 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTAE: Graph-Transformer based Auto-Encoders for Linguistic-Constrained Text Style Transfer
Feb 01, 2021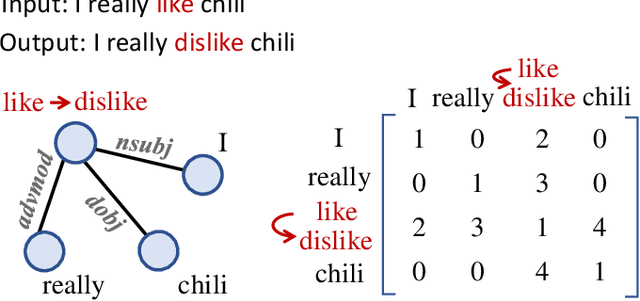
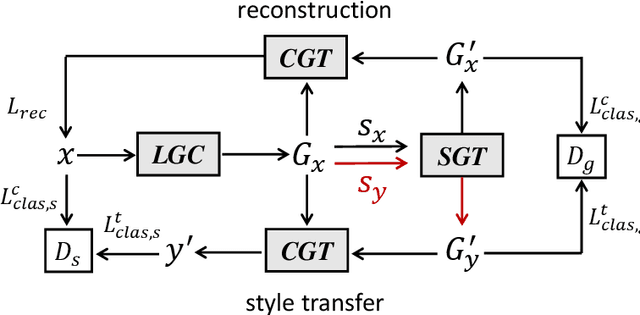
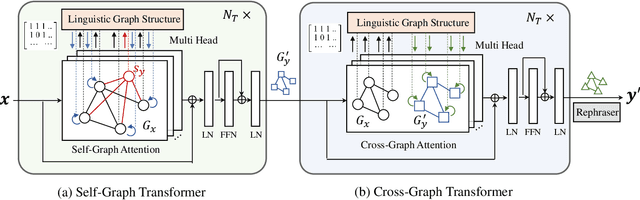
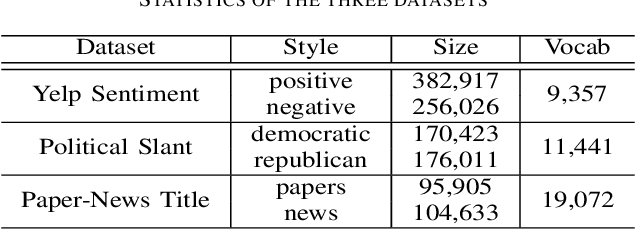
Non-parallel text style transfer has attracted increasing research interests in recent years. Despite successes in transferring the style based on the encoder-decoder framework, current approaches still lack the ability to preserve the content and even logic of original sentences, mainly due to the large unconstrained model space or too simplified assumptions on latent embedding space. Since language itself is an intelligent product of humans with certain grammars and has a limited rule-based model space by its nature, relieving this problem requires reconciling the model capacity of deep neural networks with the intrinsic model constraints from human linguistic rules. To this end, we propose a method called Graph Transformer based Auto Encoder (GTAE), which models a sentence as a linguistic graph and performs feature extraction and style transfer at the graph level, to maximally retain the content and the linguistic structure of original sentences. Quantitative experiment results on three non-parallel text style transfer tasks show that our model outperforms state-of-the-art methods in content preservation, while achieving comparable performance on transfer accuracy and sentence naturalness.
Temporal Contrastive Graph for Self-supervised Video Representation Learning
Feb 01, 2021

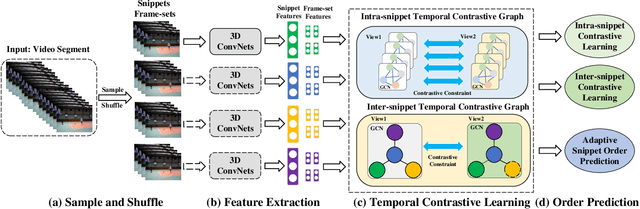

Attempt to fully explore the fine-grained temporal structure and global-local chronological characteristics for self-supervised video representation learning, this work takes a closer look at exploiting the temporal structure of videos and further proposes a novel self-supervised method named Temporal Contrastive Graph (TCG). In contrast to the existing methods that randomly shuffle the video frames or video snippets within a video, our proposed TCG roots in a hybrid graph contrastive learning strategy to regard the inter-snippet and intra-snippet temporal relationships as self-supervision signals for temporal representation learning. To increase the temporal diversity of features more comprehensively and precisely, our proposed TCG integrates the prior knowledge about the frame and snippet orders into temporal contrastive graph structures, i.e., the intra-/inter- snippet temporal contrastive graph modules. By randomly removing edges and masking node features of the intra-snippet graphs or inter-snippet graphs, our TCG can generate different correlated graph views. Then, specific contrastive losses are designed to maximize the agreement between node embeddings in different views. To learn the global context representation and recalibrate the channel-wise features adaptively, we introduce an adaptive video snippet order prediction module, which leverages the relational knowledge among video snippets to predict the actual snippet orders.Experimental results demonstrate the superiority of our TCG over the state-of-the-art methods on large-scale action recognition and video retrieval benchmarks.
