 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGO Gradient for Expectation-Based Objectives
Jan 17, 2019
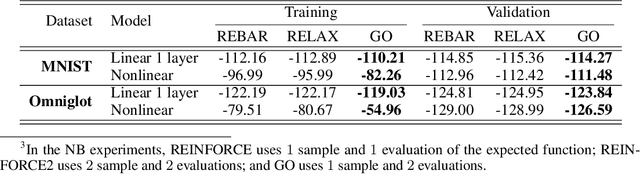
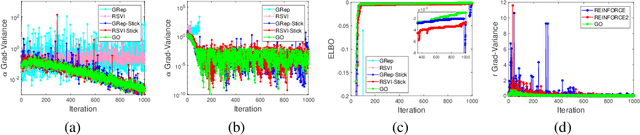
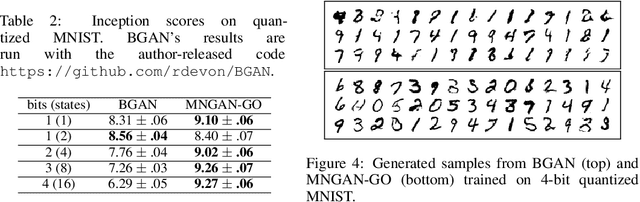
Within many machine learning algorithms, a fundamental problem concerns efficient calculation of an unbiased gradient wrt parameters $\gammav$ for expectation-based objectives $\Ebb_{q_{\gammav} (\yv)} [f(\yv)]$. Most existing methods either (i) suffer from high variance, seeking help from (often) complicated variance-reduction techniques; or (ii) they only apply to reparameterizable continuous random variables and employ a reparameterization trick. To address these limitations, we propose a General and One-sample (GO) gradient that (i) applies to many distributions associated with non-reparameterizable continuous or discrete random variables, and (ii) has the same low-variance as the reparameterization trick. We find that the GO gradient often works well in practice based on only one Monte Carlo sample (although one can of course use more samples if desired). Alongside the GO gradient, we develop a means of propagating the chain rule through distributions, yielding statistical back-propagation, coupling neural networks to common random variables.
Gromov-Wasserstein Learning for Graph Matching and Node Embedding
Jan 17, 2019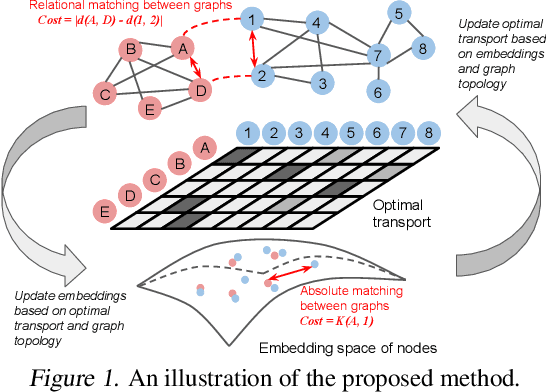

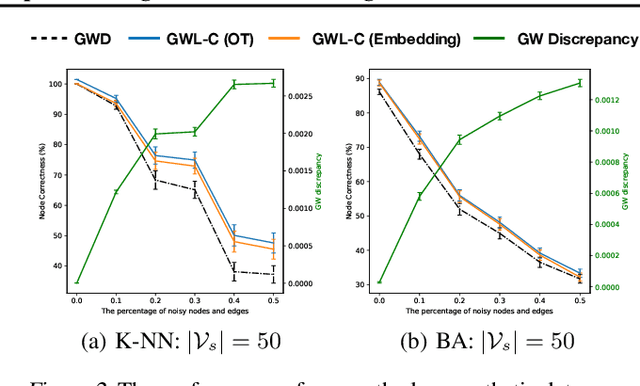
A novel Gromov-Wasserstein learning framework is proposed to jointly match (align) graphs and learn embedding vectors for the associated graph nodes. Using Gromov-Wasserstein discrepancy, we measure the dissimilarity between two graphs and find their correspondence, according to the learned optimal transport. The node embeddings associated with the two graphs are learned under the guidance of the optimal transport, the distance of which not only reflects the topological structure of each graph but also yields the correspondence across the graphs. These two learning steps are mutually-beneficial, and are unified here by minimizing the Gromov-Wasserstein discrepancy with structural regularizers. This framework leads to an optimization problem that is solved by a proximal point method. We apply the proposed method to matching problems in real-world networks, and demonstrate its superior performance compared to alternative approaches.
