 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLi Zhang
CBARF: Cascaded Bundle-Adjusting Neural Radiance Fields from Imperfect Camera Poses
Oct 15, 2023
Existing volumetric neural rendering techniques, such as Neural Radiance Fields (NeRF), face limitations in synthesizing high-quality novel views when the camera poses of input images are imperfect. To address this issue, we propose a novel 3D reconstruction framework that enables simultaneous optimization of camera poses, dubbed CBARF (Cascaded Bundle-Adjusting NeRF).In a nutshell, our framework optimizes camera poses in a coarse-to-fine manner and then reconstructs scenes based on the rectified poses. It is observed that the initialization of camera poses has a significant impact on the performance of bundle-adjustment (BA). Therefore, we cascade multiple BA modules at different scales to progressively improve the camera poses. Meanwhile, we develop a neighbor-replacement strategy to further optimize the results of BA in each stage. In this step, we introduce a novel criterion to effectively identify poorly estimated camera poses. Then we replace them with the poses of neighboring cameras, thus further eliminating the impact of inaccurate camera poses. Once camera poses have been optimized, we employ a density voxel grid to generate high-quality 3D reconstructed scenes and images in novel views. Experimental results demonstrate that our CBARF model achieves state-of-the-art performance in both pose optimization and novel view synthesis, especially in the existence of large camera pose noise.
Multi-Depth Branches Network for Efficient Image Super-Resolution
Sep 29, 2023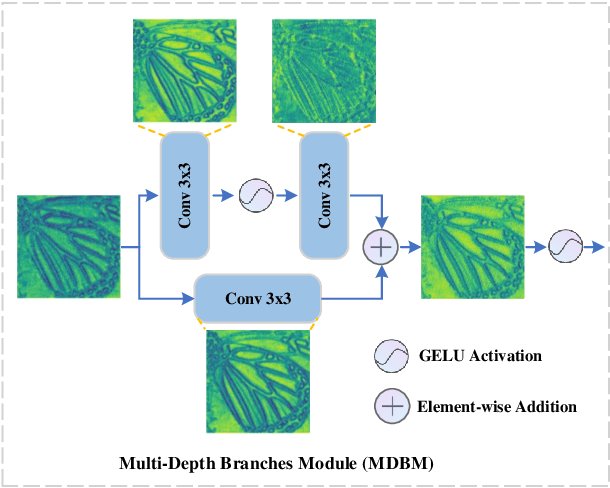
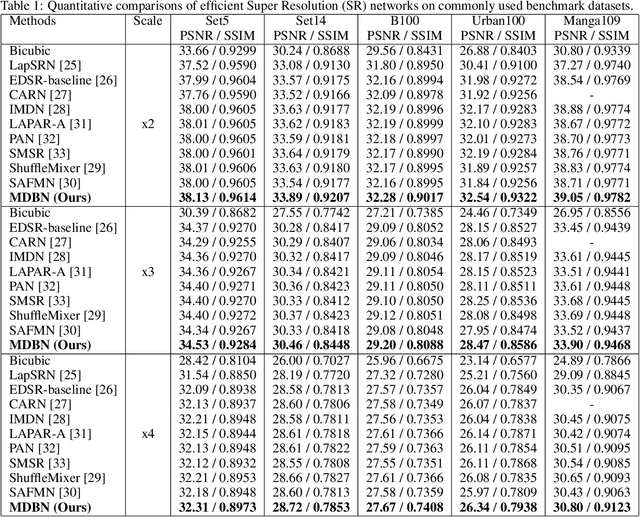
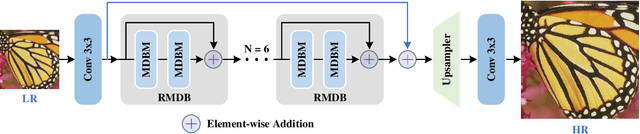
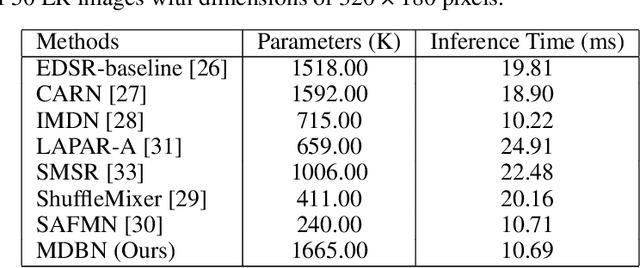
