 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Modular and Joint Approaches for Speaker-Attributed ASR on Monaural Long-Form Audio
Jul 06, 2021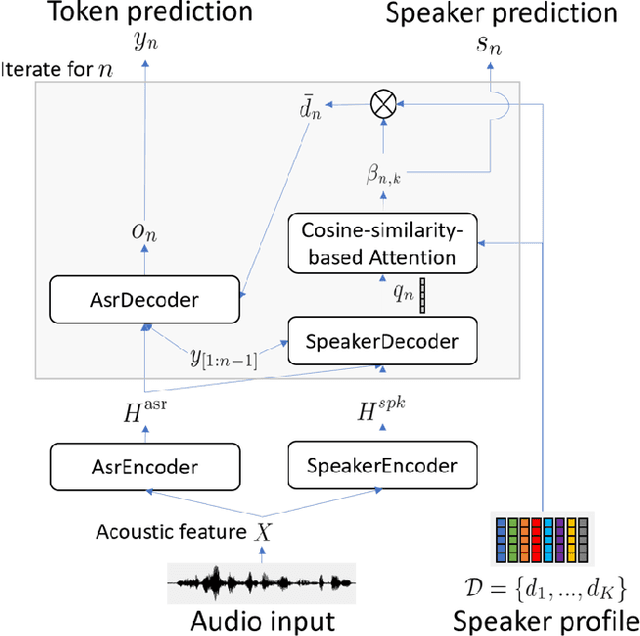
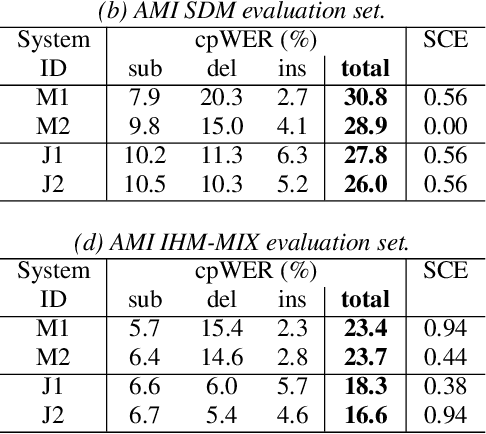
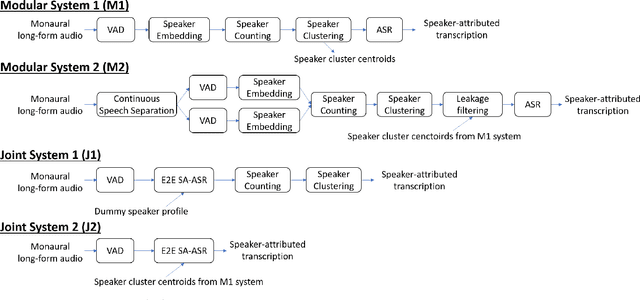
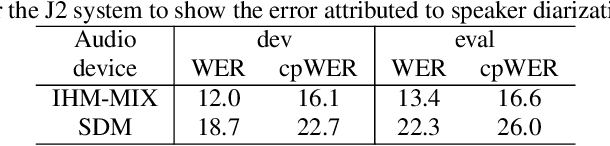
Speaker-attributed automatic speech recognition (SA-ASR) is a task to recognize "who spoke what" from multi-talker recordings. An SA-ASR system usually consists of multiple modules such as speech separation, speaker diarization and ASR. On the other hand, considering the joint optimization, an end-to-end (E2E) SA-ASR model has recently been proposed with promising results on simulation data. In this paper, we present our recent study on the comparison of such modular and joint approaches towards SA-ASR on real monaural recordings. We develop state-of-the-art SA-ASR systems for both modular and joint approaches by leveraging large-scale training data, including 75 thousand hours of ASR training data and the VoxCeleb corpus for speaker representation learning. We also propose a new pipeline that performs the E2E SA-ASR model after speaker clustering. Our evaluation on the AMI meeting corpus reveals that after fine-tuning with a small real data, the joint system performs 9.2--29.4% better in accuracy compared to the best modular system while the modular system performs better before such fine-tuning. We also conduct various error analyses to show the remaining issues for the monaural SA-ASR.