Graphonomy: Universal Image Parsing via Graph Reasoning and Transfer
Jan 26, 2021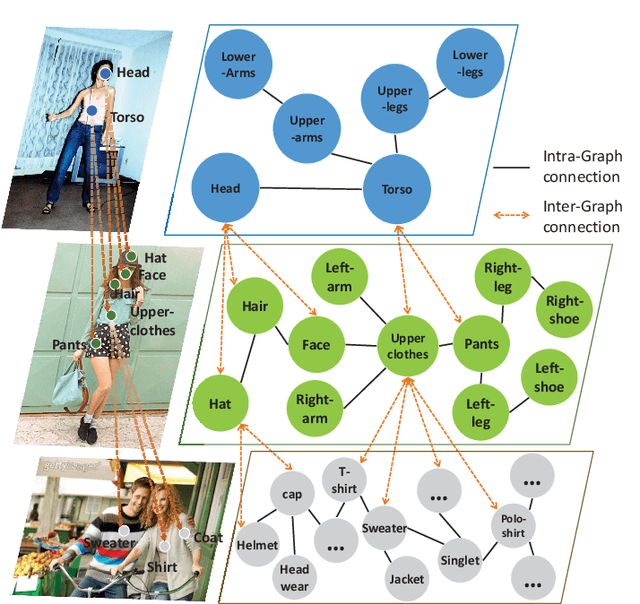

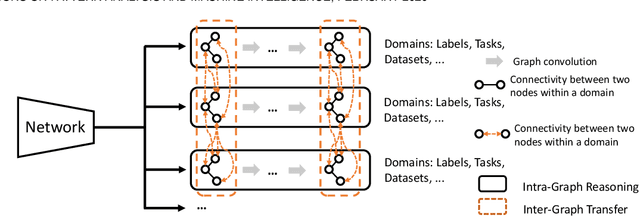
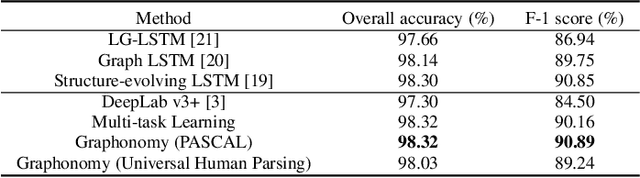
Prior highly-tuned image parsing models are usually studied in a certain domain with a specific set of semantic labels and can hardly be adapted into other scenarios (e.g., sharing discrepant label granularity) without extensive re-training. Learning a single universal parsing model by unifying label annotations from different domains or at various levels of granularity is a crucial but rarely addressed topic. This poses many fundamental learning challenges, e.g., discovering underlying semantic structures among different label granularity or mining label correlation across relevant tasks. To address these challenges, we propose a graph reasoning and transfer learning framework, named "Graphonomy", which incorporates human knowledge and label taxonomy into the intermediate graph representation learning beyond local convolutions. In particular, Graphonomy learns the global and structured semantic coherency in multiple domains via semantic-aware graph reasoning and transfer, enforcing the mutual benefits of the parsing across domains (e.g., different datasets or co-related tasks). The Graphonomy includes two iterated modules: Intra-Graph Reasoning and Inter-Graph Transfer modules. The former extracts the semantic graph in each domain to improve the feature representation learning by propagating information with the graph; the latter exploits the dependencies among the graphs from different domains for bidirectional knowledge transfer. We apply Graphonomy to two relevant but different image understanding research topics: human parsing and panoptic segmentation, and show Graphonomy can handle both of them well via a standard pipeline against current state-of-the-art approaches. Moreover, some extra benefit of our framework is demonstrated, e.g., generating the human parsing at various levels of granularity by unifying annotations across different datasets.