Significant progress has been made in the field of super-resolution (SR), yet many convolutional neural networks (CNNs) based SR models primarily focus on restoring high-frequency details, often overlooking crucial low-frequency contour information. Transformer-based SR methods, while incorporating global structural details, frequently come with an abundance of parameters, leading to high computational overhead. In this paper, we address these challenges by introducing a Multi-Depth Branches Network (MDBN). This framework extends the ResNet architecture by integrating an additional branch that captures vital structural characteristics of images. Our proposed multi-depth branches module (MDBM) involves the stacking of convolutional kernels of identical size at varying depths within distinct branches. By conducting a comprehensive analysis of the feature maps, we observe that branches with differing depths can extract contour and detail information respectively. By integrating these branches, the overall architecture can preserve essential low-frequency semantic structural information during the restoration of high-frequency visual elements, which is more closely with human visual cognition. Compared to GoogLeNet-like models, our basic multi-depth branches structure has fewer parameters, higher computational efficiency, and improved performance. Our model outperforms state-of-the-art (SOTA) lightweight SR methods with less inference time. Our code is available at https://github.com/thy960112/MDBN
Choice-75: A Dataset on Decision Branching in Script Learning
Sep 21, 2023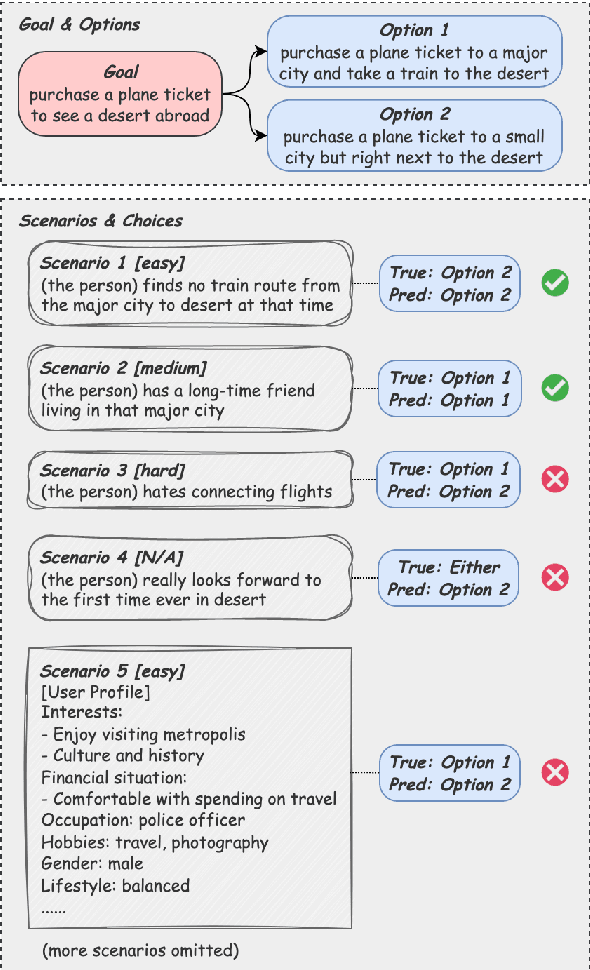
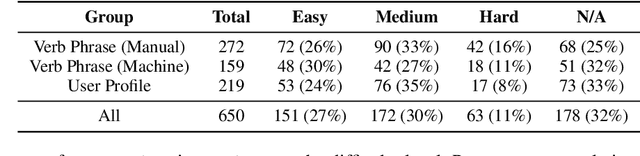
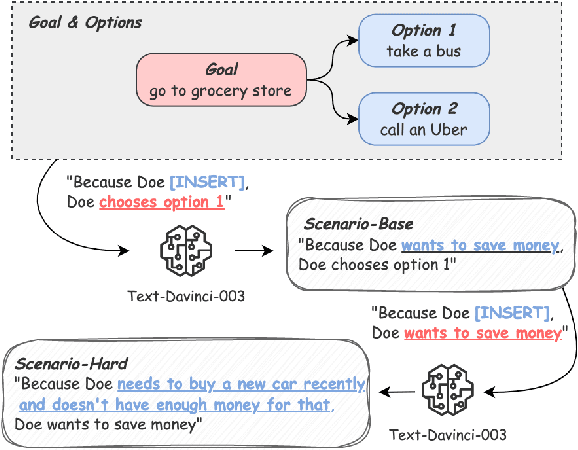

Script learning studies how daily events unfold. Previous works tend to consider a script as a linear sequence of events while ignoring the potential branches that arise due to people's circumstantial choices. We hence propose Choice-75, the first benchmark that challenges intelligent systems to predict decisions given descriptive scenarios, containing 75 scripts and more than 600 scenarios. While large language models demonstrate overall decent performances, there is still notable room for improvement in many hard scenarios.
