 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart broadcasting: Do you want to be seen?
May 22, 2016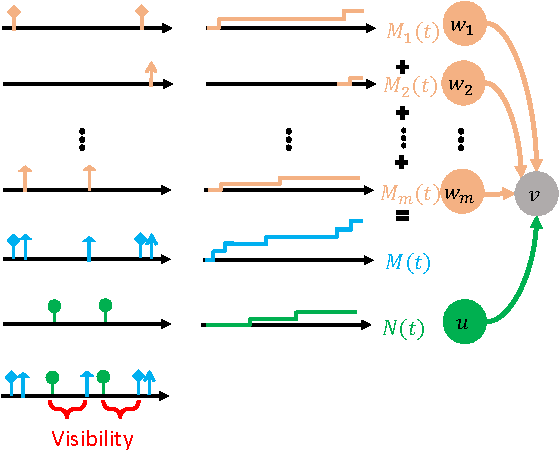
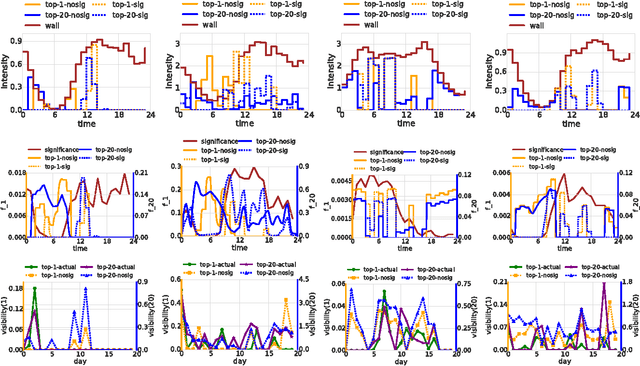
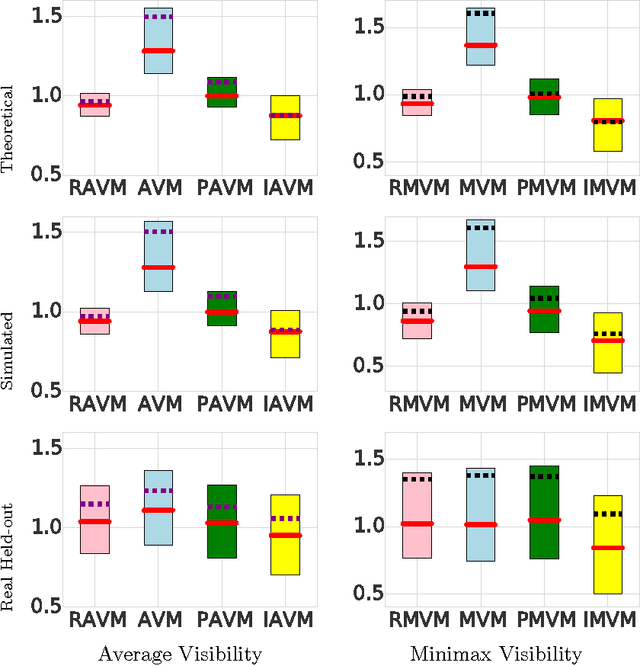
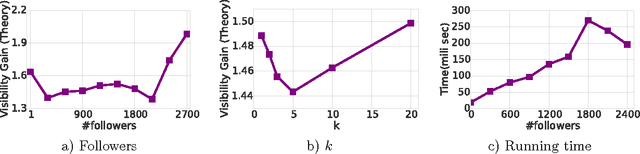
Many users in online social networks are constantly trying to gain attention from their followers by broadcasting posts to them. These broadcasters are likely to gain greater attention if their posts can remain visible for a longer period of time among their followers' most recent feeds. Then when to post? In this paper, we study the problem of smart broadcasting using the framework of temporal point processes, where we model users feeds and posts as discrete events occurring in continuous time. Based on such continuous-time model, then choosing a broadcasting strategy for a user becomes a problem of designing the conditional intensity of her posting events. We derive a novel formula which links this conditional intensity with the visibility of the user in her followers' feeds. Furthermore, by exploiting this formula, we develop an efficient convex optimization framework for the when-to-post problem. Our method can find broadcasting strategies that reach a desired visibility level with provable guarantees. We experimented with data gathered from Twitter, and show that our framework can consistently make broadcasters' post more visible than alternatives.
