 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAesExpert: Towards Multi-modality Foundation Model for Image Aesthetics Perception
Apr 15, 2024



The highly abstract nature of image aesthetics perception (IAP) poses significant challenge for current multimodal large language models (MLLMs). The lack of human-annotated multi-modality aesthetic data further exacerbates this dilemma, resulting in MLLMs falling short of aesthetics perception capabilities. To address the above challenge, we first introduce a comprehensively annotated Aesthetic Multi-Modality Instruction Tuning (AesMMIT) dataset, which serves as the footstone for building multi-modality aesthetics foundation models. Specifically, to align MLLMs with human aesthetics perception, we construct a corpus-rich aesthetic critique database with 21,904 diverse-sourced images and 88K human natural language feedbacks, which are collected via progressive questions, ranging from coarse-grained aesthetic grades to fine-grained aesthetic descriptions. To ensure that MLLMs can handle diverse queries, we further prompt GPT to refine the aesthetic critiques and assemble the large-scale aesthetic instruction tuning dataset, i.e. AesMMIT, which consists of 409K multi-typed instructions to activate stronger aesthetic capabilities. Based on the AesMMIT database, we fine-tune the open-sourced general foundation models, achieving multi-modality Aesthetic Expert models, dubbed AesExpert. Extensive experiments demonstrate that the proposed AesExpert models deliver significantly better aesthetic perception performances than the state-of-the-art MLLMs, including the most advanced GPT-4V and Gemini-Pro-Vision. Source data will be available at https://github.com/yipoh/AesExpert.
Diffusion Model Based Visual Compensation Guidance and Visual Difference Analysis for No-Reference Image Quality Assessment
Feb 22, 2024



Existing free-energy guided No-Reference Image Quality Assessment (NR-IQA) methods still suffer from finding a balance between learning feature information at the pixel level of the image and capturing high-level feature information and the efficient utilization of the obtained high-level feature information remains a challenge. As a novel class of state-of-the-art (SOTA) generative model, the diffusion model exhibits the capability to model intricate relationships, enabling a comprehensive understanding of images and possessing a better learning of both high-level and low-level visual features. In view of these, we pioneer the exploration of the diffusion model into the domain of NR-IQA. Firstly, we devise a new diffusion restoration network that leverages the produced enhanced image and noise-containing images, incorporating nonlinear features obtained during the denoising process of the diffusion model, as high-level visual information. Secondly, two visual evaluation branches are designed to comprehensively analyze the obtained high-level feature information. These include the visual compensation guidance branch, grounded in the transformer architecture and noise embedding strategy, and the visual difference analysis branch, built on the ResNet architecture and the residual transposed attention block. Extensive experiments are conducted on seven public NR-IQA datasets, and the results demonstrate that the proposed model outperforms SOTA methods for NR-IQA.
Deep Shape-Texture Statistics for Completely Blind Image Quality Evaluation
Jan 16, 2024



Opinion-Unaware Blind Image Quality Assessment (OU-BIQA) models aim to predict image quality without training on reference images and subjective quality scores. Thereinto, image statistical comparison is a classic paradigm, while the performance is limited by the representation ability of visual descriptors. Deep features as visual descriptors have advanced IQA in recent research, but they are discovered to be highly texture-biased and lack of shape-bias. On this basis, we find out that image shape and texture cues respond differently towards distortions, and the absence of either one results in an incomplete image representation. Therefore, to formulate a well-round statistical description for images, we utilize the shapebiased and texture-biased deep features produced by Deep Neural Networks (DNNs) simultaneously. More specifically, we design a Shape-Texture Adaptive Fusion (STAF) module to merge shape and texture information, based on which we formulate qualityrelevant image statistics. The perceptual quality is quantified by the variant Mahalanobis Distance between the inner and outer Shape-Texture Statistics (DSTS), wherein the inner and outer statistics respectively describe the quality fingerprints of the distorted image and natural images. The proposed DSTS delicately utilizes shape-texture statistical relations between different data scales in the deep domain, and achieves state-of-the-art (SOTA) quality prediction performance on images with artificial and authentic distortions.
