 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabOSBench: Benchmarking Computer Use Agents for Scientific Instrument Control
Jun 15, 2026Current computer-use benchmarks primarily focus on software operation tasks in virtualized systems, whereas scientific instrumentation scenarios require coordinated control over complex interfaces, and feedback-driven parameter adjustment. However, directly evaluating agents on physical high-precision instruments is impractical due to high cost, safety risks, limited accessibility, and difficulty in ensuring reproducible evaluation. This motivates the need for a simulated yet realistic testbed that preserves the operational challenges of scientific instruments while enabling scalable and safe benchmarking. To this end, we introduce LabOSBench, a challenging benchmark for multimodal GUI agents built on a suite of web-based scientific-instrument simulators. Operating directly via a browser, LabOSBench avoids resource-heavy OS virtualization while supporting flexible task configuration and execution-based evaluation. Specifically, LabOSBench constructs 96 subtasks across eight instrument simulators, covering workflows from sample loading, alignment, parameter tuning, and data acquisition to result inspection. We evaluate general-purpose vision-language models, specialized GUI agent models, and advanced agentic frameworks at both subtask and end-to-end levels. Our experiments reveal that while existing agents can complete many structured GUI subtasks, they still struggle with feedback-driven operations and long-horizon workflow execution. Overall, LabOSBench provides a reproducible, low-cost testbed for advancing computer-using agents toward scientific-instrument control.
Nonperiodic dynamic CT reconstruction using backward-warping INR with regularization of diffeomorphism (BIRD)
May 06, 2025



Dynamic computed tomography (CT) reconstruction faces significant challenges in addressing motion artifacts, particularly for nonperiodic rapid movements such as cardiac imaging with fast heart rates. Traditional methods struggle with the extreme limited-angle problems inherent in nonperiodic cases. Deep learning methods have improved performance but face generalization challenges. Recent implicit neural representation (INR) techniques show promise through self-supervised deep learning, but have critical limitations: computational inefficiency due to forward-warping modeling, difficulty balancing DVF complexity with anatomical plausibility, and challenges in preserving fine details without additional patient-specific pre-scans. This paper presents a novel INR-based framework, BIRD, for nonperiodic dynamic CT reconstruction. It addresses these challenges through four key contributions: (1) backward-warping deformation that enables direct computation of each dynamic voxel with significantly reduced computational cost, (2) diffeomorphism-based DVF regularization that ensures anatomically plausible deformations while maintaining representational capacity, (3) motion-compensated analytical reconstruction that enhances fine details without requiring additional pre-scans, and (4) dimensional-reduction design for efficient 4D coordinate encoding. Through various simulations and practical studies, including digital and physical phantoms and retrospective patient data, we demonstrate the effectiveness of our approach for nonperiodic dynamic CT reconstruction with enhanced details and reduced motion artifacts. The proposed framework enables more accurate dynamic CT reconstruction with potential clinical applications, such as one-beat cardiac reconstruction, cinematic image sequences for functional imaging, and motion artifact reduction in conventional CT scans.
A square cross-section FOV rotational CL and its analytical reconstruction method
Jun 18, 2024



Rotational computed laminography (CL) has broad application potential in three-dimensional imaging of plate-like objects, as it only needs x-ray to pass through the tested object in the thickness direction during the imaging process. In this study, a square cross-section FOV rotational CL (SC-CL) was proposed. Then, the FDK-type analytical reconstruction algorithm applicable to the SC-CL was derived. On this basis, the proposed method was validated through numerical experiments.
