 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly supervised cross-domain alignment with optimal transport
Aug 14, 2020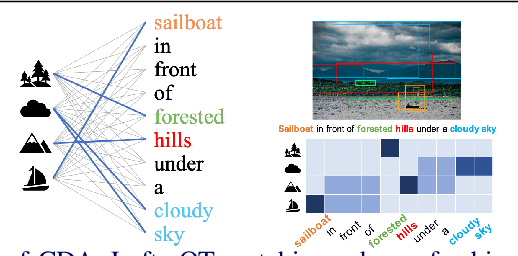
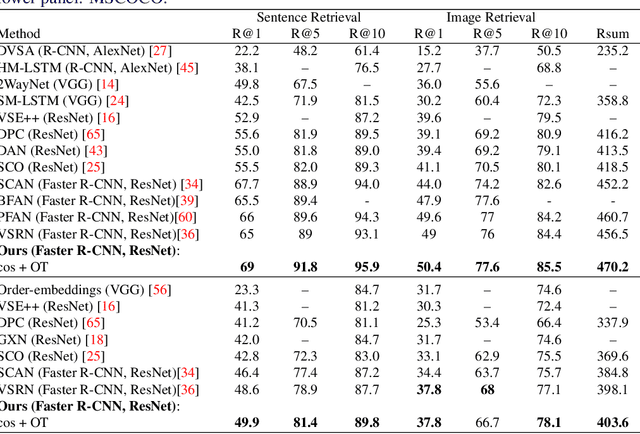
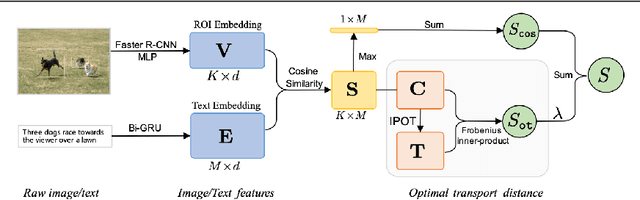
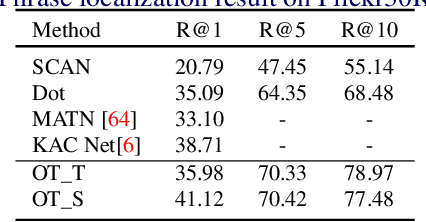
Cross-domain alignment between image objects and text sequences is key to many visual-language tasks, and it poses a fundamental challenge to both computer vision and natural language processing. This paper investigates a novel approach for the identification and optimization of fine-grained semantic similarities between image and text entities, under a weakly-supervised setup, improving performance over state-of-the-art solutions. Our method builds upon recent advances in optimal transport (OT) to resolve the cross-domain matching problem in a principled manner. Formulated as a drop-in regularizer, the proposed OT solution can be efficiently computed and used in combination with other existing approaches. We present empirical evidence to demonstrate the effectiveness of our approach, showing how it enables simpler model architectures to outperform or be comparable with more sophisticated designs on a range of vision-language tasks.