Unifying Relational Sentence Generation and Retrieval for Medical Image Report Composition
Jan 09, 2021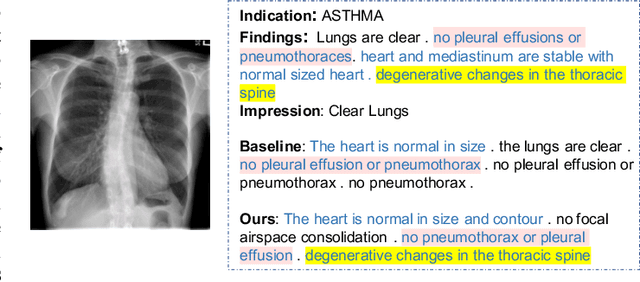
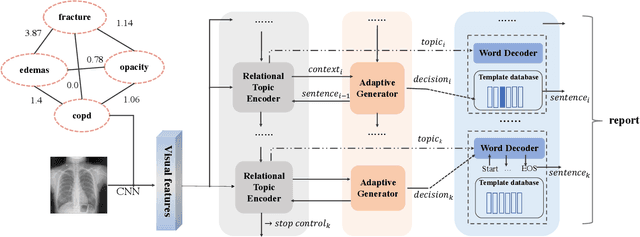
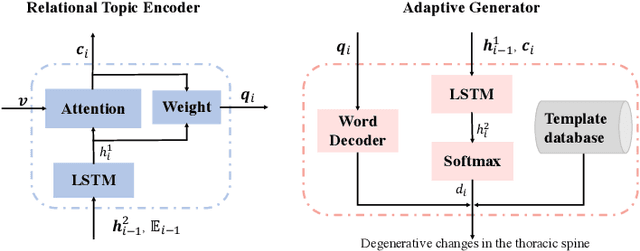
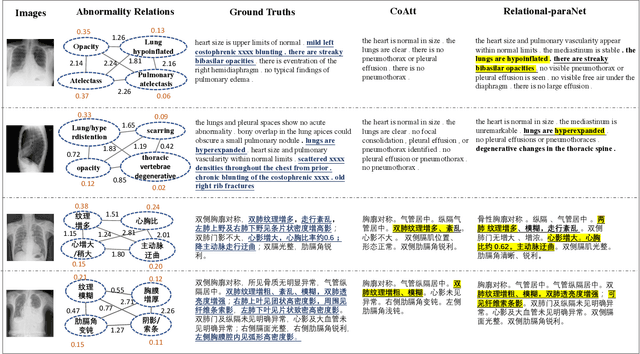
Beyond generating long and topic-coherent paragraphs in traditional captioning tasks, the medical image report composition task poses more task-oriented challenges by requiring both the highly-accurate medical term diagnosis and multiple heterogeneous forms of information including impression and findings. Current methods often generate the most common sentences due to dataset bias for individual case, regardless of whether the sentences properly capture key entities and relationships. Such limitations severely hinder their applicability and generalization capability in medical report composition where the most critical sentences lie in the descriptions of abnormal diseases that are relatively rare. Moreover, some medical terms appearing in one report are often entangled with each other and co-occurred, e.g. symptoms associated with a specific disease. To enforce the semantic consistency of medical terms to be incorporated into the final reports and encourage the sentence generation for rare abnormal descriptions, we propose a novel framework that unifies template retrieval and sentence generation to handle both common and rare abnormality while ensuring the semantic-coherency among the detected medical terms. Specifically, our approach exploits hybrid-knowledge co-reasoning: i) explicit relationships among all abnormal medical terms to induce the visual attention learning and topic representation encoding for better topic-oriented symptoms descriptions; ii) adaptive generation mode that changes between the template retrieval and sentence generation according to a contextual topic encoder. Experimental results on two medical report benchmarks demonstrate the superiority of the proposed framework in terms of both human and metrics evaluation.