Provable Bayesian Inference via Particle Mirror Descent
May 05, 2016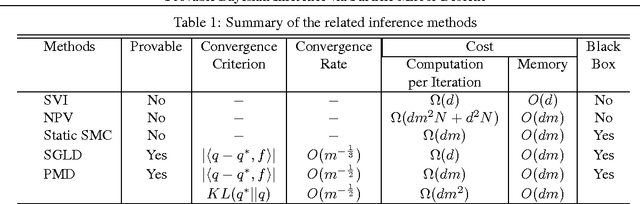
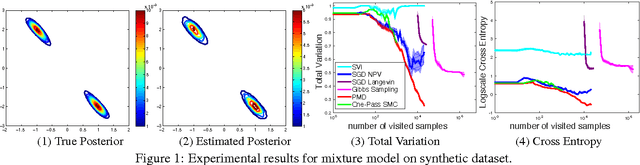
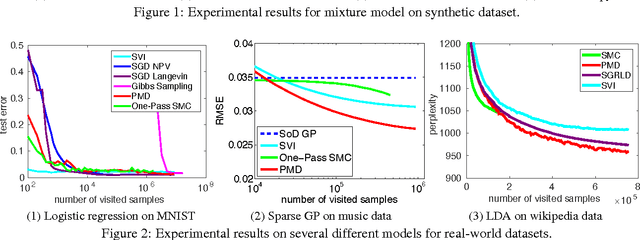
Bayesian methods are appealing in their flexibility in modeling complex data and ability in capturing uncertainty in parameters. However, when Bayes' rule does not result in tractable closed-form, most approximate inference algorithms lack either scalability or rigorous guarantees. To tackle this challenge, we propose a simple yet provable algorithm, \emph{Particle Mirror Descent} (PMD), to iteratively approximate the posterior density. PMD is inspired by stochastic functional mirror descent where one descends in the density space using a small batch of data points at each iteration, and by particle filtering where one uses samples to approximate a function. We prove result of the first kind that, with $m$ particles, PMD provides a posterior density estimator that converges in terms of $KL$-divergence to the true posterior in rate $O(1/\sqrt{m})$. We demonstrate competitive empirical performances of PMD compared to several approximate inference algorithms in mixture models, logistic regression, sparse Gaussian processes and latent Dirichlet allocation on large scale datasets.
COEVOLVE: A Joint Point Process Model for Information Diffusion and Network Co-evolution
Apr 01, 2016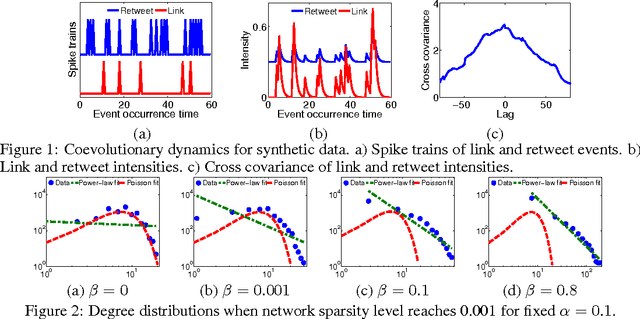
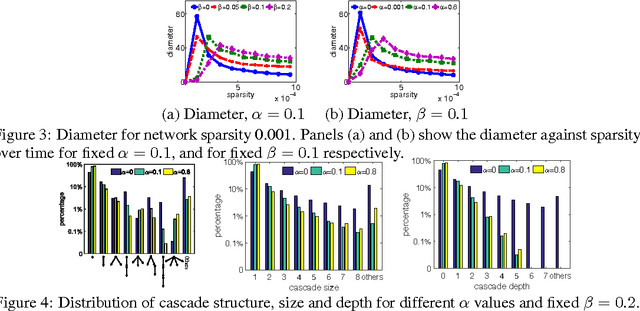
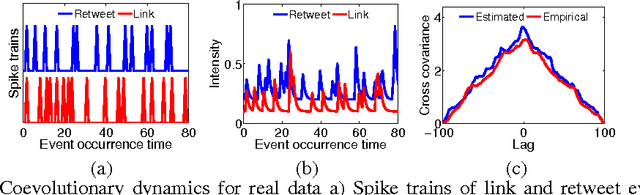
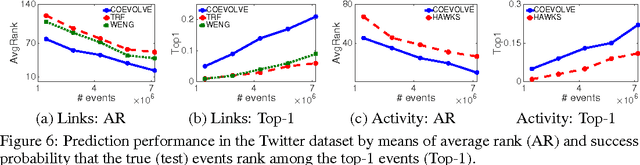
Information diffusion in online social networks is affected by the underlying network topology, but it also has the power to change it. Online users are constantly creating new links when exposed to new information sources, and in turn these links are alternating the way information spreads. However, these two highly intertwined stochastic processes, information diffusion and network evolution, have been predominantly studied separately, ignoring their co-evolutionary dynamics. We propose a temporal point process model, COEVOLVE, for such joint dynamics, allowing the intensity of one process to be modulated by that of the other. This model allows us to