 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePay Attention to Sequence Split: Uncovering the Impacts of Sub-Sequence Splitting on Sequential Recommendation Models
Apr 07, 2026Sub-sequence splitting (SSS) has been demonstrated as an effective approach to mitigate data sparsity in sequential recommendation (SR) by splitting a raw user interaction sequence into multiple sub-sequences. Previous studies have demonstrated its ability to enhance the performance of SR models significantly. However, in this work, we discover that \textbf{(i). SSS may interfere with the evaluation of the model's actual performance.} We observed that many recent state-of-the-art SR models employ SSS during the data reading stage (not mentioned in the papers). When we removed this operation, performance significantly declined, even falling below that of earlier classical SR models. The varying improvements achieved by SSS and different splitting methods across different models prompt us to analyze further when SSS proves effective. We find that \textbf{(ii). SSS demonstrates strong capabilities only when specific splitting methods, target strategies, and loss functions are used together.} Inappropriate combinations may even harm performance. Furthermore, we analyze why sub-sequence splitting yields such remarkable performance gains and find that \textbf{(iii). it evens out the distribution of training data while increasing the likelihood that different items are targeted.} Finally, we provide suggestions for overcoming SSS interference, along with a discussion on data augmentation methods and future directions. We hope this work will prompt the broader community to re-examine the impact of data splitting on SR and promote fairer, more rigorous model evaluation. All analysis code and data will be made available upon acceptance. We provide a simple, anonymous implementation at https://github.com/KingGugu/SSS4SR.
A Rapid Instrument Exchange System for Humanoid Robots in Minimally Invasive Surgery
Apr 03, 2026Humanoid robot technologies have demonstrated immense potential for minimally invasive surgery (MIS). Unlike dedicated multi-arm surgical platforms, the inherent dual-arm configuration of humanoid robots necessitates an efficient instrument exchange capability to perform complex procedures, mimicking the natural workflow where surgeons manually switch instruments. To address this, this paper proposes an immersive teleoperated rapid instrument exchange system. The system utilizes a low-latency mechanism based on single-axis compliant docking and environmental constraint release. Integrated with real-time first-person view (FPV) perception via a head-mounted display (HMD), this framework significantly reduces operational complexity and cognitive load during the docking process. Comparative evaluations between experts and novices demonstrate high operational robustness and a rapidly converging learning curve; novice performance in instrument attachment and detachment improved substantially after brief training. While long-distance spatial alignment still presents challenges in time cost and collaborative stability, this study successfully validates the technical feasibility of humanoid robots executing stable instrument exchanges within constrained clinical environments.
Towards an Incremental Unified Multimodal Anomaly Detection: Augmenting Multimodal Denoising From an Information Bottleneck Perspective
Mar 03, 2026The quest for incremental unified multimodal anomaly detection seeks to empower a single model with the ability to systematically detect anomalies across all categories and support incremental learning to accommodate emerging objects/categories. Central to this pursuit is resolving the catastrophic forgetting dilemma, which involves acquiring new knowledge while preserving prior learned knowledge. Despite some efforts to address this dilemma, a key oversight persists: ignoring the potential impact of spurious and redundant features on catastrophic forgetting. In this paper, we delve into the negative effect of spurious and redundant features on this dilemma in incremental unified frameworks, and reveal that under similar conditions, the multimodal framework developed by naive aggregation of unimodal architectures is more prone to forgetting. To address this issue, we introduce a novel denoising framework called IB-IUMAD, which exploits the complementary benefits of the Mamba decoder and information bottleneck fusion module: the former dedicated to disentangle inter-object feature coupling, preventing spurious feature interference between objects; the latter serves to filter out redundant features from the fused features, thus explicitly preserving discriminative information. A series of theoretical analyses and experiments on MVTec 3D-AD and Eyecandies datasets demonstrates the effectiveness and competitive performance of IB-IUMAD.