WAFFLe: Weight Anonymized Factorization for Federated Learning
Aug 13, 2020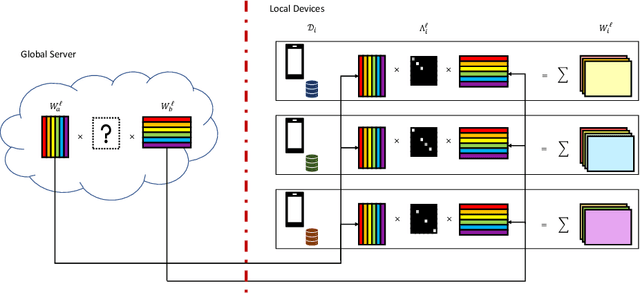
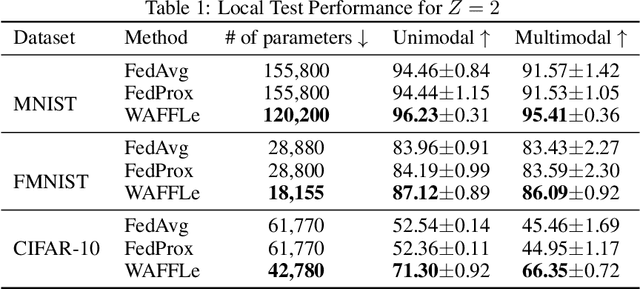
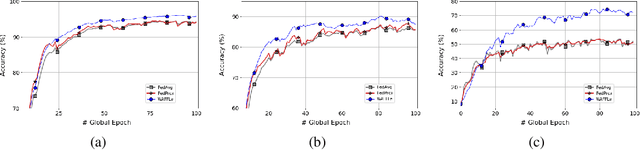
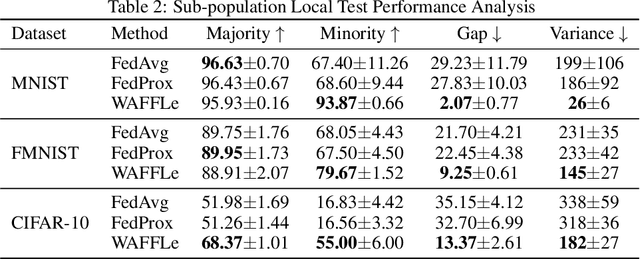
In domains where data are sensitive or private, there is great value in methods that can learn in a distributed manner without the data ever leaving the local devices. In light of this need, federated learning has emerged as a popular training paradigm. However, many federated learning approaches trade transmitting data for communicating updated weight parameters for each local device. Therefore, a successful breach that would have otherwise directly compromised the data instead grants whitebox access to the local model, which opens the door to a number of attacks, including exposing the very data federated learning seeks to protect. Additionally, in distributed scenarios, individual client devices commonly exhibit high statistical heterogeneity. Many common federated approaches learn a single global model; while this may do well on average, performance degrades when the i.i.d. assumption is violated, underfitting individuals further from the mean, and raising questions of fairness. To address these issues, we propose Weight Anonymized Factorization for Federated Learning (WAFFLe), an approach that combines the Indian Buffet Process with a shared dictionary of weight factors for neural networks. Experiments on MNIST, FashionMNIST, and CIFAR-10 demonstrate WAFFLe's significant improvement to local test performance and fairness while simultaneously providing an extra layer of security.
