 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCutting-Splicing data augmentation: A novel technology for medical image segmentation
Oct 17, 2022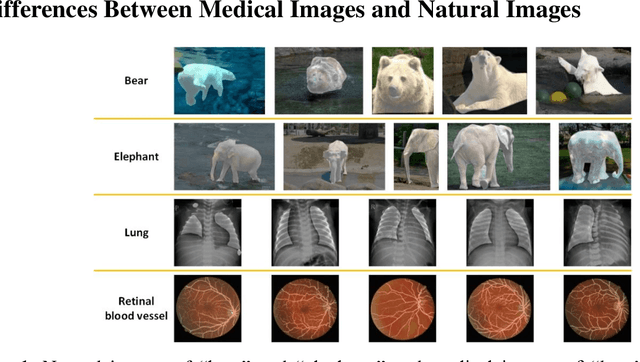
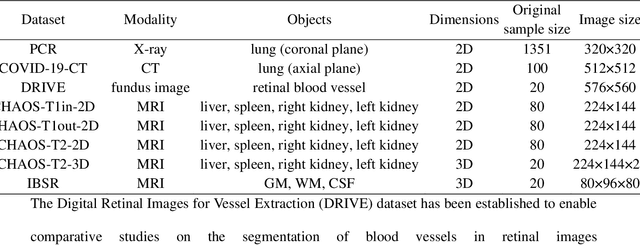
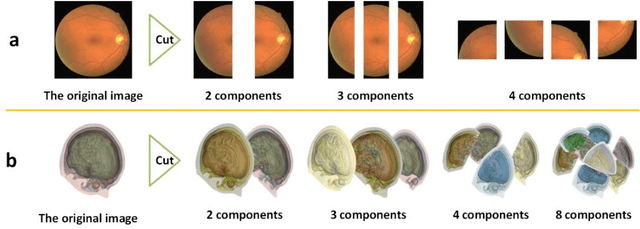
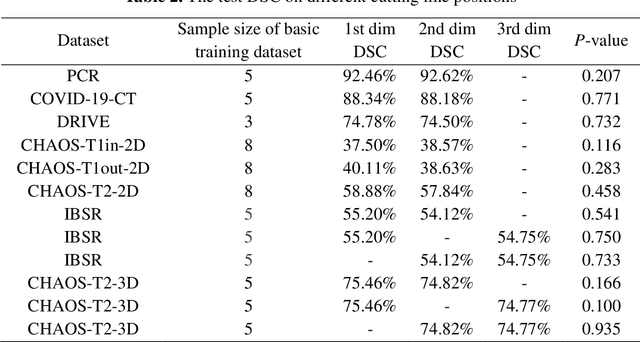
Background: Medical images are more difficult to acquire and annotate than natural images, which results in data augmentation technologies often being used in medical image segmentation tasks. Most data augmentation technologies used in medical segmentation were originally developed on natural images and do not take into account the characteristic that the overall layout of medical images is standard and fixed. Methods: Based on the characteristics of medical images, we developed the cutting-splicing data augmentation (CS-DA) method, a novel data augmentation technology for medical image segmentation. CS-DA augments the dataset by splicing different position components cut from different original medical images into a new image. The characteristics of the medical image result in the new image having the same layout as and similar appearance to the original image. Compared with classical data augmentation technologies, CS-DA is simpler and more robust. Moreover, CS-DA does not introduce any noise or fake information into the newly created image. Results: To explore the properties of CS-DA, many experiments are conducted on eight diverse datasets. On the training dataset with the small sample size, CS-DA can effectively increase the performance of the segmentation model. When CS-DA is used together with classical data augmentation technologies, the performance of the segmentation model can be further improved and is much better than that of CS-DA and classical data augmentation separately. We also explored the influence of the number of components, the position of the cutting line, and the splicing method on the CS-DA performance. Conclusions: The excellent performance of CS-DA in the experiment has confirmed the effectiveness of CS-DA, and provides a new data augmentation idea for the small sample segmentation task.
