 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQue2Engage: Embedding-based Retrieval for Relevant and Engaging Products at Facebook Marketplace
Feb 21, 2023Embedding-based Retrieval (EBR) in e-commerce search is a powerful search retrieval technique to address semantic matches between search queries and products. However, commercial search engines like Facebook Marketplace Search are complex multi-stage systems optimized for multiple business objectives. At Facebook Marketplace, search retrieval focuses on matching search queries with relevant products, while search ranking puts more emphasis on contextual signals to up-rank the more engaging products. As a result, the end-to-end searcher experience is a function of both relevance and engagement, and the interaction between different stages of the system. This presents challenges to EBR systems in order to optimize for better searcher experiences. In this paper we presents Que2Engage, a search EBR system built towards bridging the gap between retrieval and ranking for end-to-end optimizations. Que2Engage takes a multimodal & multitask approach to infuse contextual information into the retrieval stage and to balance different business objectives. We show the effectiveness of our approach via a multitask evaluation framework and thorough baseline comparisons and ablation studies. Que2Engage is deployed on Facebook Marketplace Search and shows significant improvements in searcher engagement in two weeks of A/B testing.
CiT: Curation in Training for Effective Vision-Language Data
Jan 05, 2023



Large vision-language models are generally applicable to many downstream tasks, but come at an exorbitant training cost that only large institutions can afford. This paper trades generality for efficiency and presents Curation in Training (CiT), a simple and efficient vision-text learning algorithm that couples a data objective into training. CiT automatically yields quality data to speed-up contrastive image-text training and alleviates the need for an offline data filtering pipeline, allowing broad data sources (including raw image-text pairs from the web). CiT contains two loops: an outer loop curating the training data and an inner loop consuming the curated training data. The text encoder connects the two loops. Given metadata for tasks of interest, e.g., class names, and a large pool of image-text pairs, CiT alternatively selects relevant training data from the pool by measuring the similarity of their text embeddings and embeddings of the metadata. In our experiments, we observe that CiT can speed up training by over an order of magnitude, especially if the raw data size is large.
Tell Me What Happened: Unifying Text-guided Video Completion via Multimodal Masked Video Generation
Nov 23, 2022Generating a video given the first several static frames is challenging as it anticipates reasonable future frames with temporal coherence. Besides video prediction, the ability to rewind from the last frame or infilling between the head and tail is also crucial, but they have rarely been explored for video completion. Since there could be different outcomes from the hints of just a few frames, a system that can follow natural language to perform video completion may significantly improve controllability. Inspired by this, we introduce a novel task, text-guided video completion (TVC), which requests the model to generate a video from partial frames guided by an instruction. We then propose Multimodal Masked Video Generation (MMVG) to address this TVC task. During training, MMVG discretizes the video frames into visual tokens and masks most of them to perform video completion from any time point. At inference time, a single MMVG model can address all 3 cases of TVC, including video prediction, rewind, and infilling, by applying corresponding masking conditions. We evaluate MMVG in various video scenarios, including egocentric, animation, and gaming. Extensive experimental results indicate that MMVG is effective in generating high-quality visual appearances with text guidance for TVC.
FaD-VLP: Fashion Vision-and-Language Pre-training towards Unified Retrieval and Captioning
Oct 26, 2022



Multimodal tasks in the fashion domain have significant potential for e-commerce, but involve challenging vision-and-language learning problems - e.g., retrieving a fashion item given a reference image plus text feedback from a user. Prior works on multimodal fashion tasks have either been limited by the data in individual benchmarks, or have leveraged generic vision-and-language pre-training but have not taken advantage of the characteristics of fashion data. Additionally, these works have mainly been restricted to multimodal understanding tasks. To address these gaps, we make two key contributions. First, we propose a novel fashion-specific pre-training framework based on weakly-supervised triplets constructed from fashion image-text pairs. We show the triplet-based tasks are an effective addition to standard multimodal pre-training tasks. Second, we propose a flexible decoder-based model architecture capable of both fashion retrieval and captioning tasks. Together, our model design and pre-training approach are competitive on a diverse set of fashion tasks, including cross-modal retrieval, image retrieval with text feedback, image captioning, relative image captioning, and multimodal categorization.