Private Matrix Factorization with Public Item Features
Sep 17, 2023We consider the problem of training private recommendation models with access to public item features. Training with Differential Privacy (DP) offers strong privacy guarantees, at the expense of loss in recommendation quality. We show that incorporating public item features during training can help mitigate this loss in quality. We propose a general approach based on collective matrix factorization (CMF), that works by simultaneously factorizing two matrices: the user feedback matrix (representing sensitive data) and an item feature matrix that encodes publicly available (non-sensitive) item information. The method is conceptually simple, easy to tune, and highly scalable. It can be applied to different types of public item data, including: (1) categorical item features; (2) item-item similarities learned from public sources; and (3) publicly available user feedback. Furthermore, these data modalities can be collectively utilized to fully leverage public data. Evaluating our method on a standard DP recommendation benchmark, we find that using public item features significantly narrows the quality gap between private models and their non-private counterparts. As privacy constraints become more stringent, models rely more heavily on public side features for recommendation. This results in a smooth transition from collaborative filtering to item-based contextual recommendations.
Designs and Implementations in Neural Network-based Video Coding
Sep 13, 2023
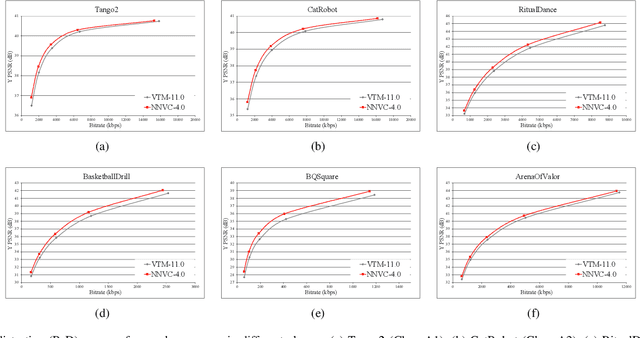
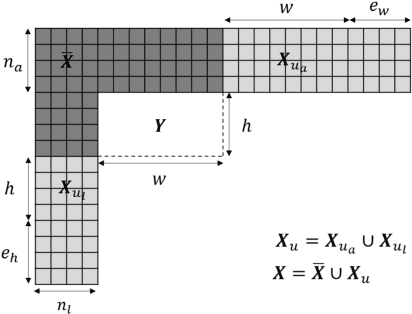
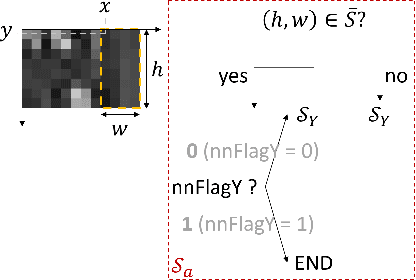
The past decade has witnessed the huge success of deep learning in well-known artificial intelligence applications such as face recognition, autonomous driving, and large language model like ChatGPT. Recently, the application of deep learning has been extended to a much wider range, with neural network-based video coding being one of them. Neural network-based video coding can be performed at two different levels: embedding neural network-based (NN-based) coding tools into a classical video compression framework or building the entire compression framework upon neural networks. This paper elaborates some of the recent exploration efforts of JVET (Joint Video Experts Team of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC29) in the name of neural network-based video coding (NNVC), falling in the former category. Specifically, this paper discusses two major NN-based video coding technologies, i.e. neural network-based intra prediction and neural network-based in-loop filtering, which have been investigated for several meeting cycles in JVET and finally adopted into the reference software of NNVC. Extensive experiments on top of the NNVC have been conducted to evaluate the effectiveness of the proposed techniques. Compared with VTM-11.0_nnvc, the proposed NN-based coding tools in NNVC-4.0 could achieve {11.94%, 21.86%, 22.59%}, {9.18%, 19.76%, 20.92%}, and {10.63%, 21.56%, 23.02%} BD-rate reductions on average for {Y, Cb, Cr} under random-access, low-delay, and all-intra configurations respectively.
