 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning What Not to Impute: An Uncertainty-Aware Diffusion Framework for Meaningful Missingness
Jun 03, 2026Missing value imputation is a fundamental task in machine learning, with most existing methods assuming that all missing entries correspond to unobserved regular values. In many real-world datasets, however, missingness may arise from two distinct sources: some entries are meaningfully missing (intrinsically absent and semantically valid), while others are missing due to the observation process and should be imputed. We formalize this distinction as a selective imputation problem, where the goal is to jointly infer which missing entries should be preserved and which should be recovered. To address this challenge, we propose Diff-Joint, a diffusion-based framework that jointly models tabular data together with a latent missingness mask. The method alternates between conditional sampling and uncertainty-aware aggregation to iteratively refine both imputed values and missingness labels. Empirical results on synthetic and real-world datasets demonstrate that Diff-Joint effectively identifies meaningfully missing entries while achieving competitive imputation accuracy and improved downstream task performance.
Mamoda2.5: Enhancing Unified Multimodal Model with DiT-MoE
May 04, 2026We present Mamoda2.5, a unified AR-Diffusion framework that seamlessly integrates multimodal understanding and generation within a single architecture. To efficiently enhance the model's generation capability, we equip the Diffusion Transformer backbone with a fine-grained Mixture-of-Experts (MoE) design (128 experts, Top-8 routing), yielding a 25B-parameter model that activates only 3B parameters, significantly reducing training costs while scaling up the model capacity. Mamoda2.5 achieves top-tier generation performance on VBench 2.0 and sets a new record in video editing quality, surpassing evaluated open-source models and matching the performance of current top-tier proprietary models, including the Kling O1 on OpenVE-Bench. Furthermore, we introduce a joint few-step distillation and reinforcement learning framework that compresses the 30-step editing model into a 4-step model and greatly accelerates model inference. Compared to open-source baselines, Mamoda2.5 achieves up to $95.9\times$ faster video editing inference. In real-world applications, Mamoda2.5 has been successfully deployed for content moderation and creative restoration tasks in advertising scenarios, achieving a 98% success rate in internal advertising video editing scenario.
Learning to Test: Physics-Informed Representation for Dynamical Instability Detection
Apr 13, 2026Many safety-critical scientific and engineering systems evolve according to differential-algebraic equations (DAEs), where dynamical behavior is constrained by physical laws and admissibility conditions. In practice, these systems operate under stochastically varying environmental inputs, so stability is not a static property but must be reassessed as the context distribution shifts. Repeated large-scale DAE simulation, however, is computationally prohibitive in high-dimensional or real-time settings. This paper proposes a test-oriented learning framework for stability assessment under distribution shift. Rather than re-estimating physical parameters or repeatedly solving the underlying DAE, we learn a physics-informed latent representation of contextual variables that captures stability-relevant structure and is regularized toward a tractable reference distribution. Trained on baseline data from a certified safe regime, the learned representation enables deployment-time safety monitoring to be formulated as a distributional hypothesis test in latent space, with controlled Type I error. By integrating neural dynamical surrogates, uncertainty-aware calibration, and uniformity-based testing, our approach provides a scalable and statistically grounded method for detecting instability risk in stochastic constrained dynamical systems without repeated simulation.
Score-Based Change-Point Detection and Region Localization for Spatio-Temporal Point Processes
Feb 04, 2026We study sequential change-point detection for spatio-temporal point processes, where actionable detection requires not only identifying when a distributional change occurs but also localizing where it manifests in space. While classical quickest change detection methods provide strong guarantees on detection delay and false-alarm rates, existing approaches for point-process data predominantly focus on temporal changes and do not explicitly infer affected spatial regions. We propose a likelihood-free, score-based detection framework that jointly estimates the change time and the change region in continuous space-time without assuming parametric knowledge of the pre- or post-change dynamics. The method leverages a localized and conditionally weighted Hyvärinen score to quantify event-level deviations from nominal behavior and aggregates these scores using a spatio-temporal CUSUM-type statistic over a prescribed class of spatial regions. Operating sequentially, the procedure outputs both a stopping time and an estimated change region, enabling real-time detection with spatial interpretability. We establish theoretical guarantees on false-alarm control, detection delay, and spatial localization accuracy, and demonstrate the effectiveness of the proposed approach through simulations and real-world spatio-temporal event data.
When Robustness Meets Conservativeness: Conformalized Uncertainty Calibration for Balanced Decision Making
Oct 09, 2025
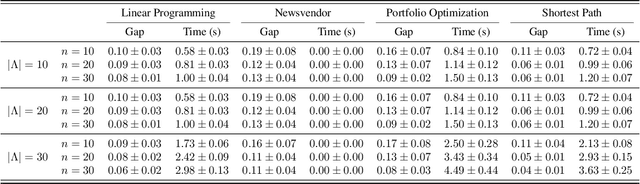
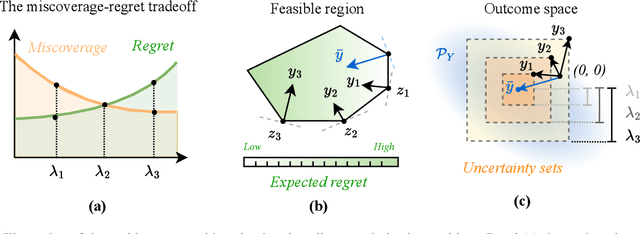