AesBench: An Expert Benchmark for Multimodal Large Language Models on Image Aesthetics Perception
Jan 16, 2024With collective endeavors, multimodal large language models (MLLMs) are undergoing a flourishing development. However, their performances on image aesthetics perception remain indeterminate, which is highly desired in real-world applications. An obvious obstacle lies in the absence of a specific benchmark to evaluate the effectiveness of MLLMs on aesthetic perception. This blind groping may impede the further development of more advanced MLLMs with aesthetic perception capacity. To address this dilemma, we propose AesBench, an expert benchmark aiming to comprehensively evaluate the aesthetic perception capacities of MLLMs through elaborate design across dual facets. (1) We construct an Expert-labeled Aesthetics Perception Database (EAPD), which features diversified image contents and high-quality annotations provided by professional aesthetic experts. (2) We propose a set of integrative criteria to measure the aesthetic perception abilities of MLLMs from four perspectives, including Perception (AesP), Empathy (AesE), Assessment (AesA) and Interpretation (AesI). Extensive experimental results underscore that the current MLLMs only possess rudimentary aesthetic perception ability, and there is still a significant gap between MLLMs and humans. We hope this work can inspire the community to engage in deeper explorations on the aesthetic potentials of MLLMs. Source data will be available at https://github.com/yipoh/AesBench.
Video Super-Resolution Transformer with Masked Inter&Intra-Frame Attention
Jan 15, 2024



Recently, Vision Transformer has achieved great success in recovering missing details in low-resolution sequences, i.e., the video super-resolution (VSR) task. Despite its superiority in VSR accuracy, the heavy computational burden as well as the large memory footprint hinder the deployment of Transformer-based VSR models on constrained devices. In this paper, we address the above issue by proposing a novel feature-level masked processing framework: VSR with Masked Intra and inter frame Attention (MIA-VSR). The core of MIA-VSR is leveraging feature-level temporal continuity between adjacent frames to reduce redundant computations and make more rational use of previously enhanced SR features. Concretely, we propose an intra-frame and inter-frame attention block which takes the respective roles of past features and input features into consideration and only exploits previously enhanced features to provide supplementary information. In addition, an adaptive block-wise mask prediction module is developed to skip unimportant computations according to feature similarity between adjacent frames. We conduct detailed ablation studies to validate our contributions and compare the proposed method with recent state-of-the-art VSR approaches. The experimental results demonstrate that MIA-VSR improves the memory and computation efficiency over state-of-the-art methods, without trading off PSNR accuracy. The code is available at https://github.com/LabShuHangGU/MIA-VSR.
Dehazed Image Quality Evaluation: From Partial Discrepancy to Blind Perception
Nov 22, 2022



Image dehazing aims to restore spatial details from hazy images. There have emerged a number of image dehazing algorithms, designed to increase the visibility of those hazy images. However, much less work has been focused on evaluating the visual quality of dehazed images. In this paper, we propose a Reduced-Reference dehazed image quality evaluation approach based on Partial Discrepancy (RRPD) and then extend it to a No-Reference quality assessment metric with Blind Perception (NRBP). Specifically, inspired by the hierarchical characteristics of the human perceiving dehazed images, we introduce three groups of features: luminance discrimination, color appearance, and overall naturalness. In the proposed RRPD, the combined distance between a set of sender and receiver features is adopted to quantify the perceptually dehazed image quality. By integrating global and local channels from dehazed images, the RRPD is converted to NRBP which does not rely on any information from the references. Extensive experiment results on several dehazed image quality databases demonstrate that our proposed methods outperform state-of-the-art full-reference, reduced-reference, and no-reference quality assessment models. Furthermore, we show that the proposed dehazed image quality evaluation methods can be effectively applied to tune parameters for potential image dehazing algorithms.