Tail-Aware Data Augmentation for Long-Tail Sequential Recommendation
Jan 16, 2026Sequential recommendation (SR) learns user preferences based on their historical interaction sequences and provides personalized suggestions. In real-world scenarios, most users can only interact with a handful of items, while the majority of items are seldom consumed. This pervasive long-tail challenge limits the model's ability to learn user preferences. Despite previous efforts to enrich tail items/users with knowledge from head parts or improve tail learning through additional contextual information, they still face the following issues: 1) They struggle to improve the situation where interactions of tail users/items are scarce, leading to incomplete preferences learning for the tail parts. 2) Existing methods often degrade overall or head parts performance when improving accuracy for tail users/items, thereby harming the user experience. We propose Tail-Aware Data Augmentation (TADA) for long-tail sequential recommendation, which enhances the interaction frequency for tail items/users while maintaining head performance, thereby promoting the model's learning capabilities for the tail. Specifically, we first capture the co-occurrence and correlation among low-popularity items by a linear model. Building upon this, we design two tail-aware augmentation operators, T-Substitute and T-Insert. The former replaces the head item with a relevant item, while the latter utilizes co-occurrence relationships to extend the original sequence by incorporating both head and tail items. The augmented and original sequences are mixed at the representation level to preserve preference knowledge. We further extend the mix operation across different tail-user sequences and augmented sequences to generate richer augmented samples, thereby improving tail performance. Comprehensive experiments demonstrate the superiority of our method. The codes are provided at https://github.com/KingGugu/TADA.
Learning from Loss Landscape: Generalizable Mixed-Precision Quantization via Adaptive Sharpness-Aware Gradient Aligning
May 08, 2025Mixed Precision Quantization (MPQ) has become an essential technique for optimizing neural network by determining the optimal bitwidth per layer. Existing MPQ methods, however, face a major hurdle: they require a computationally expensive search for quantization policies on large-scale datasets. To resolve this issue, we introduce a novel approach that first searches for quantization policies on small datasets and then generalizes them to large-scale datasets. This approach simplifies the process, eliminating the need for large-scale quantization fine-tuning and only necessitating model weight adjustment. Our method is characterized by three key techniques: sharpness-aware minimization for enhanced quantization generalization, implicit gradient direction alignment to handle gradient conflicts among different optimization objectives, and an adaptive perturbation radius to accelerate optimization. Both theoretical analysis and experimental results validate our approach. Using the CIFAR10 dataset (just 0.5\% the size of ImageNet training data) for MPQ policy search, we achieved equivalent accuracy on ImageNet with a significantly lower computational cost, while improving efficiency by up to 150% over the baselines.
Revisiting Multimodal Fusion for 3D Anomaly Detection from an Architectural Perspective
Dec 23, 2024Existing efforts to boost multimodal fusion of 3D anomaly detection (3D-AD) primarily concentrate on devising more effective multimodal fusion strategies. However, little attention was devoted to analyzing the role of multimodal fusion architecture (topology) design in contributing to 3D-AD. In this paper, we aim to bridge this gap and present a systematic study on the impact of multimodal fusion architecture design on 3D-AD. This work considers the multimodal fusion architecture design at the intra-module fusion level, i.e., independent modality-specific modules, involving early, middle or late multimodal features with specific fusion operations, and also at the inter-module fusion level, i.e., the strategies to fuse those modules. In both cases, we first derive insights through theoretically and experimentally exploring how architectural designs influence 3D-AD. Then, we extend SOTA neural architecture search (NAS) paradigm and propose 3D-ADNAS to simultaneously search across multimodal fusion strategies and modality-specific modules for the first time.Extensive experiments show that 3D-ADNAS obtains consistent improvements in 3D-AD across various model capacities in terms of accuracy, frame rate, and memory usage, and it exhibits great potential in dealing with few-shot 3D-AD tasks.
HEP-NAS: Towards Efficient Few-shot Neural Architecture Search via Hierarchical Edge Partitioning
Dec 14, 2024One-shot methods have significantly advanced the field of neural architecture search (NAS) by adopting weight-sharing strategy to reduce search costs. However, the accuracy of performance estimation can be compromised by co-adaptation. Few-shot methods divide the entire supernet into individual sub-supernets by splitting edge by edge to alleviate this issue, yet neglect relationships among edges and result in performance degradation on huge search space. In this paper, we introduce HEP-NAS, a hierarchy-wise partition algorithm designed to further enhance accuracy. To begin with, HEP-NAS treats edges sharing the same end node as a hierarchy, permuting and splitting edges within the same hierarchy to directly search for the optimal operation combination for each intermediate node. This approach aligns more closely with the ultimate goal of NAS. Furthermore, HEP-NAS selects the most promising sub-supernet after each segmentation, progressively narrowing the search space in which the optimal architecture may exist. To improve performance evaluation of sub-supernets, HEP-NAS employs search space mutual distillation, stabilizing the training process and accelerating the convergence of each individual sub-supernet. Within a given budget, HEP-NAS enables the splitting of all edges and gradually searches for architectures with higher accuracy. Experimental results across various datasets and search spaces demonstrate the superiority of HEP-NAS compared to state-of-the-art methods.