efficiently simulate interleaved diffusion and network events, and generate traces obeying common diffusion and network patterns observed in real-world networks. Furthermore, we also develop a convex optimization framework to learn the parameters of the model from historical diffusion and network evolution traces. We experimented with both synthetic data and data gathered from Twitter, and show that our model provides a good fit to the data as well as more accurate predictions than alternatives.
Communication Efficient Distributed Kernel Principal Component Analysis
Feb 13, 2016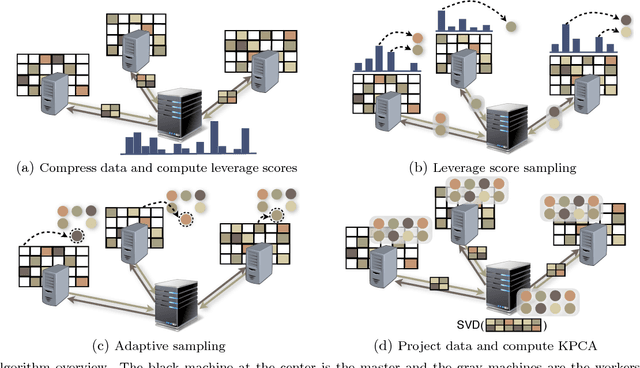
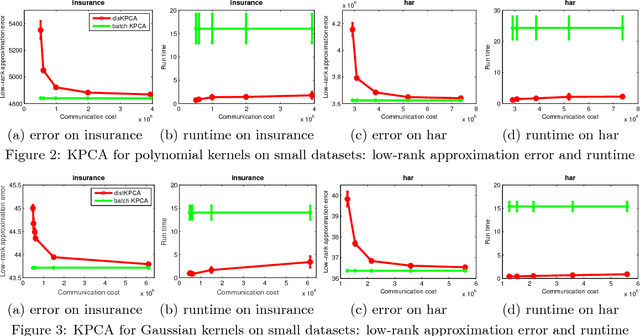
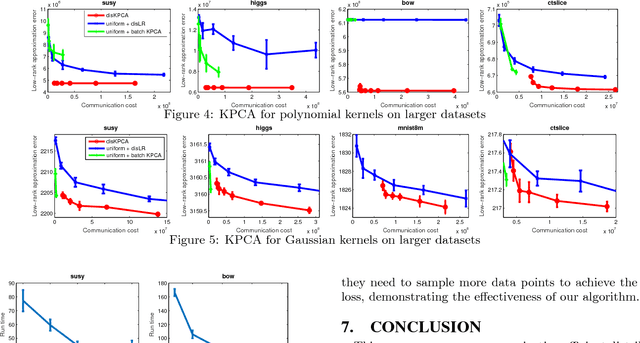
Kernel Principal Component Analysis (KPCA) is a key machine learning algorithm for extracting nonlinear features from data. In the presence of a large volume of high dimensional data collected in a distributed fashion, it becomes very costly to communicate all of this data to a single data center and then perform kernel PCA. Can we perform kernel PCA on the entire dataset in a distributed and communication efficient fashion while maintaining provable and strong guarantees in solution quality? In this paper, we give an affirmative answer to the question by developing a communication efficient algorithm to perform kernel PCA in the distributed setting. The algorithm is a clever combination of subspace embedding and adaptive sampling techniques, and we show that the algorithm can take as input an arbitrary configuration of distributed datasets, and compute a set of global kernel principal components with relative error guarantees independent of the dimension of the feature space or the total number of data points. In particular, computing $k$ principal components with relative error $\epsilon$ over $s$ workers has communication cost $\tilde{O}(s \rho k/\epsilon+s k^2/\epsilon^3)$ words, where $\rho$ is the average number of nonzero entries in each data point. Furthermore, we experimented the algorithm with large-scale real world datasets and showed that the algorithm produces a high quality kernel PCA solution while using significantly less communication than alternative approaches.
