 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternal Language Model Training for Domain-Adaptive End-to-End Speech Recognition
Feb 02, 2021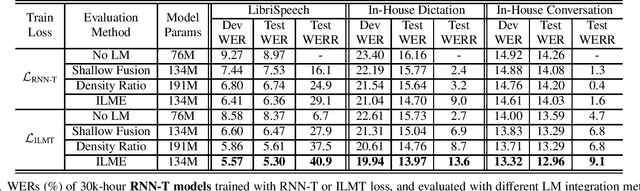
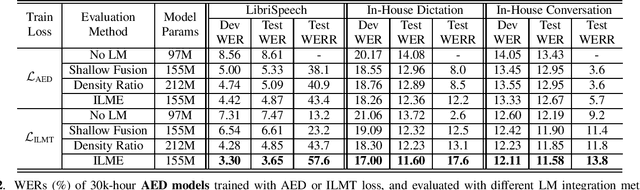
The efficacy of external language model (LM) integration with existing end-to-end (E2E) automatic speech recognition (ASR) systems can be improved significantly using the internal language model estimation (ILME) method. In this method, the internal LM score is subtracted from the score obtained by interpolating the E2E score with the external LM score, during inference. To improve the ILME-based inference, we propose an internal LM training (ILMT) method to minimize an additional internal LM loss by updating only the E2E model components that affect the internal LM estimation. ILMT encourages the E2E model to form a standalone LM inside its existing components, without sacrificing ASR accuracy. After ILMT, the more modular E2E model with matched training and inference criteria enables a more thorough elimination of the source-domain internal LM, and therefore leads to a more effective integration of the target-domain external LM. Experimented with 30K-hour trained recurrent neural network transducer and attention-based encoder-decoder models, ILMT with ILME-based inference achieves up to 31.5% and 11.4% relative word error rate reductions from standard E2E training with Shallow Fusion on out-of-domain LibriSpeech and in-domain Microsoft production test sets, respectively.
* 5 pages, ICASSP 2021
Streaming end-to-end multi-talker speech recognition
Nov 26, 2020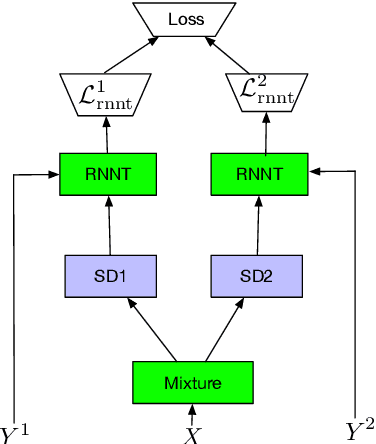

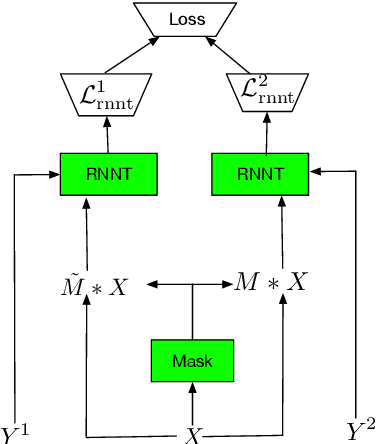

End-to-end multi-talker speech recognition is an emerging research trend in the speech community due to its vast potential in applications such as conversation and meeting transcriptions. To the best of our knowledge, all existing research works are constrained in the offline scenario. In this work, we propose the Streaming Unmixing and Recognition Transducer (SURT) for end-to-end multi-talker speech recognition. Our model employs the Recurrent Neural Network Transducer as the backbone that can meet various latency constraints. We study two different model architectures that are based on a speaker-differentiator encoder and a mask encoder respectively. To train this model, we investigate the widely used Permutation Invariant Training (PIT) approach and the recently introduced Heuristic Error Assignment Training (HEAT) approach. Based on experiments on the publicly available LibriSpeechMix dataset, we show that HEAT can achieve better accuracy compared with PIT, and the SURT model with 120 milliseconds algorithmic latency constraint compares favorably with the offline sequence-to-sequence based baseline model in terms of accuracy.