Efficient Search of the k Shortest Non-Homotopic Paths by Eliminating Non-k-Optimal Topologies
Jul 27, 2022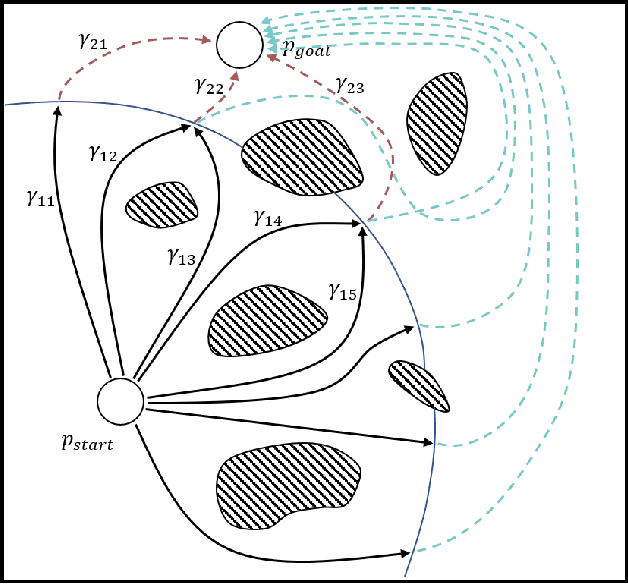
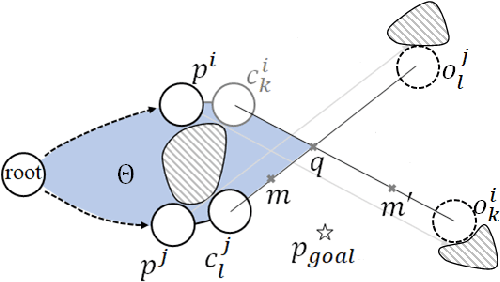
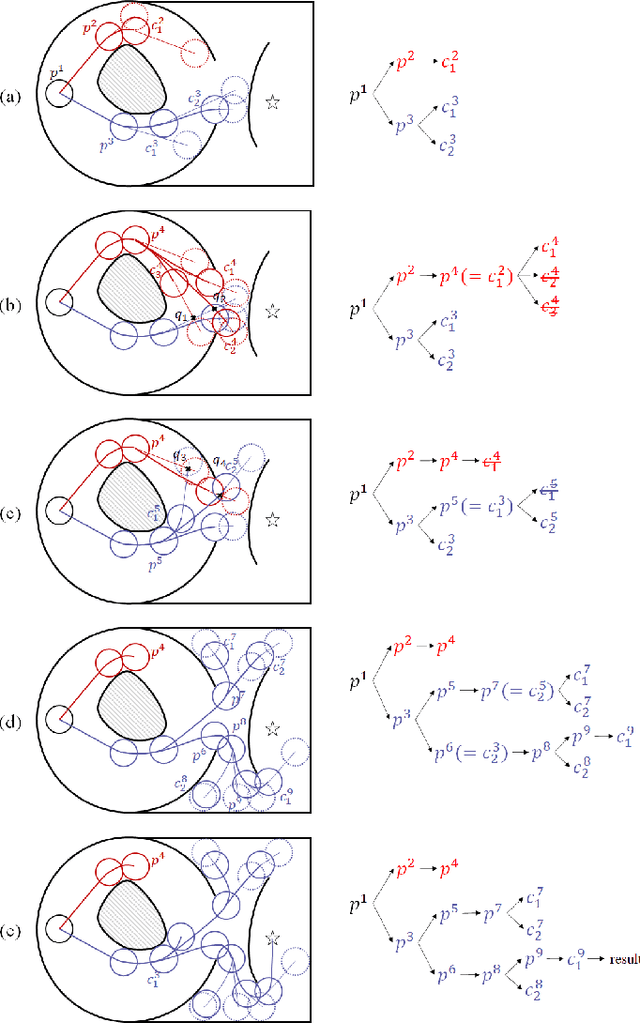
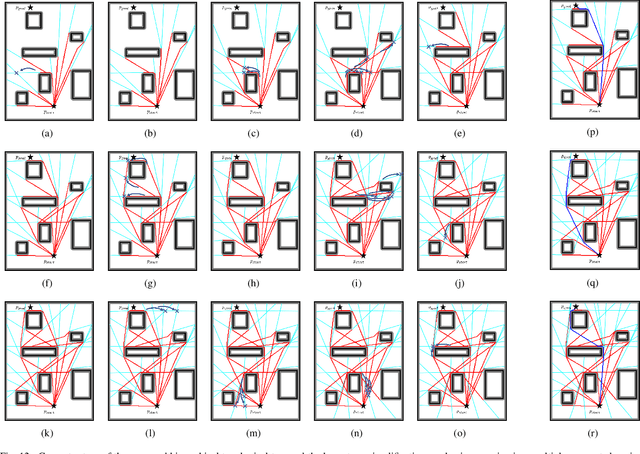
An efficient algorithm to solve the $k$ shortest non-homotopic path planning ($k$-SNPP) problem in a 2D environment is proposed in this paper. Motivated by accelerating the inefficient exploration of the homotopy-augmented space of the 2D environment, our fundamental idea is to identify the non-$k$-optimal path topologies as early as possible and terminate the pathfinding along them. This is a non-trivial practice because it has to be done at an intermediate state of the path planning process when locally shortest paths have not been fully constructed. In other words, the paths to be compared have not rendezvoused at the goal location, which makes the homotopy theory, modelling the spatial relationship among the paths having the same endpoint, not applicable. This paper is the first work that develops a systematic distance-based topology simplification mechanism to solve the $k$-SNPP task, whose core contribution is to assert the distance-based order of non-homotopic locally shortest paths before constructing them. If the order can be predicted, then those path topologies having more than $k$ better topologies are proven free of the desired $k$ paths and thus can be safely discarded during the path planning process. To this end, a hierarchical topological tree is proposed as an implementation of the mechanism, whose nodes are proven to expand in non-homotopic directions and edges (collision-free path segments) are proven locally shortest. With efficient criteria that observe the order relations between partly constructed locally shortest paths being imparted into the tree, the tree nodes that expand in non-$k$-optimal topologies will not be expanded. As a result, the computational time for solving the $k$-SNPP problem is reduced by near two orders of magnitude.