REM-Net: Recursive Erasure Memory Network for Commonsense Evidence Refinement
Jan 03, 2021
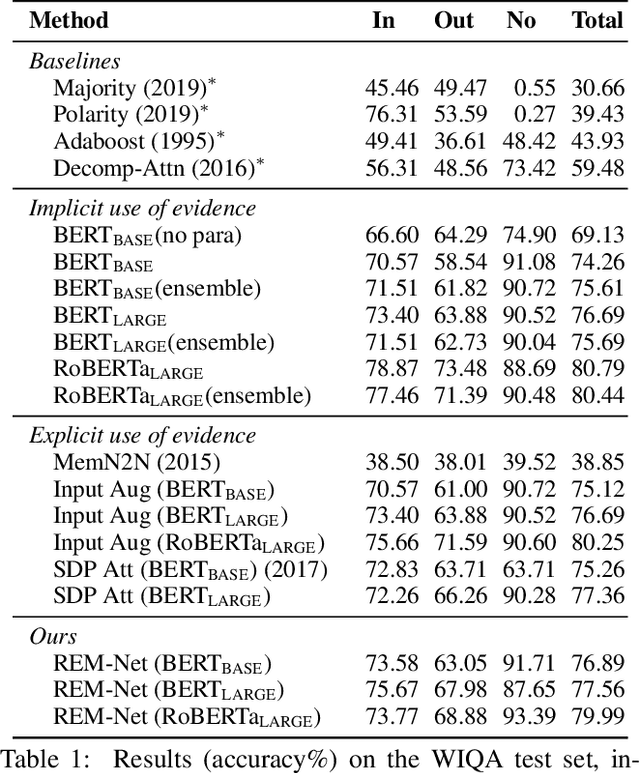
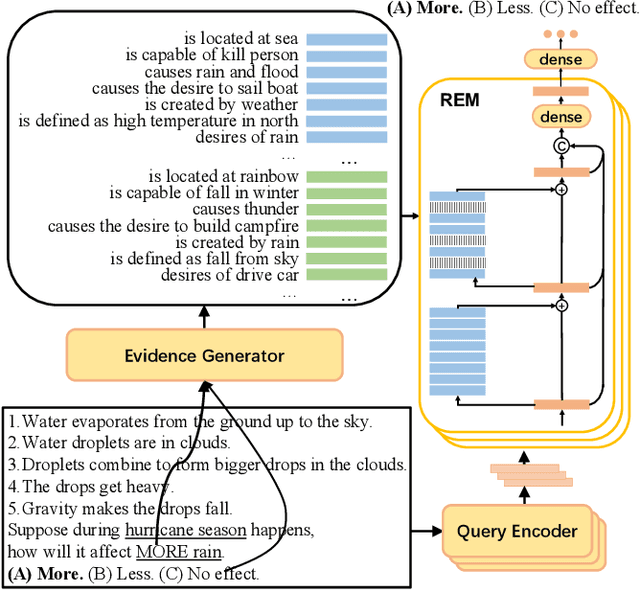

When answering a question, people often draw upon their rich world knowledge in addition to the particular context. While recent works retrieve supporting facts/evidence from commonsense knowledge bases to supply additional information to each question, there is still ample opportunity to advance it on the quality of the evidence. It is crucial since the quality of the evidence is the key to answering commonsense questions, and even determines the upper bound on the QA systems performance. In this paper, we propose a recursive erasure memory network (REM-Net) to cope with the quality improvement of evidence. To address this, REM-Net is equipped with a module to refine the evidence by recursively erasing the low-quality evidence that does not explain the question answering. Besides, instead of retrieving evidence from existing knowledge bases, REM-Net leverages a pre-trained generative model to generate candidate evidence customized for the question. We conduct experiments on two commonsense question answering datasets, WIQA and CosmosQA. The results demonstrate the performance of REM-Net and show that the refined evidence is explainable.
AU-Expression Knowledge Constrained Representation Learning for Facial Expression Recognition
Dec 29, 2020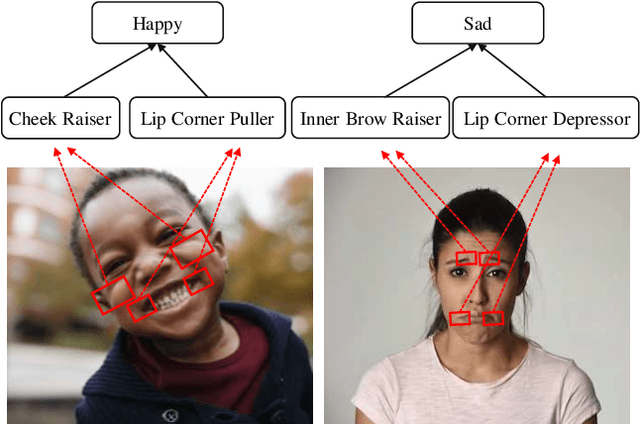
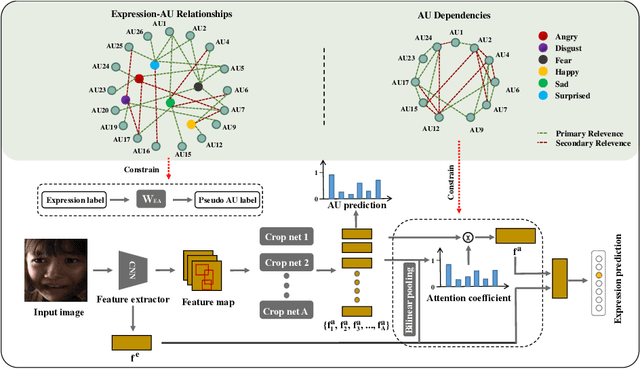
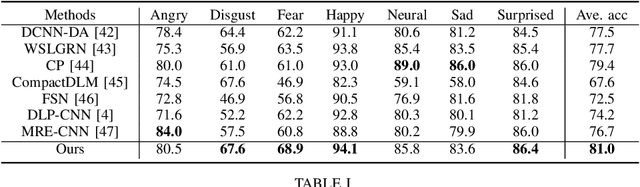

Recognizing human emotion/expressions automatically is quite an expected ability for intelligent robotics, as it can promote better communication and cooperation with humans. Current deep-learning-based algorithms may achieve impressive performance in some lab-controlled environments, but they always fail to recognize the expressions accurately for the uncontrolled in-the-wild situation. Fortunately, facial action units (AU) describe subtle facial behaviors, and they can help distinguish uncertain and ambiguous expressions. In this work, we explore the correlations among the action units and facial expressions, and devise an AU-Expression Knowledge Constrained Representation Learning (AUE-CRL) framework to learn the AU representations without AU annotations and adaptively use representations to facilitate facial expression recognition. Specifically, it leverages AU-expression correlations to guide the learning of the AU classifiers, and thus it can obtain AU representations