Minimum Bayes Risk Training for End-to-End Speaker-Attributed ASR
Nov 03, 2020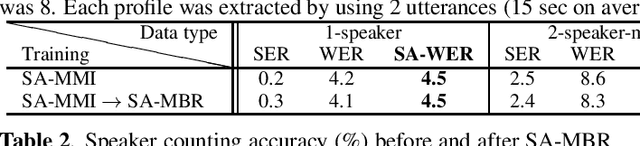
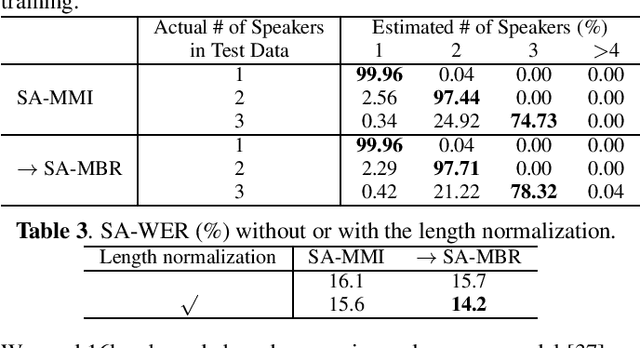
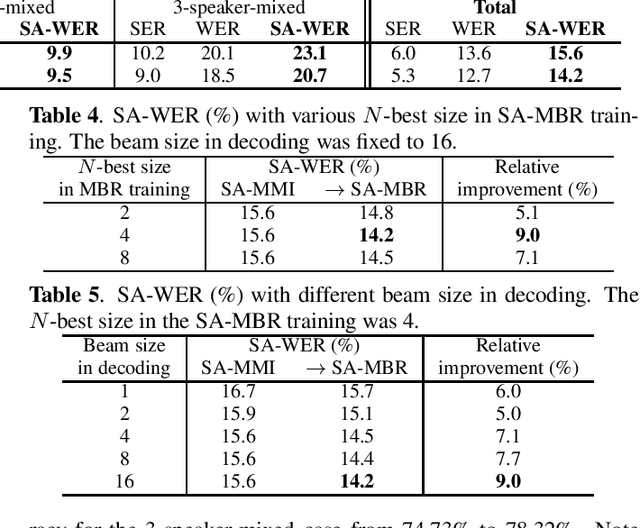
Recently, an end-to-end speaker-attributed automatic speech recognition (E2E SA-ASR) model was proposed as a joint model of speaker counting, speech recognition and speaker identification for monaural overlapped speech. In the previous study, the model parameters were trained based on the speaker-attributed maximum mutual information (SA-MMI) criterion, with which the joint posterior probability for multi-talker transcription and speaker identification are maximized over training data. Although SA-MMI training showed promising results for overlapped speech consisting of various numbers of speakers, the training criterion was not directly linked to the final evaluation metric, i.e., speaker-attributed word error rate (SA-WER). In this paper, we propose a speaker-attributed minimum Bayes risk (SA-MBR) training method where the parameters are trained to directly minimize the expected SA-WER over the training data. Experiments using the LibriSpeech corpus show that the proposed SA-MBR training reduces the SA-WER by 9.0 % relative compared with the SA-MMI-trained model.