Investigation of domain gap problem in several deep-learning-based CT metal artefact reduction methods
Nov 25, 2021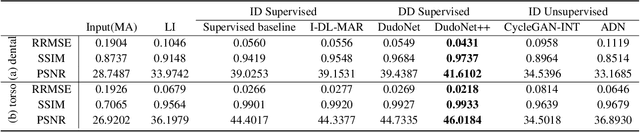
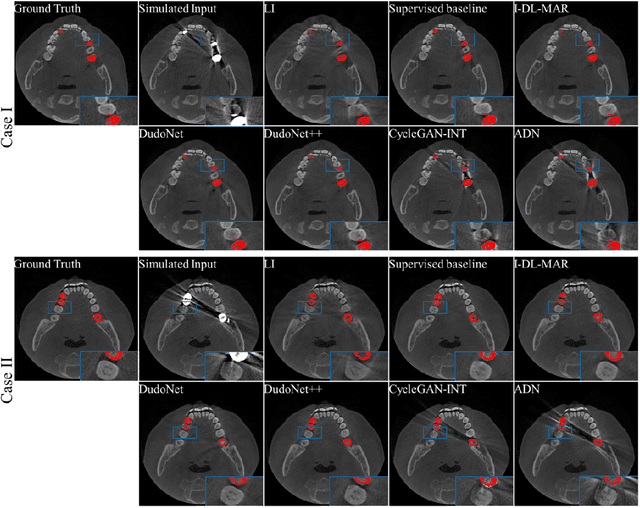
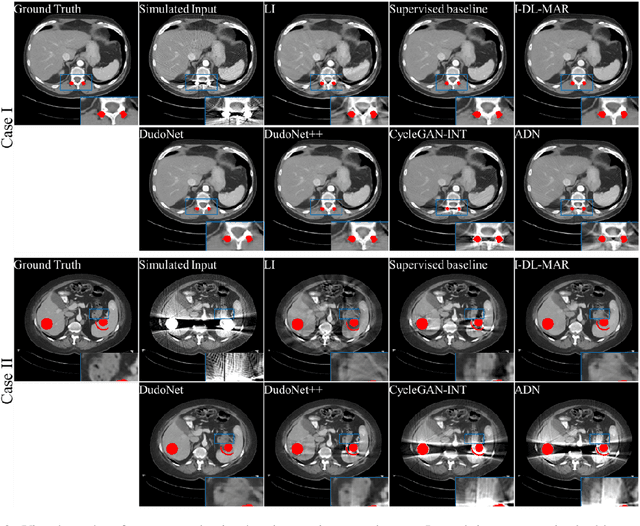
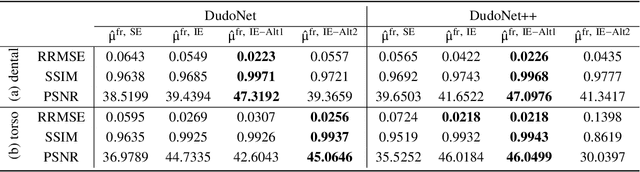
Metal artefacts in CT images may disrupt image quality and interfere with diagnosis. Recently many deep-learning-based CT metal artefact reduction (MAR) methods have been proposed. Current deep MAR methods may be troubled with domain gap problem, where methods trained on simulated data cannot perform well on practical data. In this work, we experimentally investigate two image-domain supervised methods, two dual-domain supervised methods and two image-domain unsupervised methods on a dental dataset and a torso dataset, to explore whether domain gap problem exists or is overcome. We find that I-DL-MAR and DudoNet are effective for practical data of the torso dataset, indicating the domain gap problem is solved. However, none of the investigated methods perform satisfactorily on practical data of the dental dataset. Based on the experimental results, we further analyze the causes of domain gap problem for each method and dataset, which may be beneficial for improving existing methods or designing new ones. The findings suggest that the domain gap problem in deep MAR methods remains to be addressed.
