 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Plan via Neural Exploration-Exploitation Trees
Mar 26, 2019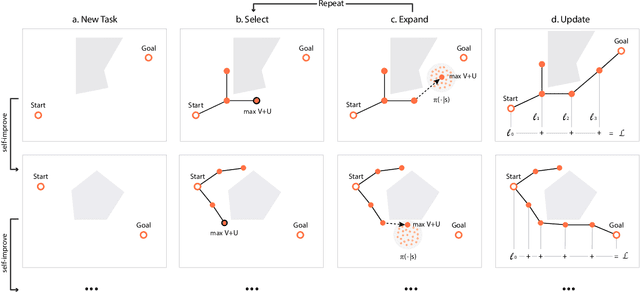
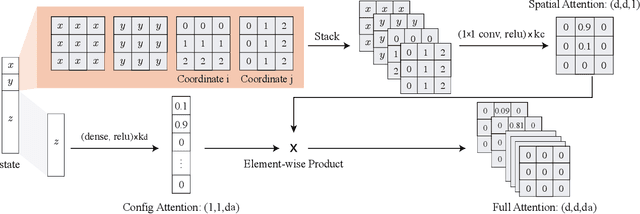
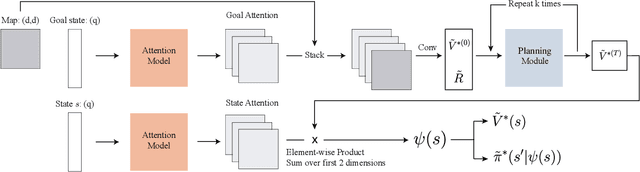

Sampling-based planning algorithms such as RRT and its variants are powerful tools for path planning problems in high-dimensional continuous state and action spaces. While these algorithms perform systematic exploration of the state space, they do not fully exploit past planning experiences from similar environments. In this paper, we design a meta path planning algorithm, called Neural Exploration-Exploitation Trees (NEXT), which can utilize prior experience to drastically reduce the sample requirement for solving new path planning problems. More specifically, NEXT contains a novel neural architecture which can learn from experiences the dependency between task structures and promising path search directions. Then this learned prior is integrated with a UCB-type algorithm to achieve an online balance between exploration and exploitation when solving a new problem. Empirically, we show that NEXT can complete the planning tasks with very small search trees and significantly outperforms previous state-of-the-arts on several benchmark problems.
Cost-Effective Incentive Allocation via Structured Counterfactual Inference
Feb 07, 2019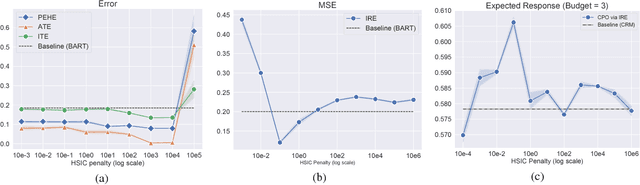
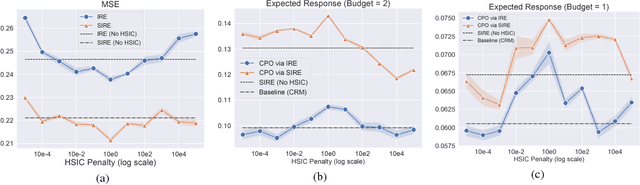
We address a practical problem ubiquitous in modern industry, in which a mediator tries to learn a policy for allocating strategic financial incentives for customers in a marketing campaign and observes only bandit feedback. In contrast to traditional policy optimization frameworks, we rely on a specific assumption for the reward structure and we incorporate budget constraints. We develop a new two-step method for solving this constrained counterfactual policy optimization problem. First, we cast the reward estimation problem as a domain adaptation problem with supplementary structure. Subsequently, the estimators are used for optimizing the policy with constraints. We establish theoretical error bounds for our estimation procedure and we empirically show that the approach leads to significant improvement on both synthetic and real datasets.