Internal Language Model Estimation for Domain-Adaptive End-to-End Speech Recognition
Nov 03, 2020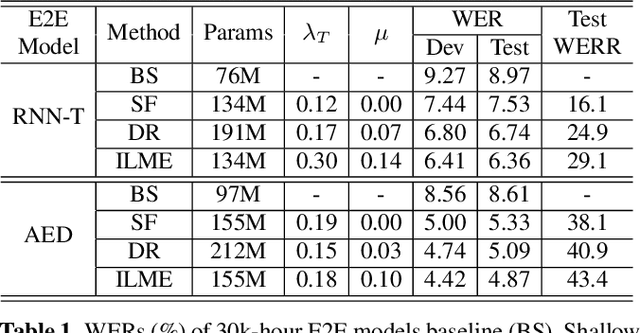
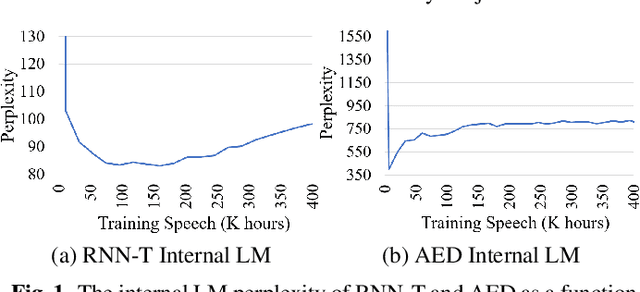
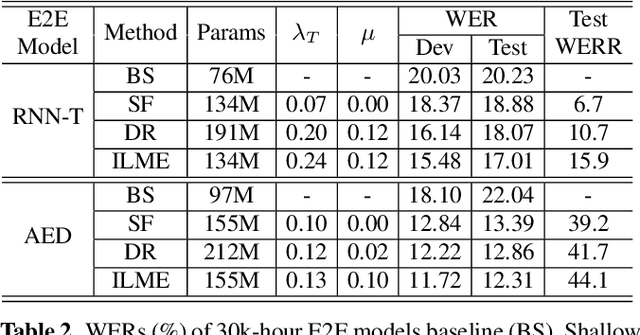
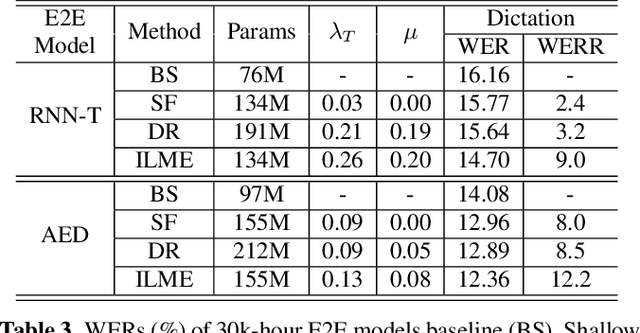
The external language models (LM) integration remains a challenging task for end-to-end (E2E) automatic speech recognition (ASR) which has no clear division between acoustic and language models. In this work, we propose an internal LM estimation (ILME) method to facilitate a more effective integration of the external LM with all pre-existing E2E models with no additional model training, including the most popular recurrent neural network transducer (RNN-T) and attention-based encoder-decoder (AED) models. Trained with audio-transcript pairs, an E2E model implicitly learns an internal LM that characterizes the training data in the source domain. With ILME, the internal LM scores of an E2E model are estimated and subtracted from the log-linear interpolation between the scores of the E2E model and the external LM. The internal LM scores are approximated as the output of an E2E model when eliminating its acoustic components. ILME can alleviate the domain mismatch between training and testing, or improve the multi-domain E2E ASR. Experimented with 30K-hour trained RNN-T and AED models, ILME achieves up to 15.5% and 6.8% relative word error rate reductions from Shallow Fusion on out-of-domain LibriSpeech and in-domain Microsoft production test sets, respectively.
* 8 pages, 2 figures, SLT 2021
On Minimum Word Error Rate Training of the Hybrid Autoregressive Transducer
Oct 23, 2020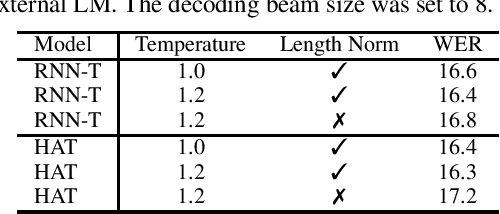
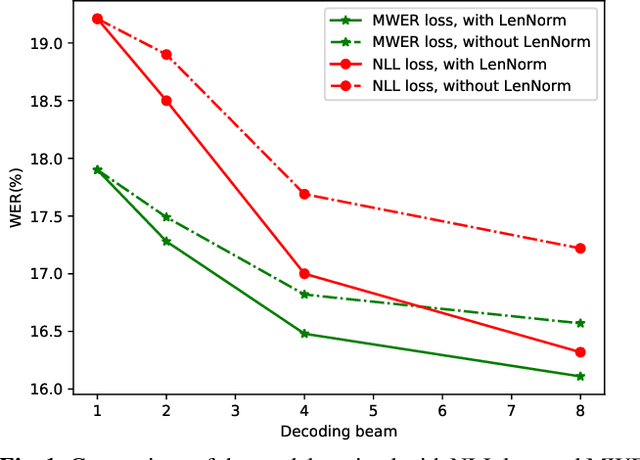
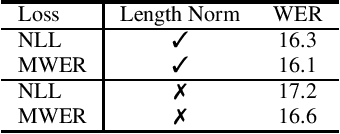
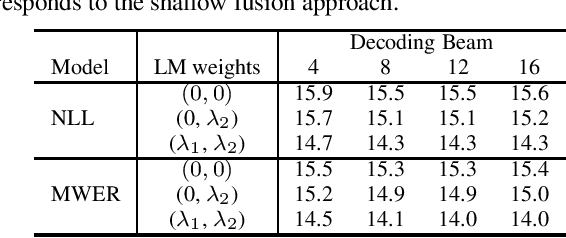
Hybrid Autoregressive Transducer (HAT) is a recently proposed end-to-end acoustic model that extends the standard Recurrent Neural Network Transducer (RNN-T) for the purpose of the external language model (LM) fusion. In HAT, the blank probability and the label probability are estimated using two separate probability distributions, which provides