without incurring any AU annotations. Then, it introduces a knowledge-guided attention mechanism that mines useful AU representations under the constraint of AU-expression correlations. In this way, the framework can capture local discriminative and complementary features to enhance facial representation for facial expression recognition. We conduct experiments on the challenging uncontrolled datasets to demonstrate the superiority of the proposed framework over current state-of-the-art methods.
Adversarial Meta Sampling for Multilingual Low-Resource Speech Recognition
Dec 23, 2020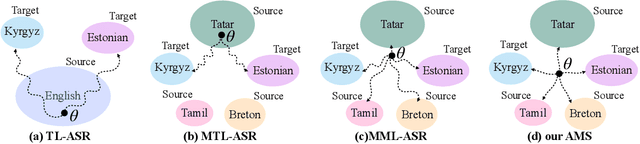
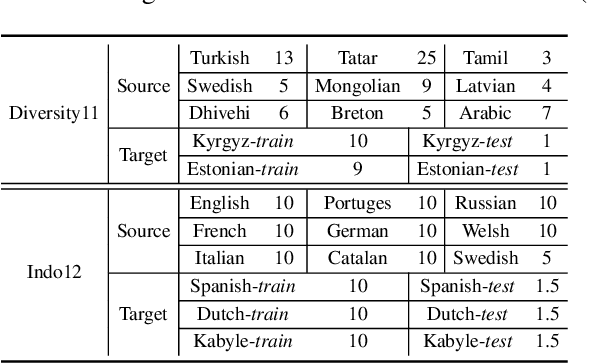
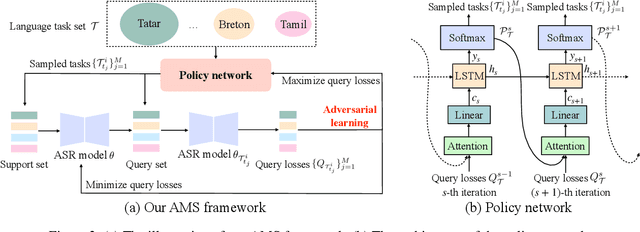

Low-resource automatic speech recognition (ASR) is challenging, as the low-resource target language data cannot well train an ASR model. To solve this issue, meta-learning formulates ASR for each source language into many small ASR tasks and meta-learns a model initialization on all tasks from different source languages to access fast adaptation on unseen target languages. However, for different source languages, the quantity and difficulty vary greatly because of their different data scales and diverse phonological systems, which leads to task-quantity and task-difficulty imbalance issues and thus a failure of multilingual meta-learning ASR (MML-ASR). In this work, we solve this problem by developing a novel adversarial meta sampling (AMS) approach to improve MML-ASR. When sampling tasks in MML-ASR, AMS adaptively determines the task sampling probability for each source language. Specifically, for each source language, if the query loss is large, it means that its tasks are not well sampled to train ASR model in terms of its quantity and difficulty and thus should be sampled more frequently for extra learning. Inspired by this fact, we feed the historical task query loss of all source language domain into a network to learn a task sampling policy for adversarially increasing the current query loss of MML-ASR. Thus, the learnt task sampling policy can master the learning situation of each language and thus predicts good task sampling probability for each language for more effective learning. Finally, experiment results on two multilingual datasets show significant performance improvement when applying our AMS on MML-ASR, and also demonstrate the applicability of AMS to other low-resource speech tasks and transfer learning ASR approaches. Our codes are available at: https://github.com/iamxiaoyubei/AMS.