CLUB: A Contrastive Log-ratio Upper Bound of Mutual Information
Jul 14, 2020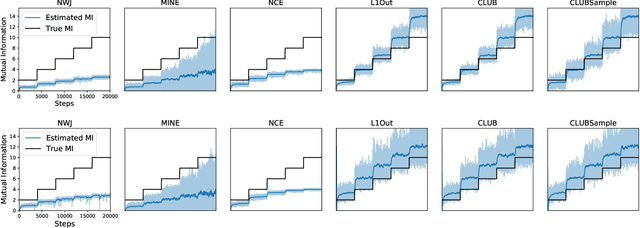
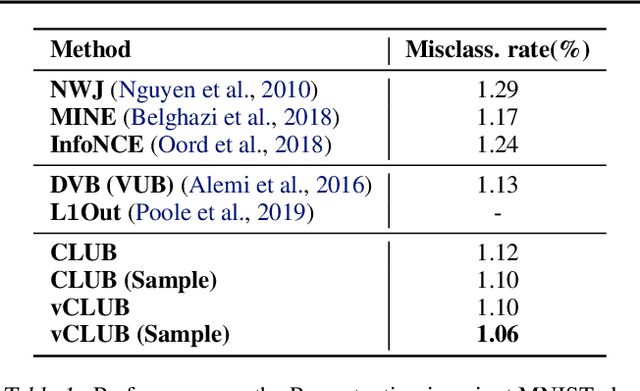
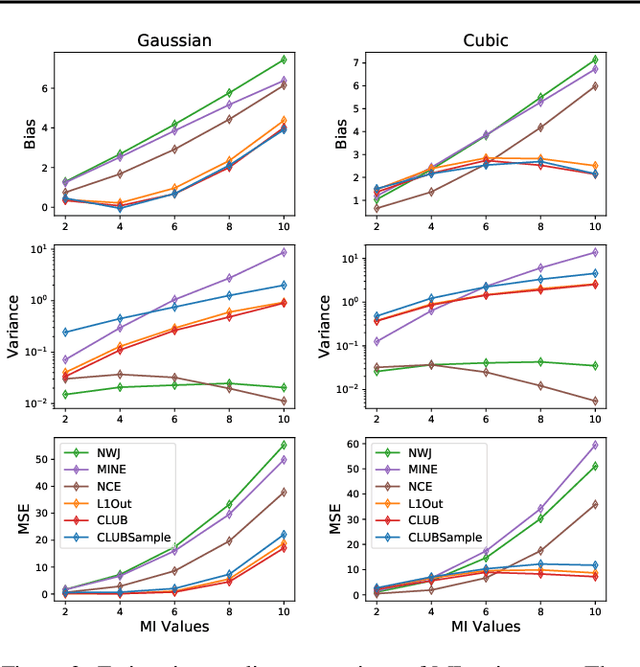
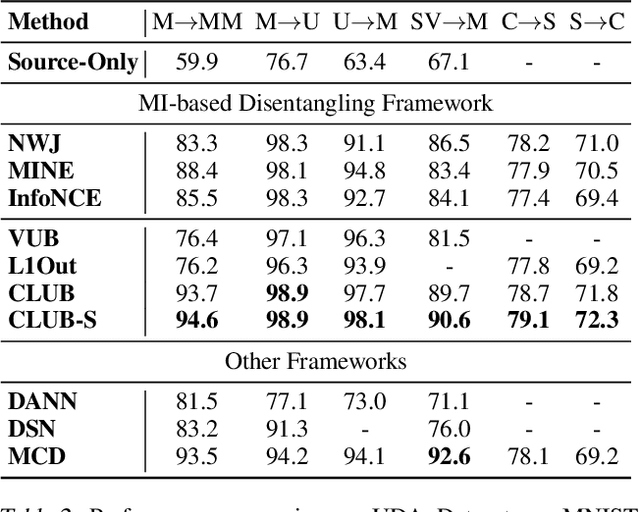
Mutual information (MI) minimization has gained considerable interests in various machine learning tasks. However, estimating and minimizing MI in high-dimensional spaces remains a challenging problem, especially when only samples, rather than distribution forms, are accessible. Previous works mainly focus on MI lower bound approximation, which is not applicable to MI minimization problems. In this paper, we propose a novel Contrastive Log-ratio Upper Bound (CLUB) of mutual information. We provide a theoretical analysis of the properties of CLUB and its variational approximation. Based on this upper bound, we introduce an accelerated MI minimization training scheme, which bridges MI minimization with negative sampling. Simulation studies on Gaussian distributions show the reliable estimation ability of CLUB. Real-world MI minimization experiments, including domain adaptation and information bottleneck, further demonstrate the effectiveness of the proposed method. The code is at https://github.com/Linear95/CLUB.