A novel deep learning-based method for monochromatic image synthesis from spectral CT using photon-counting detectors
Jul 20, 2020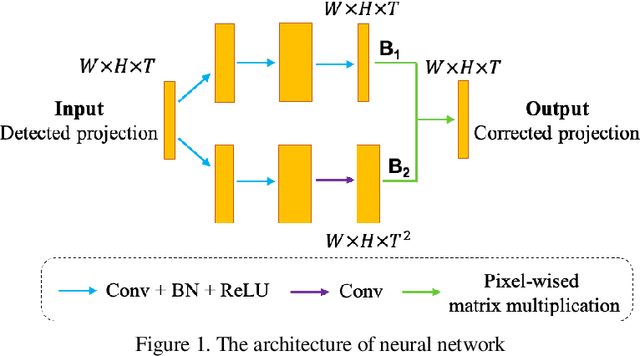
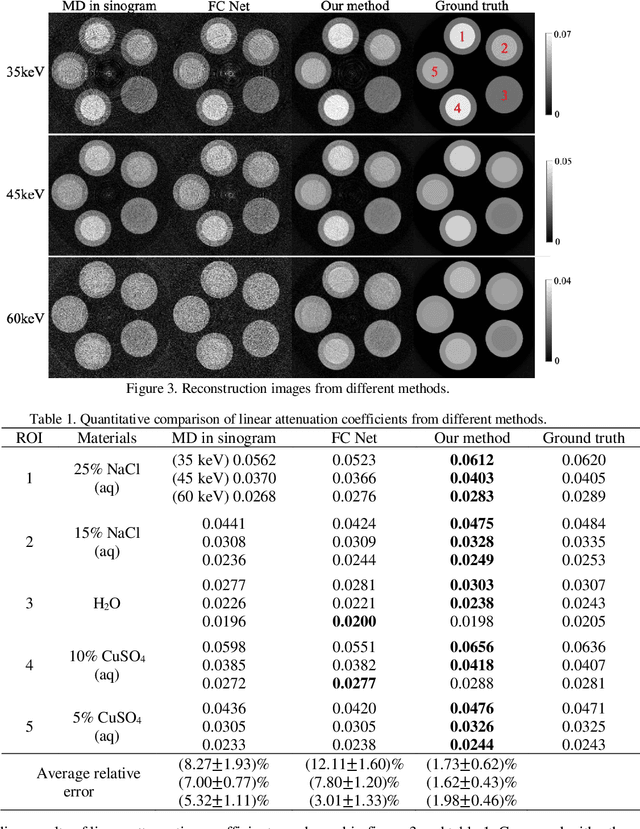

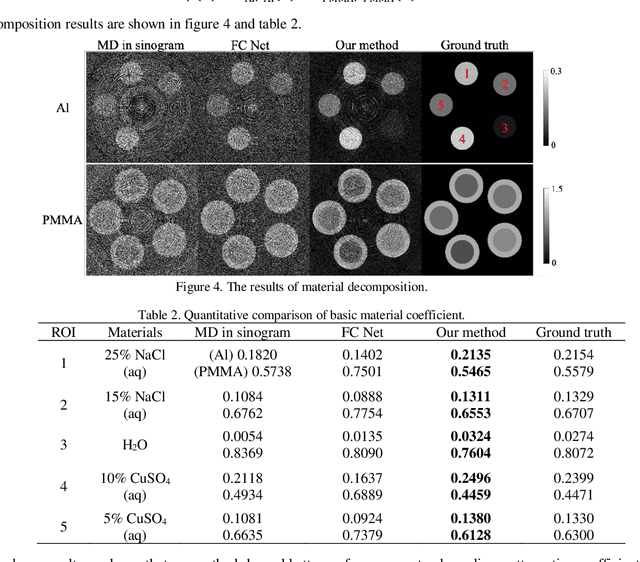
With the growing technology of photon-counting detectors (PCD), spectral CT is a widely concerned topic which has the potential of material differentiation. However, due to some non-ideal factors such as cross talk and pulse pile-up of the detectors, direct reconstruction from detected spectrum without any corrections will get a wrong result. Conventional methods try to model these factors using calibration and make corrections accordingly, but depend on the preciseness of the model. To solve this problem, in this paper, we proposed a novel deep learning-based monochromatic image synthesis method working in sinogram domain. Different from previous deep learning-based methods aimed at this problem, we designed a novel network architecture according to the physical model of cross talk, and it can solve this problem better in an ingenious way. Our method was tested on a cone-beam CT (CBCT) system equipped with a PCD. After using FDK algorithm on the corrected projection, we got quite more accurate results with less noise, which showed the feasibility of monochromatic image synthesis by our method.