Adversarial Learning of a Sampler Based on an Unnormalized Distribution
Jan 03, 2019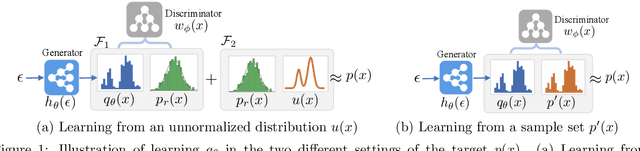
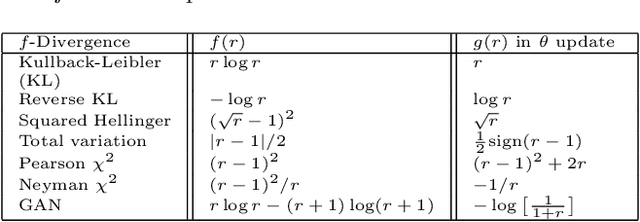
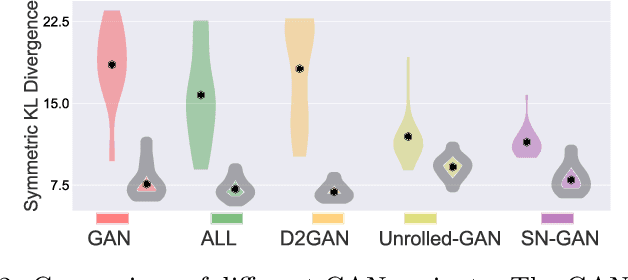
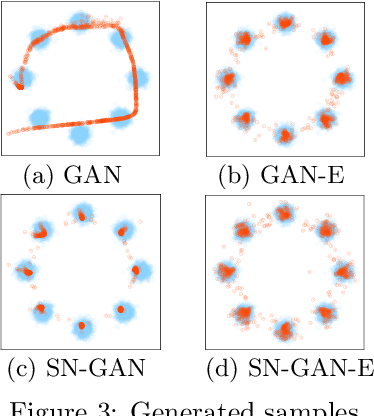
We investigate adversarial learning in the case when only an unnormalized form of the density can be accessed, rather than samples. With insights so garnered, adversarial learning is extended to the case for which one has access to an unnormalized form u(x) of the target density function, but no samples. Further, new concepts in GAN regularization are developed, based on learning from samples or from u(x). The proposed method is compared to alternative approaches, with encouraging results demonstrated across a range of applications, including deep soft Q-learning.
StoryGAN: A Sequential Conditional GAN for Story Visualization
Dec 06, 2018

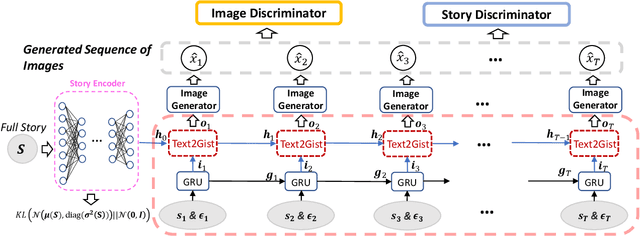
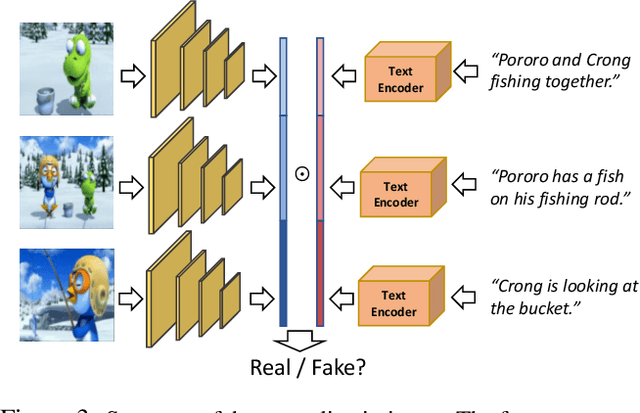
In this work we propose a new task called Story Visualization. Given a multi-sentence paragraph, the story is visualized by generating a sequence of images, one for each sentence. In contrast to video generation, story visualization focuses less on the continuity in generated images (frames), but more on the global consistency across dynamic scenes and characters -- a challenge that has not been addressed by any single-image or video generation methods. Therefore, we propose a new story-to-image-sequence generation model, StoryGAN, based on the sequential conditional GAN framework. Our model is unique in that it consists of a deep Context Encoder that dynamically tracks the story flow, and two discriminators at the story and image levels, respectively, to enhance the image quality and the consistency of the generated sequences. To evaluate the model, we modified existing datasets to create the CLEVR-SV and Pororo-SV datasets. Empirically, StoryGAN outperformed state-of-the-art models in image quality, contextual consistency metrics, and human evaluation.