Bridging Maximum Likelihood and Adversarial Learning via $α$-Divergence
Jul 13, 2020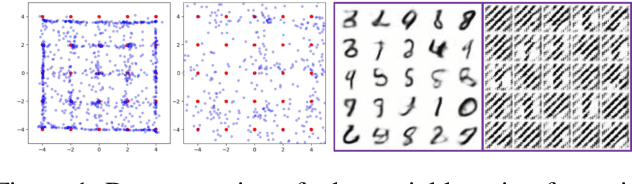

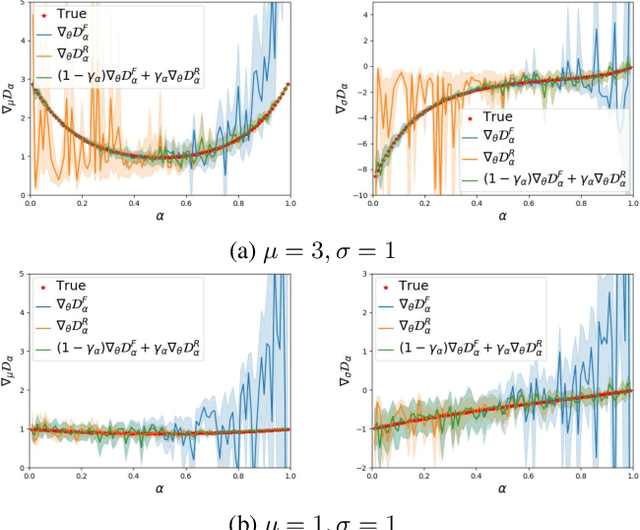

Maximum likelihood (ML) and adversarial learning are two popular approaches for training generative models, and from many perspectives these techniques are complementary. ML learning encourages the capture of all data modes, and it is typically characterized by stable training. However, ML learning tends to distribute probability mass diffusely over the data space, $e.g.$, yielding blurry synthetic images. Adversarial learning is well known to synthesize highly realistic natural images, despite practical challenges like mode dropping and delicate training. We propose an $\alpha$-Bridge to unify the advantages of ML and adversarial learning, enabling the smooth transfer from one to the other via the $\alpha$-divergence. We reveal that generalizations of the $\alpha$-Bridge are closely related to approaches developed recently to regularize adversarial learning, providing insights into that prior work, and further understanding of why the $\alpha$-Bridge performs well in practice.
Graph Optimal Transport for Cross-Domain Alignment
Jun 29, 2020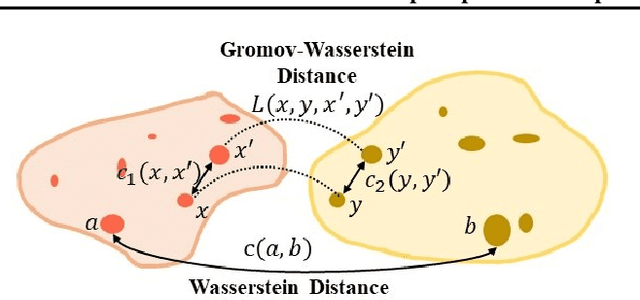
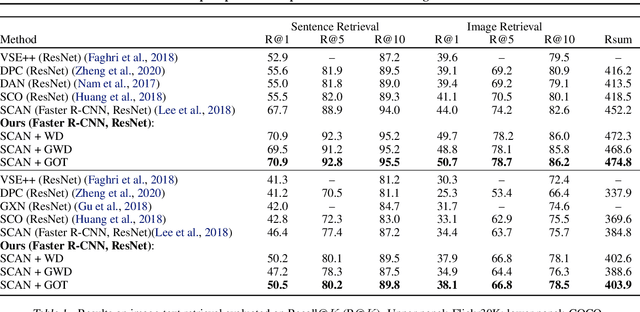
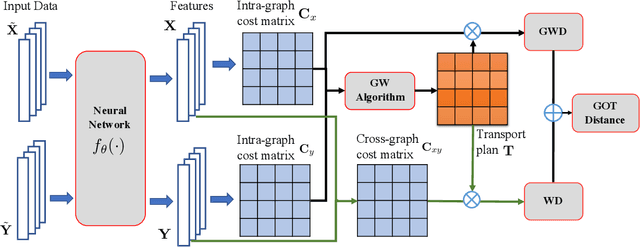
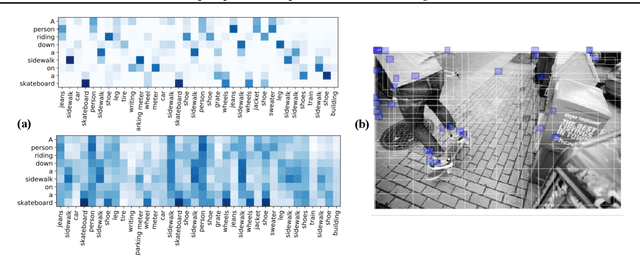
Cross-domain alignment between two sets of entities (e.g., objects in an image, words in a sentence) is fundamental to both computer vision and natural language processing. Existing methods mainly focus on designing advanced attention mechanisms to simulate soft alignment, with no training signals to explicitly encourage alignment. The learned attention matrices are also dense and lacks interpretability. We propose Graph Optimal Transport (GOT), a principled framework that germinates from recent advances in Optimal Transport (OT). In GOT, cross-domain alignment is formulated as a graph matching problem, by representing entities into a dynamically-constructed graph. Two types of OT distances are considered: (i) Wasserstein distance (WD) for node (entity) matching; and (ii) Gromov-Wasserstein distance (GWD) for edge (structure) matching. Both WD and GWD can be incorporated into existing neural network models, effectively acting as a drop-in regularizer. The inferred transport plan also yields sparse and self-normalized alignment, enhancing the interpretability of the learned model. Experiments show consistent outperformance of GOT over baselines across a wide range of tasks, including image-text retrieval, visual question answering, image captioning, machine translation, and text summarization.
