 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Feature Pyramid Tokenization and Open Vocabulary Semantic Segmentation
Dec 18, 2024



The visual understanding are often approached from 3 granular levels: image, patch and pixel. Visual Tokenization, trained by self-supervised reconstructive learning, compresses visual data by codebook in patch-level with marginal information loss, but the visual tokens does not have semantic meaning. Open Vocabulary semantic segmentation benefits from the evolving Vision-Language models (VLMs) with strong image zero-shot capability, but transferring image-level to pixel-level understanding remains an imminent challenge. In this paper, we treat segmentation as tokenizing pixels and study a united perceptual and semantic token compression for all granular understanding and consequently facilitate open vocabulary semantic segmentation. Referring to the cognitive process of pretrained VLM where the low-level features are progressively composed to high-level semantics, we propose Feature Pyramid Tokenization (PAT) to cluster and represent multi-resolution feature by learnable codebooks and then decode them by joint learning pixel reconstruction and semantic segmentation. We design loosely coupled pixel and semantic learning branches. The pixel branch simulates bottom-up composition and top-down visualization of codebook tokens, while the semantic branch collectively fuse hierarchical codebooks as auxiliary segmentation guidance. Our experiments show that PAT enhances the semantic intuition of VLM feature pyramid, improves performance over the baseline segmentation model and achieves competitive performance on open vocabulary semantic segmentation benchmark. Our model is parameter-efficient for VLM integration and flexible for the independent tokenization. We hope to give inspiration not only on improving segmentation but also on semantic visual token utilization.
On the Limit of Language Models as Planning Formalizers
Dec 13, 2024



Large Language Models have been shown to fail to create executable and verifiable plans in grounded environments. An emerging line of work shows success in using LLM as a formalizer to generate a formal representation (e.g., PDDL) of the planning domain, which can be deterministically solved to find a plan. We systematically evaluate this methodology while bridging some major gaps. While previous work only generates a partial PDDL representation given templated and thus unrealistic environment descriptions, we generate the complete representation given descriptions of various naturalness levels. Among an array of observations critical to improve LLMs' formal planning ability, we note that large enough models can effectively formalize descriptions as PDDL, outperforming those directly generating plans, while being robust to lexical perturbation. As the descriptions become more natural-sounding, we observe a decrease in performance and provide detailed error analysis.
OmniDrag: Enabling Motion Control for Omnidirectional Image-to-Video Generation
Dec 12, 2024