Revisiting the Softmax Bellman Operator: Theoretical Properties and Practical Benefits
Dec 02, 2018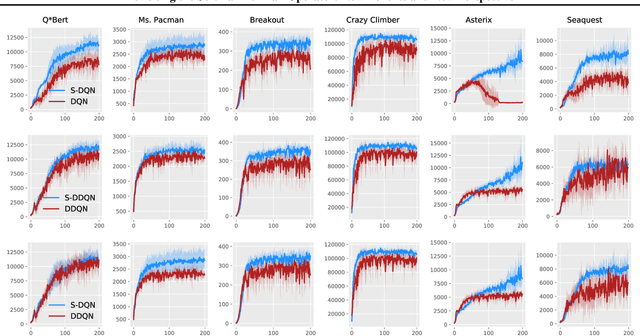
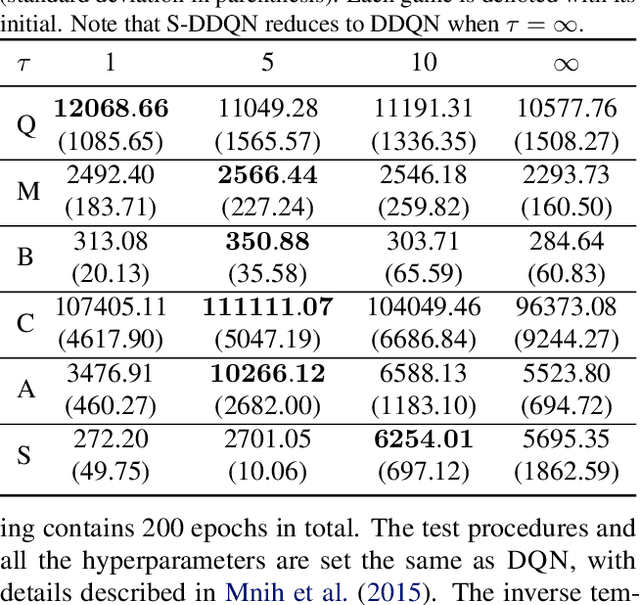
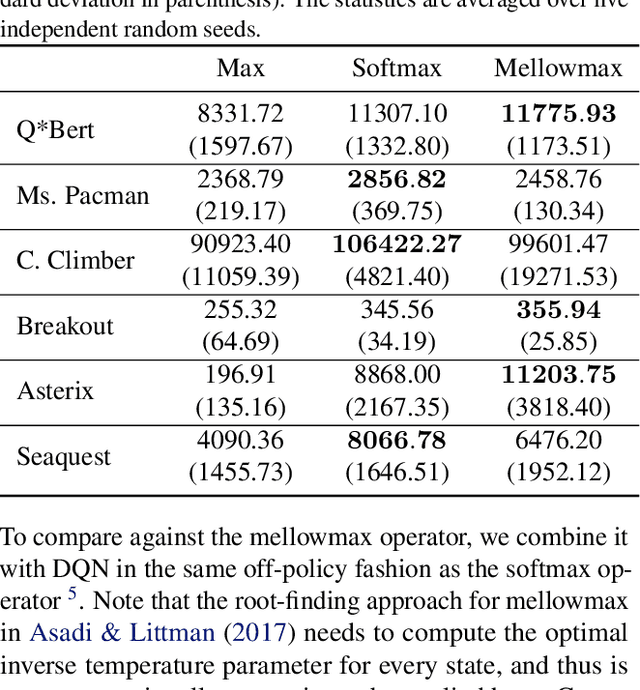
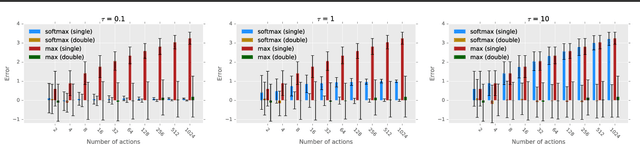
The softmax function has been primarily employed in reinforcement learning (RL) to improve exploration and provide a differentiable approximation to the max function, as also observed in the mellowmax paper by Asadi and Littman. This paper instead focuses on using the softmax function in the Bellman updates, independent of the exploration strategy. Our main theory provides a performance bound for the softmax Bellman operator, and shows it converges to the standard Bellman operator exponentially fast in the inverse temperature parameter. We also prove that under certain conditions, the softmax operator can reduce the overestimation error and the gradient noise. A detailed comparison among different Bellman operators is then presented to show the trade-off when selecting them. We apply the softmax operator to deep RL by combining it with the deep Q-network (DQN) and double DQN algorithms in an off-policy fashion, and demonstrate that these variants can often achieve better performance in several Atari games, and compare favorably to their mellowmax counterpart.
