 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Training of the Superimposed Direct and Reflected Links in Reconfigurable Intelligent Surface Assisted Multiuser Communications
May 30, 2021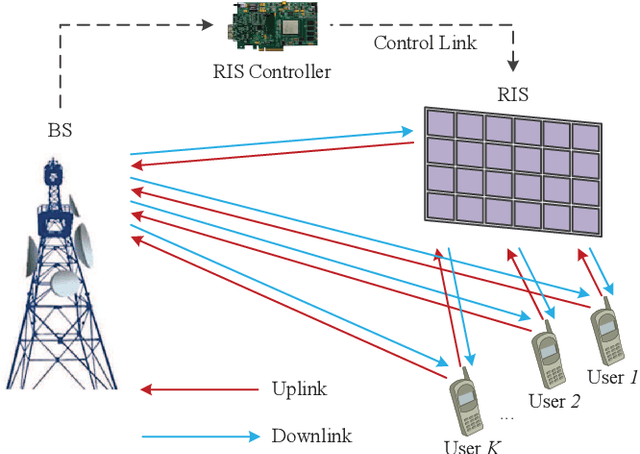
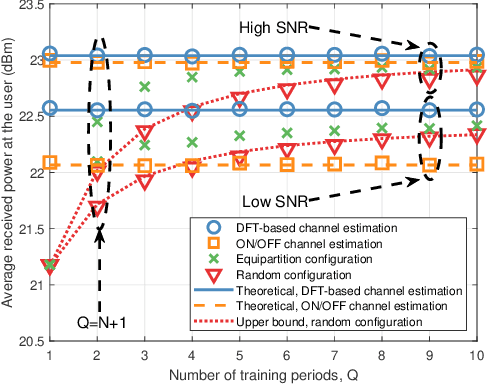
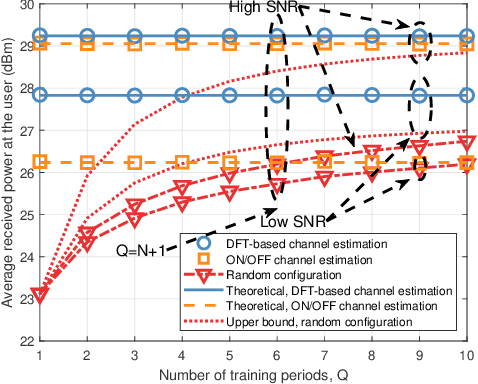
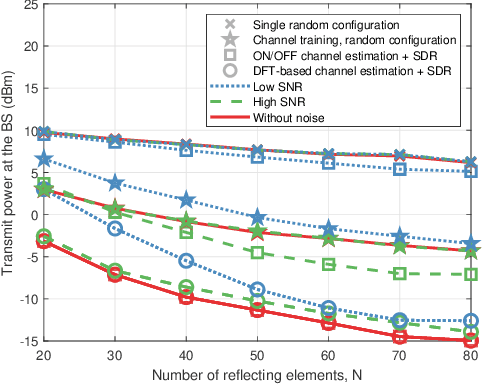
In Reconfigurable intelligent surface (RIS)-assisted systems the acquisition of CSI and the optimization of the reflecting coefficients constitute a pair of salient design issues. In this paper, a novel channel training protocol is proposed, which is capable of achieving a flexible performance vs. signalling and pilot overhead as well as implementation complexity trade-off. More specifically, first of all, we conceive a holistic channel estimation protocol, which integrates the existing channel estimation techniques and passive beamforming design. Secondly, we propose a new channel training framework. In contrast to the conventional channel estimation arrangements, our new framework divides the training phase into several periods, where the superimposed end-to-end channel is estimated instead of separately estimating the direct BS-user channel and cascaded reflected BS-RIS-user channels. As a result, the reflecting coefficients of the RIS are optimized by comparing the objective function values over multiple training periods. Moreover, the theoretical performance of our channel training protocol is analyzed and compared to that under the optimal reflecting coefficients. In addition, the potential benefits of our channel training protocol in reducing the complexity, pilot overhead as well as signalling overhead are also detailed. Thirdly, we derive the theoretical performance of channel estimation protocols and our channel training protocol in the presence of noise for a SISO scenario, which provides useful insights into the impact of the noise on the overall RIS performance. Finally, our numerical simulations characterize the performance of the proposed protocols and verify our theoretical analysis. In particular, the simulation results demonstrate that our channel training protocol is more competitive than the channel estimation protocol at low signal-to-noise ratios.