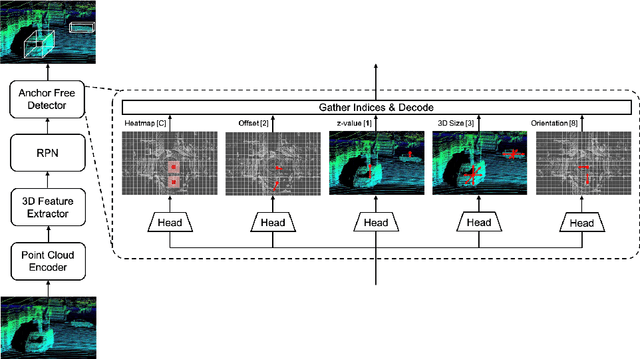
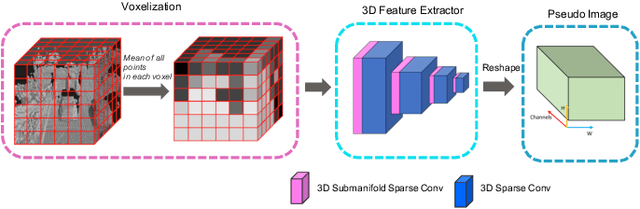
AFDetV2: Rethinking the Necessity of the Second Stage for Object Detection from Point Clouds
Dec 16, 2021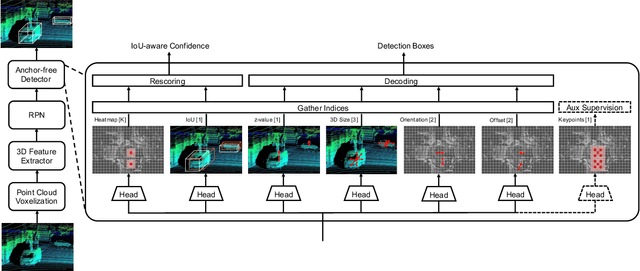

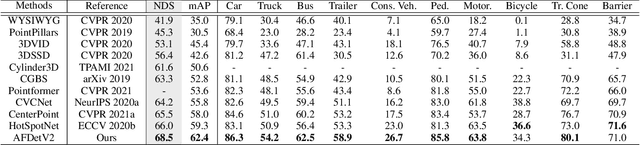
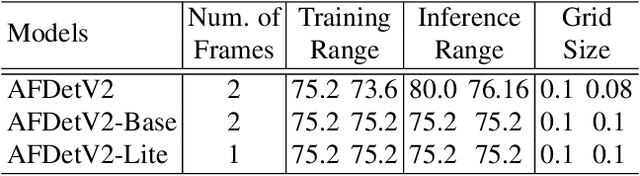
There have been two streams in the 3D detection from point clouds: single-stage methods and two-stage methods. While the former is more computationally efficient, the latter usually provides better detection accuracy. By carefully examining the two-stage approaches, we have found that if appropriately designed, the first stage can produce accurate box regression. In this scenario, the second stage mainly rescores the boxes such that the boxes with better localization get selected. From this observation, we have devised a single-stage anchor-free network that can fulfill these requirements. This network, named AFDetV2, extends the previous work by incorporating a self-calibrated convolution block in the backbone, a keypoint auxiliary supervision, and an IoU prediction branch in the multi-task head. As a result, the detection accuracy is drastically boosted in the single-stage. To evaluate our approach, we have conducted extensive experiments on the Waymo Open Dataset and the nuScenes Dataset. We have observed that our AFDetV2 achieves the state-of-the-art results on these two datasets, superior to all the prior arts, including both the single-stage and the two-stage se3D detectors. AFDetV2 won the 1st place in the Real-Time 3D Detection of the Waymo Open Dataset Challenge 2021. In addition, a variant of our model AFDetV2-Base was entitled the "Most Efficient Model" by the Challenge Sponsor, showing a superior computational efficiency. To demonstrate the generality of this single-stage method, we have also applied it to the first stage of the two-stage networks. Without exception, the results show that with the strengthened backbone and the rescoring approach, the second stage refinement is no longer needed.