Graph-Evolving Meta-Learning for Low-Resource Medical Dialogue Generation
Dec 22, 2020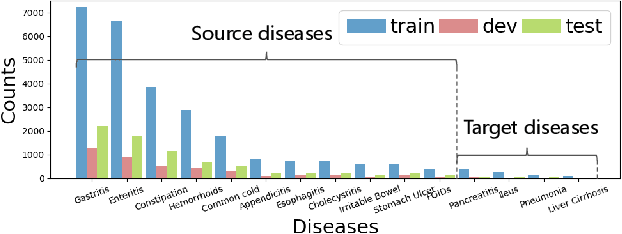
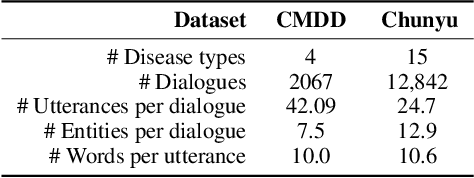
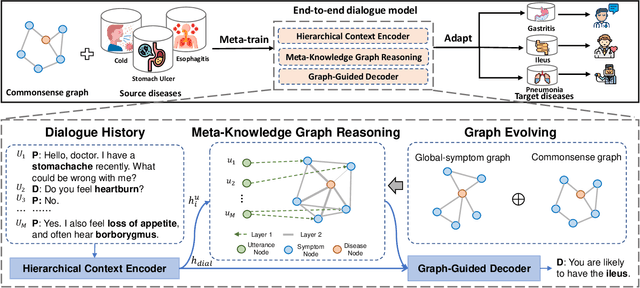
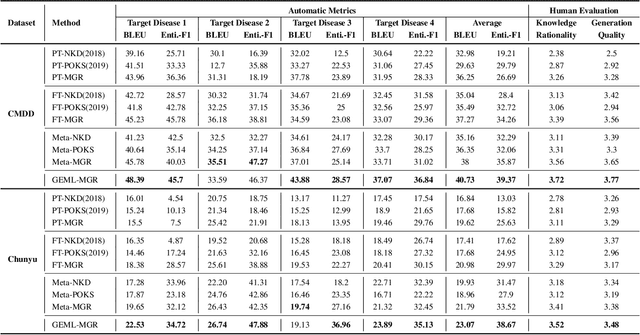
Human doctors with well-structured medical knowledge can diagnose a disease merely via a few conversations with patients about symptoms. In contrast, existing knowledge-grounded dialogue systems often require a large number of dialogue instances to learn as they fail to capture the correlations between different diseases and neglect the diagnostic experience shared among them. To address this issue, we propose a more natural and practical paradigm, i.e., low-resource medical dialogue generation, which can transfer the diagnostic experience from source diseases to target ones with a handful of data for adaptation. It is capitalized on a commonsense knowledge graph to characterize the prior disease-symptom relations. Besides, we develop a Graph-Evolving Meta-Learning (GEML) framework that learns to evolve the commonsense graph for reasoning disease-symptom correlations in a new disease, which effectively alleviates the needs of a large number of dialogues. More importantly, by dynamically evolving disease-symptom graphs, GEML also well addresses the real-world challenges that the disease-symptom correlations of each disease may vary or evolve along with more diagnostic cases. Extensive experiment results on the CMDD dataset and our newly-collected Chunyu dataset testify the superiority of our approach over state-of-the-art approaches. Besides, our GEML can generate an enriched dialogue-sensitive knowledge graph in an online manner, which could benefit other tasks grounded on knowledge graph.