HVS Revisited: A Comprehensive Video Quality Assessment Framework
Oct 09, 2022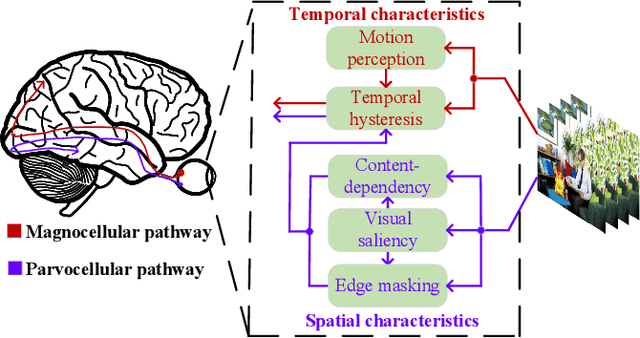
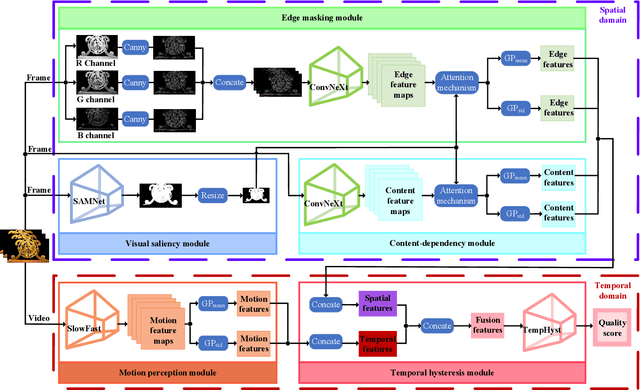

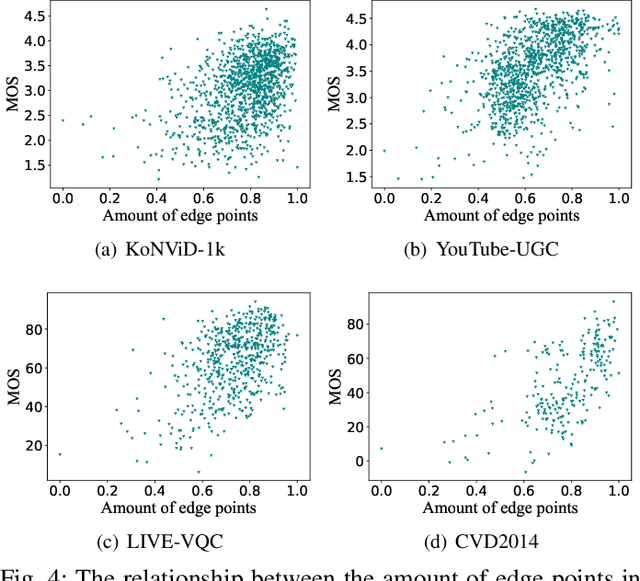
Video quality is a primary concern for video service providers. In recent years, the techniques of video quality assessment (VQA) based on deep convolutional neural networks (CNNs) have been developed rapidly. Although existing works attempt to introduce the knowledge of the human visual system (HVS) into VQA, there still exhibit limitations that prevent the full exploitation of HVS, including an incomplete model by few characteristics and insufficient connections among these characteristics. To overcome these limitations, this paper revisits HVS with five representative characteristics, and further reorganizes their connections. Based on the revisited HVS, a no-reference VQA framework called HVS-5M (NRVQA framework with five modules simulating HVS with five characteristics) is proposed. It works in a domain-fusion design paradigm with advanced network structures. On the side of the spatial domain, the visual saliency module applies SAMNet to obtain a saliency map. And then, the content-dependency and the edge masking modules respectively utilize ConvNeXt to extract the spatial features, which have been attentively weighted by the saliency map for the purpose of highlighting those regions that human beings may be interested in. On the other side of the temporal domain, to supplement the static spatial features, the motion perception module utilizes SlowFast to obtain the dynamic temporal features. Besides, the temporal hysteresis module applies TempHyst to simulate the memory mechanism of human beings, and comprehensively evaluates the quality score according to the fusion features from the spatial and temporal domains. Extensive experiments show that our HVS-5M outperforms the state-of-the-art VQA methods. Ablation studies are further conducted to verify the effectiveness of each module towards the proposed framework.