Real-Time Anchor-Free Single-Stage 3D Detection with IoU-Awareness
Aug 03, 2021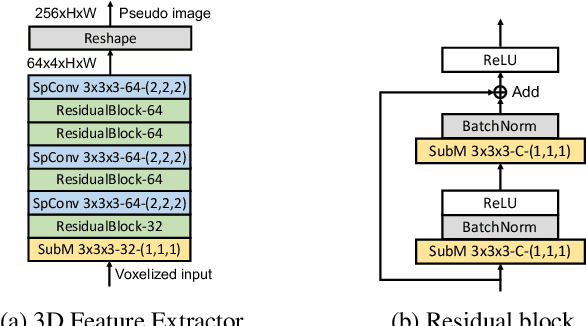
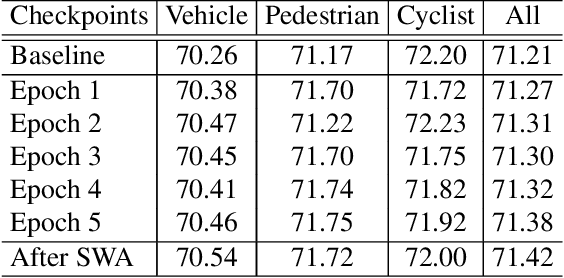
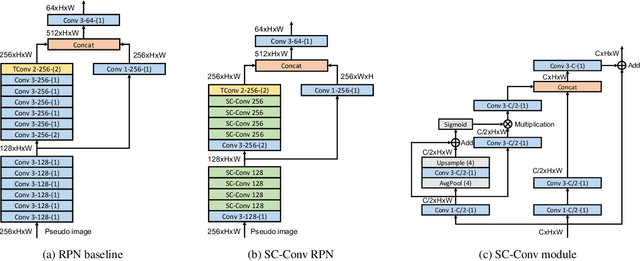
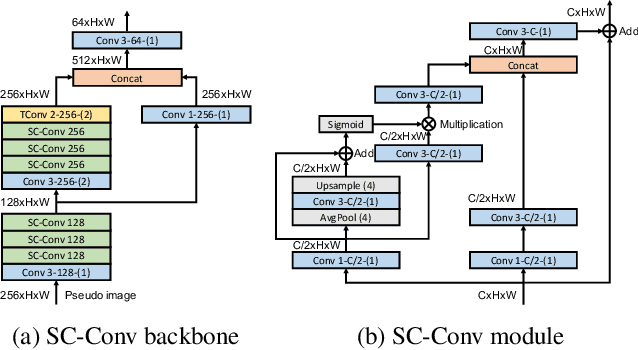
In this report, we introduce our winning solution to the Real-time 3D Detection and also the "Most Efficient Model" in the Waymo Open Dataset Challenges at CVPR 2021. Extended from our last year's award-winning model AFDet, we have made a handful of modifications to the base model, to improve the accuracy and at the same time to greatly reduce the latency. The modified model, named as AFDetV2, is featured with a lite 3D Feature Extractor, an improved RPN with extended receptive field and an added sub-head that produces an IoU-aware confidence score. These model enhancements, together with enriched data augmentation, stochastic weights averaging, and a GPU-based implementation of voxelization, lead to a winning accuracy of 73.12 mAPH/L2 for our AFDetV2 with a latency of 60.06 ms, and an accuracy of 72.57 mAPH/L2 for our AFDetV2-base, entitled as the "Most Efficient Model" by the challenge sponsor, with a winning latency of 55.86 ms.