Continuous Speech Separation with Ad Hoc Microphone Arrays
Mar 03, 2021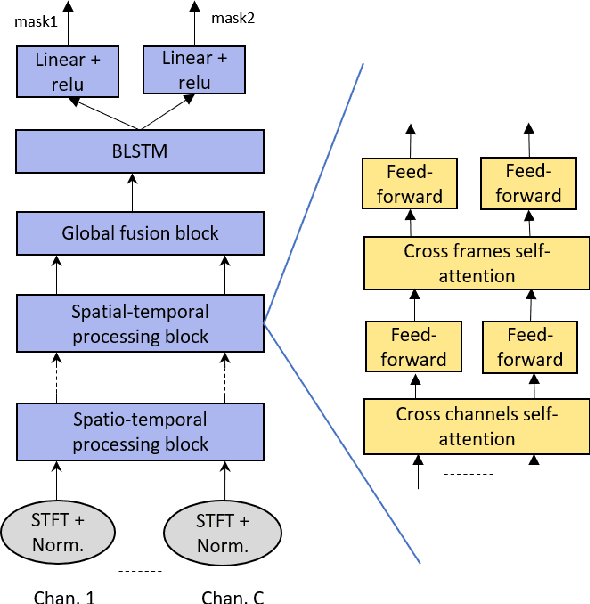

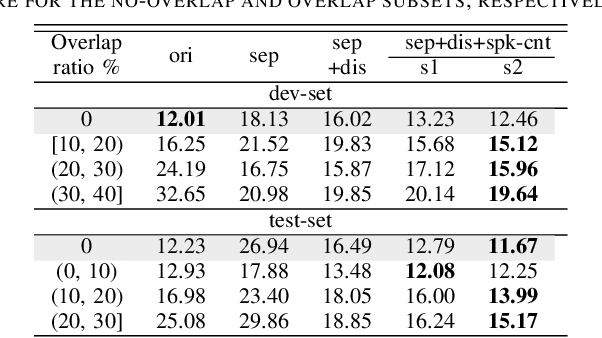
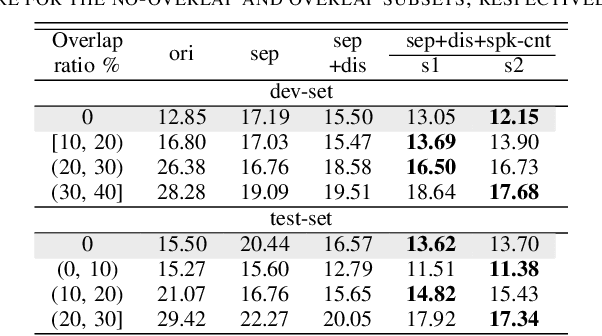
Speech separation has been shown effective for multi-talker speech recognition. Under the ad hoc microphone array setup where the array consists of spatially distributed asynchronous microphones, additional challenges must be overcome as the geometry and number of microphones are unknown beforehand. Prior studies show, with a spatial-temporalinterleaving structure, neural networks can efficiently utilize the multi-channel signals of the ad hoc array. In this paper, we further extend this approach to continuous speech separation. Several techniques are introduced to enable speech separation for real continuous recordings. First, we apply a transformer-based network for spatio-temporal modeling of the ad hoc array signals. In addition, two methods are proposed to mitigate a speech duplication problem during single talker segments, which seems more severe in the ad hoc array scenarios. One method is device distortion simulation for reducing the acoustic mismatch between simulated training data and real recordings. The other is speaker counting to detect the single speaker segments and merge the output signal channels. Experimental results for AdHoc-LibiCSS, a new dataset consisting of continuous recordings of concatenated LibriSpeech utterances obtained by multiple different devices, show the proposed separation method can significantly improve the ASR accuracy for overlapped speech with little performance degradation for single talker segments.