As virtual reality gains popularity, the demand for controllable creation of immersive and dynamic omnidirectional videos (ODVs) is increasing. While previous text-to-ODV generation methods achieve impressive results, they struggle with content inaccuracies and inconsistencies due to reliance solely on textual inputs. Although recent motion control techniques provide fine-grained control for video generation, directly applying these methods to ODVs often results in spatial distortion and unsatisfactory performance, especially with complex spherical motions. To tackle these challenges, we propose OmniDrag, the first approach enabling both scene- and object-level motion control for accurate, high-quality omnidirectional image-to-video generation. Building on pretrained video diffusion models, we introduce an omnidirectional control module, which is jointly fine-tuned with temporal attention layers to effectively handle complex spherical motion. In addition, we develop a novel spherical motion estimator that accurately extracts motion-control signals and allows users to perform drag-style ODV generation by simply drawing handle and target points. We also present a new dataset, named Move360, addressing the scarcity of ODV data with large scene and object motions. Experiments demonstrate the significant superiority of OmniDrag in achieving holistic scene-level and fine-grained object-level control for ODV generation. The project page is available at https://lwq20020127.github.io/OmniDrag.
UniScene: Unified Occupancy-centric Driving Scene Generation
Dec 06, 2024Generating high-fidelity, controllable, and annotated training data is critical for autonomous driving. Existing methods typically generate a single data form directly from a coarse scene layout, which not only fails to output rich data forms required for diverse downstream tasks but also struggles to model the direct layout-to-data distribution. In this paper, we introduce UniScene, the first unified framework for generating three key data forms - semantic occupancy, video, and LiDAR - in driving scenes. UniScene employs a progressive generation process that decomposes the complex task of scene generation into two hierarchical steps: (a) first generating semantic occupancy from a customized scene layout as a meta scene representation rich in both semantic and geometric information, and then (b) conditioned on occupancy, generating video and LiDAR data, respectively, with two novel transfer strategies of Gaussian-based Joint Rendering and Prior-guided Sparse Modeling. This occupancy-centric approach reduces the generation burden, especially for intricate scenes, while providing detailed intermediate representations for the subsequent generation stages. Extensive experiments demonstrate that UniScene outperforms previous SOTAs in the occupancy, video, and LiDAR generation, which also indeed benefits downstream driving tasks.
A Framework For Image Synthesis Using Supervised Contrastive Learning
Dec 05, 2024Text-to-image (T2I) generation aims at producing realistic images corresponding to text descriptions. Generative Adversarial Network (GAN) has proven to be successful in this task. Typical T2I GANs are 2 phase methods that first pretrain an inter-modal representation from aligned image-text pairs and then use GAN to train image generator on that basis. However, such representation ignores the inner-modal semantic correspondence, e.g. the images with same label. The semantic label in priory describes the inherent distribution pattern with underlying cross-image relationships, which is supplement to the text description for understanding the full characteristics of image. In this paper, we propose a framework leveraging both inter- and inner-modal correspondence by label guided supervised contrastive learning. We extend the T2I GANs to two parameter-sharing contrast branches in both pretraining and generation phases. This integration effectively clusters the semantically similar image-text pair representations, thereby fostering the generation of higher-quality images. We demonstrate our framework on four novel T2I GANs by both single-object dataset CUB and multi-object dataset COCO, achieving significant improvements in the Inception Score (IS) and Frechet Inception Distance (FID) metrics of imagegeneration evaluation. Notably, on more complex multi-object COCO, our framework improves FID by 30.1%, 27.3%, 16.2% and 17.1% for AttnGAN, DM-GAN, SSA-GAN and GALIP, respectively. We also validate our superiority by comparing with other label guided T2I GANs. The results affirm the effectiveness and competitiveness of our approach in advancing the state-of-the-art GAN for T2I generation
A Multi-Agent Framework for Extensible Structured Text Generation in PLCs
Dec 03, 2024



Programmable Logic Controllers (PLCs) are microcomputers essential for automating factory operations. Structured Text (ST), a high-level language adhering to the IEC 61131-3 standard, is pivotal for PLCs due to its ability to express logic succinctly and to seamlessly integrate with other languages within the same standard. However, vendors develop their own customized versions of ST, and the lack of comprehensive and standardized documentation for the full semantics of ST has contributed to inconsistencies in how the language is implemented. Consequently, the steep learning curve associated with ST, combined with ever-evolving industrial requirements, presents significant challenges for developers. In response to these issues, we present AutoPLC, an LLM-based approach designed to automate the generation of vendor-specific ST code. To facilitate effective code generation, we first built a comprehensive knowledge base, including Rq2ST Case Library (requirements and corresponding implementations) and Instruction libraries. Then we developed a retrieval module to incorporate the domain-specific knowledge by identifying pertinent cases and instructions, guiding the LLM to generate code that meets the requirements. In order to verify and improve the quality of the generated code, we designed an adaptable code checker. If errors are detected, we initiate an iterative self-improvement process to instruct the LLM to revise the generated code. We evaluate AutoPLC's performance against seven state-of-the-art baselines using three benchmarks, one for open-source basic ST and two for commercial Structured Control Language (SCL) from Siemens. The results show that our approach consistently achieves superior performance across all benchmarks. Ablation study emphasizes the significance of our modules. Further manual analysis confirm the practical utility of the ST code generated by AutoPLC.
Explainable CTR Prediction via LLM Reasoning
Dec 03, 2024