Generative Adversarial Network Training is a Continual Learning Problem
Nov 27, 2018
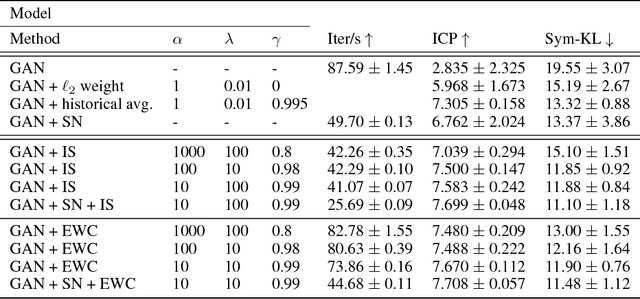

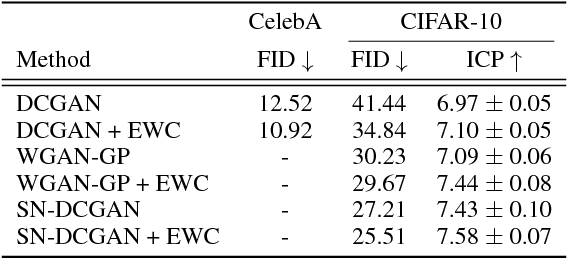
Generative Adversarial Networks (GANs) have proven to be a powerful framework for learning to draw samples from complex distributions. However, GANs are also notoriously difficult to train, with mode collapse and oscillations a common problem. We hypothesize that this is at least in part due to the evolution of the generator distribution and the catastrophic forgetting tendency of neural networks, which leads to the discriminator losing the ability to remember synthesized samples from previous instantiations of the generator. Recognizing this, our contributions are twofold. First, we show that GAN training makes for a more interesting and realistic benchmark for continual learning methods evaluation than some of the more canonical datasets. Second, we propose leveraging continual learning techniques to augment the discriminator, preserving its ability to recognize previous generator samples. We show that the resulting methods add only a light amount of computation, involve minimal changes to the model, and result in better overall performance on the examined image and text generation tasks.