Dual-Path Modeling for Long Recording Speech Separation in Meetings
Feb 23, 2021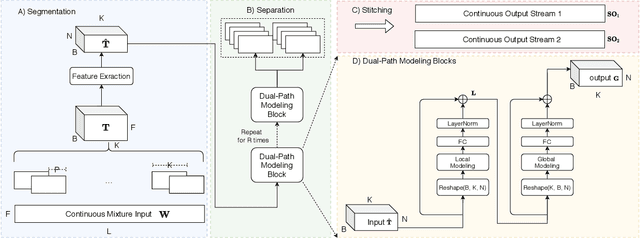
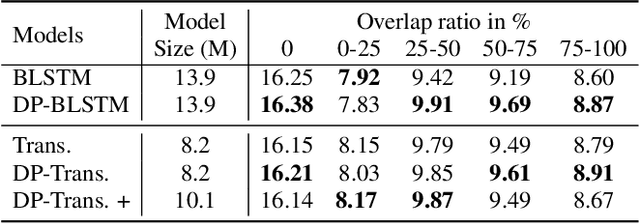
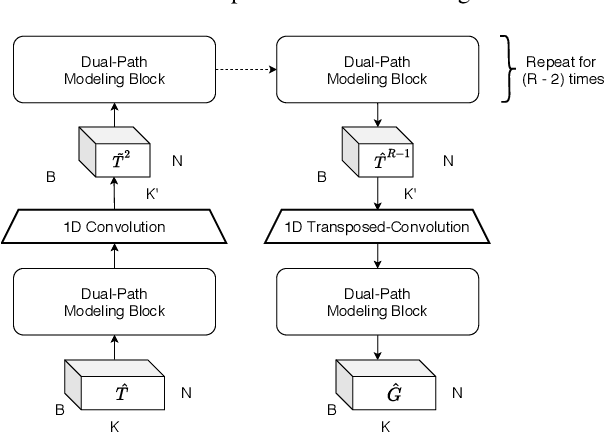
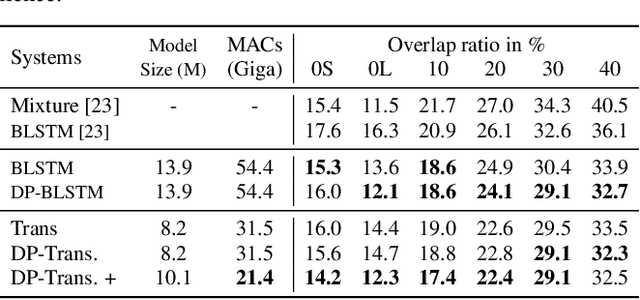
The continuous speech separation (CSS) is a task to separate the speech sources from a long, partially overlapped recording, which involves a varying number of speakers. A straightforward extension of conventional utterance-level speech separation to the CSS task is to segment the long recording with a size-fixed window and process each window separately. Though effective, this extension fails to model the long dependency in speech and thus leads to sub-optimum performance. The recent proposed dual-path modeling could be a remedy to this problem, thanks to its capability in jointly modeling the cross-window dependency and the local-window processing. In this work, we further extend the dual-path modeling framework for CSS task. A transformer-based dual-path system is proposed, which integrates transform layers for global modeling. The proposed models are applied to LibriCSS, a real recorded multi-talk dataset, and consistent WER reduction can be observed in the ASR evaluation for separated speech. Also, a dual-path transformer equipped with convolutional layers is proposed. It significantly reduces the computation amount by 30% with better WER evaluation. Furthermore, the online processing dual-path models are investigated, which shows 10% relative WER reduction compared to the baseline.
Joint Speaker Counting, Speech Recognition, and Speaker Identification for Overlapped Speech of Any Number of Speakers
Jun 19, 2020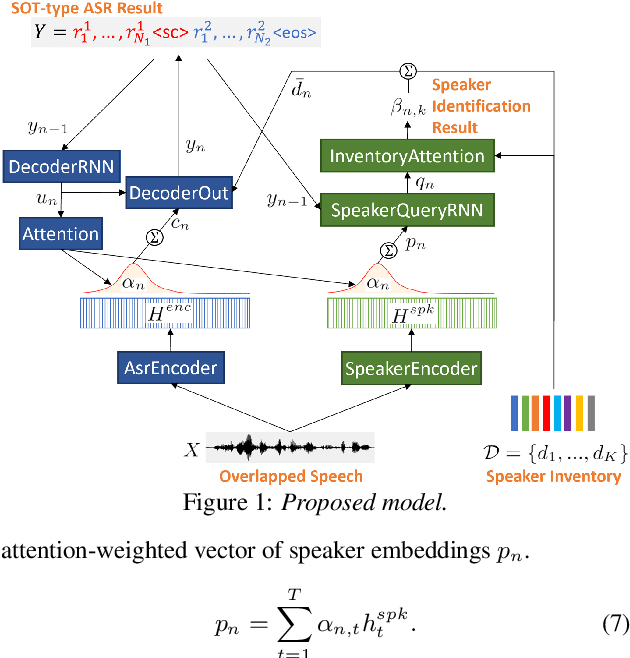
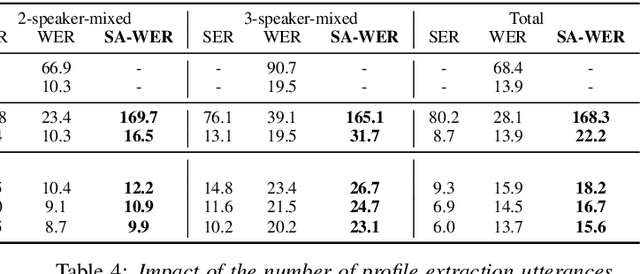
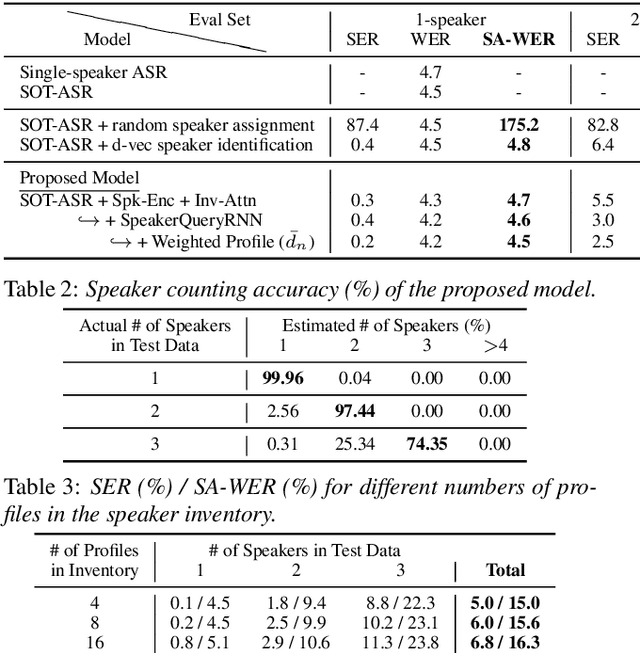
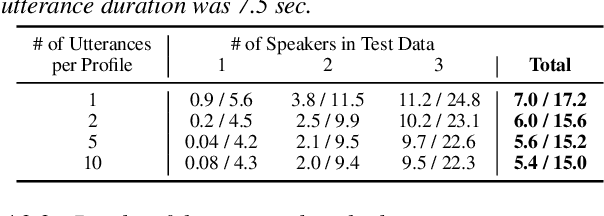