Scale Up Nonlinear Component Analysis with Doubly Stochastic Gradients
Jan 10, 2016
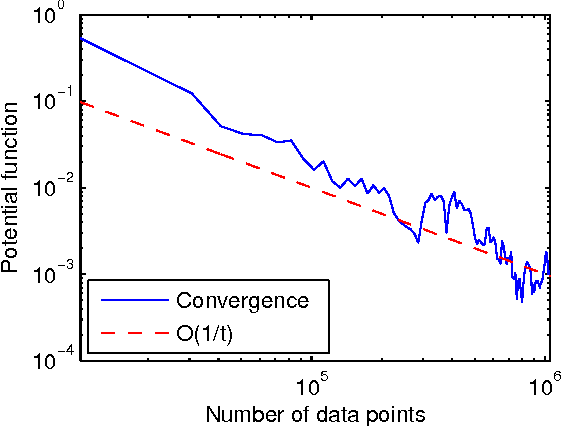
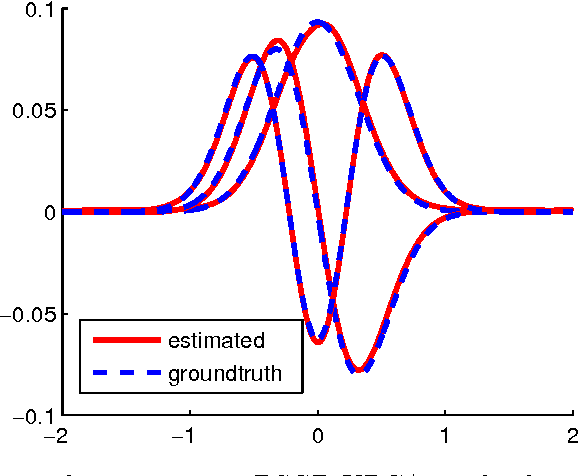
Nonlinear component analysis such as kernel Principle Component Analysis (KPCA) and kernel Canonical Correlation Analysis (KCCA) are widely used in machine learning, statistics and data analysis, but they can not scale up to big datasets. Recent attempts have employed random feature approximations to convert the problem to the primal form for linear computational complexity. However, to obtain high quality solutions, the number of random features should be the same order of magnitude as the number of data points, making such approach not directly applicable to the regime with millions of data points. We propose a simple, computationally efficient, and memory friendly algorithm based on the "doubly stochastic gradients" to scale up a range of kernel nonlinear component analysis, such as kernel PCA, CCA and SVD. Despite the \emph{non-convex} nature of these problems, our method enjoys theoretical guarantees that it converges at the rate $\tilde{O}(1/t)$ to the global optimum, even for the top $k$ eigen subspace. Unlike many alternatives, our algorithm does not require explicit orthogonalization, which is infeasible on big datasets. We demonstrate the effectiveness and scalability of our algorithm on large scale synthetic and real world datasets.