Seeking Subjectivity in Visual Emotion Distribution Learning
Jul 25, 2022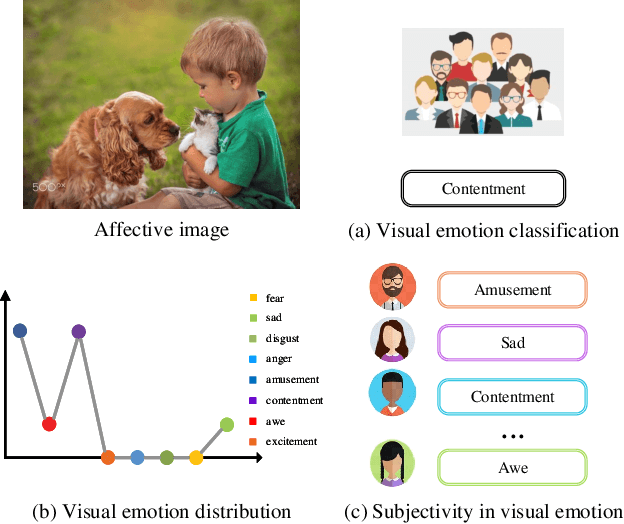
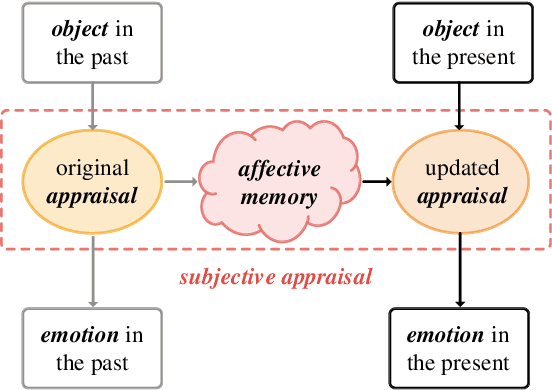
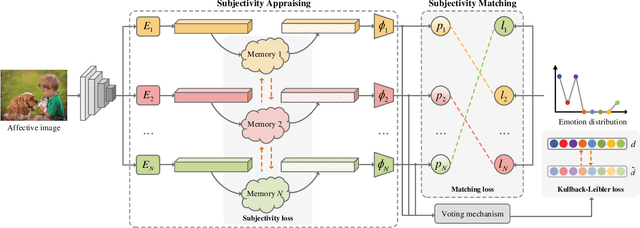
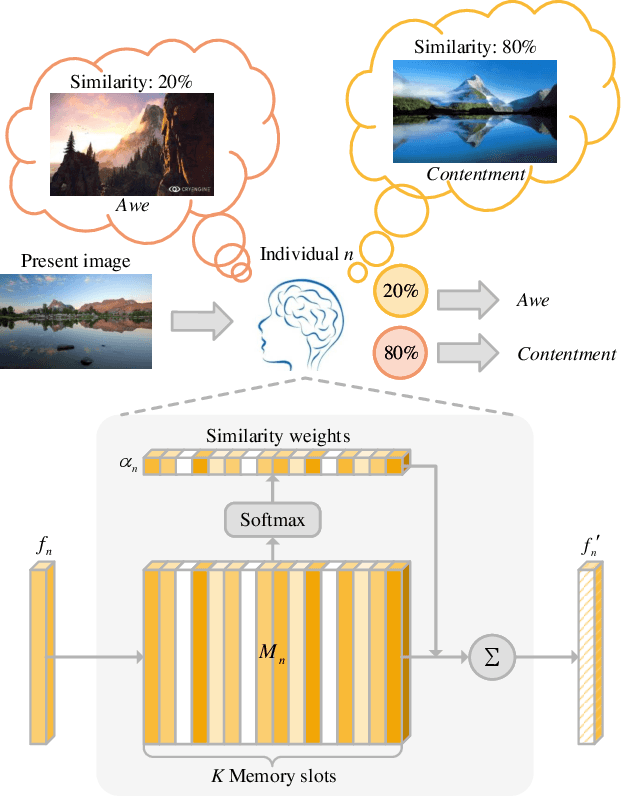
Visual Emotion Analysis (VEA), which aims to predict people's emotions towards different visual stimuli, has become an attractive research topic recently. Rather than a single label classification task, it is more rational to regard VEA as a Label Distribution Learning (LDL) problem by voting from different individuals. Existing methods often predict visual emotion distribution in a unified network, neglecting the inherent subjectivity in its crowd voting process. In psychology, the \textit{Object-Appraisal-Emotion} model has demonstrated that each individual's emotion is affected by his/her subjective appraisal, which is further formed by the affective memory. Inspired by this, we propose a novel \textit{Subjectivity Appraise-and-Match Network (SAMNet)} to investigate the subjectivity in visual emotion distribution. To depict the diversity in crowd voting process, we first propose the \textit{Subjectivity Appraising} with multiple branches, where each branch simulates the emotion evocation process of a specific individual. Specifically, we construct the affective memory with an attention-based mechanism to preserve each individual's unique emotional experience. A subjectivity loss is further proposed to guarantee the divergence between different individuals. Moreover, we propose the \textit{Subjectivity Matching} with a matching loss, aiming at assigning unordered emotion labels to ordered individual predictions in a one-to-one correspondence with the Hungarian algorithm. Extensive experiments and comparisons are conducted on public visual emotion distribution datasets, and the results demonstrate that the proposed SAMNet consistently outperforms the state-of-the-art methods. Ablation study verifies the effectiveness of our method and visualization proves its interpretability.