Meta Particle Flow for Sequential Bayesian Inference
Feb 02, 2019
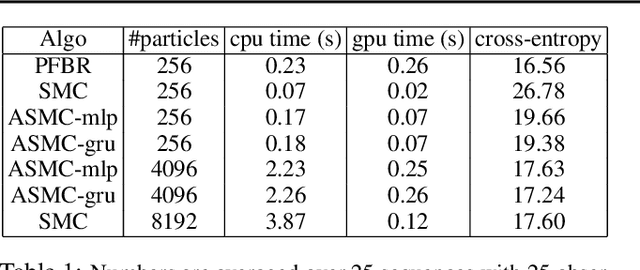

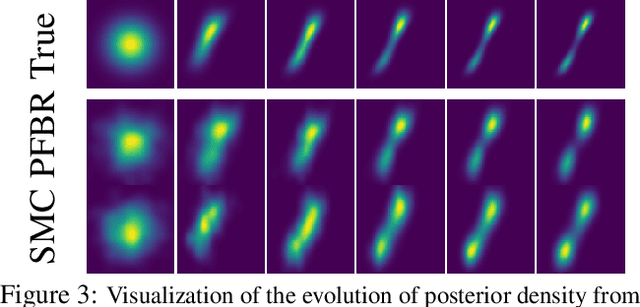
We present a particle flow realization of Bayes' rule, where an ODE-based neural operator is used to transport particles from a prior to its posterior after a new observation. We prove that such an ODE operator exists and its neural parameterization can be trained in a meta-learning framework, allowing this operator to reason about the effect of an individual observation on the posterior, and thus generalize across different priors, observations and to online Bayesian inference. We demonstrated the generalization ability of our particle flow Bayes operator in several canonical and high dimensional examples.
Value Propagation for Decentralized Networked Deep Multi-agent Reinforcement Learning
Jan 27, 2019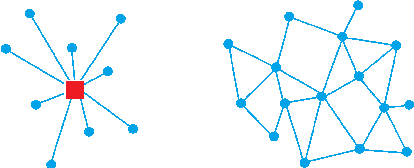
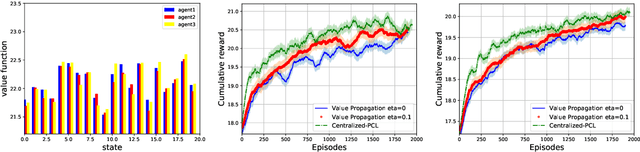
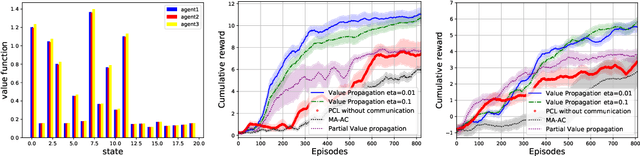
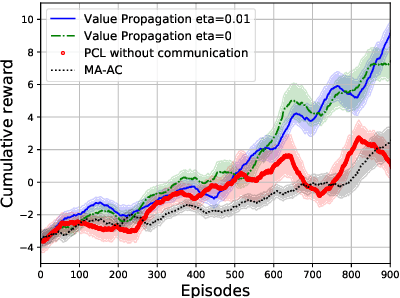
We consider the networked multi-agent reinforcement learning (MARL) problem in a fully decentralized setting, where agents learn to coordinate to achieve the joint success. This problem is widely encountered in many areas including traffic control, distributed control, and smart grids. We assume that the reward function for each agent can be different and observed only locally by the agent itself. Furthermore, each agent is located at a node of a communication network and can exchanges information only with its neighbors. Using softmax temporal consistency and a decentralized optimization method, we obtain a principled and data-efficient iterative algorithm. In the first step of each iteration, an agent computes its local policy and value gradients and then updates only policy parameters. In the second step, the agent propagates to its neighbors the messages based on its value function and then updates its own value function. Hence we name the algorithm value propagation. We prove a non-asymptotic convergence rate 1/T with the nonlinear function approximation. To the best of our knowledge, it is the first MARL algorithm with convergence guarantee in the control, off-policy and non-linear function approximation setting. We empirically demonstrate the effectiveness of our approach in experiments.