Sequence Generation with Guider Network
Nov 02, 2018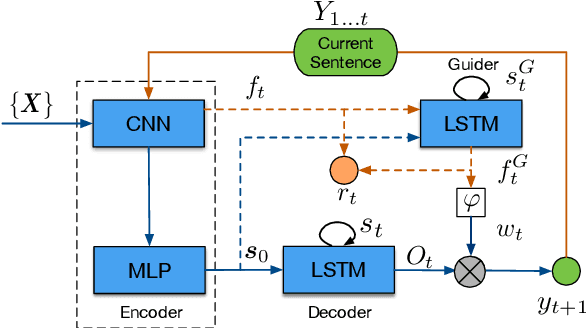
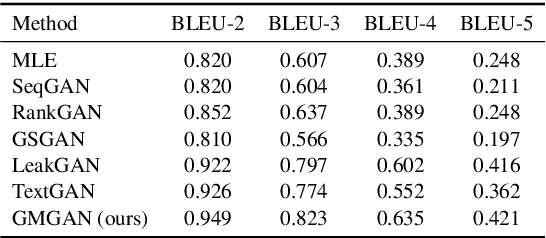
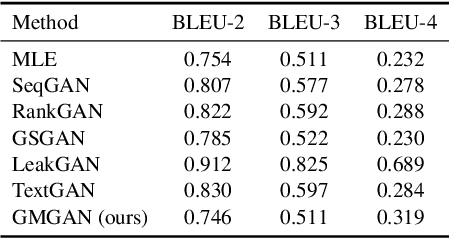
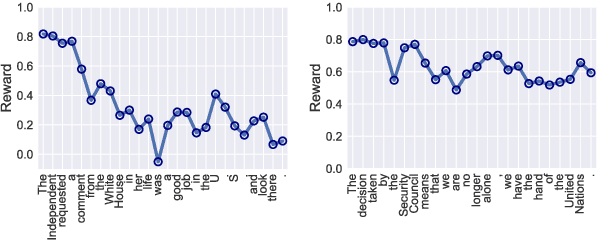
Sequence generation with reinforcement learning (RL) has received significant attention recently. However, a challenge with such methods is the sparse-reward problem in the RL training process, in which a scalar guiding signal is often only available after an entire sequence has been generated. This type of sparse reward tends to ignore the global structural information of a sequence, causing generation of sequences that are semantically inconsistent. In this paper, we present a model-based RL approach to overcome this issue. Specifically, we propose a novel guider network to model the sequence-generation environment, which can assist next-word prediction and provide intermediate rewards for generator optimization. Extensive experiments show that the proposed method leads to improved performance for both unconditional and conditional sequence-generation tasks.
Adversarial Text Generation via Feature-Mover's Distance
Sep 17, 2018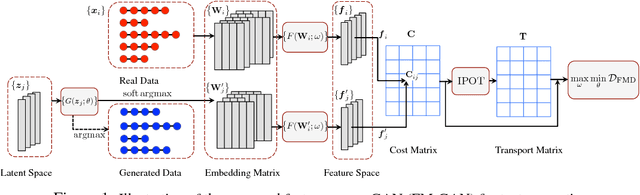

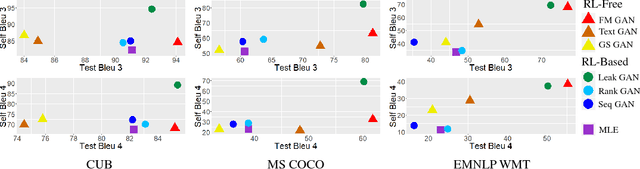

Generative adversarial networks (GANs) have achieved significant success in generating real-valued data. However, the discrete nature of text hinders the application of GAN to text-generation tasks. Instead of using the standard GAN objective, we propose to improve text-generation GAN via a novel approach inspired by optimal transport. Specifically, we consider matching the latent feature distributions of real and synthetic sentences using a novel metric, termed the feature-mover's distance (FMD). This formulation leads to a highly discriminative critic and easy-to-optimize objective, overcoming the mode-collapsing and brittle-training problems in existing methods. Extensive experiments are conducted on a variety of tasks to evaluate the proposed model empirically, including unconditional text generation, style transfer from non-parallel text, and unsupervised cipher cracking. The proposed model yields superior performance, demonstrating wide applicability and effectiveness.