Robust optimization safeguards decisions against uncertainty by optimizing against worst-case scenarios, yet their effectiveness hinges on a prespecified robustness level that is often chosen ad hoc, leading to either insufficient protection or overly conservative and costly solutions. Recent approaches using conformal prediction construct data-driven uncertainty sets with finite-sample coverage guarantees, but they still fix coverage targets a priori and offer little guidance for selecting robustness levels. We propose a new framework that provides distribution-free, finite-sample guarantees on both miscoverage and regret for any family of robust predict-then-optimize policies. Our method constructs valid estimators that trace out the miscoverage-regret Pareto frontier, enabling decision-makers to reliably evaluate and calibrate robustness levels according to their cost-risk preferences. The framework is simple to implement, broadly applicable across classical optimization formulations, and achieves sharper finite-sample performance than existing approaches. These results offer the first principled data-driven methodology for guiding robustness selection and empower practitioners to balance robustness and conservativeness in high-stakes decision-making.
Conformalized Decision Risk Assessment
May 19, 2025



High-stakes decisions in domains such as healthcare, energy, and public policy are often made by human experts using domain knowledge and heuristics, yet are increasingly supported by predictive and optimization-based tools. A dominant approach in operations research is the predict-then-optimize paradigm, where a predictive model estimates uncertain inputs, and an optimization model recommends a decision. However, this approach often lacks interpretability and can fail under distributional uncertainty -- particularly when the outcome distribution is multi-modal or complex -- leading to brittle or misleading decisions. In this paper, we introduce CREDO, a novel framework that quantifies, for any candidate decision, a distribution-free upper bound on the probability that the decision is suboptimal. By combining inverse optimization geometry with conformal prediction and generative modeling, CREDO produces risk certificates that are both statistically rigorous and practically interpretable. This framework enables human decision-makers to audit and validate their own decisions under uncertainty, bridging the gap between algorithmic tools and real-world judgment.
Adaptive Robust Optimization with Data-Driven Uncertainty for Enhancing Distribution System Resilience
May 16, 2025Extreme weather events are placing growing strain on electric power systems, exposing the limitations of purely reactive responses and prompting the need for proactive resilience planning. However, existing approaches often rely on simplified uncertainty models and decouple proactive and reactive decisions, overlooking their critical interdependence. This paper proposes a novel tri-level optimization framework that integrates proactive infrastructure investment, adversarial modeling of spatio-temporal disruptions, and adaptive reactive response. We construct high-probability, distribution-free uncertainty sets using conformal prediction to capture complex and data-scarce outage patterns. To solve the resulting nested decision problem, we derive a bi-level reformulation via strong duality and develop a scalable Benders decomposition algorithm. Experiments on both real and synthetic data demonstrate that our approach consistently outperforms conventional robust and two-stage methods, achieving lower worst-case losses and more efficient resource allocation, especially under tight operational constraints and large-scale uncertainty.
Topology-Aware Conformal Prediction for Stream Networks
Mar 06, 2025



Stream networks, a unique class of spatiotemporal graphs, exhibit complex directional flow constraints and evolving dependencies, making uncertainty quantification a critical yet challenging task. Traditional conformal prediction methods struggle in this setting due to the need for joint predictions across multiple interdependent locations and the intricate spatio-temporal dependencies inherent in stream networks. Existing approaches either neglect dependencies, leading to overly conservative predictions, or rely solely on data-driven estimations, failing to capture the rich topological structure of the network. To address these challenges, we propose Spatio-Temporal Adaptive Conformal Inference (\texttt{STACI}), a novel framework that integrates network topology and temporal dynamics into the conformal prediction framework. \texttt{STACI} introduces a topology-aware nonconformity score that respects directional flow constraints and dynamically adjusts prediction sets to account for temporal distributional shifts. We provide theoretical guarantees on the validity of our approach and demonstrate its superior performance on both synthetic and real-world datasets. Our results show that \texttt{STACI} effectively balances prediction efficiency and coverage, outperforming existing conformal prediction methods for stream networks.
Global-Decision-Focused Neural ODEs for Proactive Grid Resilience Management
Feb 25, 2025Extreme hazard events such as wildfires and hurricanes increasingly threaten power systems, causing widespread outages and disrupting critical services. Recently, predict-then-optimize approaches have gained traction in grid operations, where system functionality forecasts are first generated and then used as inputs for downstream decision-making. However, this two-stage method often results in a misalignment between prediction and optimization objectives, leading to suboptimal resource allocation. To address this, we propose predict-all-then-optimize-globally (PATOG), a framework that integrates outage prediction with globally optimized interventions. At its core, our global-decision-focused (GDF) neural ODE model captures outage dynamics while optimizing resilience strategies in a decision-aware manner. Unlike conventional methods, our approach ensures spatially and temporally coherent decision-making, improving both predictive accuracy and operational efficiency. Experiments on synthetic and real-world datasets demonstrate significant improvements in outage prediction consistency and grid resilience.
Gen-DFL: Decision-Focused Generative Learning for Robust Decision Making
Feb 08, 2025



Decision-focused learning (DFL) integrates predictive models with downstream optimization, directly training machine learning models to minimize decision errors. While DFL has been shown to provide substantial advantages when compared to a counterpart that treats the predictive and prescriptive models separately, it has also been shown to struggle in high-dimensional and risk-sensitive settings, limiting its applicability in real-world settings. To address this limitation, this paper introduces decision-focused generative learning (Gen-DFL), a novel framework that leverages generative models to adaptively model uncertainty and improve decision quality. Instead of relying on fixed uncertainty sets, Gen-DFL learns a structured representation of the optimization parameters and samples from the tail regions of the learned distribution to enhance robustness against worst-case scenarios. This approach mitigates over-conservatism while capturing complex dependencies in the parameter space. The paper shows, theoretically, that Gen-DFL achieves improved worst-case performance bounds compared to traditional DFL. Empirically, it evaluates Gen-DFL on various scheduling and logistics problems, demonstrating its strong performance against existing DFL methods.