A Continuous-time Mutually-Exciting Point Process Framework for Prioritizing Events in Social Media
Nov 13, 2015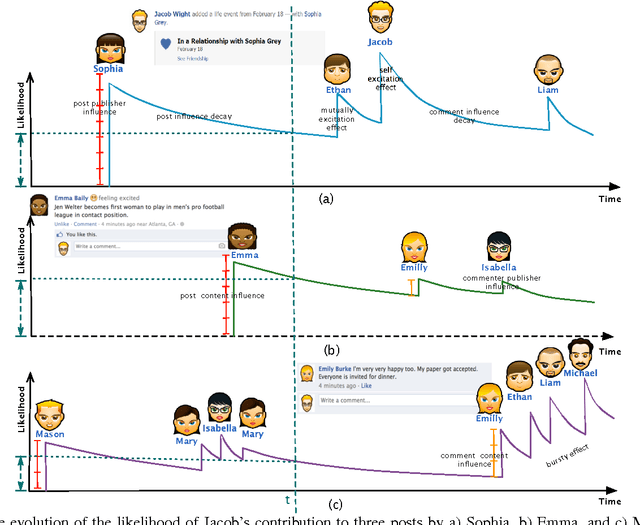
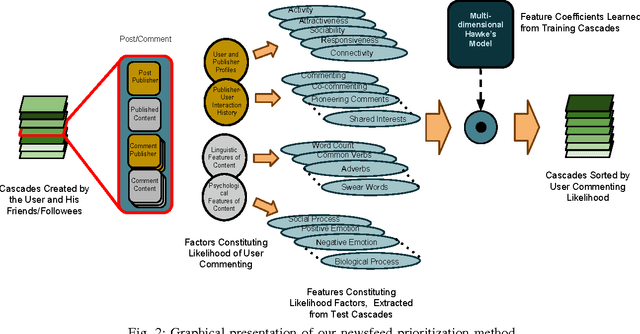
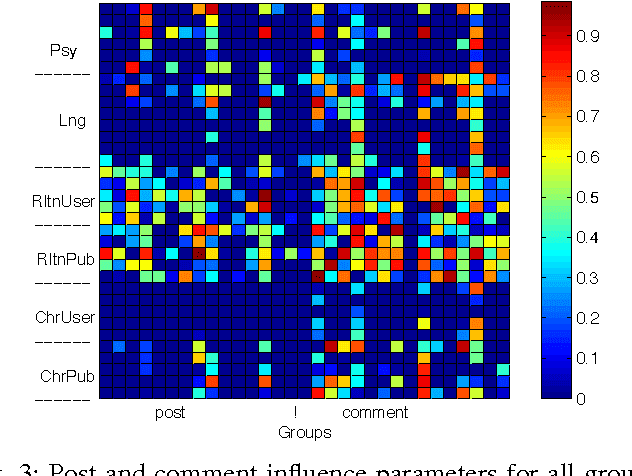
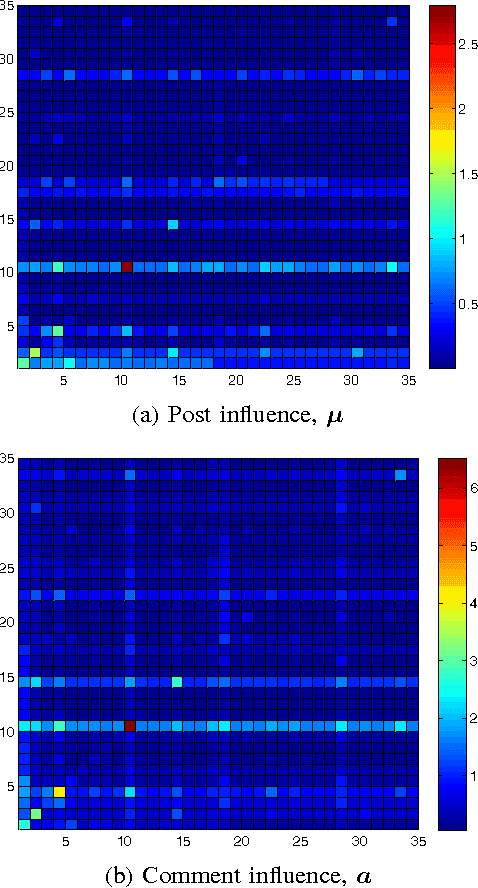
The overwhelming amount and rate of information update in online social media is making it increasingly difficult for users to allocate their attention to their topics of interest, thus there is a strong need for prioritizing news feeds. The attractiveness of a post to a user depends on many complex contextual and temporal features of the post. For instance, the contents of the post, the responsiveness of a third user, and the age of the post may all have impact. So far, these static and dynamic features has not been incorporated in a unified framework to tackle the post prioritization problem. In this paper, we propose a novel approach for prioritizing posts based on a feature modulated multi-dimensional point process. Our model is able to simultaneously capture textual and sentiment features, and temporal features such as self-excitation, mutual-excitation and bursty nature of social interaction. As an evaluation, we also curated a real-world conversational benchmark dataset crawled from Facebook. In our experiments, we demonstrate that our algorithm is able to achieve the-state-of-the-art performance in terms of analyzing, predicting, and prioritizing events. In terms of interpretability of our method, we observe that features indicating individual user profile and linguistic characteristics of the events work best for prediction and prioritization of new events.