AGSFCOS: Based on attention mechanism and Scale-Equalizing pyramid network of object detection
May 20, 2021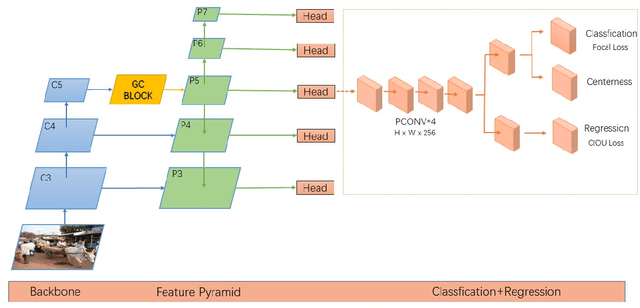

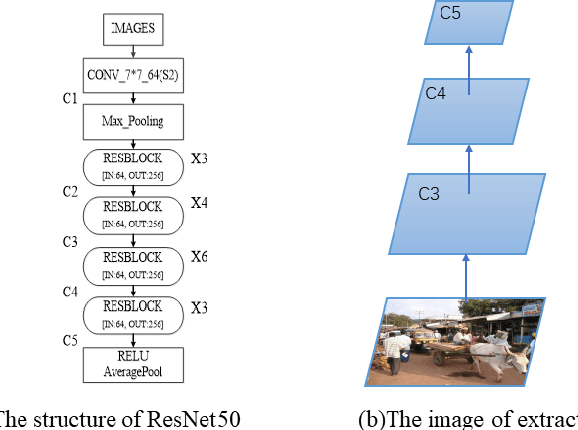
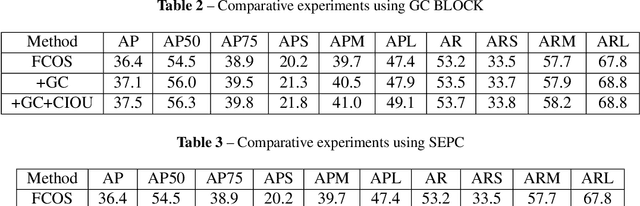
Recently, the anchor-free object detection model has shown great potential for accuracy and speed to exceed anchor-based object detection. Therefore, two issues are mainly studied in this article: (1) How to let the backbone network in the anchor-free object detection model learn feature extraction? (2) How to make better use of the feature pyramid network? In order to solve the above problems, Experiments show that our model has a certain improvement in accuracy compared with the current popular detection models on the COCO dataset, the designed attention mechanism module can capture contextual information well, improve detection accuracy, and use sepc network to help balance abstract and detailed information, and reduce the problem of semantic gap in the feature pyramid network. Whether it is anchor-based network model YOLOv3, Faster RCNN, or anchor-free network model Foveabox, FSAF, FCOS. Our optimal model can get 39.5% COCO AP under the background of ResNet50.
Towards a Model for LSH
May 11, 2021
As data volumes continue to grow, clustering and outlier detection algorithms are becoming increasingly time-consuming. Classical index structures for neighbor search are no longer sustainable due to the "curse of dimensionality". Instead, approximated index structures offer a good opportunity to significantly accelerate the neighbor search for clustering and outlier detection and to have the lowest possible error rate in the results of the algorithms. Locality-sensitive hashing is one of those. We indicate directions to model the properties of LSH.