Students Need More Attention: BERT-based AttentionModel for Small Data with Application to AutomaticPatient Message Triage
Jun 22, 2020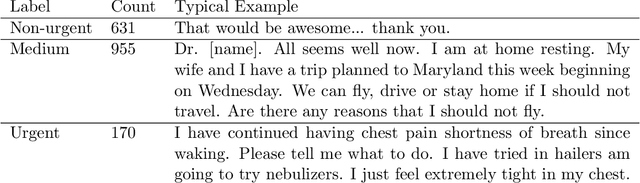
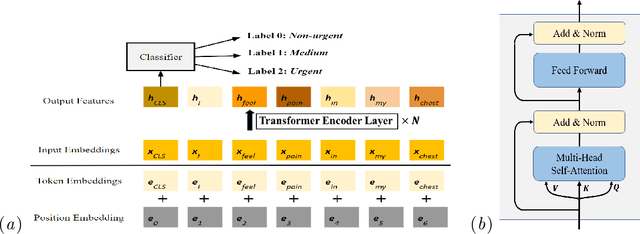

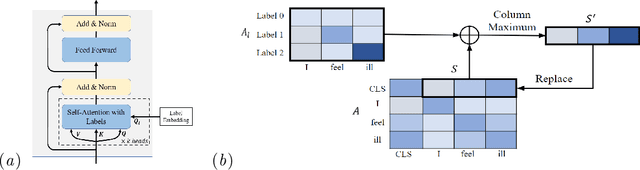
Small and imbalanced datasets commonly seen in healthcare represent a challenge when training classifiers based on deep learning models. So motivated, we propose a novel framework based on BioBERT (Bidirectional Encoder Representations from Transformers forBiomedical TextMining). Specifically, (i) we introduce Label Embeddings for Self-Attention in each layer of BERT, which we call LESA-BERT, and (ii) by distilling LESA-BERT to smaller variants, we aim to reduce overfitting and model size when working on small datasets. As an application, our framework is utilized to build a model for patient portal message triage that classifies the urgency of a message into three categories: non-urgent, medium and urgent. Experiments demonstrate that our approach can outperform several strong baseline classifiers by a significant margin of 4.3% in terms of macro F1 score. The code for this project is publicly available at \url{https://github.com/shijing001/text_classifiers}.