Knowledge-Routed Visual Question Reasoning: Challenges for Deep Representation Embedding
Dec 14, 2020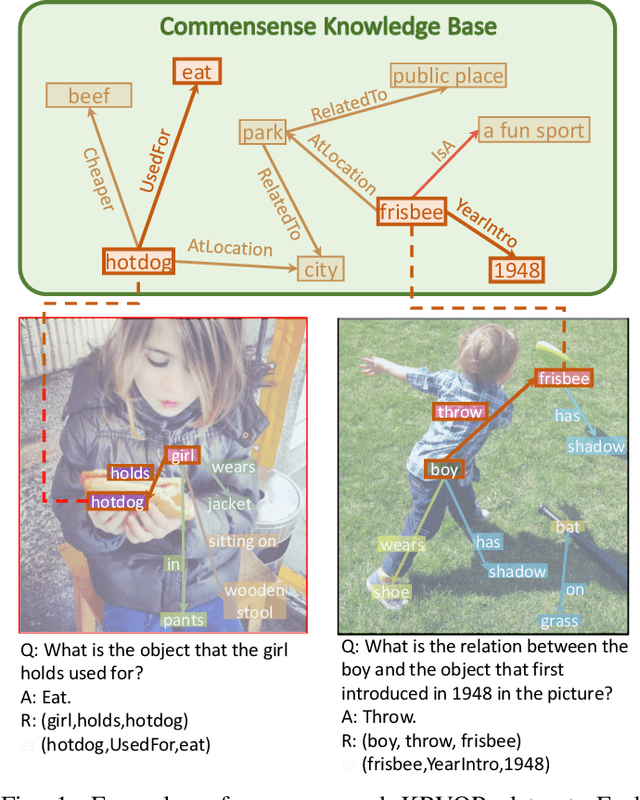
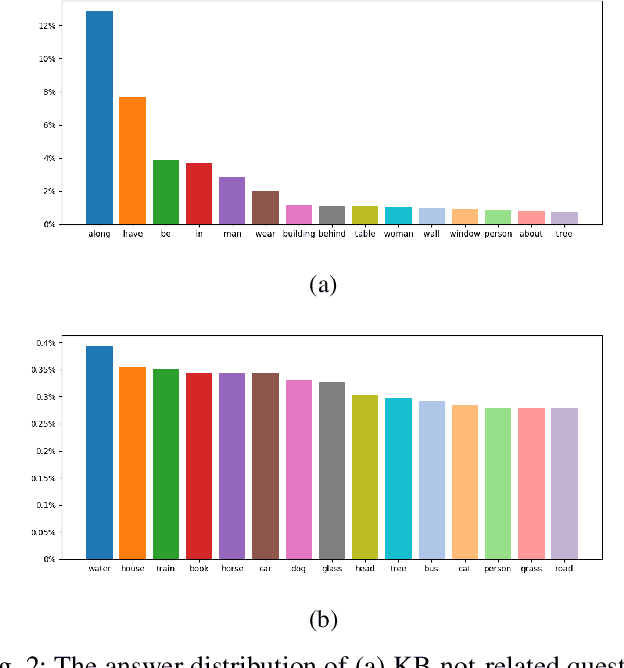
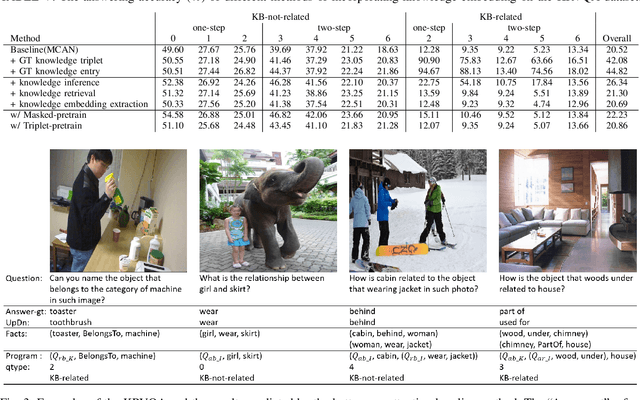
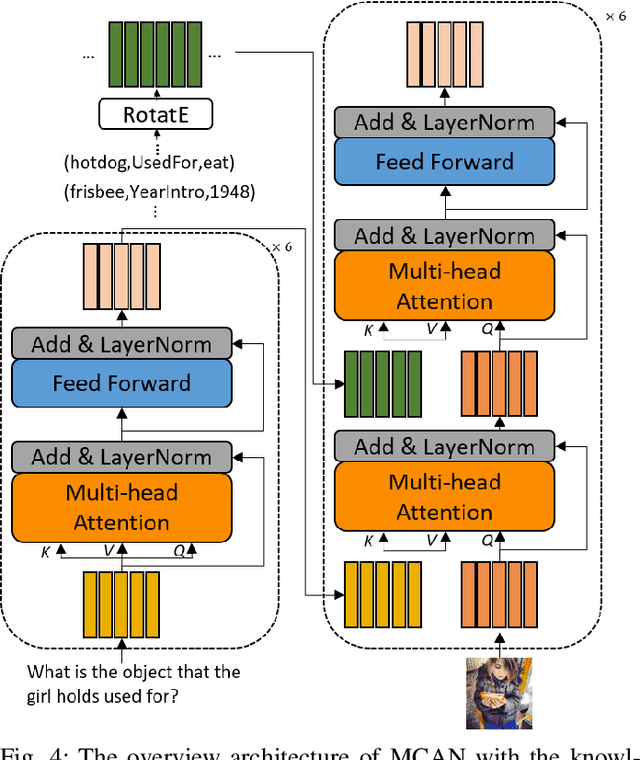
Though beneficial for encouraging the Visual Question Answering (VQA) models to discover the underlying knowledge by exploiting the input-output correlation beyond image and text contexts, the existing knowledge VQA datasets are mostly annotated in a crowdsource way, e.g., collecting questions and external reasons from different users via the internet. In addition to the challenge of knowledge reasoning, how to deal with the annotator bias also remains unsolved, which often leads to superficial over-fitted correlations between questions and answers. To address this issue, we propose a novel dataset named Knowledge-Routed Visual Question Reasoning for VQA model evaluation. Considering that a desirable VQA model should correctly perceive the image context, understand the question, and incorporate its learned knowledge, our proposed dataset aims to cutoff the shortcut learning exploited by the current deep embedding models and push the research boundary of the knowledge-based visual question reasoning. Specifically, we generate the question-answer pair based on both the Visual Genome scene graph and an external knowledge base with controlled programs to disentangle the knowledge from other biases. The programs can select one or two triplets from the scene graph or knowledge base to push multi-step reasoning, avoid answer ambiguity, and balanced the answer distribution. In contrast to the existing VQA datasets, we further imply the following two major constraints on the programs to incorporate knowledge reasoning: i) multiple knowledge triplets can be related to the question, but only one knowledge relates to the image object. This can enforce the VQA model to correctly perceive the image instead of guessing the knowledge based on the given question solely; ii) all questions are based on different knowledge, but the candidate answers are the same for both the training and test sets.