a more accurate solution for internal LM score estimation, and thus works better when combining with an external LM. Previous work mainly focuses on HAT model training with the negative log-likelihood loss, while in this paper, we study the minimum word error rate (MWER) training of HAT -- a criterion that is closer to the evaluation metric for speech recognition, and has been successfully applied to other types of end-to-end models such as sequence-to-sequence (S2S) and RNN-T models. From experiments with around 30,000 hours of training data, we show that MWER training can improve the accuracy of HAT models, while at the same time, improving the robustness of the model against the decoding hyper-parameters such as length normalization and decoding beam during inference.
Exploring Transformers for Large-Scale Speech Recognition
May 19, 2020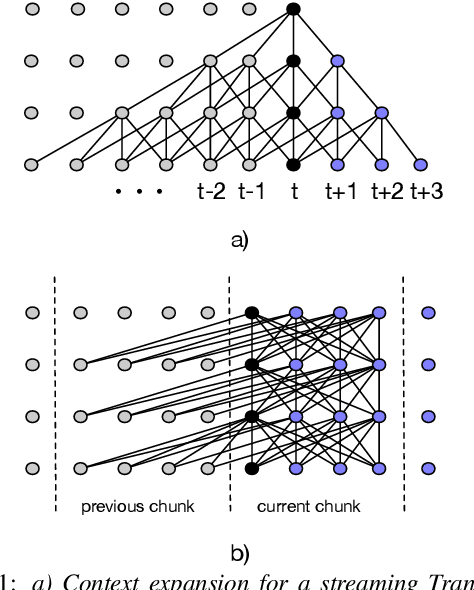
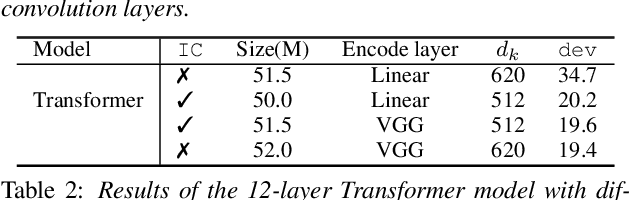
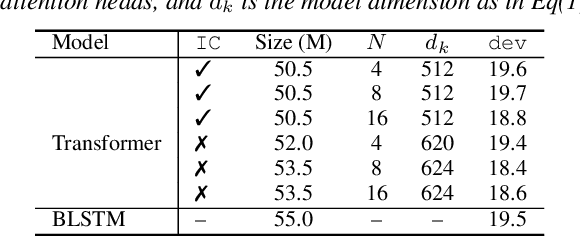
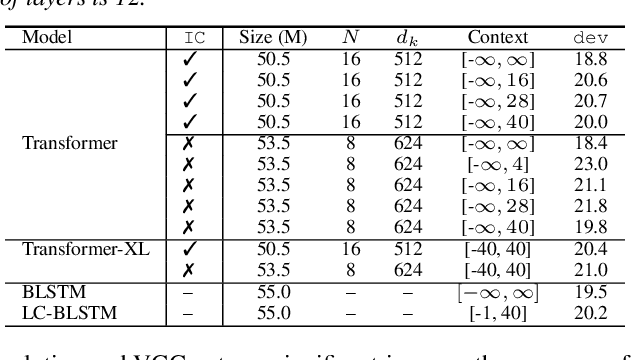
While recurrent neural networks still largely define state-of-the-art speech recognition systems, the Transformer network has been proven to be a competitive alternative, especially in the offline condition. Most studies with Transformers have been constrained in a relatively small scale setting, and some forms of data argumentation approaches are usually applied to combat the data sparsity issue. In this paper, we aim at understanding the behaviors of Transformers in the large-scale speech recognition setting, where we have used around 65,000 hours of training data. We investigated various aspects on scaling up Transformers, including model initialization, warmup training as well as different Layer Normalization strategies. In the streaming condition, we compared the widely used attention mask based future context lookahead approach to the Transformer-XL network. From our experiments, we show that Transformers can achieve around 6% relative word error rate (WER) reduction compared to the BLSTM baseline in the offline fashion, while in the streaming fashion, Transformer-XL is comparable to LC-BLSTM with 800 millisecond latency constraint.