GO Hessian for Expectation-Based Objectives
Jun 16, 2020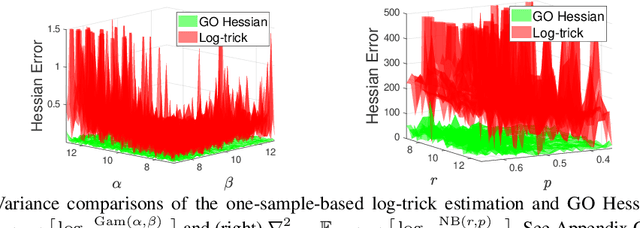

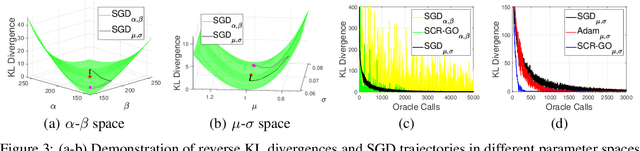
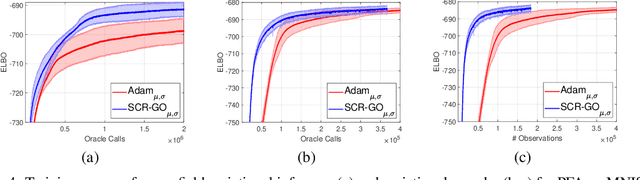
An unbiased low-variance gradient estimator, termed GO gradient, was proposed recently for expectation-based objectives $\mathbb{E}_{q_{\boldsymbol{\gamma}}(\boldsymbol{y})} [f(\boldsymbol{y})]$, where the random variable (RV) $\boldsymbol{y}$ may be drawn from a stochastic computation graph with continuous (non-reparameterizable) internal nodes and continuous/discrete leaves. Upgrading the GO gradient, we present for $\mathbb{E}_{q_{\boldsymbol{\boldsymbol{\gamma}}}(\boldsymbol{y})} [f(\boldsymbol{y})]$ an unbiased low-variance Hessian estimator, named GO Hessian. Considering practical implementation, we reveal that GO Hessian is easy-to-use with auto-differentiation and Hessian-vector products, enabling efficient cheap exploitation of curvature information over stochastic computation graphs. As representative examples, we present the GO Hessian for non-reparameterizable gamma and negative binomial RVs/nodes. Based on the GO Hessian, we design a new second-order method for $\mathbb{E}_{q_{\boldsymbol{\boldsymbol{\gamma}}}(\boldsymbol{y})} [f(\boldsymbol{y})]$, with rigorous experiments conducted to verify its effectiveness and efficiency.
Survival Analysis meets Counterfactual Inference
Jun 14, 2020
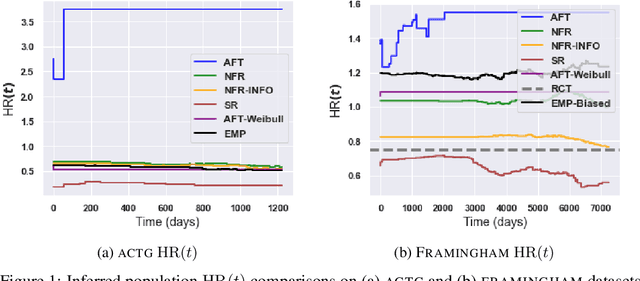
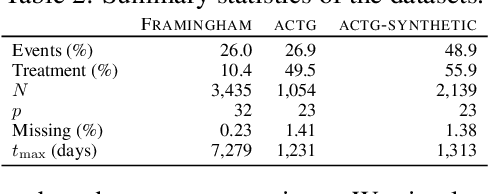
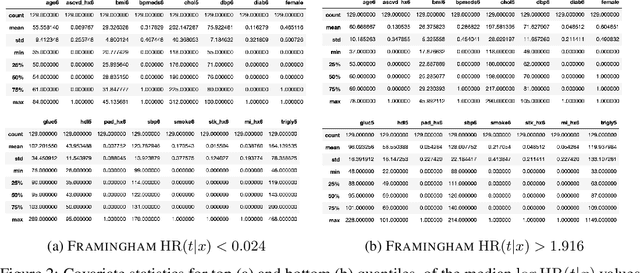
There is growing interest in applying machine learning methods for counterfactual inference from observational data. However, approaches that account for survival outcomes are relatively limited. Survival data are frequently encountered across diverse medical applications, \textit{i.e.}, drug development, risk profiling, and clinical trials, and such data are also relevant in fields like manufacturing (for equipment monitoring). When the outcome of interest is time-to-event, special precautions for handling censored events need to be taken, as ignoring censored outcomes may lead to biased estimates. We propose a theoretically grounded unified framework for counterfactual inference applicable to survival outcomes. Further, we formulate a nonparametric hazard ratio metric for evaluating average and individualized treatment effects. Experimental results on real-world and semi-synthetic datasets, the latter which we introduce, demonstrate that the proposed approach significantly outperforms competitive alternatives in both survival-outcome predictions and treatment-effect estimation.