Lite-FPN for Keypoint-based Monocular 3D Object Detection
May 01, 2021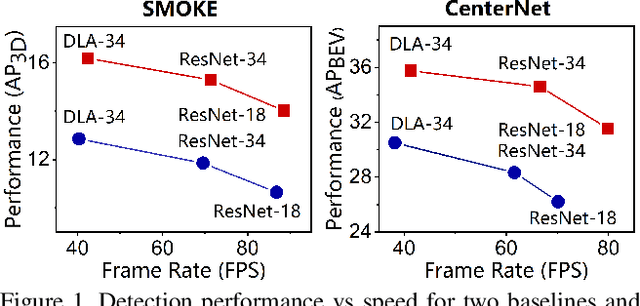
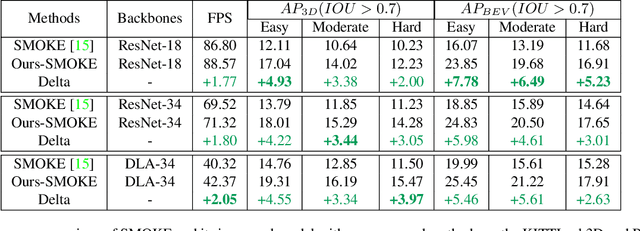
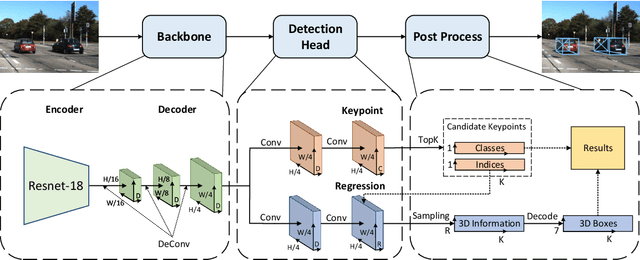
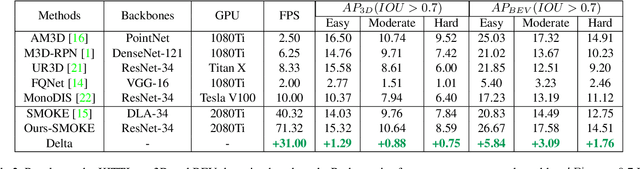
3D object detection with a single image is an essential and challenging task for autonomous driving. Recently, keypoint-based monocular 3D object detection has made tremendous progress and achieved great speed-accuracy trade-off. However, there still exists a huge gap with LIDAR-based methods in terms of accuracy. To improve their performance without sacrificing efficiency, we propose a sort of lightweight feature pyramid network called Lite-FPN to achieve multi-scale feature fusion in an effective and efficient way, which can boost the multi-scale detection capability of keypoint-based detectors. Besides, the misalignment between the classification score and the localization precision is further relieved by introducing a novel regression loss named attention loss. With the proposed loss, predictions with high confidence but poor localization are treated with more attention during the training phase. Comparative experiments based on several state-of-the-art keypoint-based detectors on the KITTI dataset show that our proposed method achieves significantly higher accuracy and frame rate at the same time. The code and pretrained models will be available at https://github.com/yanglei18/Lite-FPN.