Minimum Latency Training Strategies for Streaming Sequence-to-Sequence ASR
May 15, 2020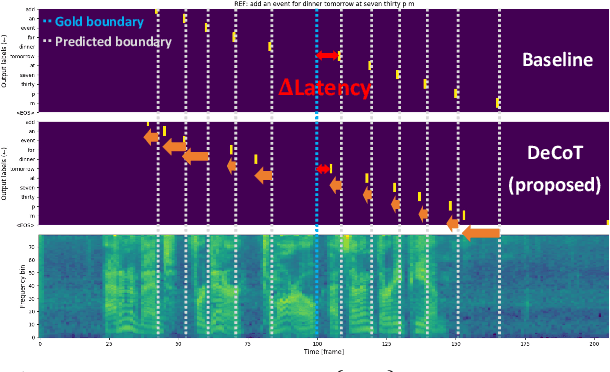

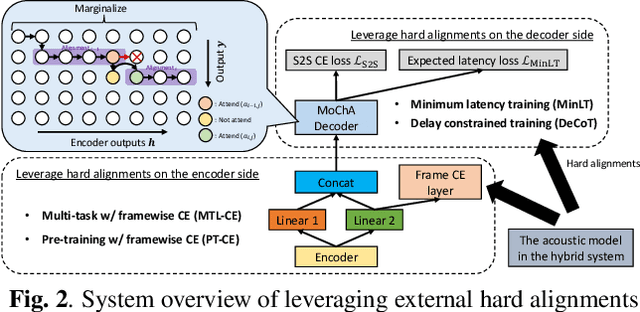
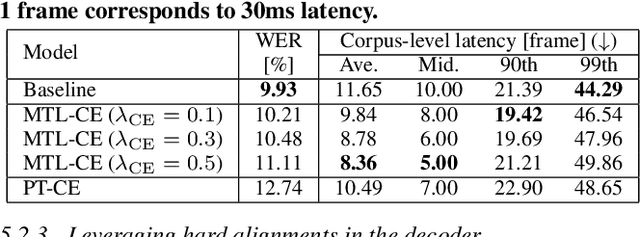
Recently, a few novel streaming attention-based sequence-to-sequence (S2S) models have been proposed to perform online speech recognition with linear-time decoding complexity. However, in these models, the decisions to generate tokens are delayed compared to the actual acoustic boundaries since their unidirectional encoders lack future information. This leads to an inevitable latency during inference. To alleviate this issue and reduce latency, we propose several strategies during training by leveraging external hard alignments extracted from the hybrid model. We investigate to utilize the alignments in both the encoder and the decoder. On the encoder side, (1) multi-task learning and (2) pre-training with the framewise classification task are studied. On the decoder side, we (3) remove inappropriate alignment paths beyond an acceptable latency during the alignment marginalization, and (4) directly minimize the differentiable expected latency loss. Experiments on the Cortana voice search task demonstrate that our proposed methods can significantly reduce the latency, and even improve the recognition accuracy in certain cases on the decoder side. We also present some analysis to understand the behaviors of streaming S2S models.
