designed at two semantic levels: (i) Nonexistent Element Manipulation and (ii) Existent Element Manipulation. To efficiently measure the hallucination generated by LMMs, we propose GPT4-Assisted Visual Instruction Evaluation (GAVIE), a novel approach to evaluate visual instruction tuning without the need for human-annotated groundtruth answers and can adapt to diverse instruction formats. We conduct comprehensive experiments to investigate the hallucination of LMMs. Our results demonstrate that existing LMMs exhibit significant hallucination when presented with our negative instructions, particularly with Existent Element Manipulation instructions. Moreover, by finetuning MiniGPT4 on LRV-Instruction, we successfully mitigate hallucination while improving performance on public datasets using less training data compared to state-of-the-art methods. Additionally, we observed that a balanced ratio of positive and negative instances in the training data leads to a more robust model. Our project link is available at https://fuxiaoliu.github.io/LRV/.