In this paper, we propose a joint model for simultaneous speaker counting, speech recognition, and speaker identification on monaural overlapped speech. Our model is built on serialized output training (SOT) with attention-based encoder-decoder, a recently proposed method for recognizing overlapped speech comprising an arbitrary number of speakers. We extend the SOT model by introducing a speaker inventory as an auxiliary input to produce speaker labels as well as multi-speaker transcriptions. All model parameters are optimized by speaker-attributed maximum mutual information criterion, which represents a joint probability for overlapped speech recognition and speaker identification. Experiments on LibriSpeech corpus show that our proposed method achieves significantly better speaker-attributed word error rate than the baseline that separately performs overlapped speech recognition and speaker identification.
Continuous speech separation: dataset and analysis
Jan 30, 2020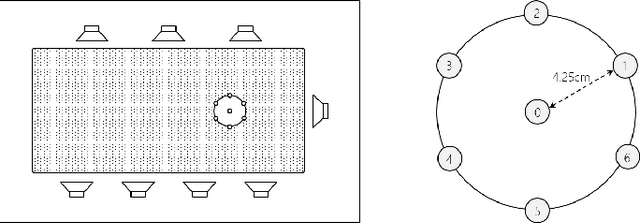
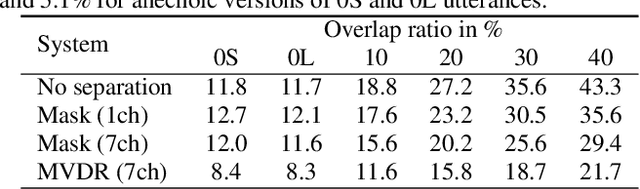
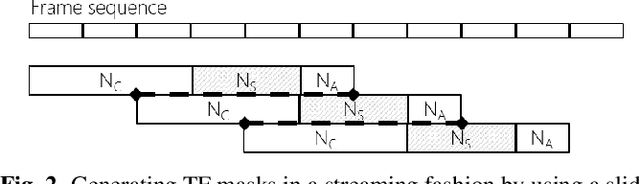
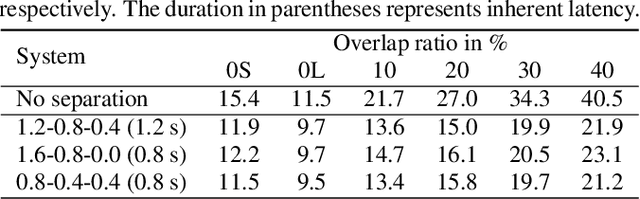
This paper describes a dataset and protocols for evaluating continuous speech separation algorithms. Most prior studies on speech separation use pre-segmented signals of artificially mixed speech utterances which are mostly \emph{fully} overlapped, and the algorithms are evaluated based on signal-to-distortion ratio or similar performance metrics. However, in natural conversations, a speech signal is continuous, containing both overlapped and overlap-free components. In addition, the signal-based metrics have very weak correlations with automatic speech recognition (ASR) accuracy. We think that not only does this make it hard to assess the practical relevance of the tested algorithms, it also hinders researchers from developing systems that can be readily applied to real scenarios. In this paper, we define continuous speech separation (CSS) as a task of generating a set of non-overlapped speech signals from a \textit{continuous} audio stream that contains multiple utterances that are \emph{partially} overlapped