SAMUS: Adapting Segment Anything Model for Clinically-Friendly and Generalizable Ultrasound Image Segmentation
Sep 13, 2023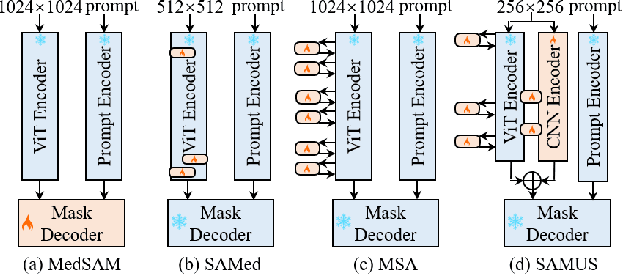
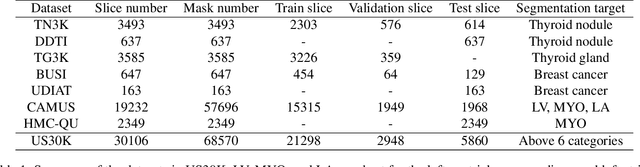
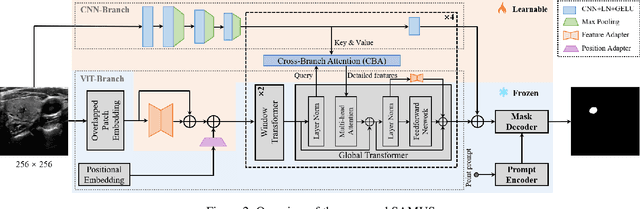
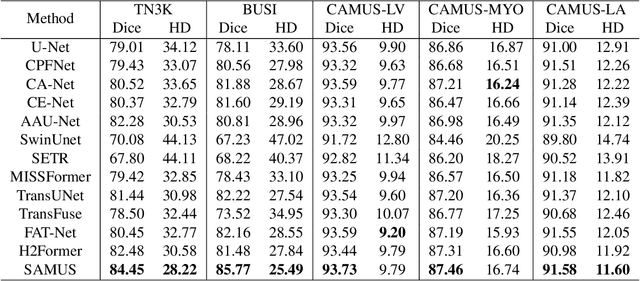
Segment anything model (SAM), an eminent universal image segmentation model, has recently gathered considerable attention within the domain of medical image segmentation. Despite the remarkable performance of SAM on natural images, it grapples with significant performance degradation and limited generalization when confronted with medical images, particularly with those involving objects of low contrast, faint boundaries, intricate shapes, and diminutive sizes. In this paper, we propose SAMUS, a universal model tailored for ultrasound image segmentation. In contrast to previous SAM-based universal models, SAMUS pursues not only better generalization but also lower deployment cost, rendering it more suitable for clinical applications. Specifically, based on SAM, a parallel CNN branch is introduced to inject local features into the ViT encoder through cross-branch attention for better medical image segmentation. Then, a position adapter and a feature adapter are developed to adapt SAM from natural to medical domains and from requiring large-size inputs (1024x1024) to small-size inputs (256x256) for more clinical-friendly deployment. A comprehensive ultrasound dataset, comprising about 30k images and 69k masks and covering six object categories, is collected for verification. Extensive comparison experiments demonstrate SAMUS's superiority against the state-of-the-art task-specific models and universal foundation models under both task-specific evaluation and generalization evaluation. Moreover, SAMUS is deployable on entry-level GPUs, as it has been liberated from the constraints of long sequence encoding. The code, data, and models will be released at https://github.com/xianlin7/SAMUS.