Scalable Kernel Methods via Doubly Stochastic Gradients
Sep 10, 2015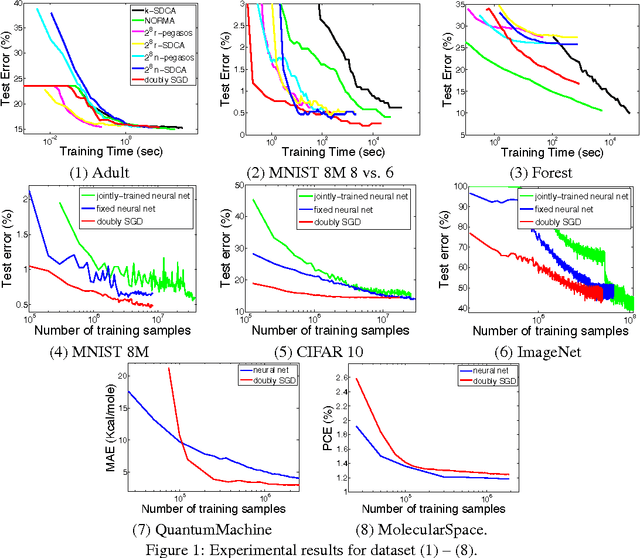
The general perception is that kernel methods are not scalable, and neural nets are the methods of choice for nonlinear learning problems. Or have we simply not tried hard enough for kernel methods? Here we propose an approach that scales up kernel methods using a novel concept called "doubly stochastic functional gradients". Our approach relies on the fact that many kernel methods can be expressed as convex optimization problems, and we solve the problems by making two unbiased stochastic approximations to the functional gradient, one using random training points and another using random functions associated with the kernel, and then descending using this noisy functional gradient. We show that a function produced by this procedure after $t$ iterations converges to the optimal function in the reproducing kernel Hilbert space in rate $O(1/t)$, and achieves a generalization performance of $O(1/\sqrt{t})$. This doubly stochasticity also allows us to avoid keeping the support vectors and to implement the algorithm in a small memory footprint, which is linear in number of iterations and independent of data dimension. Our approach can readily scale kernel methods up to the regimes which are dominated by neural nets. We show that our method can achieve competitive performance to neural nets in datasets such as 8 million handwritten digits from MNIST, 2.3 million energy materials from MolecularSpace, and 1 million photos from ImageNet.