by a varying degree. A new real recorded dataset, called LibriCSS, is derived from LibriSpeech by concatenating the corpus utterances to simulate a conversation and capturing the audio replays with far-field microphones. A Kaldi-based ASR evaluation protocol is also established by using a well-trained multi-conditional acoustic model. By using this dataset, several aspects of a recently proposed speaker-independent CSS algorithm are investigated. The dataset and evaluation scripts are available to facilitate the research in this direction.
Advances in Online Audio-Visual Meeting Transcription
Dec 10, 2019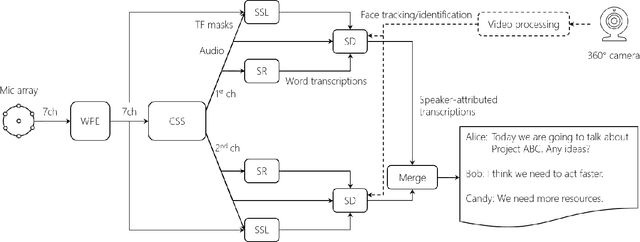

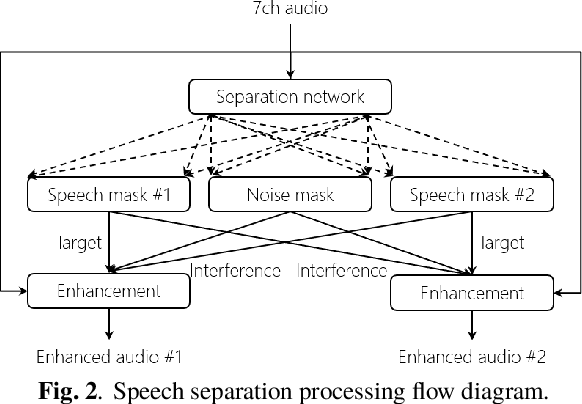
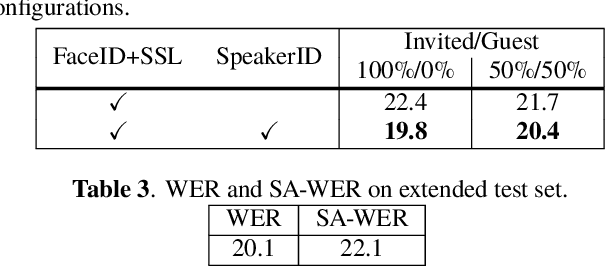
This paper describes a system that generates speaker-annotated transcripts of meetings by using a microphone array and a 360-degree camera. The hallmark of the system is its ability to handle overlapped speech, which has been an unsolved problem in realistic settings for over a decade. We show that this problem can be addressed by using a continuous speech separation approach. In addition, we describe an online audio-visual speaker diarization method that leverages face tracking and identification, sound source localization, speaker identification, and, if available, prior speaker information for robustness to various real world challenges. All components are integrated in a meeting transcription framework called SRD, which stands for "separate, recognize, and diarize". Experimental results using recordings of natural meetings involving up to 11 attendees are reported. The continuous speech separation improves a word error rate (WER) by 16.1% compared with a highly tuned beamformer. When a complete list of meeting attendees is available, the discrepancy between WER and speaker-attributed WER is only 1.0%, indicating accurate word-to-speaker association. This increases marginally to 1.6% when 50% of the attendees are unknown to the system.