Timbre-reserved Adversarial Attack in Speaker Identification
Sep 02, 2023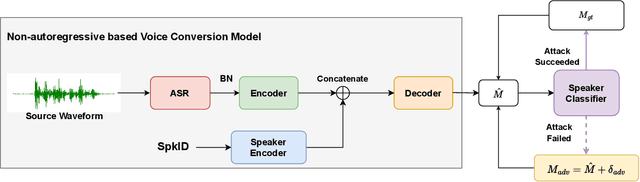
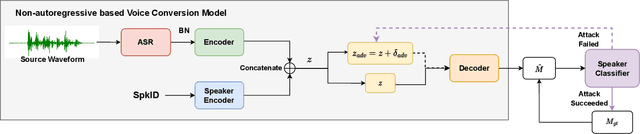
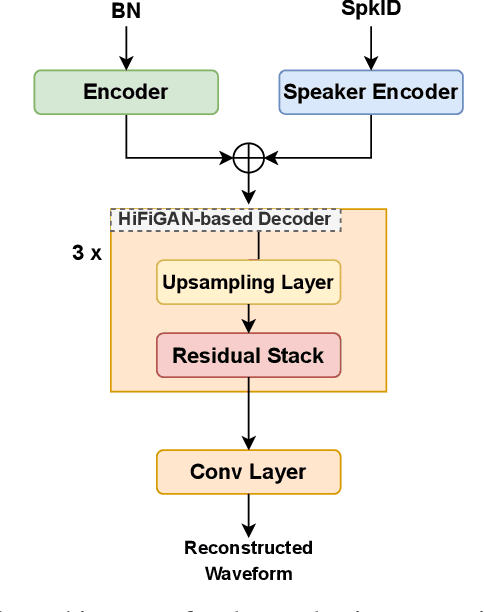
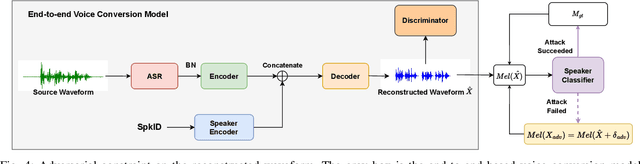
As a type of biometric identification, a speaker identification (SID) system is confronted with various kinds of attacks. The spoofing attacks typically imitate the timbre of the target speakers, while the adversarial attacks confuse the SID system by adding a well-designed adversarial perturbation to an arbitrary speech. Although the spoofing attack copies a similar timbre as the victim, it does not exploit the vulnerability of the SID model and may not make the SID system give the attacker's desired decision. As for the adversarial attack, despite the SID system can be led to a designated decision, it cannot meet the specified text or speaker timbre requirements for the specific attack scenarios. In this study, to make the attack in SID not only leverage the vulnerability of the SID model but also reserve the timbre of the target speaker, we propose a timbre-reserved adversarial attack in the speaker identification. We generate the timbre-reserved adversarial audios by adding an adversarial constraint during the different training stages of the voice conversion (VC) model. Specifically, the adversarial constraint is using the target speaker label to optimize the adversarial perturbation added to the VC model representations and is implemented by a speaker classifier joining in the VC model training. The adversarial constraint can help to control the VC model to generate the speaker-wised audio. Eventually, the inference of the VC model is the ideal adversarial fake audio, which is timbre-reserved and can fool the SID system.