Neural Model-Based Reinforcement Learning for Recommendation
Dec 27, 2018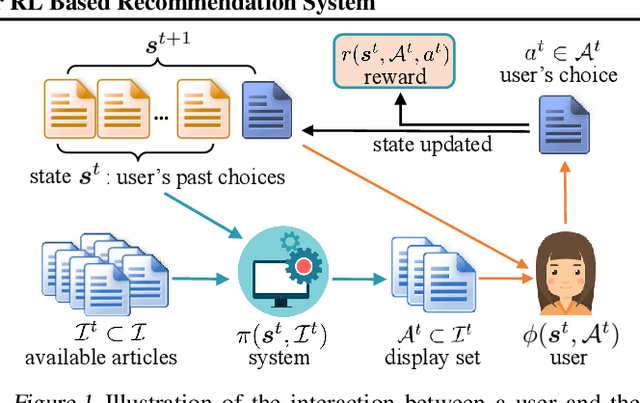

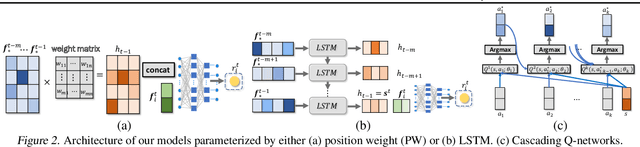
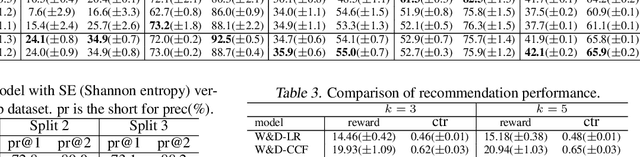
There are great interests as well as many challenges in applying reinforcement learning (RL) to recommendation systems. In this setting, an online user is the environment; neither the reward function nor the environment dynamics are clearly defined, making the application of RL challenging. In this paper, we propose a novel model-based reinforcement learning framework for recommendation systems, where we develop a generative adversarial network to imitate user behavior dynamics and learn her reward function. Using this user model as the simulation environment, we develop a novel DQN algorithm to obtain a combinatorial recommendation policy which can handle a large number of candidate items efficiently. In our experiments with real data, we show this generative adversarial user model can better explain user behavior than alternatives, and the RL policy based on this model can lead to a better long-term reward for the user and higher click rate for the system.
Double Neural Counterfactual Regret Minimization
Dec 27, 2018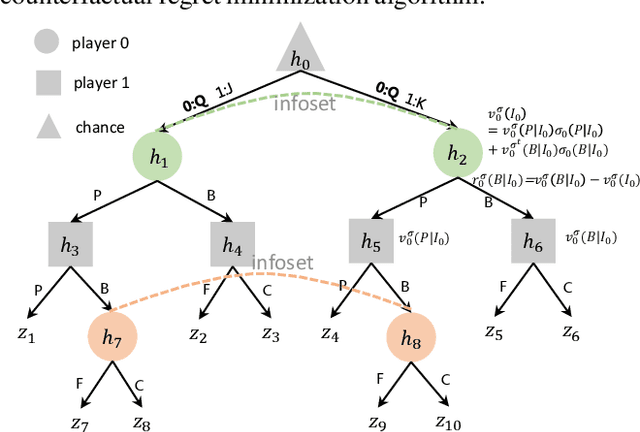
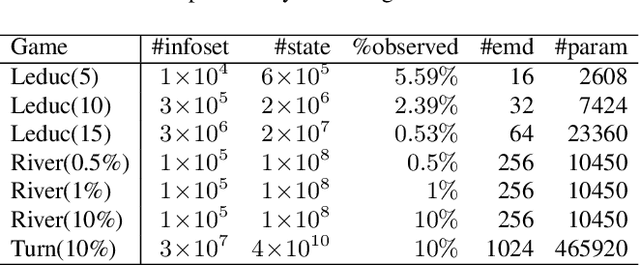
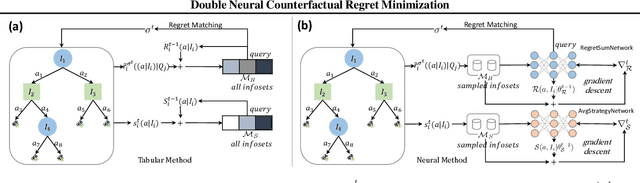
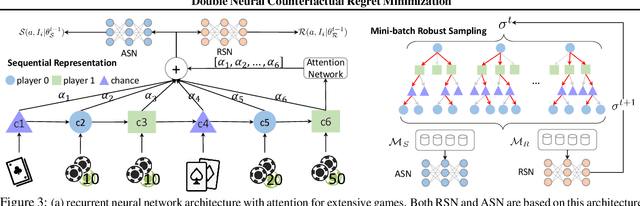
Counterfactual Regret Minimization (CRF) is a fundamental and effective technique for solving Imperfect Information Games (IIG). However, the original CRF algorithm only works for discrete state and action spaces, and the resulting strategy is maintained as a tabular representation. Such tabular representation limits the method from being directly applied to large games and continuing to improve from a poor strategy profile. In this paper, we propose a double neural representation for the imperfect information games, where one neural network represents the cumulative regret, and the other represents the average strategy. Furthermore, we adopt the counterfactual regret minimization algorithm to optimize this double neural representation. To make neural learning efficient, we also developed several novel techniques including a robust sampling method, mini-batch Monte Carlo Counterfactual Regret Minimization (MCCFR) and Monte Carlo Counterfactual Regret Minimization Plus (MCCFR+) which may be of independent interests. Experimentally, we demonstrate that the proposed double neural algorithm converges significantly better than the reinforcement learning counterpart.
