 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model Planners do not Scale, but do Formalizers?
Mar 25, 2026Recent work shows overwhelming evidence that LLMs, even those trained to scale their reasoning trace, perform unsatisfactorily when solving planning problems too complex. Whether the same conclusion holds for LLM formalizers that generate solver-oriented programs remains unknown. We systematically show that LLM formalizers greatly out-scale LLM planners, some retaining perfect accuracy in the classic BlocksWorld domain with a huge state space of size up to $10^{165}$. While performance of smaller LLM formalizers degrades with problem complexity, we show that a divide-and-conquer formalizing technique can greatly improve its robustness. Finally, we introduce unraveling problems where one line of problem description realistically corresponds to exponentially many lines of formal language such as the Planning Domain Definition Language (PDDL), greatly challenging LLM formalizers. We tackle this challenge by introducing a new paradigm, namely LLM-as-higher-order-formalizer, where an LLM generates a program generator. This decouples token output from the combinatorial explosion of the underlying formalization and search space.
On the Limit of Language Models as Planning Formalizers
Dec 13, 2024



Large Language Models have been shown to fail to create executable and verifiable plans in grounded environments. An emerging line of work shows success in using LLM as a formalizer to generate a formal representation (e.g., PDDL) of the planning domain, which can be deterministically solved to find a plan. We systematically evaluate this methodology while bridging some major gaps. While previous work only generates a partial PDDL representation given templated and thus unrealistic environment descriptions, we generate the complete representation given descriptions of various naturalness levels. Among an array of observations critical to improve LLMs' formal planning ability, we note that large enough models can effectively formalize descriptions as PDDL, outperforming those directly generating plans, while being robust to lexical perturbation. As the descriptions become more natural-sounding, we observe a decrease in performance and provide detailed error analysis.
Adversarial Examples Generation for Reducing Implicit Gender Bias in Pre-trained Models
Oct 03, 2021
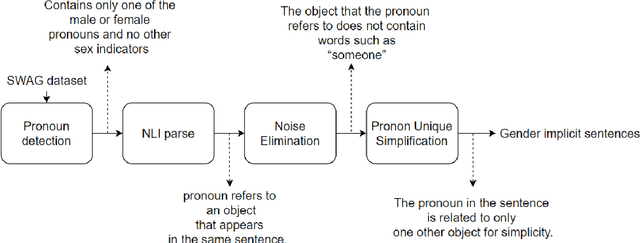

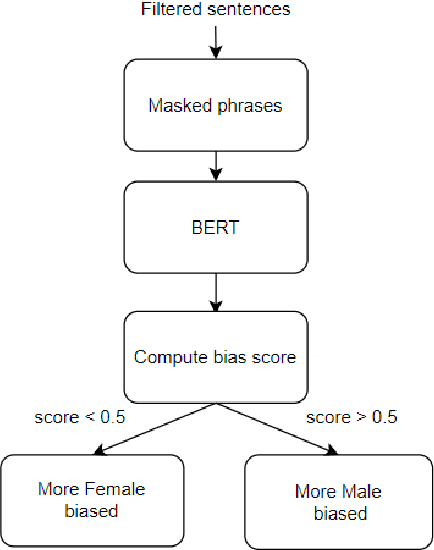
Over the last few years, Contextualized Pre-trained Neural Language Models, such as BERT, GPT, have shown significant gains in various NLP tasks. To enhance the robustness of existing pre-trained models, one way is adversarial examples generation and evaluation for conducting data augmentation or adversarial learning. In the meanwhile, gender bias embedded in the models seems to be a serious problem in practical applications. Many researches have covered the gender bias produced by word-level information(e.g. gender-stereotypical occupations), while few researchers have investigated the sentence-level cases and implicit cases. In this paper, we proposed a method to automatically generate implicit gender bias samples at sentence-level and a metric to measure gender bias. Samples generated by our method will be evaluated in terms of accuracy. The metric will be used to guide the generation of examples from Pre-trained models. Therefore, those examples could be used to impose attacks on Pre-trained Models. Finally, we discussed the evaluation efficacy of our generated examples on reducing gender bias for future research.