Privacy-Preserving Federated Learning on Partitioned Attributes
Apr 29, 2021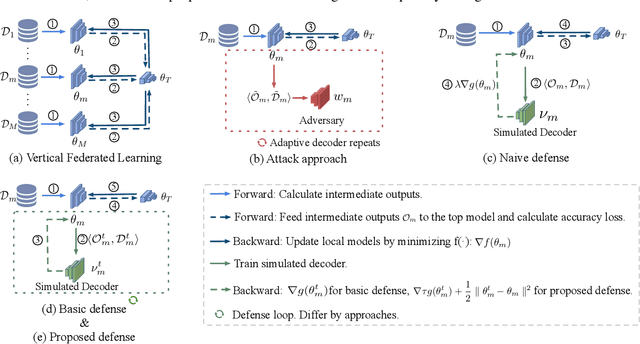

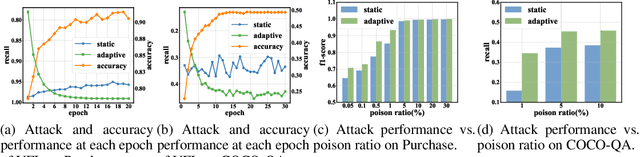
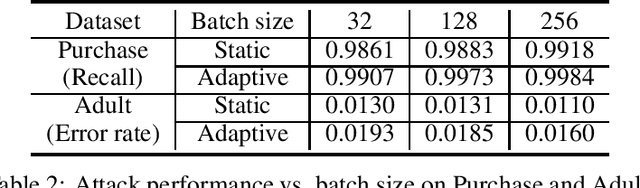
Real-world data is usually segmented by attributes and distributed across different parties. Federated learning empowers collaborative training without exposing local data or models. As we demonstrate through designed attacks, even with a small proportion of corrupted data, an adversary can accurately infer the input attributes. We introduce an adversarial learning based procedure which tunes a local model to release privacy-preserving intermediate representations. To alleviate the accuracy decline, we propose a defense method based on the forward-backward splitting algorithm, which respectively deals with the accuracy loss and privacy loss in the forward and backward gradient descent steps, achieving the two objectives simultaneously. Extensive experiments on a variety of datasets have shown that our defense significantly mitigates privacy leakage with negligible impact on the federated learning task.
Depth-conditioned Dynamic Message Propagation for Monocular 3D Object Detection
Mar 30, 2021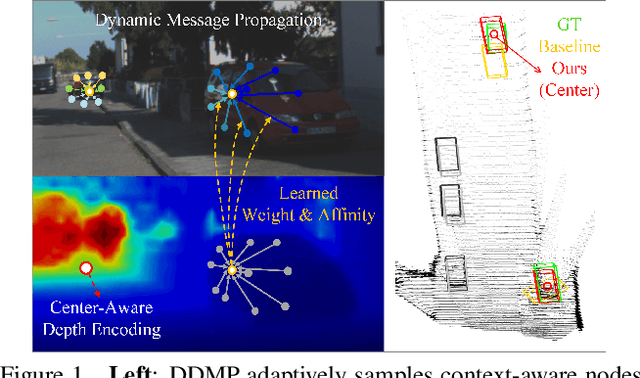
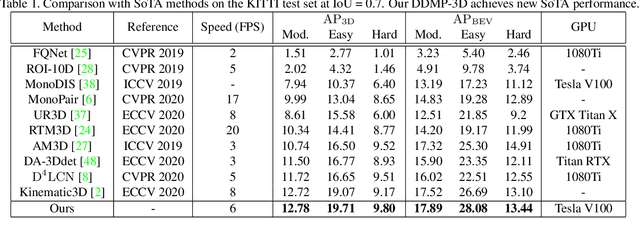
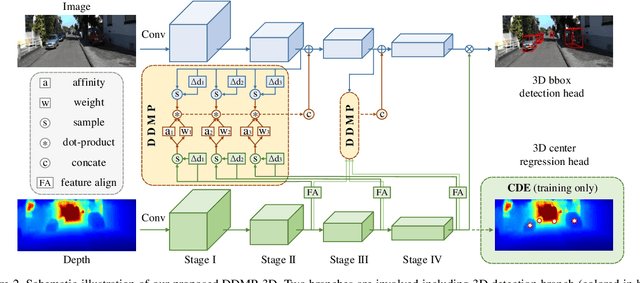
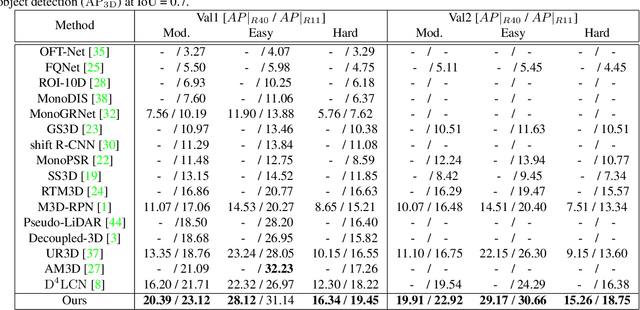
