 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-reasoning Technical Report
Apr 30, 2025We introduce Phi-4-reasoning, a 14-billion parameter reasoning model that achieves strong performance on complex reasoning tasks. Trained via supervised fine-tuning of Phi-4 on carefully curated set of "teachable" prompts-selected for the right level of complexity and diversity-and reasoning demonstrations generated using o3-mini, Phi-4-reasoning generates detailed reasoning chains that effectively leverage inference-time compute. We further develop Phi-4-reasoning-plus, a variant enhanced through a short phase of outcome-based reinforcement learning that offers higher performance by generating longer reasoning traces. Across a wide range of reasoning tasks, both models outperform significantly larger open-weight models such as DeepSeek-R1-Distill-Llama-70B model and approach the performance levels of full DeepSeek-R1 model. Our comprehensive evaluations span benchmarks in math and scientific reasoning, coding, algorithmic problem solving, planning, and spatial understanding. Interestingly, we observe a non-trivial transfer of improvements to general-purpose benchmarks as well. In this report, we provide insights into our training data, our training methodologies, and our evaluations. We show that the benefit of careful data curation for supervised fine-tuning (SFT) extends to reasoning language models, and can be further amplified by reinforcement learning (RL). Finally, our evaluation points to opportunities for improving how we assess the performance and robustness of reasoning models.
Inference-Time Scaling for Complex Tasks: Where We Stand and What Lies Ahead
Mar 31, 2025Inference-time scaling can enhance the reasoning capabilities of large language models (LLMs) on complex problems that benefit from step-by-step problem solving. Although lengthening generated scratchpads has proven effective for mathematical tasks, the broader impact of this approach on other tasks remains less clear. In this work, we investigate the benefits and limitations of scaling methods across nine state-of-the-art models and eight challenging tasks, including math and STEM reasoning, calendar planning, NP-hard problems, navigation, and spatial reasoning. We compare conventional models (e.g., GPT-4o) with models fine-tuned for inference-time scaling (e.g., o1) through evaluation protocols that involve repeated model calls, either independently or sequentially with feedback. These evaluations approximate lower and upper performance bounds and potential for future performance improvements for each model, whether through enhanced training or multi-model inference systems. Our extensive empirical analysis reveals that the advantages of inference-time scaling vary across tasks and diminish as problem complexity increases. In addition, simply using more tokens does not necessarily translate to higher accuracy in these challenging regimes. Results from multiple independent runs with conventional models using perfect verifiers show that, for some tasks, these models can achieve performance close to the average performance of today's most advanced reasoning models. However, for other tasks, a significant performance gap remains, even in very high scaling regimes. Encouragingly, all models demonstrate significant gains when inference is further scaled with perfect verifiers or strong feedback, suggesting ample potential for future improvements.
Unearthing Skill-Level Insights for Understanding Trade-Offs of Foundation Models
Oct 17, 2024



With models getting stronger, evaluations have grown more complex, testing multiple skills in one benchmark and even in the same instance at once. However, skill-wise performance is obscured when inspecting aggregate accuracy, under-utilizing the rich signal modern benchmarks contain. We propose an automatic approach to recover the underlying skills relevant for any evaluation instance, by way of inspecting model-generated rationales. After validating the relevance of rationale-parsed skills and inferring skills for $46$k instances over $12$ benchmarks, we observe many skills to be common across benchmarks, resulting in the curation of hundreds of skill-slices (i.e. sets of instances testing a common skill). Inspecting accuracy over these slices yields novel insights on model trade-offs: e.g., compared to GPT-4o and Claude 3.5 Sonnet, on average, Gemini 1.5 Pro is $18\%$ more accurate in "computing molar mass", but $19\%$ less accurate in "applying constitutional law", despite the overall accuracies of the three models differing by a mere $0.4\%$. Furthermore, we demonstrate the practical utility of our approach by showing that insights derived from skill slice analysis can generalize to held-out instances: when routing each instance to the model strongest on the relevant skills, we see a $3\%$ accuracy improvement over our $12$ dataset corpus. Our skill-slices and framework open a new avenue in model evaluation, leveraging skill-specific analyses to unlock a more granular and actionable understanding of model capabilities.
Eureka: Evaluating and Understanding Large Foundation Models
Sep 13, 2024Rigorous and reproducible evaluation is critical for assessing the state of the art and for guiding scientific advances in Artificial Intelligence. Evaluation is challenging in practice due to several reasons, including benchmark saturation, lack of transparency in methods used for measurement, development challenges in extracting measurements for generative tasks, and, more generally, the extensive number of capabilities required for a well-rounded comparison across models. We make three contributions to alleviate the above challenges. First, we present Eureka, an open-source framework for standardizing evaluations of large foundation models beyond single-score reporting and rankings. Second, we introduce Eureka-Bench as an extensible collection of benchmarks testing capabilities that (i) are still challenging for state-of-the-art models and (ii) represent fundamental but overlooked language and multimodal capabilities. The inherent space for improvement in non-saturated benchmarks enables us to discover meaningful differences between models at a capability level. Third, using Eureka, we conduct an analysis of 12 state-of-the-art models, providing in-depth insights into failure understanding and model comparison, which can be leveraged to plan targeted improvements. In contrast to recent trends in reports and leaderboards showing absolute rankings and claims for one model or another to be the best, our analysis shows that there is no such best model. Different models have different strengths, but there are models that appear more often than others as best performers for some capabilities. Despite the recent improvements, current models still struggle with several fundamental capabilities including detailed image understanding, benefiting from multimodal input when available rather than fully relying on language, factuality and grounding for information retrieval, and over refusals.