Online Supervised Subspace Tracking
Sep 01, 2015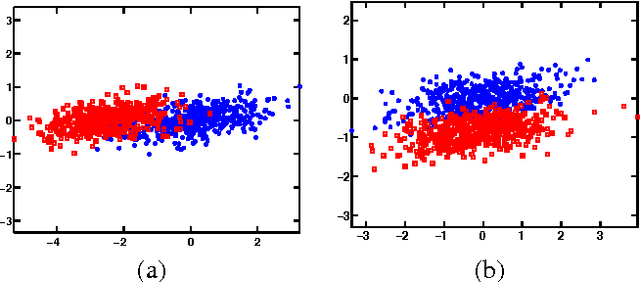

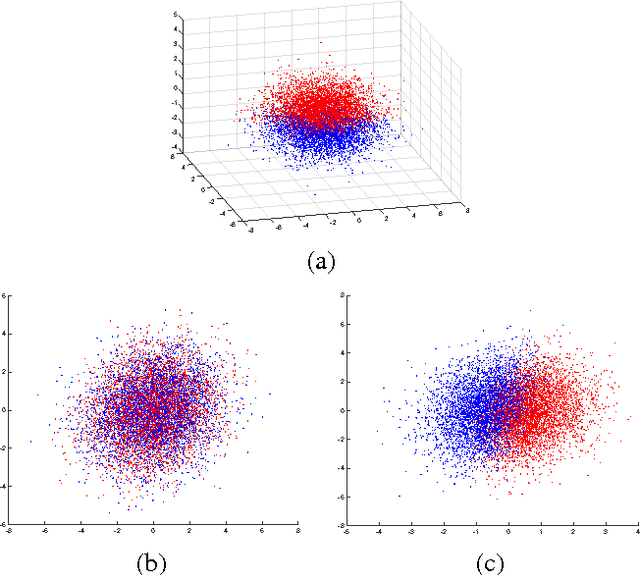
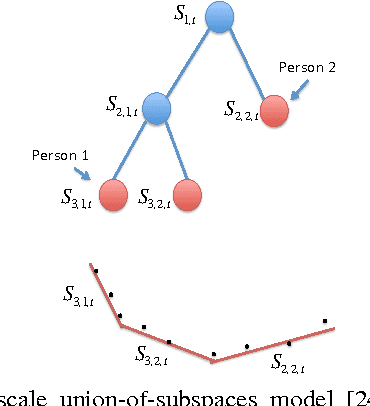
We present a framework for supervised subspace tracking, when there are two time series $x_t$ and $y_t$, one being the high-dimensional predictors and the other being the response variables and the subspace tracking needs to take into consideration of both sequences. It extends the classic online subspace tracking work which can be viewed as tracking of $x_t$ only. Our online sufficient dimensionality reduction (OSDR) is a meta-algorithm that can be applied to various cases including linear regression, logistic regression, multiple linear regression, multinomial logistic regression, support vector machine, the random dot product model and the multi-scale union-of-subspace model. OSDR reduces data-dimensionality on-the-fly with low-computational complexity and it can also handle missing data and dynamic data. OSDR uses an alternating minimization scheme and updates the subspace via gradient descent on the Grassmannian manifold. The subspace update can be performed efficiently utilizing the fact that the Grassmannian gradient with respect to the subspace in many settings is rank-one (or low-rank in certain cases). The optimization problem for OSDR is non-convex and hard to analyze in general; we provide convergence analysis of OSDR in a simple linear regression setting. The good performance of OSDR compared with the conventional unsupervised subspace tracking are demonstrated via numerical examples on simulated and real data.
Deep Fried Convnets
Jul 17, 2015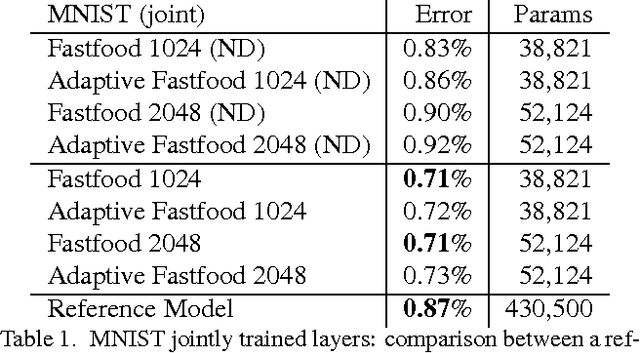
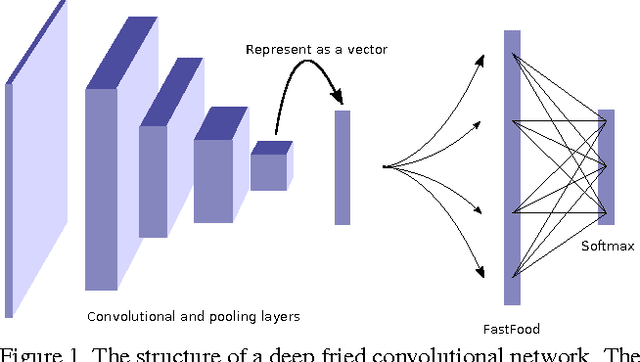
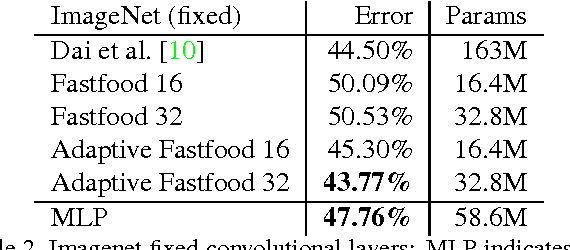
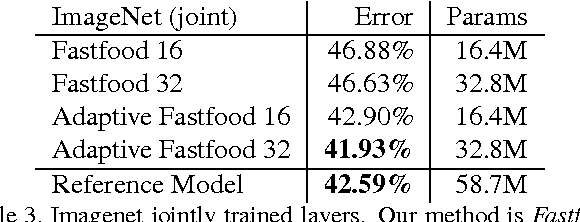