Training-Free Energy Beamforming Assisted by Wireless Sensing
Aug 18, 2023
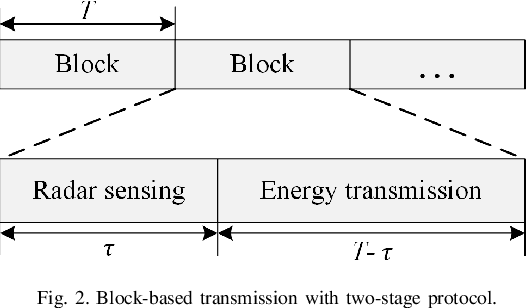
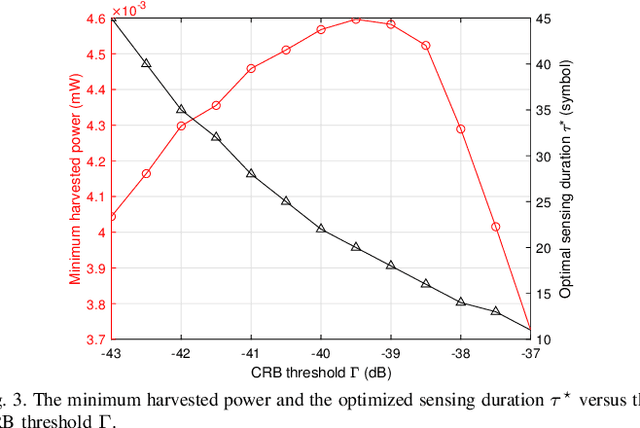
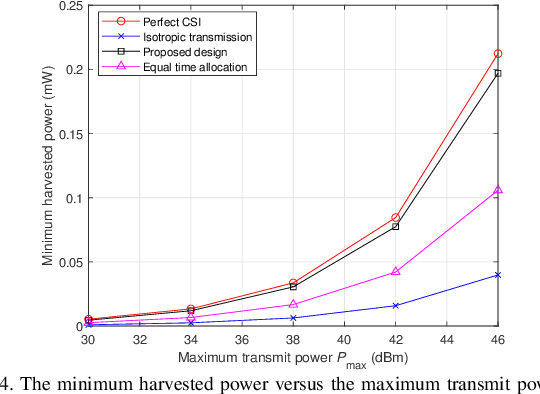
This paper studies the transmit energy beamforming in a multi-antenna wireless power transfer (WPT) system, in which an access point (AP) equipped with a uniform linear array (ULA) sends radio signals to wirelessly charge multiple single-antenna energy receivers (ERs). Different from conventional energy beamforming designs that require the AP to acquire the channel state information (CSI) via training and feedback, we propose a new training-free energy beamforming approach assisted by wireless radar sensing, which is implemented based on the following two-stage protocol. In the first stage, the AP performs wireless radar sensing to estimate the path gain and angle parameters of the ERs for constructing the corresponding CSI. In the second stage, the AP implements the transmit energy beamforming based on the constructed CSI to efficiently charge these ERs in a fair manner. Under this setup, first, we jointly optimize the sensing beamformers and duration in the first stage to minimize the sensing duration, while ensuring a given accuracy threshold for parameters estimation subject to the maximum transmit power constraint at the AP. Next, we optimize the energy beamformers in the second stage to maximize the minimum harvested energy by all ERs. In this approach, the estimation accuracy threshold for the first stage is properly designed to balance the resource allocation between the two stages for optimizing the ultimate energy harvesting performance. Finally, numerical results show that the proposed training-free energy beamforming design performs close to the performance upper bound with perfect CSI, and outperforms the benchmark schemes without such joint optimization and that with isotropic transmission.