The objective of this paper is to learn context- and depth-aware feature representation to solve the problem of monocular 3D object detection. We make following contributions: (i) rather than appealing to the complicated pseudo-LiDAR based approach, we propose a depth-conditioned dynamic message propagation (DDMP) network to effectively integrate the multi-scale depth information with the image context;(ii) this is achieved by first adaptively sampling context-aware nodes in the image context and then dynamically predicting hybrid depth-dependent filter weights and affinity matrices for propagating information; (iii) by augmenting a center-aware depth encoding (CDE) task, our method successfully alleviates the inaccurate depth prior; (iv) we thoroughly demonstrate the effectiveness of our proposed approach and show state-of-the-art results among the monocular-based approaches on the KITTI benchmark dataset. Particularly, we rank $1^{st}$ in the highly competitive KITTI monocular 3D object detection track on the submission day (November 16th, 2020). Code and models are released at \url{https://github.com/fudan-zvg/DDMP}
Cross-Dataset Collaborative Learning for Semantic Segmentation
Mar 21, 2021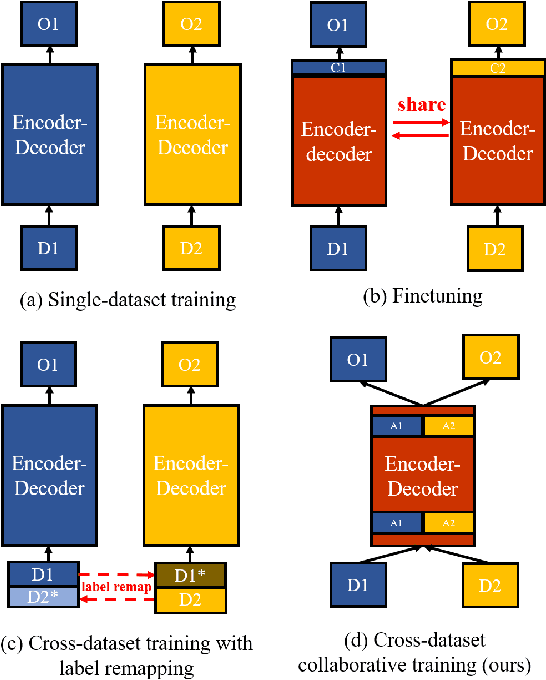
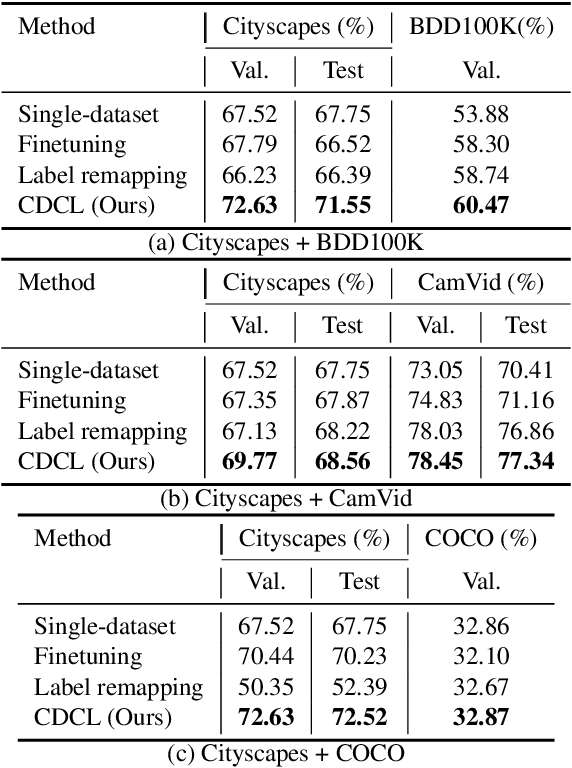
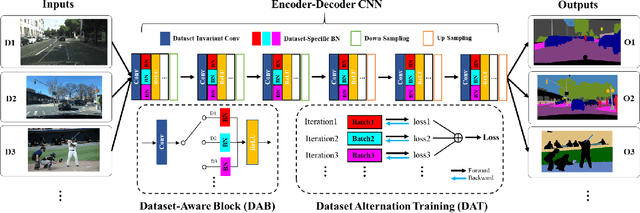