KINNEWS and KIRNEWS: Benchmarking Cross-Lingual Text Classification for Kinyarwanda and Kirundi
Oct 23, 2020
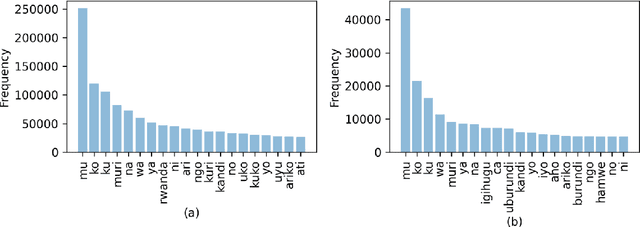

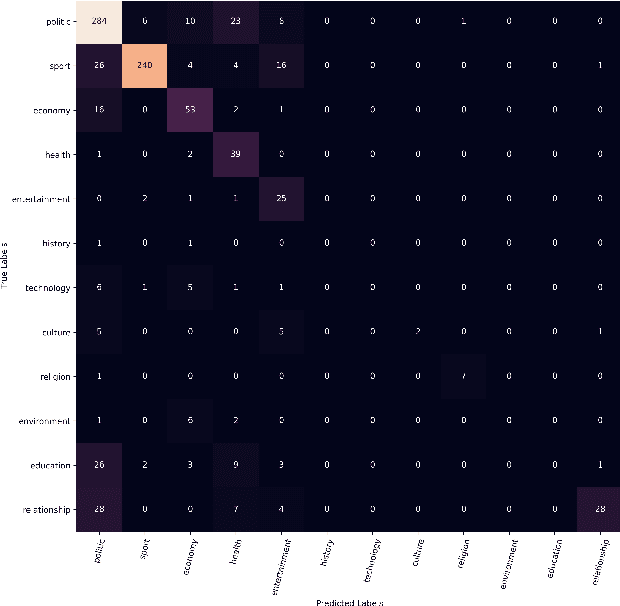
Recent progress in text classification has been focused on high-resource languages such as English and Chinese. For low-resource languages, amongst them most African languages, the lack of well-annotated data and effective preprocessing, is hindering the progress and the transfer of successful methods. In this paper, we introduce two news datasets (KINNEWS and KIRNEWS) for multi-class classification of news articles in Kinyarwanda and Kirundi, two low-resource African languages. The two languages are mutually intelligible, but while Kinyarwanda has been studied in Natural Language Processing (NLP) to some extent, this work constitutes the first study on Kirundi. Along with the datasets, we provide statistics, guidelines for preprocessing, and monolingual and cross-lingual baseline models. Our experiments show that training embeddings on the relatively higher-resourced Kinyarwanda yields successful cross-lingual transfer to Kirundi. In addition, the design of the created datasets allows for a wider use in NLP beyond text classification in future studies, such as representation learning, cross-lingual learning with more distant languages, or as base for new annotations for tasks such as parsing, POS tagging, and NER. The datasets, stopwords, and pre-trained embeddings are publicly available at https://github.com/Andrews2017/KINNEWS-and-KIRNEWS-Corpus .
AFDet: Anchor Free One Stage 3D Object Detection
Jun 30, 2020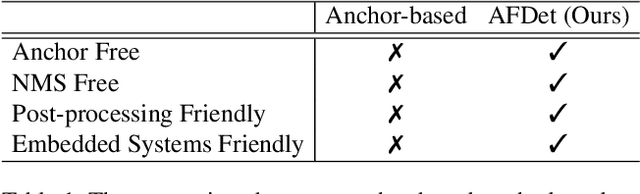
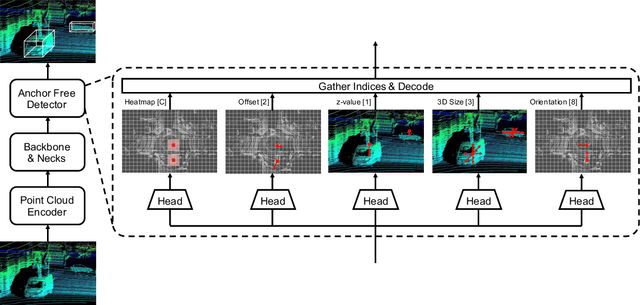
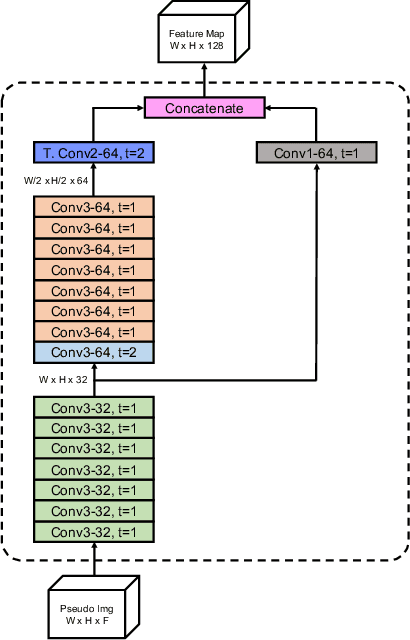