FashionViL: Fashion-Focused Vision-and-Language Representation Learning
Jul 17, 2022

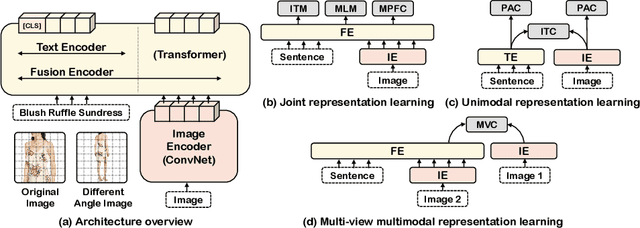
Large-scale Vision-and-Language (V+L) pre-training for representation learning has proven to be effective in boosting various downstream V+L tasks. However, when it comes to the fashion domain, existing V+L methods are inadequate as they overlook the unique characteristics of both the fashion V+L data and downstream tasks. In this work, we propose a novel fashion-focused V+L representation learning framework, dubbed as FashionViL. It contains two novel fashion-specific pre-training tasks designed particularly to exploit two intrinsic attributes with fashion V+L data. First, in contrast to other domains where a V+L data point contains only a single image-text pair, there could be multiple images in the fashion domain. We thus propose a Multi-View Contrastive Learning task for pulling closer the visual representation of one image to the compositional multimodal representation of another image+text. Second, fashion text (e.g., product description) often contains rich fine-grained concepts (attributes/noun phrases). To exploit this, a Pseudo-Attributes Classification task is introduced to encourage the learned unimodal (visual/textual) representations of the same concept to be adjacent. Further, fashion V+L tasks uniquely include ones that do not conform to the common one-stream or two-stream architectures (e.g., text-guided image retrieval). We thus propose a flexible, versatile V+L model architecture consisting of a modality-agnostic Transformer so that it can be flexibly adapted to any downstream tasks. Extensive experiments show that our FashionViL achieves a new state of the art across five downstream tasks. Code is available at https://github.com/BrandonHanx/mmf.
GEB+: A benchmark for generic event boundary captioning, grounding and text-based retrieval
Apr 10, 2022



Cognitive science has shown that humans perceive videos in terms of events separated by state changes of dominant subjects. State changes trigger new events and are one of the most useful among the large amount of redundant information perceived. However, previous research focuses on the overall understanding of segments without evaluating the fine-grained status changes inside. In this paper, we introduce a new dataset called Kinetic-GEBC (Generic Event Boundary Captioning). The dataset consists of over 170k boundaries associated with captions describing status changes in the generic events in 12K videos. Upon this new dataset, we propose three tasks supporting the development of a more fine-grained, robust, and human-like understanding of videos through status changes. We evaluate many representative baselines in our dataset, where we also design a new TPD (Temporal-based Pairwise Difference) Modeling method for current state-of-the-art backbones and achieve significant performance improvements. Besides, the results show there are still formidable challenges for current methods in the utilization of different granularities, representation of visual difference, and the accurate localization of status changes. Further analysis shows that our dataset can drive developing more powerful methods to understand status changes and thus improve video level comprehension.