In-Context Learning in Large Language Models: A Neuroscience-inspired Analysis of Representations
Oct 18, 2023



Large language models (LLMs) exhibit remarkable performance improvement through in-context learning (ICL) by leveraging task-specific examples in the input. However, the mechanisms behind this improvement remain elusive. In this work, we investigate embeddings and attention representations in Llama-2 70B and Vicuna 13B. Specifically, we study how embeddings and attention change after in-context-learning, and how these changes mediate improvement in behavior. We employ neuroscience-inspired techniques, such as representational similarity analysis (RSA), and propose novel methods for parameterized probing and attention ratio analysis (ARA, measuring the ratio of attention to relevant vs. irrelevant information). We designed three tasks with a priori relationships among their conditions: reading comprehension, linear regression, and adversarial prompt injection. We formed hypotheses about expected similarities in task representations to investigate latent changes in embeddings and attention. Our analyses revealed a meaningful correlation between changes in both embeddings and attention representations with improvements in behavioral performance after ICL. This empirical framework empowers a nuanced understanding of how latent representations affect LLM behavior with and without ICL, offering valuable tools and insights for future research and practical applications.
Streaming Active Learning with Deep Neural Networks
Mar 05, 2023Active learning is perhaps most naturally posed as an online learning problem. However, prior active learning approaches with deep neural networks assume offline access to the entire dataset ahead of time. This paper proposes VeSSAL, a new algorithm for batch active learning with deep neural networks in streaming settings, which samples groups of points to query for labels at the moment they are encountered. Our approach trades off between uncertainty and diversity of queried samples to match a desired query rate without requiring any hand-tuned hyperparameters. Altogether, we expand the applicability of deep neural networks to realistic active learning scenarios, such as applications relevant to HCI and large, fractured datasets.
Detecting Elevated Air Pollution Levels by Monitoring Web Search Queries: Deep Learning-Based Time Series Forecasting
Nov 09, 2022



Real-time air pollution monitoring is a valuable tool for public health and environmental surveillance. In recent years, there has been a dramatic increase in air pollution forecasting and monitoring research using artificial neural networks (ANNs). Most of the prior work relied on modeling pollutant concentrations collected from ground-based monitors and meteorological data for long-term forecasting of outdoor ozone, oxides of nitrogen, and PM2.5. Given that traditional, highly sophisticated air quality monitors are expensive and are not universally available, these models cannot adequately serve those not living near pollutant monitoring sites. Furthermore, because prior models were built on physical measurement data collected from sensors, they may not be suitable for predicting public health effects experienced from pollution exposure. This study aims to develop and validate models to nowcast the observed pollution levels using Web search data, which is publicly available in near real-time from major search engines. We developed novel machine learning-based models using both traditional supervised classification methods and state-of-the-art deep learning methods to detect elevated air pollution levels at the US city level, by using generally available meteorological data and aggregate Web-based search volume data derived from Google Trends. We validated the performance of these methods by predicting three critical air pollutants (ozone (O3), nitrogen dioxide (NO2), and fine particulate matter (PM2.5)), across ten major U.S. metropolitan statistical areas (MSAs) in 2017 and 2018.
Learning Genomic Representations to Predict Clinical Outcomes in Cancer
Sep 27, 2016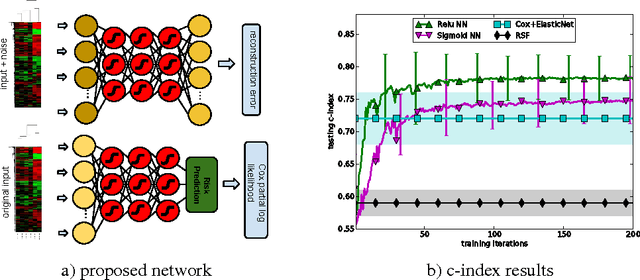
Genomics are rapidly transforming medical practice and basic biomedical research, providing insights into disease mechanisms and improving therapeutic strategies, particularly in cancer. The ability to predict the future course of a patient's disease from high-dimensional genomic profiling will be essential in realizing the promise of genomic medicine, but presents significant challenges for state-of-the-art survival analysis methods. In this abstract we present an investigation in learning genomic representations with neural networks to predict patient survival in cancer. We demonstrate the advantages of this approach over existing survival analysis methods using brain tumor data.