One-Step Forward and Backtrack: Overcoming Zig-Zagging in Loss-Aware Quantization Training
Jan 30, 2024



Weight quantization is an effective technique to compress deep neural networks for their deployment on edge devices with limited resources. Traditional loss-aware quantization methods commonly use the quantized gradient to replace the full-precision gradient. However, we discover that the gradient error will lead to an unexpected zig-zagging-like issue in the gradient descent learning procedures, where the gradient directions rapidly oscillate or zig-zag, and such issue seriously slows down the model convergence. Accordingly, this paper proposes a one-step forward and backtrack way for loss-aware quantization to get more accurate and stable gradient direction to defy this issue. During the gradient descent learning, a one-step forward search is designed to find the trial gradient of the next-step, which is adopted to adjust the gradient of current step towards the direction of fast convergence. After that, we backtrack the current step to update the full-precision and quantized weights through the current-step gradient and the trial gradient. A series of theoretical analysis and experiments on benchmark deep models have demonstrated the effectiveness and competitiveness of the proposed method, and our method especially outperforms others on the convergence performance.
Survey on Evolutionary Deep Learning: Principles, Algorithms, Applications and Open Issues
Aug 23, 2022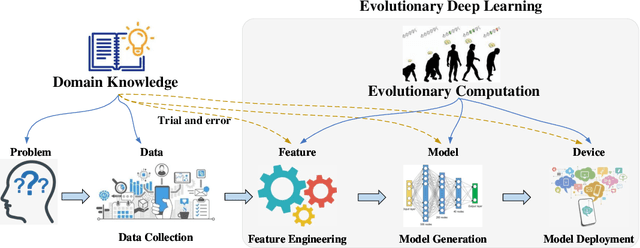
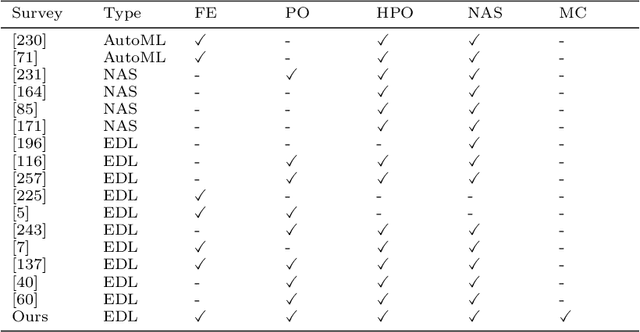
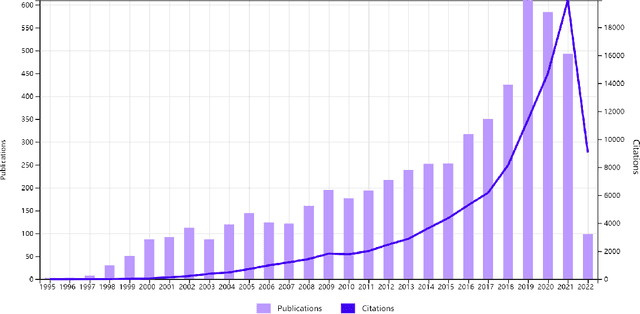
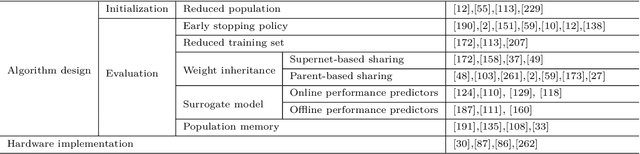
Over recent years, there has been a rapid development of deep learning (DL) in both industry and academia fields. However, finding the optimal hyperparameters of a DL model often needs high computational cost and human expertise. To mitigate the above issue, evolutionary computation (EC) as a powerful heuristic search approach has shown significant merits in the automated design of DL models, so-called evolutionary deep learning (EDL). This paper aims to analyze EDL from the perspective of automated machine learning (AutoML). Specifically, we firstly illuminate EDL from machine learning and EC and regard EDL as an optimization problem. According to the DL pipeline, we systematically introduce EDL methods ranging from feature engineering, model generation, to model deployment with a new taxonomy (i.e., what and how to evolve/optimize), and focus on the discussions of solution representation and search paradigm in handling the optimization problem by EC. Finally, key applications, open issues and potentially promising lines of future research are suggested. This survey has reviewed recent developments of EDL and offers insightful guidelines for the development of EDL.