Semi-Supervised Dual-Stream Self-Attentive Adversarial Graph Contrastive Learning for Cross-Subject EEG-based Emotion Recognition
Aug 13, 2023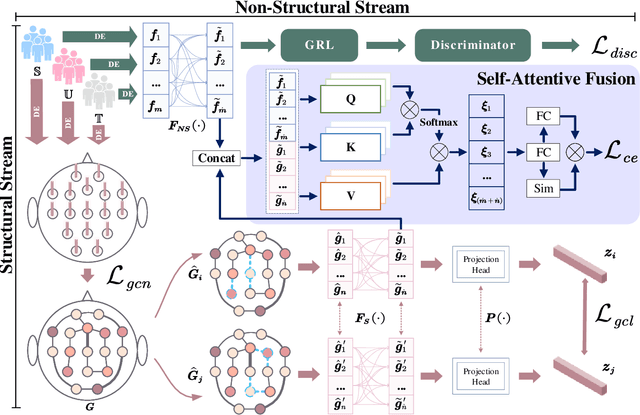
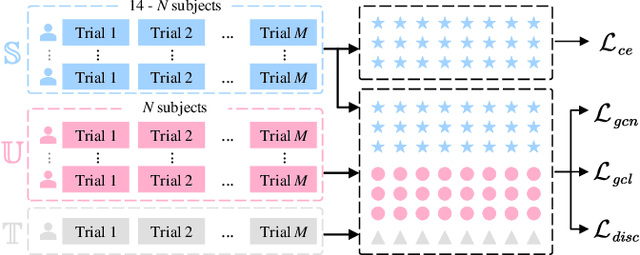
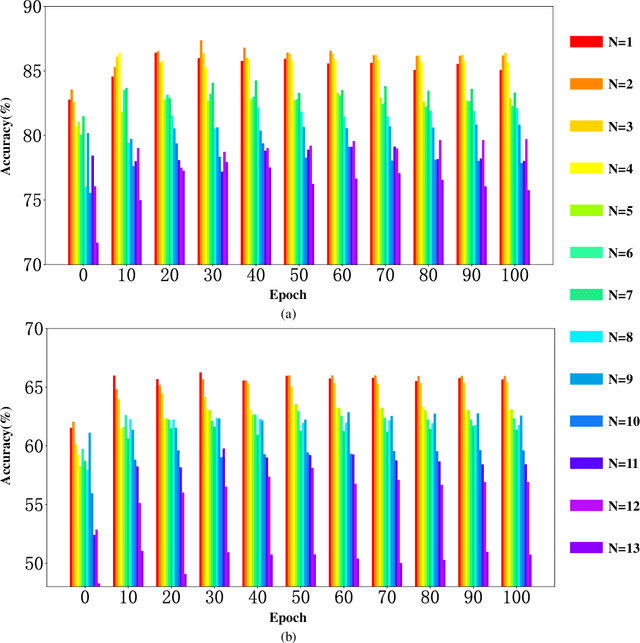
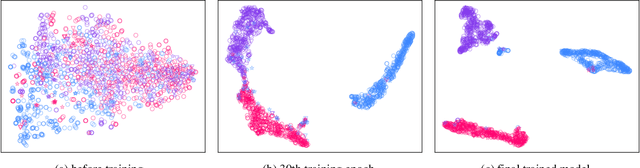
Electroencephalography (EEG) is an objective tool for emotion recognition with promising applications. However, the scarcity of labeled data remains a major challenge in this field, limiting the widespread use of EEG-based emotion recognition. In this paper, a semi-supervised Dual-stream Self-Attentive Adversarial Graph Contrastive learning framework (termed as DS-AGC) is proposed to tackle the challenge of limited labeled data in cross-subject EEG-based emotion recognition. The DS-AGC framework includes two parallel streams for extracting non-structural and structural EEG features. The non-structural stream incorporates a semi-supervised multi-domain adaptation method to alleviate distribution discrepancy among labeled source domain, unlabeled source domain, and unknown target domain. The structural stream develops a graph contrastive learning method to extract effective graph-based feature representation from multiple EEG channels in a semi-supervised manner. Further, a self-attentive fusion module is developed for feature fusion, sample selection, and emotion recognition, which highlights EEG features more relevant to emotions and data samples in the labeled source domain that are closer to the target domain. Extensive experiments conducted on two benchmark databases (SEED and SEED-IV) using a semi-supervised cross-subject leave-one-subject-out cross-validation evaluation scheme show that the proposed model outperforms existing methods under different incomplete label conditions (with an average improvement of 5.83% on SEED and 6.99% on SEED-IV), demonstrating its effectiveness in addressing the label scarcity problem in cross-subject EEG-based emotion recognition.