Cross-Modal Collaborative Representation Learning and a Large-Scale RGBT Benchmark for Crowd Counting
Dec 08, 2020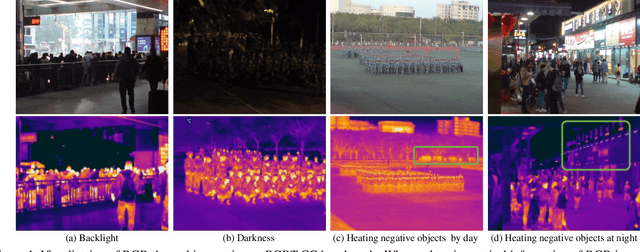
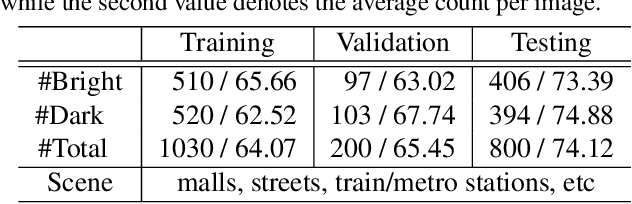
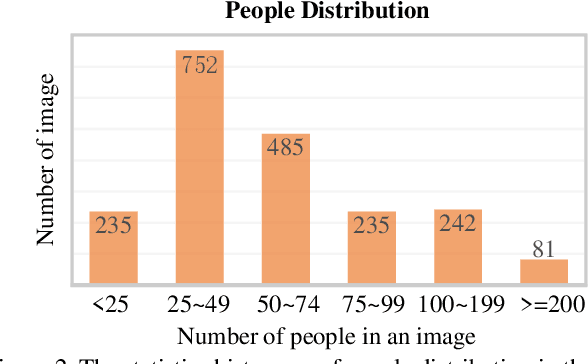
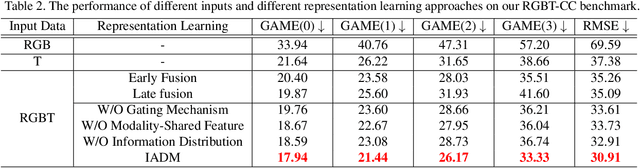
Crowd counting is a fundamental yet challenging problem, which desires rich information to generate pixel-wise crowd density maps. However, most previous methods only utilized the limited information of RGB images and may fail to discover the potential pedestrians in unconstrained environments. In this work, we find that incorporating optical and thermal information can greatly help to recognize pedestrians. To promote future researches in this field, we introduce a large-scale RGBT Crowd Counting (RGBT-CC) benchmark, which contains 2,030 pairs of RGB-thermal images with 138,389 annotated people. Furthermore, to facilitate the multimodal crowd counting, we propose a cross-modal collaborative representation learning framework, which consists of multiple modality-specific branches, a modality-shared branch, and an Information Aggregation-Distribution Module (IADM) to fully capture the complementary information of different modalities. Specifically, our IADM incorporates two collaborative information transfer components to dynamically enhance the modality-shared and modality-specific representations with a dual information propagation mechanism. Extensive experiments conducted on the RGBT-CC benchmark demonstrate the effectiveness of our framework for RGBT crowd counting. Moreover, the proposed approach is universal for multimodal crowd counting and is also capable to achieve superior performance on the ShanghaiTechRGBD dataset.