Personalized Image Aesthetics Assessment with Rich Attributes
Mar 31, 2022
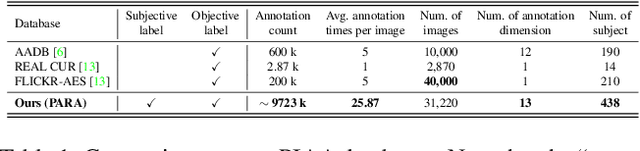
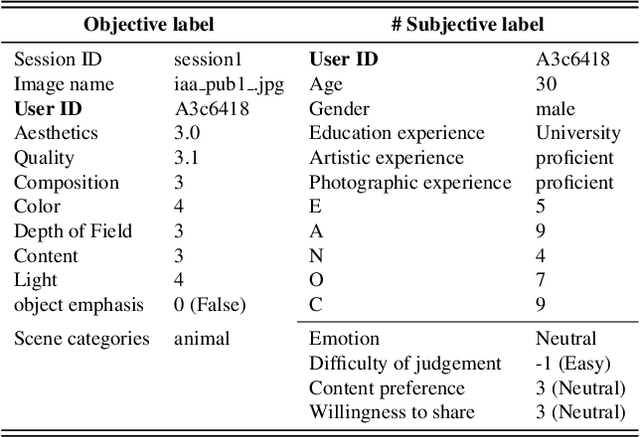
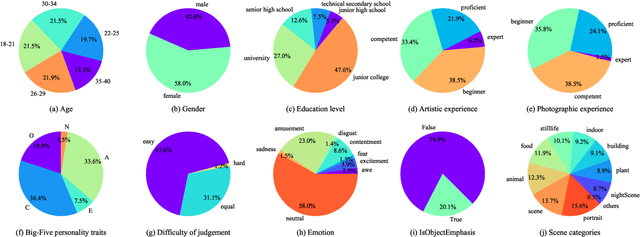
Personalized image aesthetics assessment (PIAA) is challenging due to its highly subjective nature. People's aesthetic tastes depend on diversified factors, including image characteristics and subject characters. The existing PIAA databases are limited in terms of annotation diversity, especially the subject aspect, which can no longer meet the increasing demands of PIAA research. To solve the dilemma, we conduct so far, the most comprehensive subjective study of personalized image aesthetics and introduce a new Personalized image Aesthetics database with Rich Attributes (PARA), which consists of 31,220 images with annotations by 438 subjects. PARA features wealthy annotations, including 9 image-oriented objective attributes and 4 human-oriented subjective attributes. In addition, desensitized subject information, such as personality traits, is also provided to support study of PIAA and user portraits. A comprehensive analysis of the annotation data is provided and statistic study indicates that the aesthetic preferences can be mirrored by proposed subjective attributes. We also propose a conditional PIAA model by utilizing subject information as conditional prior. Experimental results indicate that the conditional PIAA model can outperform the control group, which is also the first attempt to demonstrate how image aesthetics and subject characters interact to produce the intricate personalized tastes on image aesthetics. We believe the database and the associated analysis would be useful for conducting next-generation PIAA study. The project page of PARA can be found at: https://cv-datasets.institutecv.com/#/data-sets.