Exploring Pre-training with Alignments for RNN Transducer based End-to-End Speech Recognition
May 01, 2020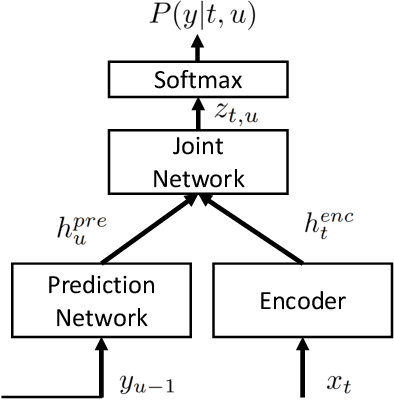

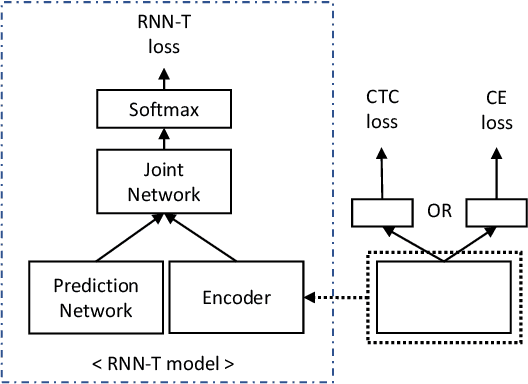
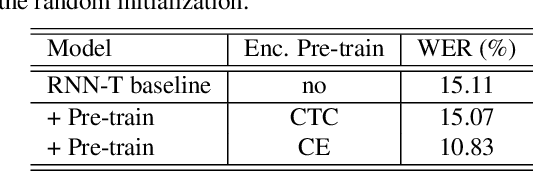
Recently, the recurrent neural network transducer (RNN-T) architecture has become an emerging trend in end-to-end automatic speech recognition research due to its advantages of being capable for online streaming speech recognition. However, RNN-T training is made difficult by the huge memory requirements, and complicated neural structure. A common solution to ease the RNN-T training is to employ connectionist temporal classification (CTC) model along with RNN language model (RNNLM) to initialize the RNN-T parameters. In this work, we conversely leverage external alignments to seed the RNN-T model. Two different pre-training solutions are explored, referred to as encoder pre-training, and whole-network pre-training respectively. Evaluated on Microsoft 65,000 hours anonymized production data with personally identifiable information removed, our proposed methods can obtain significant improvement. In particular, the encoder pre-training solution achieved a 10% and a 8% relative word error rate reduction when compared with random initialization and the widely used CTC+RNNLM initialization strategy, respectively. Our solutions also significantly reduce the RNN-T model latency from the baseline.
Continuous speech separation: dataset and analysis
Jan 30, 2020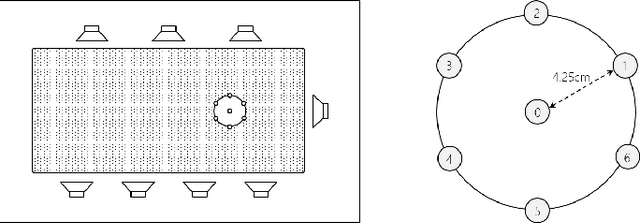
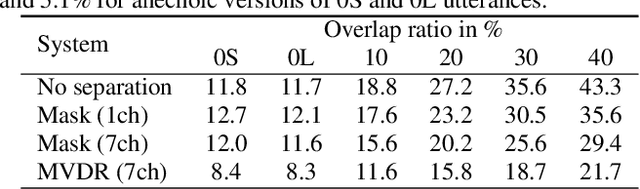
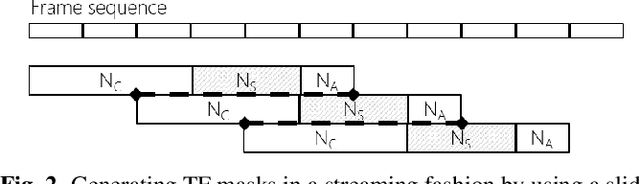
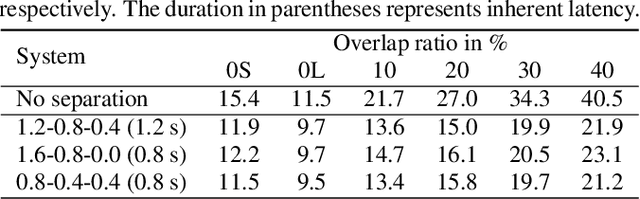
This paper describes a dataset and protocols for evaluating continuous speech separation algorithms. Most prior studies on speech separation use pre-segmented signals of artificially mixed speech utterances which are mostly \emph{fully} overlapped, and the algorithms are evaluated based on signal-to-distortion ratio or similar performance metrics. However, in natural conversations, a speech signal is continuous, containing both overlapped and overlap-free components. In addition, the signal-based metrics have very weak correlations with automatic speech recognition (ASR) accuracy. We think that not only does this make it hard to assess the practical relevance of the tested algorithms, it also hinders researchers from developing systems that can be readily applied to real scenarios. In this paper, we define continuous speech separation (CSS) as a task of generating a set of non-overlapped speech signals from a \textit{continuous} audio stream that contains multiple utterances that are \emph{partially} overlapped by a varying degree. A new real recorded dataset, called LibriCSS, is derived from LibriSpeech by concatenating the corpus utterances to simulate a conversation and capturing the audio replays with far-field microphones. A Kaldi-based ASR evaluation protocol is also established by using a well-trained multi-conditional acoustic model. By using this dataset, several aspects of a recently proposed speaker-independent CSS algorithm are investigated. The dataset and evaluation scripts are available to facilitate the research in this direction.