Recent work attempts to improve semantic segmentation performance by exploring well-designed architectures on a target dataset. However, it remains challenging to build a unified system that simultaneously learns from various datasets due to the inherent distribution shift across different datasets. In this paper, we present a simple, flexible, and general method for semantic segmentation, termed Cross-Dataset Collaborative Learning (CDCL). Given multiple labeled datasets, we aim to improve the generalization and discrimination of feature representations on each dataset. Specifically, we first introduce a family of Dataset-Aware Blocks (DAB) as the fundamental computing units of the network, which help capture homogeneous representations and heterogeneous statistics across different datasets. Second, we propose a Dataset Alternation Training (DAT) mechanism to efficiently facilitate the optimization procedure. We conduct extensive evaluations on four diverse datasets, i.e., Cityscapes, BDD100K, CamVid, and COCO Stuff, with single-dataset and cross-dataset settings. Experimental results demonstrate our method consistently achieves notable improvements over prior single-dataset and cross-dataset training methods without introducing extra FLOPs. Particularly, with the same architecture of PSPNet (ResNet-18), our method outperforms the single-dataset baseline by 5.65\%, 6.57\%, and 5.79\% of mIoU on the validation sets of Cityscapes, BDD100K, CamVid, respectively. Code and models will be released.
An Efficient Calibration Method for Triaxial Gyroscope
Mar 20, 2021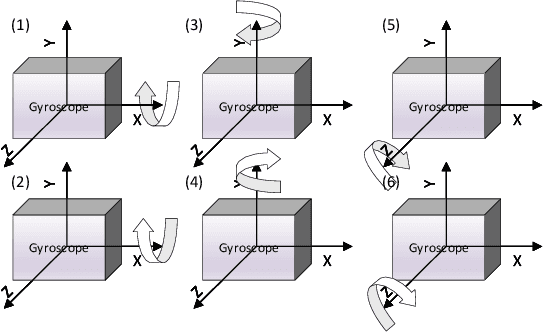
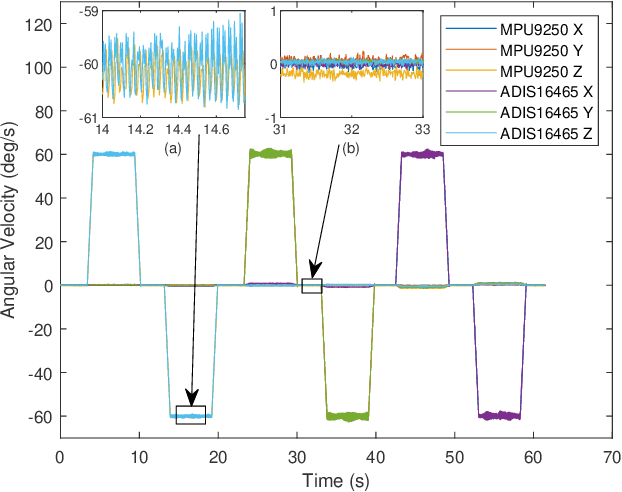
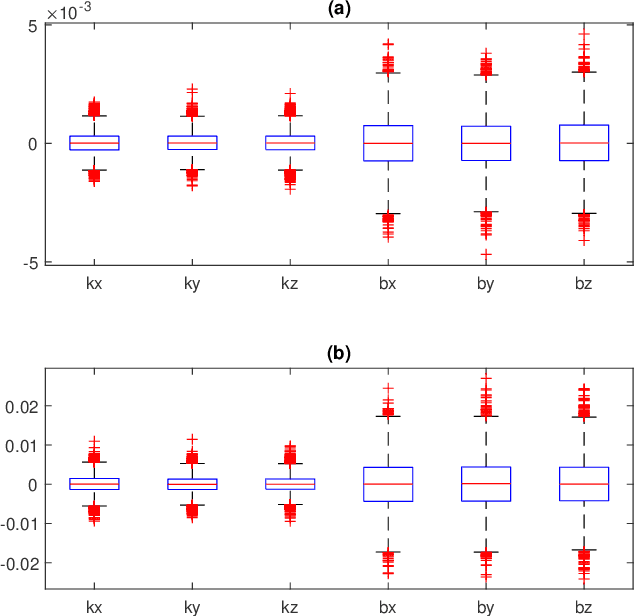
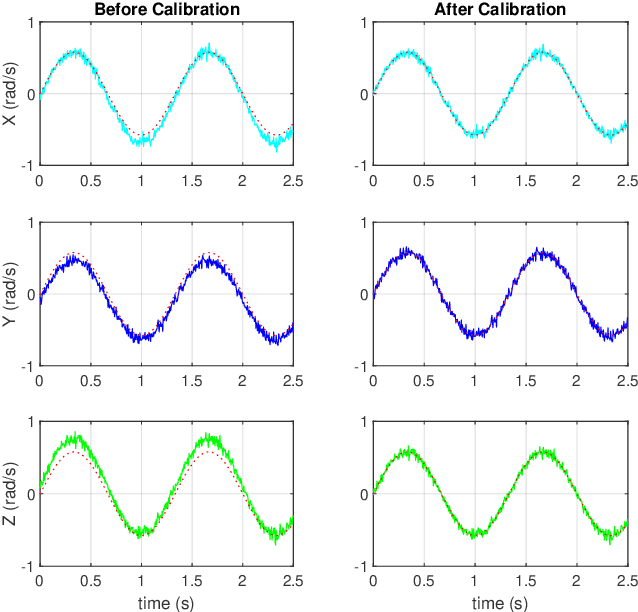
This paper presents an efficient servomotor-aided calibration method for the triaxial gyroscope. The entire calibration process only takes about one minute, and high-precision equipment is not used. The main idea of this method is that the measurement of the gyroscope should equal to the rotation speed of the servomotor. A six-observation experimental design is proposed to minimize the maximum variance of the estimated scale factors and biases. Besides, a fast converged recursive linear least square estimation method is presented to reduce computational complexity. The simulation results specify the robustness under normal and extreme condition. We experimentally demonstrate the achievability of the proposed method on a robot arm and implements the method on a microcontroller. The calibration results of the proposed method are verified by comparing with a traditional turntable method, and the experiment indicates that the error between these two methods is less than $10^{-3}$. By comparing the calibrated low-cost gyroscope reading with the reading from a high-precision gyroscope, we can infer that our method significantly increases the accuracy of the low-cost gyroscopes.