GAN Memory with No Forgetting
Jun 13, 2020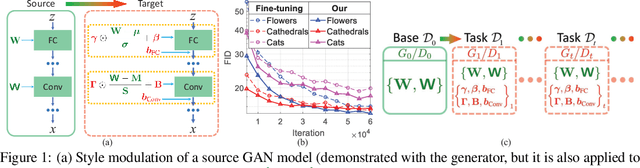



Seeking to address the fundamental issue of memory in lifelong learning, we propose a GAN memory that is capable of realistically remembering a stream of generative processes with \emph{no} forgetting. Our GAN memory is based on recognizing that one can modulate the ``style'' of a GAN model to form perceptually-distant targeted generation. Accordingly, we propose to do sequential style modulations atop a well-behaved base GAN model, to form sequential targeted generative models, while simultaneously benefiting from the transferred base knowledge. Experiments demonstrate the superiority of our method over existing approaches and its effectiveness in alleviating catastrophic forgetting for lifelong classification problems.
Scalable Control Variates for Monte Carlo Methods via Stochastic Optimization
Jun 12, 2020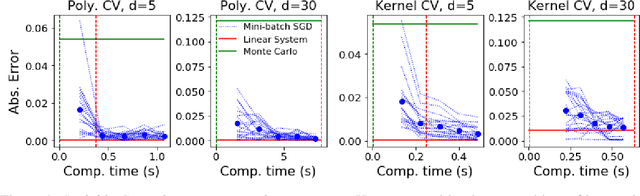
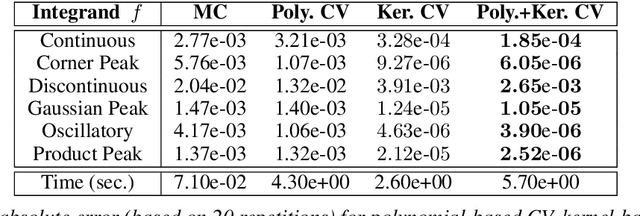
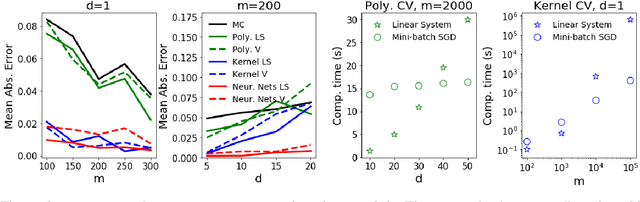
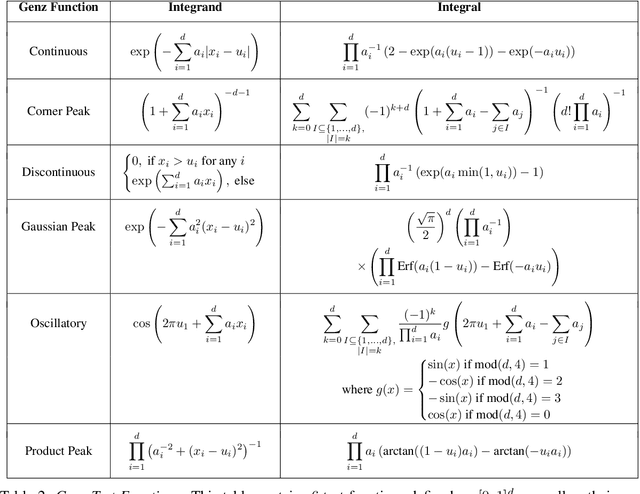
Control variates are a well-established tool to reduce the variance of Monte Carlo estimators. However, for large-scale problems including high-dimensional and large-sample settings, their advantages can be outweighed by a substantial computational cost. This paper considers control variates based on Stein operators, presenting a framework that encompasses and generalizes existing approaches that use polynomials, kernels and neural networks. A learning strategy based on minimising a variational objective through stochastic optimization is proposed, leading to scalable and effective control variates. Our results are both empirical, based on a range of test functions and problems in Bayesian inference, and theoretical, based on an analysis of the variance reduction that can be achieved.