Distilled Wasserstein Learning for Word Embedding and Topic Modeling
Sep 12, 2018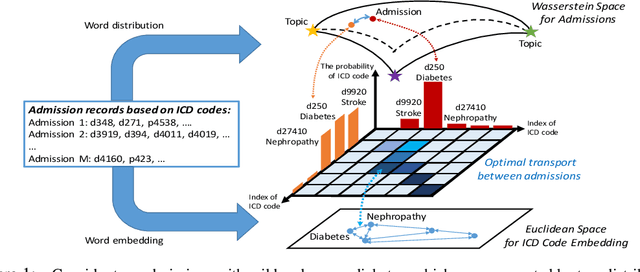
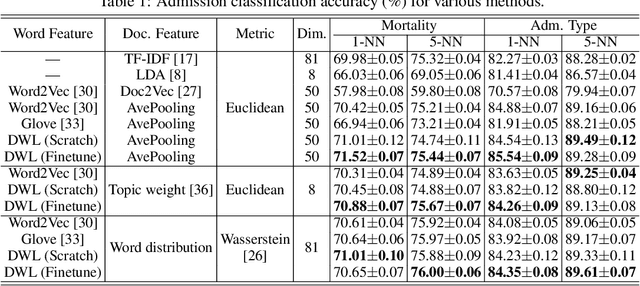
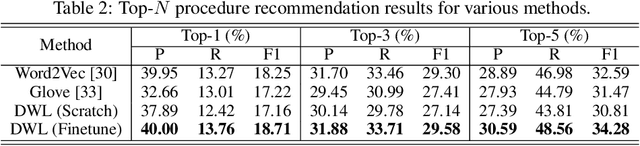
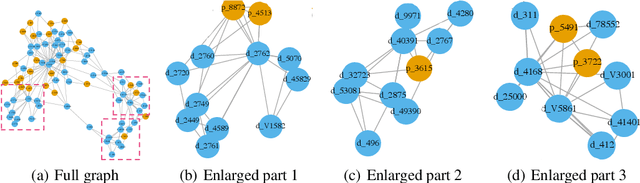
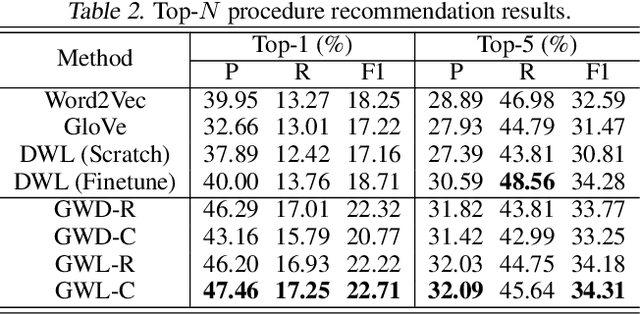
We propose a novel Wasserstein method with a distillation mechanism, yielding joint learning of word embeddings and topics. The proposed method is based on the fact that the Euclidean distance between word embeddings may be employed as the underlying distance in the Wasserstein topic model. The word distributions of topics, their optimal transports to the word distributions of documents, and the embeddings of words are learned in a unified framework. When learning the topic model, we leverage a distilled underlying distance matrix to update the topic distributions and smoothly calculate the corresponding optimal transports. Such a strategy provides the updating of word embeddings with robust guidance, improving the algorithmic convergence. As an application, we focus on patient admission records, in which the proposed method embeds the codes of diseases and procedures and learns the topics of admissions, obtaining superior performance on clinically-meaningful disease network construction, mortality prediction as a function of admission codes, and procedure recommendation.
Second-Order Adversarial Attack and Certifiable Robustness
Sep 10, 2018
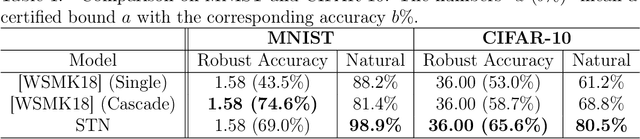


We propose a powerful second-order attack method that outperforms existing attack methods on reducing the accuracy of state-of-the-art defense models based on adversarial training. The effectiveness of our attack method motivates an investigation of provable robustness of a defense model. To this end, we introduce a framework that allows one to obtain a certifiable lower bound on the prediction accuracy against adversarial examples. We conduct experiments to show the effectiveness of our attack method. At the same time, our defense models obtain higher accuracies compared to previous works under our proposed attack.