LoopITR: Combining Dual and Cross Encoder Architectures for Image-Text Retrieval
Mar 10, 2022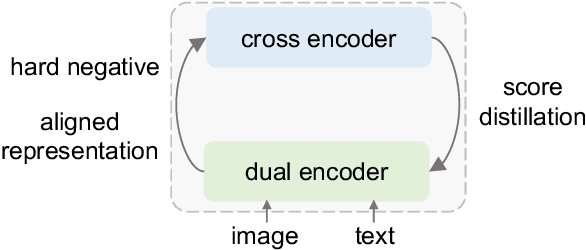
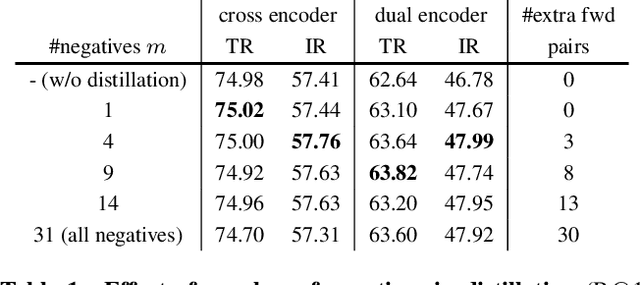

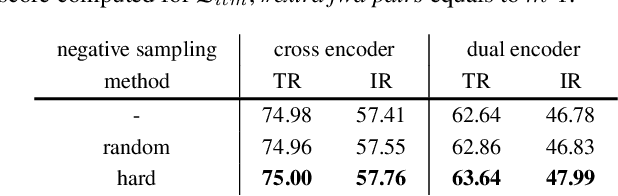
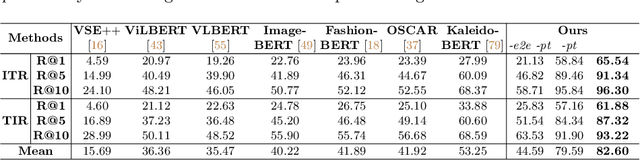
Dual encoders and cross encoders have been widely used for image-text retrieval. Between the two, the dual encoder encodes the image and text independently followed by a dot product, while the cross encoder jointly feeds image and text as the input and performs dense multi-modal fusion. These two architectures are typically modeled separately without interaction. In this work, we propose LoopITR, which combines them in the same network for joint learning. Specifically, we let the dual encoder provide hard negatives to the cross encoder, and use the more discriminative cross encoder to distill its predictions back to the dual encoder. Both steps are efficiently performed together in the same model. Our work centers on empirical analyses of this combined architecture, putting the main focus on the design of the distillation objective. Our experimental results highlight the benefits of training the two encoders in the same network, and demonstrate that distillation can be quite effective with just a few hard negative examples. Experiments on two standard datasets (Flickr30K and COCO) show our approach achieves state-of-the-art dual encoder performance when compared with approaches using a similar amount of data.
Unsupervised Vision-and-Language Pre-training via Retrieval-based Multi-Granular Alignment
Mar 01, 2022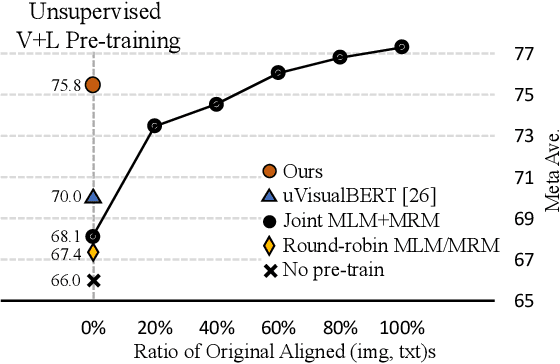
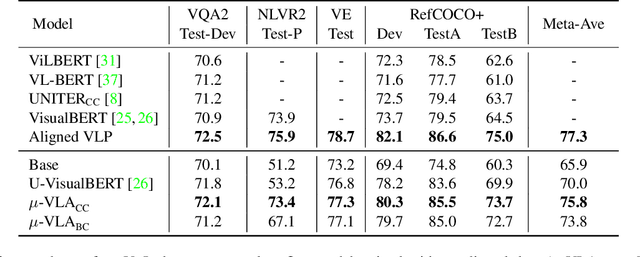
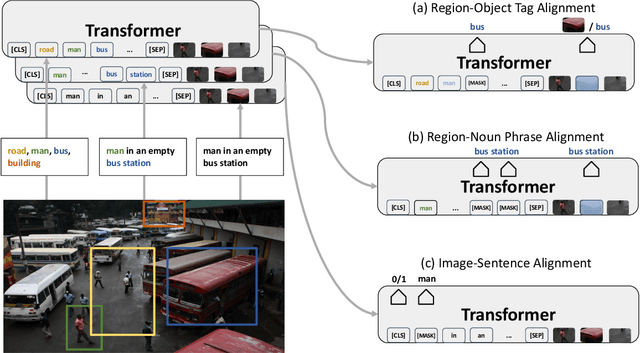
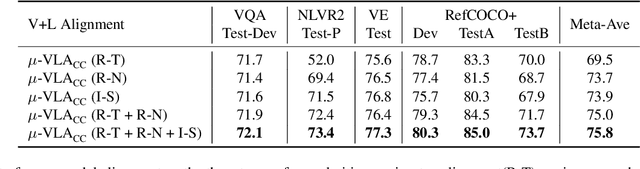
Vision-and-Language (V+L) pre-training models have achieved tremendous success in recent years on various multi-modal benchmarks. However, the majority of existing models require pre-training on a large set of parallel image-text data, which is costly to collect, compared to image-only or text-only data. In this paper, we explore unsupervised Vision-and-Language pre-training (UVLP) to learn the cross-modal representation from non-parallel image and text datasets. We found two key factors that lead to good unsupervised