S-AT GCN: Spatial-Attention Graph Convolution Network based Feature Enhancement for 3D Object Detection
Mar 15, 2021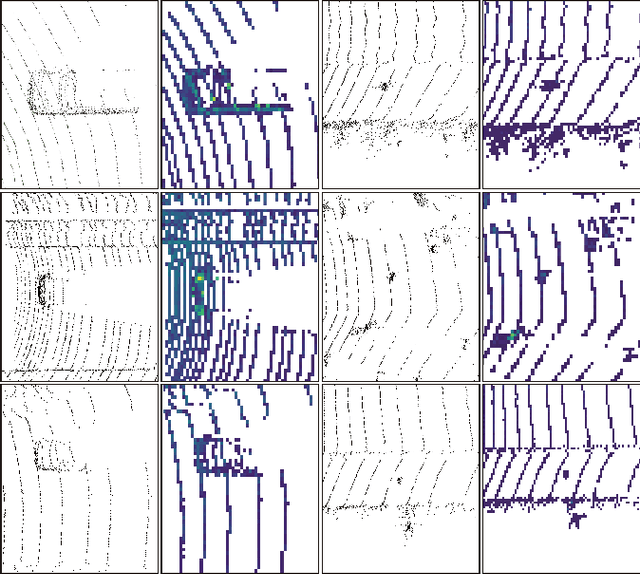
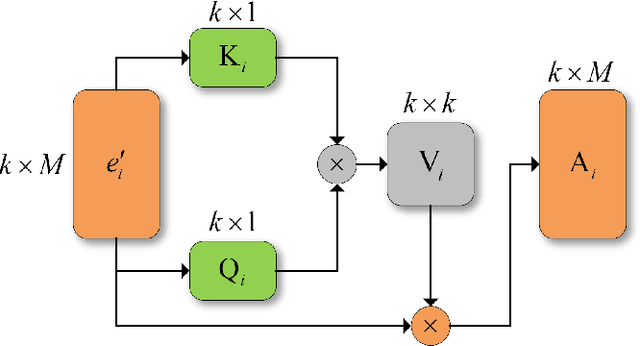
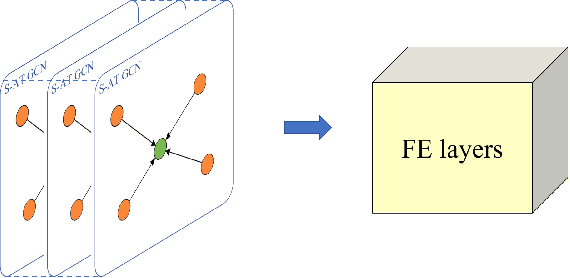
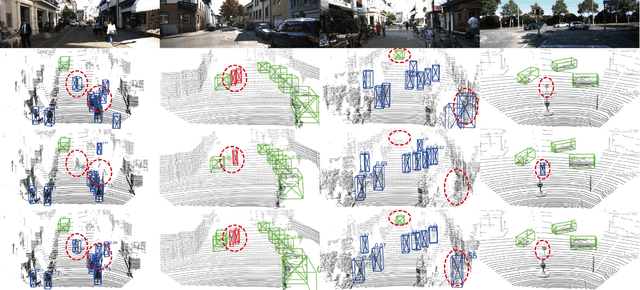
3D object detection plays a crucial role in environmental perception for autonomous vehicles, which is the prerequisite of decision and control. This paper analyses partition-based methods' inherent drawbacks. In the partition operation, a single instance such as a pedestrian is sliced into several pieces, which we call it the partition effect. We propose the Spatial-Attention Graph Convolution (S-AT GCN), forming the Feature Enhancement (FE) layers to overcome this drawback. The S-AT GCN utilizes the graph convolution and the spatial attention mechanism to extract local geometrical structure features. This allows the network to have more meaningful features for the foreground. Our experiments on the KITTI 3D object and bird's eye view detection show that S-AT Conv and FE layers are effective, especially for small objects. FE layers boost the pedestrian class performance by 3.62\% and cyclist class by 4.21\% 3D mAP. The time cost of these extra FE layers are limited. PointPillars with FE layers can achieve 48 PFS, satisfying the real-time requirement.
DM algorithms in healthindustry
Mar 02, 2021This survey reviews several approaches of data mining (DM) in healthindustry from many research groups world wide. The focus is on modern multi-core processors built into today's commodity computers, which are typically found at university institutes both as small server and workstation computers. So they are deliberately not high-performance computers. Modern multi-core processors consist of several (2 to over 100) computer cores, which work independently of each other according to the principle of "multiple instruction multiple data" (MIMD). They have a common main memory (shared memory). Each of these computer cores has several (2-16) arithmetic-logic units, which can simultaneously carry out the same arithmetic operation on several data in a vector-like manner (single instruction multiple data, SIMD). DM algorithms must use both types of parallelism (SIMD and MIMD), with access to the main memory (centralized component) being the main barrier to increased efficiency. This is important for DM in healthindustry applications like ECG, EEG, CT, SPECT, fMRI, DTI, ultrasound, microscopy, dermascopy, etc.