The fully connected layers of a deep convolutional neural network typically contain over 90% of the network parameters, and consume the majority of the memory required to store the network parameters. Reducing the number of parameters while preserving essentially the same predictive performance is critically important for operating deep neural networks in memory constrained environments such as GPUs or embedded devices. In this paper we show how kernel methods, in particular a single Fastfood layer, can be used to replace all fully connected layers in a deep convolutional neural network. This novel Fastfood layer is also end-to-end trainable in conjunction with convolutional layers, allowing us to combine them into a new architecture, named deep fried convolutional networks, which substantially reduces the memory footprint of convolutional networks trained on MNIST and ImageNet with no drop in predictive performance.
A la Carte - Learning Fast Kernels
Dec 19, 2014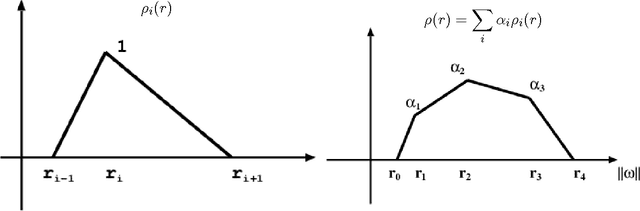
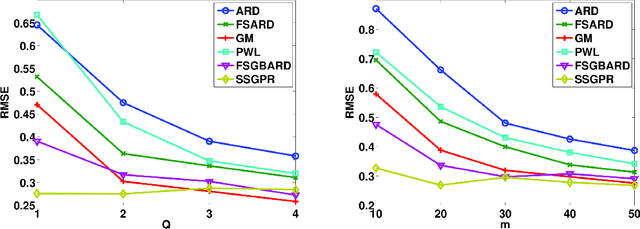
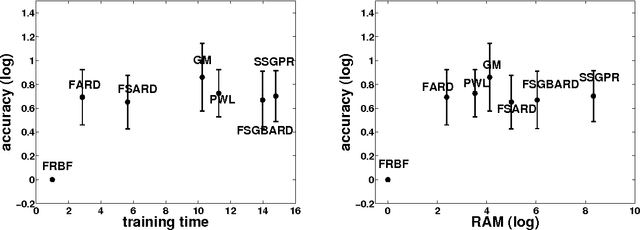
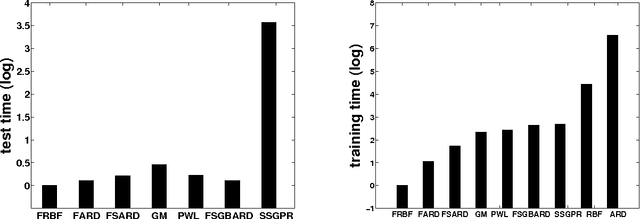
Kernel methods have great promise for learning rich statistical representations of large modern datasets. However, compared to neural networks, kernel methods have been perceived as lacking in scalability and flexibility. We introduce a family of fast, flexible, lightly parametrized and general purpose kernel learning methods, derived from Fastfood basis function expansions. We provide mechanisms to learn the properties of groups of spectral frequencies in these expansions, which require only O(mlogd) time and O(m) memory, for m basis functions and d input dimensions. We show that the proposed methods can learn a wide class of kernels, outperforming the alternatives in accuracy, speed, and memory consumption.