Bayesian Meta-network Architecture Learning
Dec 22, 2018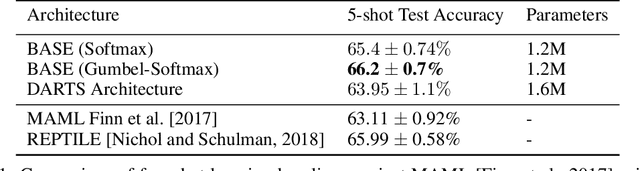
For deep neural networks, the particular structure often plays a vital role in achieving state-of-the-art performances in many practical applications. However, existing architecture search methods can only learn the architecture for a single task at a time. In this paper, we first propose a Bayesian inference view of architecture learning and use this novel view to derive a variational inference method to learn the architecture of a meta-network, which will be shared across multiple tasks. To account for the task distribution in the posterior distribution of the architecture and its corresponding weights, we exploit the optimization embedding technique to design the parameterization of the posterior. Our method finds architectures which achieve state-of-the-art performance on the few-shot learning problem and demonstrates the advantages of meta-network learning for both architecture search and meta-learning.
A Policy Gradient Method with Variance Reduction for Uplift Modeling
Nov 26, 2018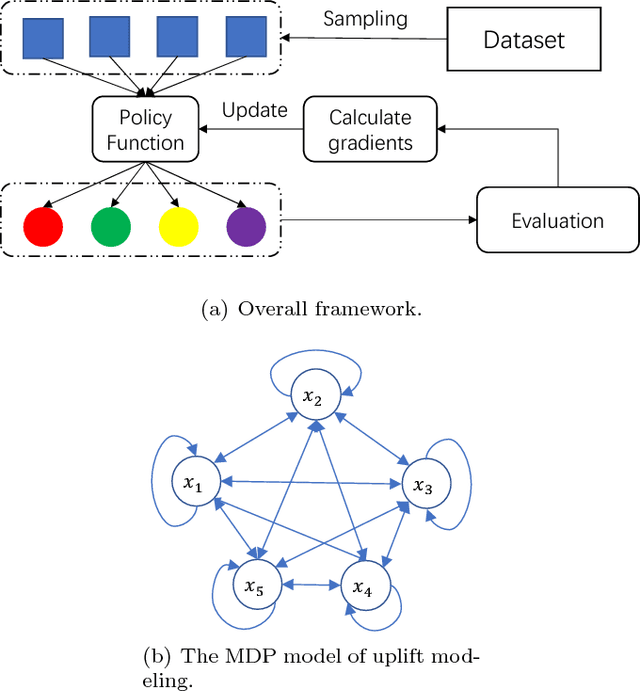

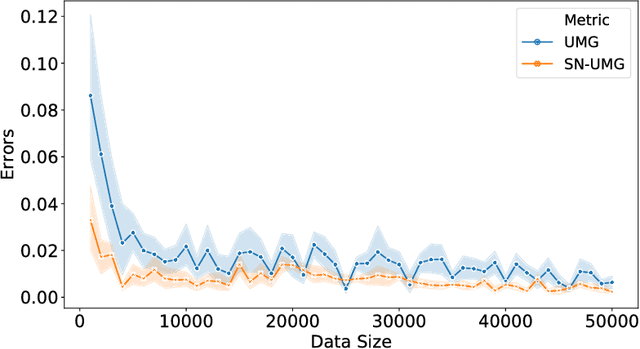
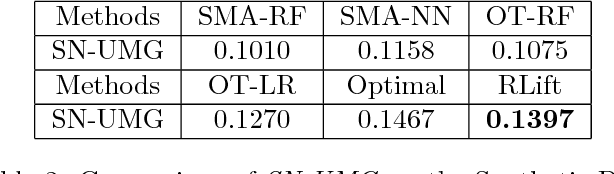
Uplift modeling aims to directly model the incremental impact of a treatment on an individual response. It has been widely and successfully used in healthcare analytics and business operations, where one tries to measure the net effect of a new medicine on patients or to understand the impact of a marketing campaign on company revenue. In this work, we address the problem from a new angle and reformulate it as a Markov Decision Process (MDP). This new formulation allows us to handle the lack of explicit labels, to deal with any number of actions (in comparison to the normal two action uplift modeling), and to apply it to applications with responses of general types, which is a challenging task for previous methods. Furthermore, we also design an unbiased metric for more accurate offline evaluation of