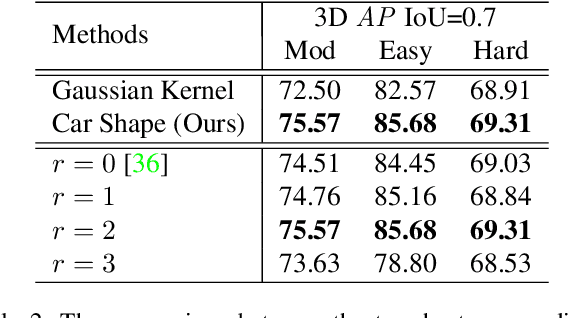
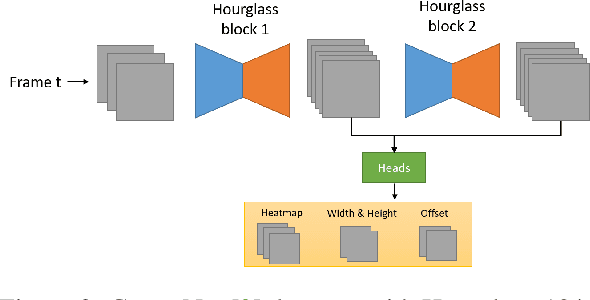
High-efficiency point cloud 3D object detection operated on embedded systems is important for many robotics applications including autonomous driving. Most previous works try to solve it using anchor-based detection methods which come with two drawbacks: post-processing is relatively complex and computationally expensive; tuning anchor parameters is tricky. We are the first to address these drawbacks with an anchor free and Non-Maximum Suppression free one stage detector called AFDet. The entire AFDet can be processed efficiently on a CNN accelerator or a GPU with the simplified post-processing. Without bells and whistles, our proposed AFDet performs competitively with other one stage anchor-based methods on KITTI validation set and Waymo Open Dataset validation set.
2nd Place Solution for Waymo Open Dataset Challenge -- 2D Object Detection
Jun 28, 2020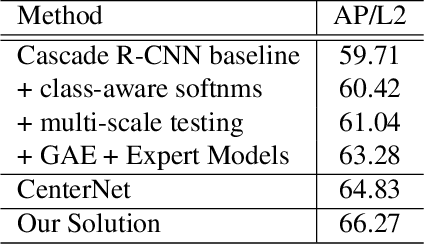
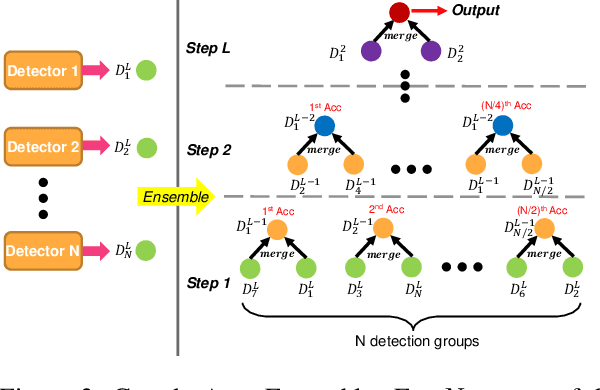
A practical autonomous driving system urges the need to reliably and accurately detect vehicles and persons. In this report, we introduce a state-of-the-art 2D object detection system for autonomous driving scenarios. Specifically, we integrate both popular two-stage detector and one-stage detector with anchor free fashion to yield a robust detection. Furthermore, we train multiple expert models and design a greedy version of the auto ensemble scheme that automatically merges detections from different models. Notably, our overall detection system achieves 70.28 L2 mAP on the Waymo Open Dataset v1.2, ranking the 2nd place in the 2D detection track of the Waymo Open Dataset Challenges.