Semantic Mask for Transformer based End-to-End Speech Recognition
Dec 06, 2019
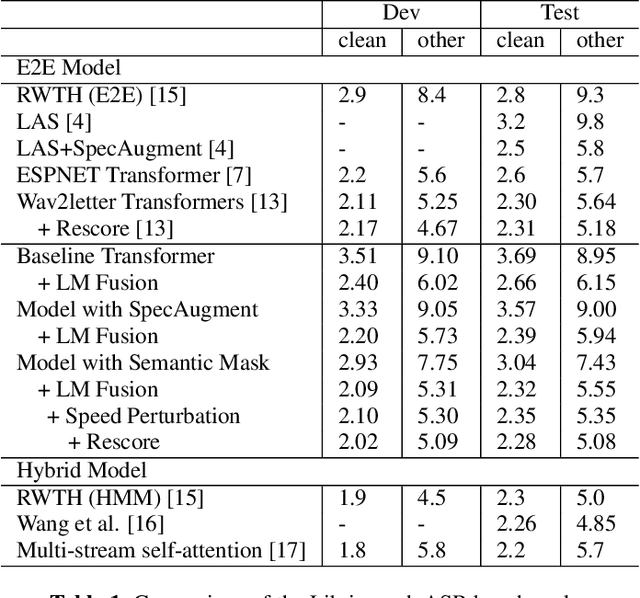
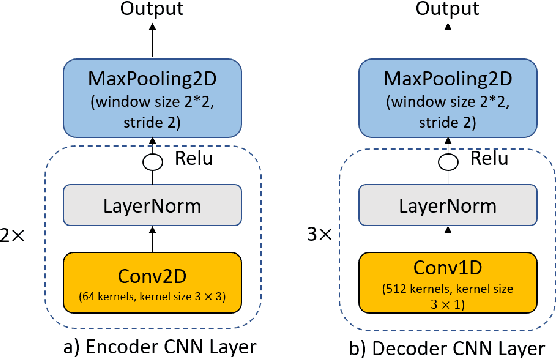
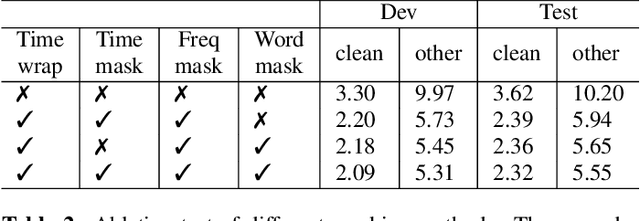
Attention-based encoder-decoder model has achieved impressive results for both automatic speech recognition (ASR) and text-to-speech (TTS) tasks. This approach takes advantage of the memorization capacity of neural networks to learn the mapping from the input sequence to the output sequence from scratch, without the assumption of prior knowledge such as the alignments. However, this model is prone to overfitting, especially when the amount of training data is limited. Inspired by SpecAugment and BERT, in this paper, we propose a semantic mask based regularization for training such kind of end-to-end (E2E) model. The idea is to mask the input features corresponding to a particular output token, e.g., a word or a word-piece, in order to encourage the model to fill the token based on the contextual information. While this approach is applicable to the encoder-decoder framework with any type of neural network architecture, we study the transformer-based model for ASR in this work. We perform experiments on Librispeech 960h and TedLium2 data sets, and achieve the state-of-the-art performance on the test set in the scope of E2E models.