Towards Fairness-Aware Multi-Objective Optimization
Jul 22, 2022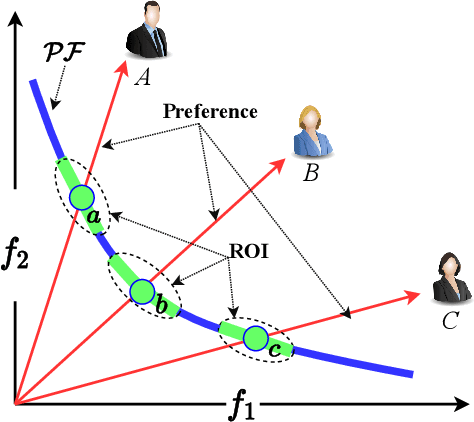
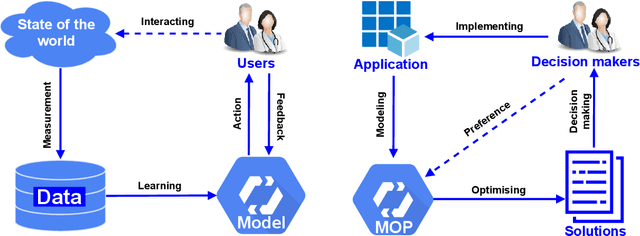
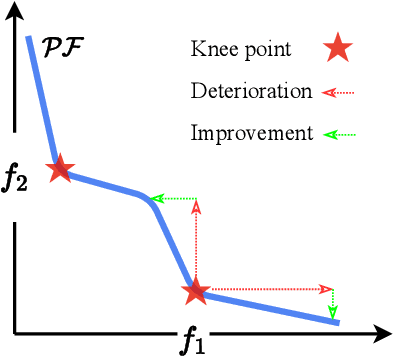
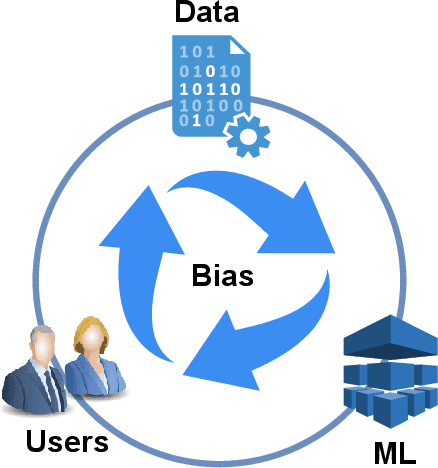
Recent years have seen the rapid development of fairness-aware machine learning in mitigating unfairness or discrimination in decision-making in a wide range of applications. However, much less attention has been paid to the fairness-aware multi-objective optimization, which is indeed commonly seen in real life, such as fair resource allocation problems and data driven multi-objective optimization problems. This paper aims to illuminate and broaden our understanding of multi-objective optimization from the perspective of fairness. To this end, we start with a discussion of user preferences in multi-objective optimization and then explore its relationship to fairness in machine learning and multi-objective optimization. Following the above discussions, representative cases of fairness-aware multiobjective optimization are presented, further elaborating the importance of fairness in traditional multi-objective optimization, data-driven optimization and federated optimization. Finally, challenges and opportunities in fairness-aware multi-objective optimization are addressed. We hope that this article makes a small step forward towards understanding fairness in the context of optimization and promote research interest in fairness-aware multi-objective optimization.