uplift effects, set up a better reward function for the policy gradient method to solve the problem and adopt some action-based baselines to reduce variance. We conducted extensive experiments on both a synthetic dataset and real-world scenarios, and showed that our method can achieve significant improvement over previous methods.
Learning Temporal Point Processes via Reinforcement Learning
Nov 12, 2018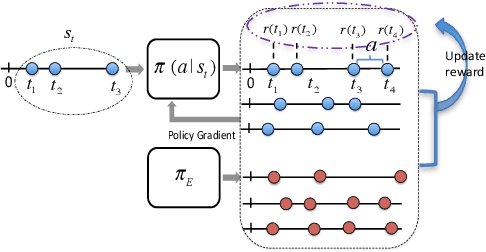
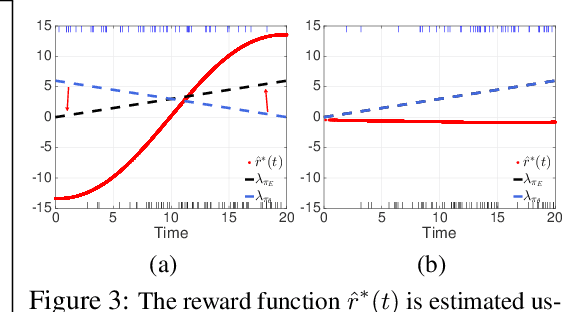
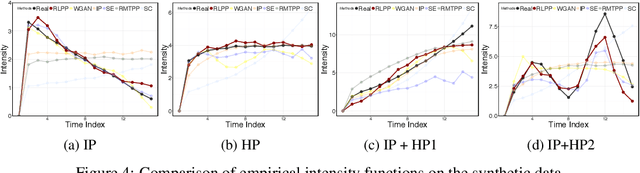
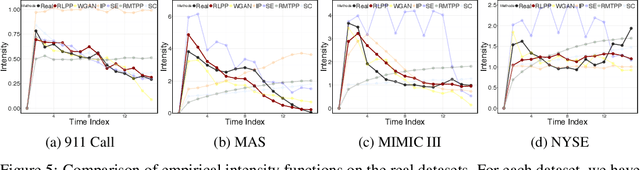
Social goods, such as healthcare, smart city, and information networks, often produce ordered event data in continuous time. The generative processes of these event data can be very complex, requiring flexible models to capture their dynamics. Temporal point processes offer an elegant framework for modeling event data without discretizing the time. However, the existing maximum-likelihood-estimation (MLE) learning paradigm requires hand-crafting the intensity function beforehand and cannot directly monitor the goodness-of-fit of the estimated model in the process of training. To alleviate the risk of model-misspecification in MLE, we propose to generate samples from the generative model and monitor the quality of the samples in the process of training until the samples and the real data are indistinguishable. We take inspiration from reinforcement learning (RL) and treat the generation of each event as the action taken by a stochastic policy. We parameterize the policy as a flexible recurrent neural network and gradually improve the policy to mimic the observed event distribution. Since the reward function is unknown in this setting, we uncover an analytic and nonparametric form of the reward function using an inverse reinforcement learning formulation. This new RL framework allows us to derive an efficient policy gradient algorithm for learning flexible point process models, and we show that it performs well in both synthetic and real data.