V+L pre-training without parallel data: (i) joint image-and-text input (ii) overall image-text alignment (even for non-parallel data). Accordingly, we propose a novel unsupervised V+L pre-training curriculum for non-parallel texts and images. We first construct a weakly aligned image-text corpus via a retrieval-based approach, then apply a set of multi-granular alignment pre-training tasks, including region-to-tag, region-to-phrase, and image-to-sentence alignment, to bridge the gap between the two modalities. A comprehensive ablation study shows each granularity is helpful to learn a stronger pre-trained model. We adapt our pre-trained model to a set of V+L downstream tasks, including VQA, NLVR2, Visual Entailment, and RefCOCO+. Our model achieves the state-of-art performance in all these tasks under the unsupervised setting.
CommerceMM: Large-Scale Commerce MultiModal Representation Learning with Omni Retrieval
Feb 15, 2022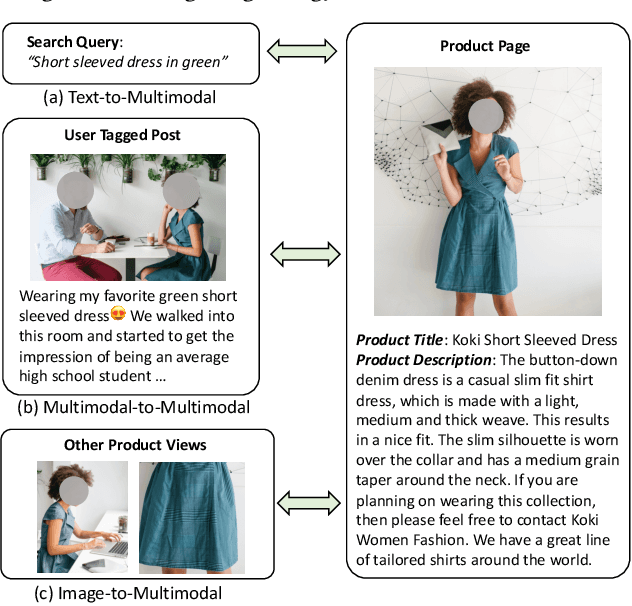
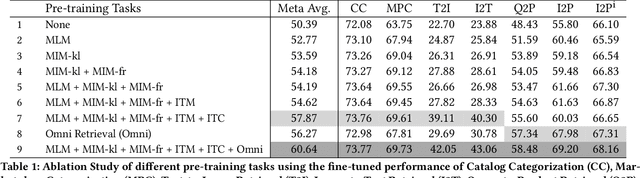
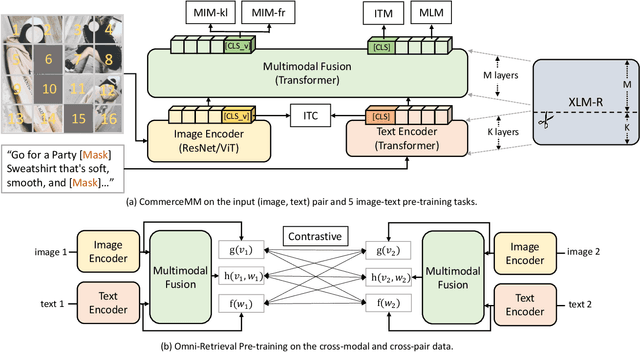

We introduce CommerceMM - a multimodal model capable of providing a diverse and granular understanding of commerce topics associated to the given piece of content (image, text, image+text), and having the capability to generalize to a wide range of tasks, including Multimodal Categorization, Image-Text Retrieval, Query-to-Product Retrieval, Image-to-Product Retrieval, etc. We follow the pre-training + fine-tuning training regime and present 5 effective pre-training tasks on image-text pairs. To embrace more common and diverse commerce data with text-to-multimodal, image-to-multimodal, and multimodal-to-multimodal mapping, we propose another 9 novel cross-modal and cross-pair retrieval tasks, called Omni-Retrieval pre-training. The pre-training is conducted in an efficient manner with only two forward/backward updates for the combined 14 tasks. Extensive experiments and analysis show the effectiveness of each task. When combining all pre-training tasks, our model achieves state-of-the-art performance on 7 commerce-related downstream tasks after fine-tuning. Additionally, we propose a novel approach of modality randomization to dynamically adjust our model under different efficiency constraints.
