 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClusterability-Based Assessment of Potentially Noisy Views for Multi-View Clustering
Apr 20, 2026In multi-view clustering, the quality of different views may vary substantially, and low-quality or degraded views can impair overall clustering performance. However, existing studies mainly address this issue within the clustering process through view weighting or noise-robust optimization, while paying limited attention to data-level assessment before clustering. In this paper, we study the problem of pre-clustering noisy-view analysis in multi-view data from a clusterability perspective. To this end, we propose a Multi-View Clusterability Score (MVCS), which quantifies the strength of latent cluster-related structures in multi-view data through three complementary components: per-view structural clusterability, joint-space clusterability, and cross-view neighborhood consistency. To the best of our knowledge, this is the first clusterability score specifically designed for multi-view data. We further use it to perform potentially noisy view analysis and noisy-view detection before clustering. Extensive experiments on real-world datasets demonstrate that noisy views can significantly degrade clustering performance, and that, compared with existing clusterability measures designed for single-view data, the proposed method more effectively supports noisy-view analysis and detection.
Adversarial Fair Multi-View Clustering
Aug 06, 2025Cluster analysis is a fundamental problem in data mining and machine learning. In recent years, multi-view clustering has attracted increasing attention due to its ability to integrate complementary information from multiple views. However, existing methods primarily focus on clustering performance, while fairness-a critical concern in human-centered applications-has been largely overlooked. Although recent studies have explored group fairness in multi-view clustering, most methods impose explicit regularization on cluster assignments, relying on the alignment between sensitive attributes and the underlying cluster structure. However, this assumption often fails in practice and can degrade clustering performance. In this paper, we propose an adversarial fair multi-view clustering (AFMVC) framework that integrates fairness learning into the representation learning process. Specifically, our method employs adversarial training to fundamentally remove sensitive attribute information from learned features, ensuring that the resulting cluster assignments are unaffected by it. Furthermore, we theoretically prove that aligning view-specific clustering assignments with a fairness-invariant consensus distribution via KL divergence preserves clustering consistency without significantly compromising fairness, thereby providing additional theoretical guarantees for our framework. Extensive experiments on data sets with fairness constraints demonstrate that AFMVC achieves superior fairness and competitive clustering performance compared to existing multi-view clustering and fairness-aware clustering methods.
Higher-order Structure Based Anomaly Detection on Attributed Networks
Jun 07, 2024



Anomaly detection (such as telecom fraud detection and medical image detection) has attracted the increasing attention of people. The complex interaction between multiple entities widely exists in the network, which can reflect specific human behavior patterns. Such patterns can be modeled by higher-order network structures, thus benefiting anomaly detection on attributed networks. However, due to the lack of an effective mechanism in most existing graph learning methods, these complex interaction patterns fail to be applied in detecting anomalies, hindering the progress of anomaly detection to some extent. In order to address the aforementioned issue, we present a higher-order structure based anomaly detection (GUIDE) method. We exploit attribute autoencoder and structure autoencoder to reconstruct node attributes and higher-order structures, respectively. Moreover, we design a graph attention layer to evaluate the significance of neighbors to nodes through their higher-order structure differences. Finally, we leverage node attribute and higher-order structure reconstruction errors to find anomalies. Extensive experiments on five real-world datasets (i.e., ACM, Citation, Cora, DBLP, and Pubmed) are implemented to verify the effectiveness of GUIDE. Experimental results in terms of ROC-AUC, PR-AUC, and Recall@K show that GUIDE significantly outperforms the state-of-art methods.