A Continuous-time Mutually-Exciting Point Process Framework for Prioritizing Events in Social Media
Nov 13, 2015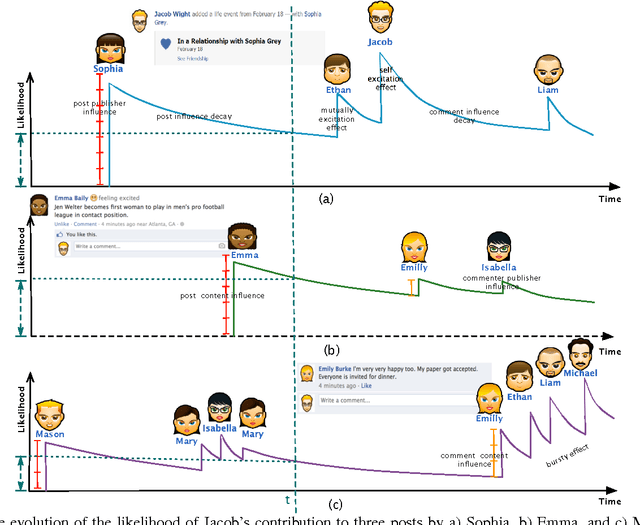
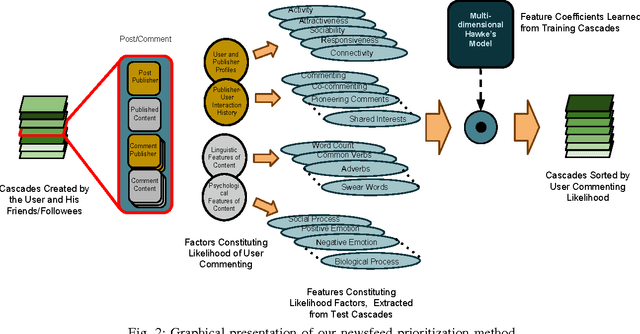
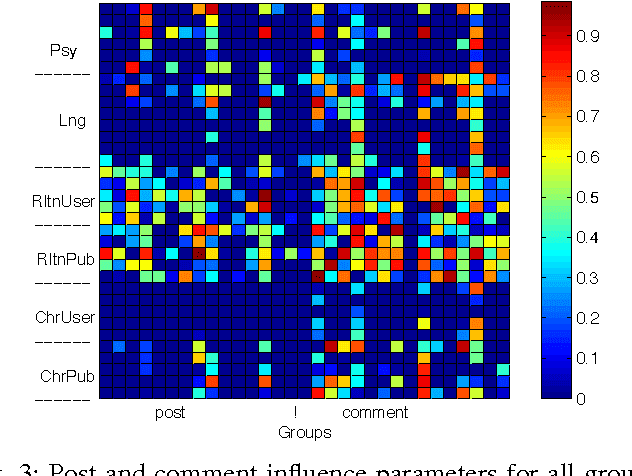
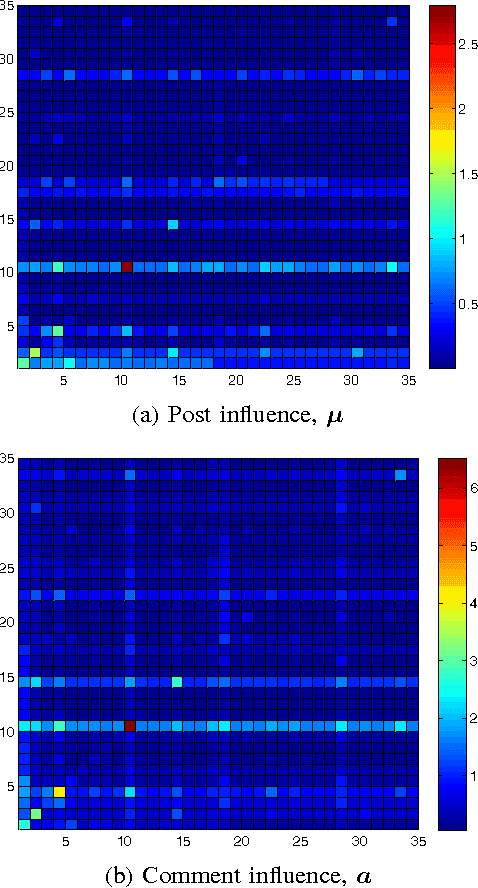
The overwhelming amount and rate of information update in online social media is making it increasingly difficult for users to allocate their attention to their topics of interest, thus there is a strong need for prioritizing news feeds. The attractiveness of a post to a user depends on many complex contextual and temporal features of the post. For instance, the contents of the post, the responsiveness of a third user, and the age of the post may all have impact. So far, these static and dynamic features has not been incorporated in a unified framework to tackle the post prioritization problem. In this paper, we propose a novel approach for prioritizing posts based on a feature modulated multi-dimensional point process. Our model is able to simultaneously capture textual and sentiment features, and temporal features such as self-excitation, mutual-excitation and bursty nature of social interaction. As an evaluation, we also curated a real-world conversational benchmark dataset crawled from Facebook. In our experiments, we demonstrate that our algorithm is able to achieve the-state-of-the-art performance in terms of analyzing, predicting, and prioritizing events. In terms of interpretability of our method, we observe that features indicating individual user profile and linguistic characteristics of the events work best for prediction and prioritization of new events.