1st Place Solutions for Waymo Open Dataset Challenges - 2D and 3D Tracking
Jun 28, 2020
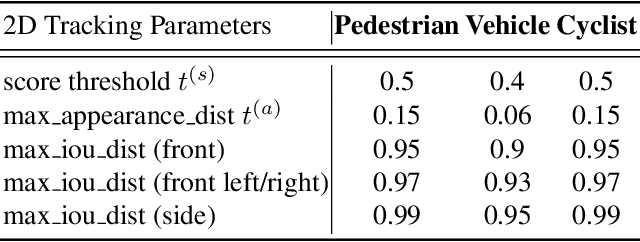
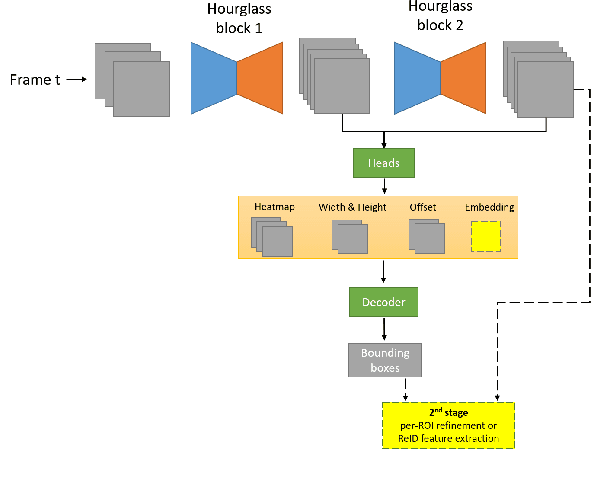
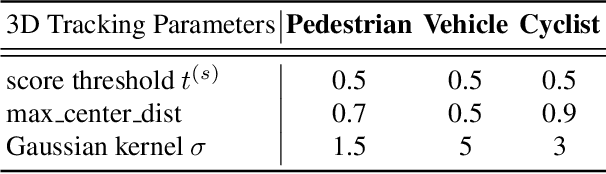
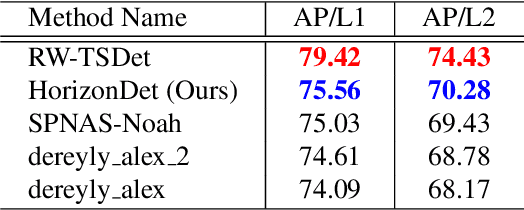
This technical report presents the online and real-time 2D and 3D multi-object tracking (MOT) algorithms that reached the 1st places on both Waymo Open Dataset 2D tracking and 3D tracking challenges. An efficient and pragmatic online tracking-by-detection framework named HorizonMOT is proposed for camera-based 2D tracking in the image space and LiDAR-based 3D tracking in the 3D world space. Within the tracking-by-detection paradigm, our trackers leverage our high-performing detectors used in the 2D/3D detection challenges and achieved 45.13% 2D MOTA/L2 and 63.45% 3D MOTA/L2 in the 2D/3D tracking challenges.
1st Place Solution for Waymo Open Dataset Challenge - 3D Detection and Domain Adaptation
Jun 28, 2020
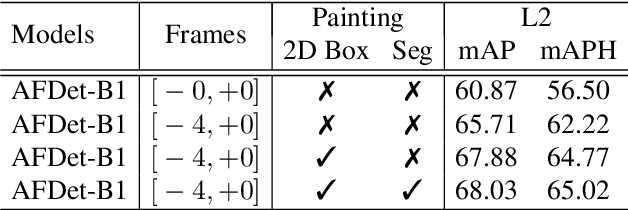
In this technical report, we introduce our winning solution "HorizonLiDAR3D" for the 3D detection track and the domain adaptation track in Waymo Open Dataset Challenge at CVPR 2020. Many existing 3D object detectors include prior-based anchor box design to account for different scales and aspect ratios and classes of objects, which limits its capability of generalization to a different dataset or domain and requires post-processing (e.g. Non-Maximum Suppression (NMS)). We proposed a one-stage, anchor-free and NMS-free 3D point cloud object detector AFDet, using object key-points to encode the 3D attributes, and to learn an end-to-end point cloud object detection without the need of hand-engineering or learning the anchors. AFDet serves as a strong baseline in our winning solution and significant improvements are made over this baseline during the challenges. Specifically, we design stronger networks and enhance the point cloud data using densification and point painting. To leverage camera information, we append/paint additional attributes to each point by projecting them to camera space and gathering image-based perception information. The final detection performance also benefits from model ensemble and Test-Time Augmentation (TTA) in both the 3D detection track and the domain adaptation track. Our solution achieves the 1st place with 77.11% mAPH/L2 and 69.49% mAPH/L2 respectively on the 3D detection track and the domain adaptation track.