Robust Depth Completion with Uncertainty-Driven Loss Functions
Dec 28, 2021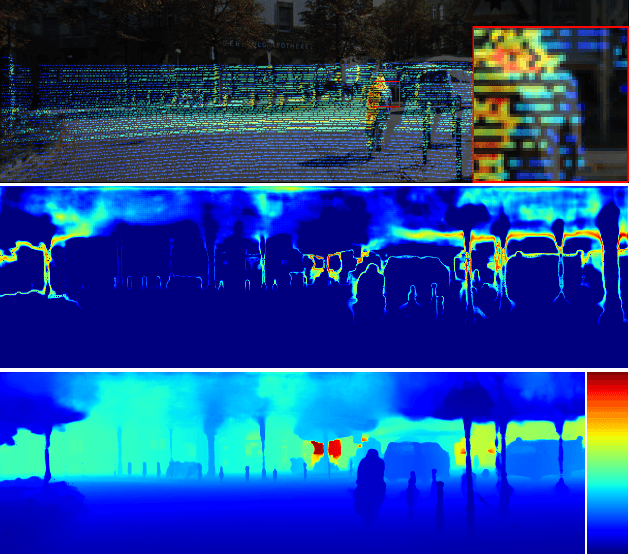
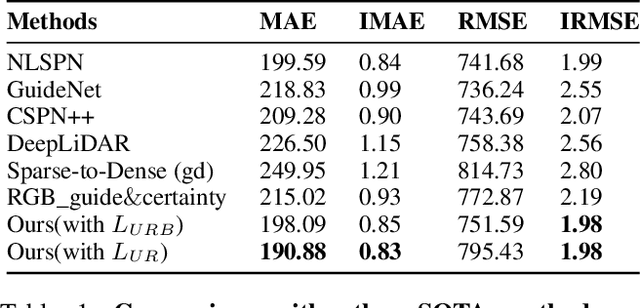
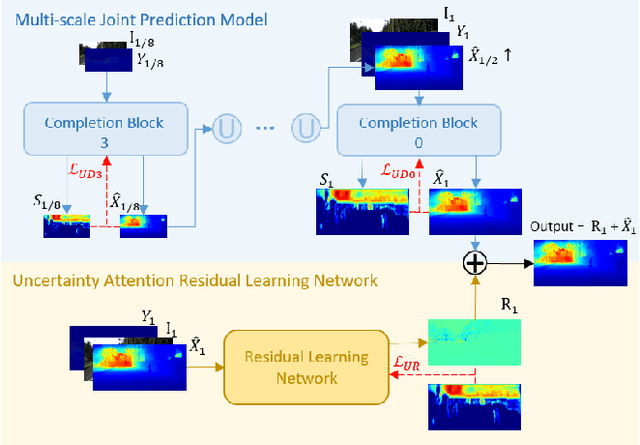
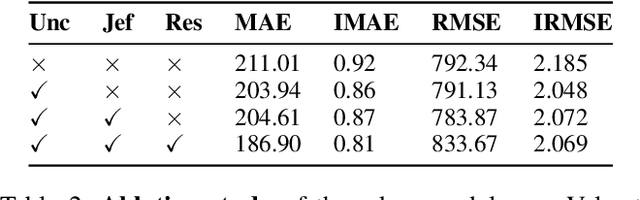
Recovering a dense depth image from sparse LiDAR scans is a challenging task. Despite the popularity of color-guided methods for sparse-to-dense depth completion, they treated pixels equally during optimization, ignoring the uneven distribution characteristics in the sparse depth map and the accumulated outliers in the synthesized ground truth. In this work, we introduce uncertainty-driven loss functions to improve the robustness of depth completion and handle the uncertainty in depth completion. Specifically, we propose an explicit uncertainty formulation for robust depth completion with Jeffrey's prior. A parametric uncertain-driven loss is introduced and translated to new loss functions that are robust to noisy or missing data. Meanwhile, we propose a multiscale joint prediction model that can simultaneously predict depth and uncertainty maps. The estimated uncertainty map is also used to perform adaptive prediction on the pixels with high uncertainty, leading to a residual map for refining the completion results. Our method has been tested on KITTI Depth Completion Benchmark and achieved the state-of-the-art robustness performance in terms of MAE, IMAE, and IRMSE metrics.