VALUE: A Multi-Task Benchmark for Video-and-Language Understanding Evaluation
Jun 08, 2021

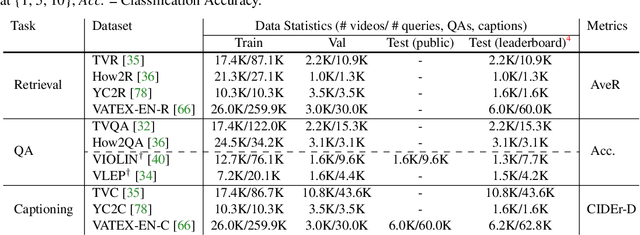
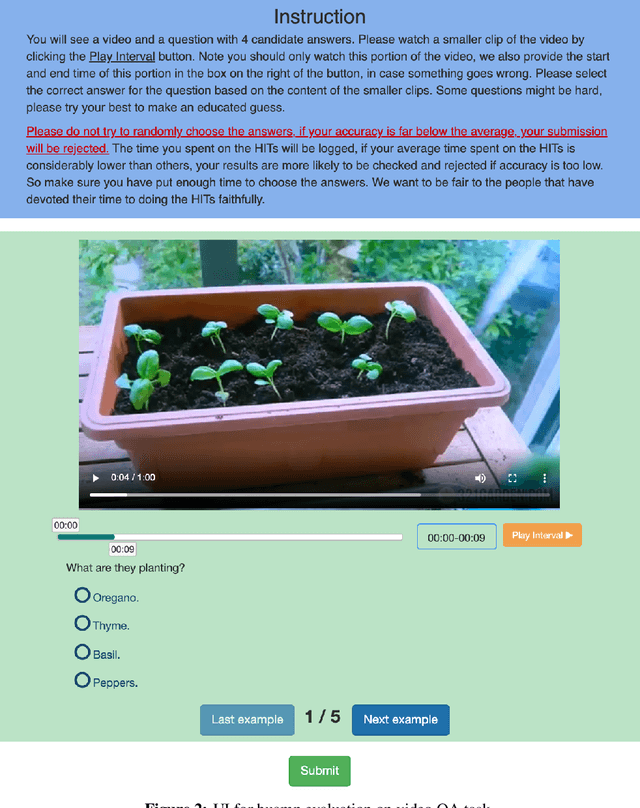
Most existing video-and-language (VidL) research focuses on a single dataset, or multiple datasets of a single task. In reality, a truly useful VidL system is expected to be easily generalizable to diverse tasks, domains, and datasets. To facilitate the evaluation of such systems, we introduce Video-And-Language Understanding Evaluation (VALUE) benchmark, an assemblage of 11 VidL datasets over 3 popular tasks: (i) text-to-video retrieval; (ii) video question answering; and (iii) video captioning. VALUE benchmark aims to cover a broad range of video genres, video lengths, data volumes, and task difficulty levels. Rather than focusing on single-channel videos with visual information only, VALUE promotes models that leverage information from both video frames and their associated subtitles, as well as models that share knowledge across multiple tasks. We evaluate various baseline methods with and without large-scale VidL pre-training, and systematically investigate the impact of video input channels, fusion methods, and different video representations. We also study the transferability between tasks, and conduct multi-task learning under different settings. The significant gap between our best model and human performance calls for future study for advanced VidL models. VALUE is available at https://value-leaderboard.github.io/.