Patient Clustering Improves Efficiency of Federated Machine Learning to predict mortality and hospital stay time using distributed Electronic Medical Records
Mar 22, 2019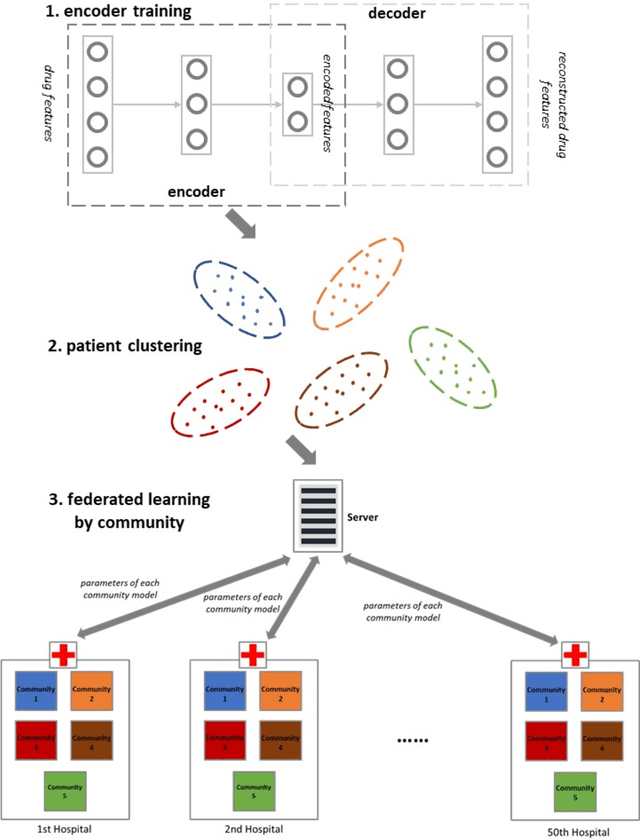
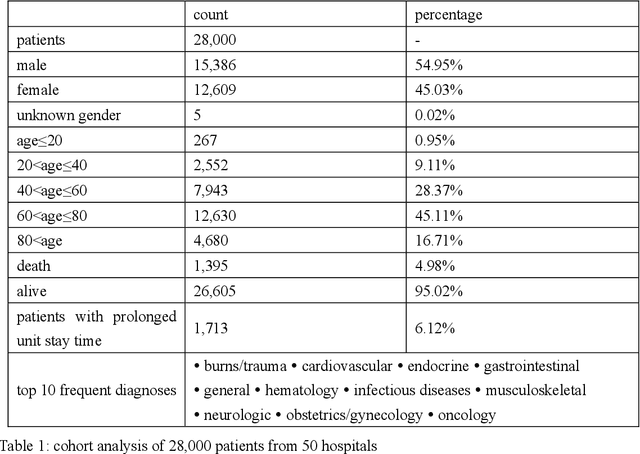

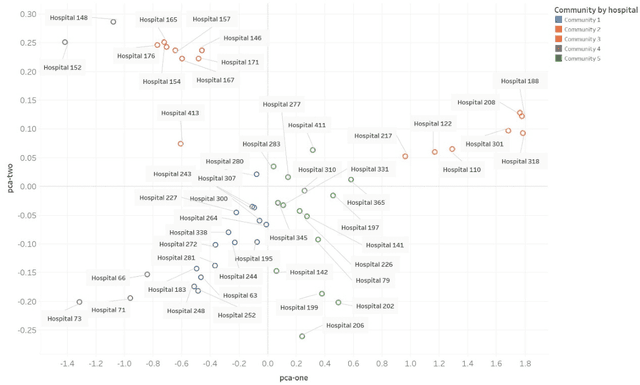
Electronic medical records (EMRs) supports the development of machine learning algorithms for predicting disease incidence, patient response to treatment, and other healthcare events. But insofar most algorithms have been centralized, taking little account of the decentralized, non-identically independently distributed (non-IID), and privacy-sensitive characteristics of EMRs that can complicate data collection, sharing and learning. To address this challenge, we introduced a community-based federated machine learning (CBFL) algorithm and evaluated it on non-IID ICU EMRs. Our algorithm clustered the distributed data into clinically meaningful communities that captured similar diagnoses and geological locations, and learnt one model for each community. Throughout the learning process, the data was kept local on hospitals, while locally-computed results were aggregated on a server. Evaluation results show that CBFL outperformed the baseline FL algorithm in terms of Area Under the Receiver Operating Characteristic Curve (ROC AUC), Area Under the Precision-Recall Curve (PR AUC), and communication cost between hospitals and the server. Furthermore, communities' performance difference could be explained by how dissimilar one community was to others.