A cascaded dual-domain deep learning reconstruction method for sparsely spaced multidetector helical CT
Oct 23, 2019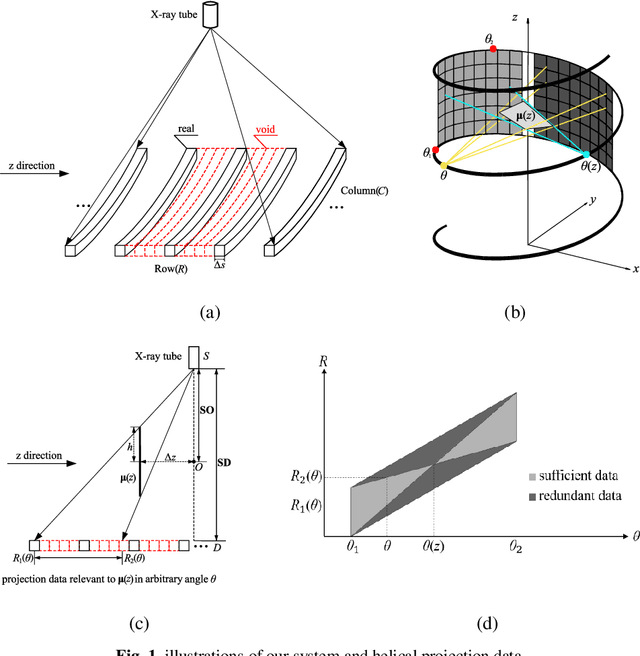

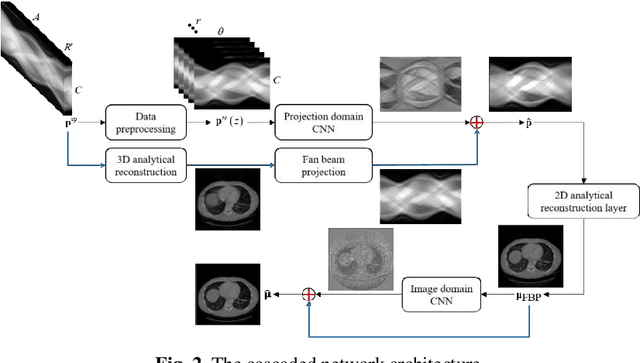
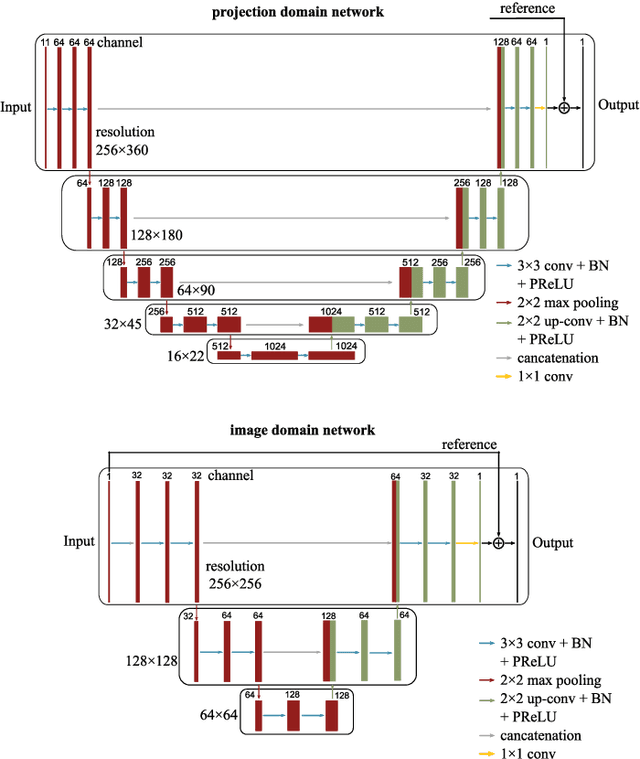
Helical CT has been widely used in clinical diagnosis. Sparsely spaced multidetector in z direction can increase the coverage of the detector provided limited detector rows. It can speed up volumetric CT scan, lower the radiation dose and reduce motion artifacts. However, it leads to insufficient data for reconstruction. That means reconstructions from general analytical methods will have severe artifacts. Iterative reconstruction methods might be able to deal with this situation but with the cost of huge computational load. In this work, we propose a cascaded dual-domain deep learning method that completes both data transformation in projection domain and error reduction in image domain. First, a convolutional neural network (CNN) in projection domain is constructed to estimate missing helical projection data and converting helical projection data to 2D fan-beam projection data. This step is to suppress helical artifacts and reduce the following computational cost. Then, an analytical linear operator is followed to transfer the data from projection domain to image domain. Finally, an image domain CNN is added to improve image quality further. These three steps work as an entirety and can be trained end to end. The overall network is trained using a simulated lung CT dataset with Poisson noise from 25 patients. We evaluate the trained network on another three patients and obtain very encouraging results with both visual examination and quantitative comparison. The resulting RRMSE is 6.56% and the SSIM is 99.60%. In addition, we test the trained network on the lung CT dataset with different noise level and a new dental CT dataset to demonstrate the generalization and robustness of our method.