Kernel Exponential Family Estimation via Doubly Dual Embedding
Nov 06, 2018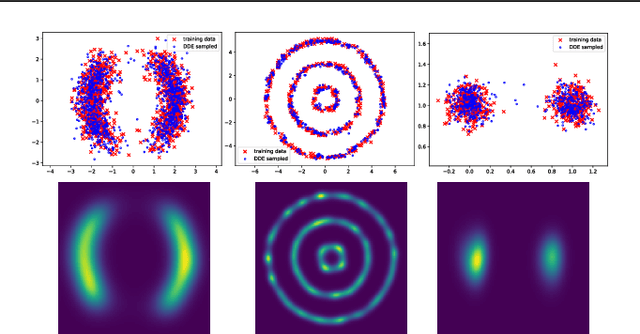
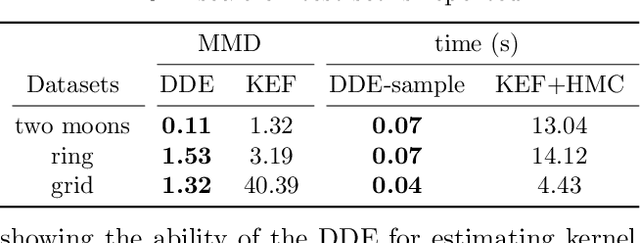
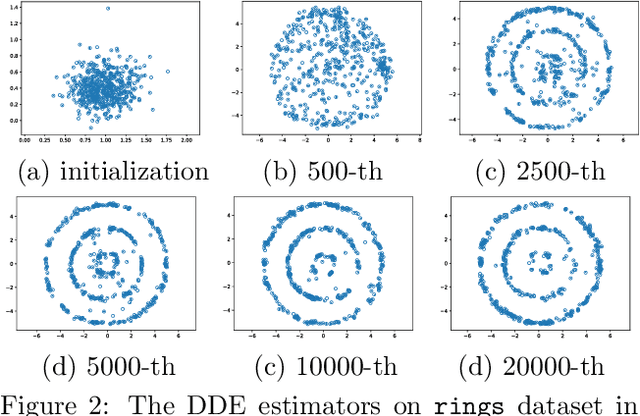
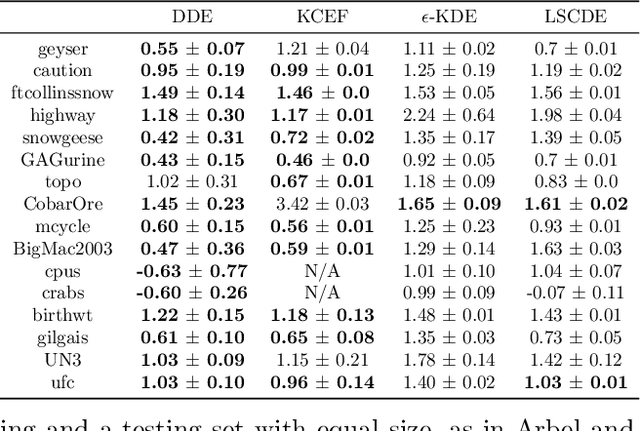
We investigate penalized maximum log-likelihood estimation for exponential family distributions whose natural parameter resides in a reproducing kernel Hilbert space. Key to our approach is a novel technique, doubly dual embedding, that avoids computation of the partition function. This technique also allows the development of a flexible sampling strategy that amortizes the cost of Monte-Carlo sampling in the inference stage. The resulting estimator can be easily generalized to kernel conditional exponential families. We furthermore establish a connection between infinite-dimensional exponential family estimation and MMD-GANs, revealing a new perspective for understanding GANs. Compared to current score matching based estimators, the proposed method improves both memory and time efficiency while enjoying stronger statistical properties, such as fully capturing smoothness in its statistical convergence rate while the score matching estimator appears to saturate. Finally, we show that the proposed estimator can empirically outperform state-of-the-art methods in both kernel exponential family estimation and its conditional extension.