 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an Incremental Unified Multimodal Anomaly Detection: Augmenting Multimodal Denoising From an Information Bottleneck Perspective
Mar 03, 2026The quest for incremental unified multimodal anomaly detection seeks to empower a single model with the ability to systematically detect anomalies across all categories and support incremental learning to accommodate emerging objects/categories. Central to this pursuit is resolving the catastrophic forgetting dilemma, which involves acquiring new knowledge while preserving prior learned knowledge. Despite some efforts to address this dilemma, a key oversight persists: ignoring the potential impact of spurious and redundant features on catastrophic forgetting. In this paper, we delve into the negative effect of spurious and redundant features on this dilemma in incremental unified frameworks, and reveal that under similar conditions, the multimodal framework developed by naive aggregation of unimodal architectures is more prone to forgetting. To address this issue, we introduce a novel denoising framework called IB-IUMAD, which exploits the complementary benefits of the Mamba decoder and information bottleneck fusion module: the former dedicated to disentangle inter-object feature coupling, preventing spurious feature interference between objects; the latter serves to filter out redundant features from the fused features, thus explicitly preserving discriminative information. A series of theoretical analyses and experiments on MVTec 3D-AD and Eyecandies datasets demonstrates the effectiveness and competitive performance of IB-IUMAD.
Revisiting Multimodal Fusion for 3D Anomaly Detection from an Architectural Perspective
Dec 23, 2024Existing efforts to boost multimodal fusion of 3D anomaly detection (3D-AD) primarily concentrate on devising more effective multimodal fusion strategies. However, little attention was devoted to analyzing the role of multimodal fusion architecture (topology) design in contributing to 3D-AD. In this paper, we aim to bridge this gap and present a systematic study on the impact of multimodal fusion architecture design on 3D-AD. This work considers the multimodal fusion architecture design at the intra-module fusion level, i.e., independent modality-specific modules, involving early, middle or late multimodal features with specific fusion operations, and also at the inter-module fusion level, i.e., the strategies to fuse those modules. In both cases, we first derive insights through theoretically and experimentally exploring how architectural designs influence 3D-AD. Then, we extend SOTA neural architecture search (NAS) paradigm and propose 3D-ADNAS to simultaneously search across multimodal fusion strategies and modality-specific modules for the first time.Extensive experiments show that 3D-ADNAS obtains consistent improvements in 3D-AD across various model capacities in terms of accuracy, frame rate, and memory usage, and it exhibits great potential in dealing with few-shot 3D-AD tasks.
Application of Data Encryption in Chinese Named Entity Recognition
Aug 31, 2022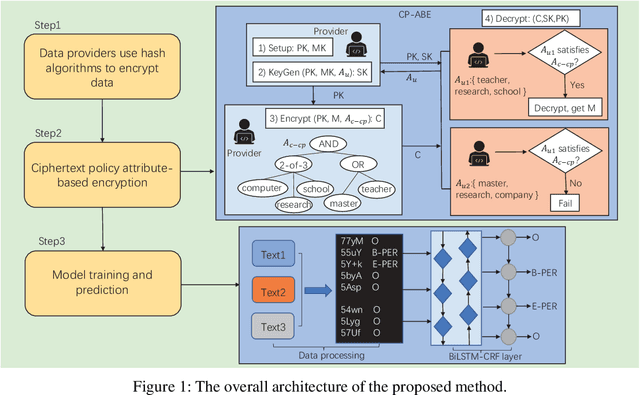
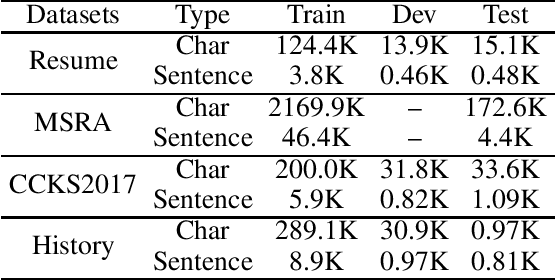
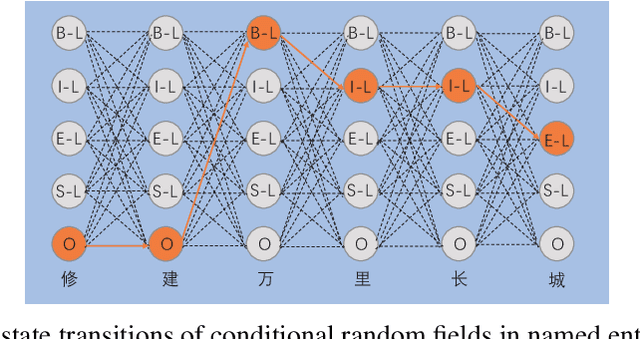
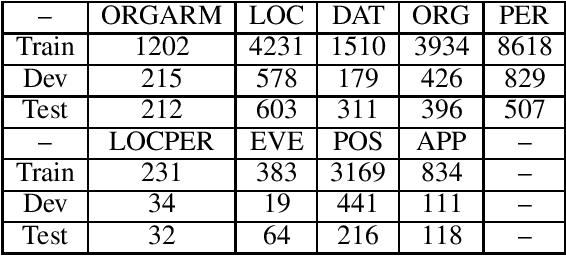
Recently, with the continuous development of deep learning, the performance of named entity recognition tasks has been dramatically improved. However, the privacy and the confidentiality of data in some specific fields, such as biomedical and military, cause insufficient data to support the training of deep neural networks. In this paper, we propose an encryption learning framework to address the problems of data leakage and inconvenient disclosure of sensitive data in certain domains. We introduce multiple encryption algorithms to encrypt training data in the named entity recognition task for the first time. In other words, we train the deep neural network using the encrypted data. We conduct experiments on six Chinese datasets, three of which are constructed by ourselves. The experimental results show that the encryption method achieves satisfactory results. The performance of some models trained with encrypted data even exceeds the performance of the unencrypted method, which verifies the effectiveness of the introduced encryption method and solves the problem of data leakage to a certain extent.