Recommendation Systems have become integral to modern user experiences, but lack transparency in their decision-making processes. Existing explainable recommendation methods are hindered by reliance on a post-hoc paradigm, wherein explanation generators are trained independently of the underlying recommender models. This paradigm necessitates substantial human effort in data construction and raises concerns about explanation reliability. In this paper, we present ExpCTR, a novel framework that integrates large language model based explanation generation directly into the CTR prediction process. Inspired by recent advances in reinforcement learning, we employ two carefully designed reward mechanisms, LC alignment, which ensures explanations reflect user intentions, and IC alignment, which maintains consistency with traditional ID-based CTR models. Our approach incorporates an efficient training paradigm with LoRA and a three-stage iterative process. ExpCTR circumvents the need for extensive explanation datasets while fostering synergy between CTR prediction and explanation generation. Experimental results demonstrate that ExpCTR significantly enhances both recommendation accuracy and interpretability across three real-world datasets.
Driving Scene Synthesis on Free-form Trajectories with Generative Prior
Dec 02, 2024



Driving scene synthesis along free-form trajectories is essential for driving simulations to enable closed-loop evaluation of end-to-end driving policies. While existing methods excel at novel view synthesis on recorded trajectories, they face challenges with novel trajectories due to limited views of driving videos and the vastness of driving environments. To tackle this challenge, we propose a novel free-form driving view synthesis approach, dubbed DriveX, by leveraging video generative prior to optimize a 3D model across a variety of trajectories. Concretely, we crafted an inverse problem that enables a video diffusion model to be utilized as a prior for many-trajectory optimization of a parametric 3D model (e.g., Gaussian splatting). To seamlessly use the generative prior, we iteratively conduct this process during optimization. Our resulting model can produce high-fidelity virtual driving environments outside the recorded trajectory, enabling free-form trajectory driving simulation. Beyond real driving scenes, DriveX can also be utilized to simulate virtual driving worlds from AI-generated videos.
Query Performance Explanation through Large Language Model for HTAP Systems
Dec 02, 2024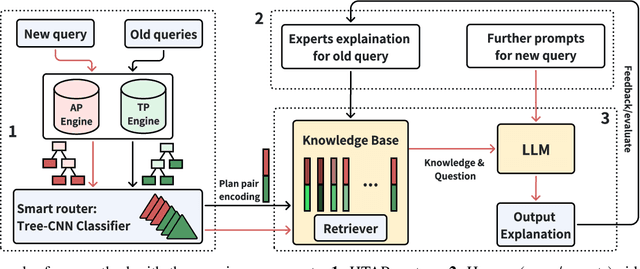



In hybrid transactional and analytical processing (HTAP) systems, users often struggle to understand why query plans from one engine (OLAP or OLTP) perform significantly slower than those from another. Although optimizers provide plan details via the EXPLAIN function, these explanations are frequently too technical for non-experts and offer limited insights into performance differences across engines. To address this, we propose a novel framework that leverages large language models (LLMs) to explain query performance in HTAP systems. Built on Retrieval-Augmented Generation (RAG), our framework constructs a knowledge base that stores historical query executions and expert-curated explanations. To enable efficient retrieval of relevant knowledge, query plans are embedded using a lightweight tree-CNN classifier. This augmentation allows the LLM to generate clear, context-aware explanations of performance differences between engines. Our approach demonstrates the potential of LLMs in hybrid engine systems, paving the way for further advancements in database optimization and user support.
DroidCall: A Dataset for LLM-powered Android Intent Invocation
Nov 30, 2024



The growing capabilities of large language models in natural language understanding significantly strengthen existing agentic systems. To power performant on-device mobile agents for better data privacy, we introduce DroidCall, the first training and testing dataset for accurate Android intent invocation. With a highly flexible and reusable data generation pipeline, we constructed 10k samples in DroidCall. Given a task instruction in natural language, small language models such as Qwen2.5-3B and Gemma2-2B fine-tuned with DroidCall can approach or even surpass the capabilities of GPT-4o for accurate Android intent invocation. We also provide an end-to-end Android app equipped with these fine-tuned models to demonstrate the Android intent invocation process. The code and dataset are available at https://github.com/UbiquitousLearning/DroidCall.