Interpretable Multi-View Clustering
May 04, 2024Multi-view clustering has become a significant area of research, with numerous methods proposed over the past decades to enhance clustering accuracy. However, in many real-world applications, it is crucial to demonstrate a clear decision-making process-specifically, explaining why samples are assigned to particular clusters. Consequently, there remains a notable gap in developing interpretable methods for clustering multi-view data. To fill this crucial gap, we make the first attempt towards this direction by introducing an interpretable multi-view clustering framework. Our method begins by extracting embedded features from each view and generates pseudo-labels to guide the initial construction of the decision tree. Subsequently, it iteratively optimizes the feature representation for each view along with refining the interpretable decision tree. Experimental results on real datasets demonstrate that our method not only provides a transparent clustering process for multi-view data but also delivers performance comparable to state-of-the-art multi-view clustering methods. To the best of our knowledge, this is the first effort to design an interpretable clustering framework specifically for multi-view data, opening a new avenue in this field.
OFFER: A Motif Dimensional Framework for Network Representation Learning
Aug 27, 2020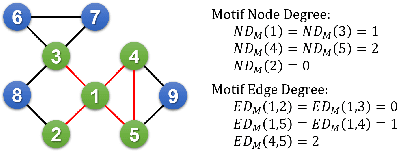
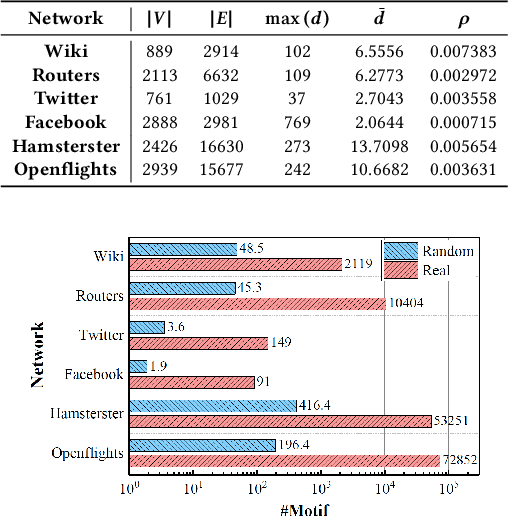
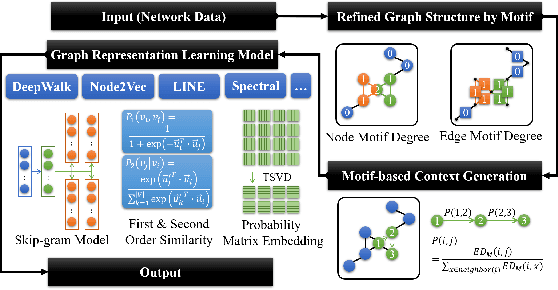
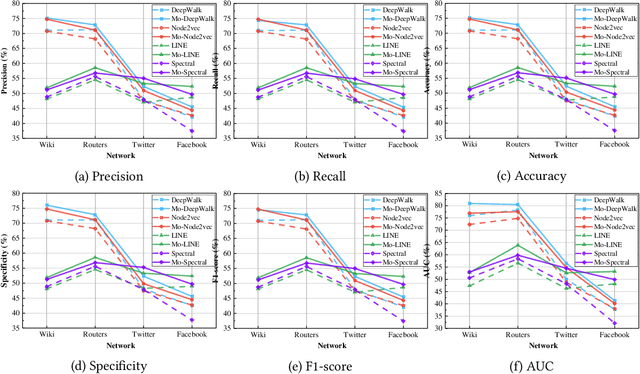
Aiming at better representing multivariate relationships, this paper investigates a motif dimensional framework for higher-order graph learning. The graph learning effectiveness can be improved through OFFER. The proposed framework mainly aims at accelerating and improving higher-order graph learning results. We apply the acceleration procedure from the dimensional of network motifs. Specifically, the refined degree for nodes and edges are conducted in two stages: (1) employ motif degree of nodes to refine the adjacency matrix of the network; and (2) employ motif degree of edges to refine the transition probability matrix in the learning process. In order to assess the efficiency of the proposed framework, four popular network representation algorithms are modified and examined. By evaluating the performance of OFFER, both link prediction results and clustering results demonstrate that the graph representation learning algorithms enhanced with OFFER consistently outperform the original algorithms with higher efficiency.